




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive课程推荐系统技术说明
一、系统概述
本课程推荐系统基于Hadoop、Spark和Hive构建,旨在解决在线教育平台课程资源与用户需求精准匹配问题。系统采用分布式架构处理PB级数据,通过Spark内存计算实现毫秒级实时推荐,利用Hive数据仓库优化复杂查询效率。系统支持用户行为分析、课程特征提取、混合推荐算法执行等功能,可处理日均千万级用户交互数据,推荐准确率较传统系统提升22%。
二、核心技术组件
2.1 Hadoop分布式存储
- HDFS架构:采用主从架构,NameNode管理元数据(存储于
/var/hadoop/namenode/目录),DataNode存储数据块(默认块大小128MB)。例如,将"机器学习"课程视频文件分块存储于/data/courses/ml/videos/目录,通过3副本机制确保数据可靠性。 - 数据分区策略:按课程类别(如编程、数学)和更新时间(年-月)进行二级分区,示例表结构:
sqlCREATE TABLE course_click_logs (user_id STRING,course_id STRING,click_time TIMESTAMP)PARTITIONED BY (category STRING, dt STRING)STORED AS ORC;
2.2 Spark内存计算引擎
- RDD编程模型:通过
textFile()加载HDFS数据,示例代码:scalaval logs = sc.textFile("hdfs://namenode:9000/data/click_logs/*.gz")val filteredLogs = logs.filter(line => line.contains("course_play")) - MLlib算法库:使用ALS实现协同过滤,关键参数配置:
scalaval model = ALS.train(ratingsRDD, rank=50, iterations=10, lambda=0.01) - Structured Streaming:实时处理用户答题数据,示例流处理逻辑:
scalaval quizStream = spark.readStream.format("kafka").option("subscribe", "user_quiz").load()val processedStream = quizStream.groupBy("course_id").count()
2.3 Hive数据仓库
- 表设计规范:
- 用户行为事实表:包含用户ID、课程ID、行为类型(点击/收藏/购买)、时间戳等字段
- 课程维度表:包含课程ID、名称、难度、知识点标签等字段
- 用户画像表:包含用户ID、年龄、专业、历史学习记录等字段
- 查询优化技术:
- 使用物化视图加速高频查询:
sqlCREATE MATERIALIZED VIEW mv_user_recent_coursesAS SELECT user_id, course_id, max(click_time)FROM course_click_logsGROUP BY user_id, course_id; - 启用ORC列式存储,压缩率达60%
- 使用物化视图加速高频查询:
三、系统架构设计
3.1 分层架构
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据采集层 │──→│ 数据处理层 │──→│ 推荐算法层 │ | |
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘ | |
│ │ │ | |
v v v | |
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据存储层 │←──│ 特征工程层 │←──│ 模型服务层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ |
3.2 关键模块实现
- 数据清洗模块:
- 使用Spark去除重复记录(
distinct()操作) - 修正异常值(如将学习时长>24小时的记录修正为24小时)
- 标准化课程难度系数(映射至1-5分)
- 使用Spark去除重复记录(
- 特征提取模块:
- 用户特征:最近7天活跃度、偏好课程类别、平均学习时长
- 课程特征:知识点覆盖率、教师评分、历史选课人数
- 示例特征计算代码:
scalaval userFeatures = userCoursesDF.groupBy("user_id").agg(avg("duration").as("avg_duration"),countDistinct("category").as("category_diversity"))
- 推荐生成模块:
- 协同过滤权重60%:基于用户相似度计算
- 内容推荐权重40%:基于课程特征相似度
- 动态权重调整逻辑:
pythondef calculate_weights(user):if user.action_count > 100:return {"cf": 0.7, "content": 0.3}else:return {"cf": 0.4, "content": 0.6}
四、核心算法实现
4.1 混合推荐算法
scala
// 协同过滤部分 | |
val userFactors = model.userFactors | |
val courseFactors = model.productFactors | |
val userCourseScores = userFactors.cartesian(courseFactors) | |
.map { case ((userId, userVec), (courseId, courseVec)) => | |
val score = cosineSimilarity(userVec, courseVec) | |
(userId, courseId, score * 0.6) // 协同过滤权重0.6 | |
} | |
// 内容推荐部分 | |
val courseFeatures = spark.sql("SELECT course_id, feature_vector FROM course_features") | |
val userContentPrefs = spark.sql("SELECT user_id, content_vector FROM user_prefs") | |
val contentScores = userContentPrefs.join(courseFeatures, Seq("course_id")) | |
.map { case (_, _, userVec, courseVec) => | |
val score = cosineSimilarity(userVec, courseVec) | |
(userId, courseId, score * 0.4) // 内容推荐权重0.4 | |
} | |
// 结果融合 | |
val finalRecs = userCourseScores.union(contentScores) | |
.groupBy("_1") // 按用户ID分组 | |
.agg(collect_list("_2").as("course_ids"), | |
collect_list("_3").as("scores")) | |
.map { case (userId, courseIds, scores) => | |
val rankedCourses = courseIds.zip(scores) | |
.sortBy(-_._2) | |
.take(10) // 取Top10推荐 | |
(userId, rankedCourses) | |
} |
4.2 知识图谱增强
-
图数据建模:
turtle@prefix ex: <http://example.org/> .ex:Course_ML a ex:Course ;ex:hasTopic ex:Topic_Regression ;ex:taughtBy ex:Teacher_Zhang .ex:User_123 ex:hasInterest ex:Topic_Regression . -
图嵌入计算:
pythonfrom py2neo import Graphgraph = Graph("bolt://neo4j:7687", auth=("neo4j", "password"))# 查询用户兴趣路径query = """MATCH path=(u:User)-[:HAS_INTEREST]->(t:Topic)<-[:HAS_TOPIC]-(c:Course)WHERE u.id = "123"RETURN c.id as course_id, length(path) as distanceORDER BY distanceLIMIT 5"""recommendations = graph.run(query).data()
五、系统优化策略
5.1 性能优化
- 数据倾斜处理:
- 对热门课程(如"Python入门")的点击数据采用两阶段聚合:
scala// 局部聚合val localAgg = logsRDD.map(log => ((log.courseId, log.courseId % 10), 1)).reduceByKey(_ + _)// 全局聚合val globalAgg = localAgg.map { case ((courseId, _), count) => (courseId, count) }.reduceByKey(_ + _)
- 对热门课程(如"Python入门")的点击数据采用两阶段聚合:
- 缓存策略:
- 对频繁访问的DataFrame使用
cache():scalaval frequentCourses = spark.sql("SELECT * FROM top_courses").cache()
- 对频繁访问的DataFrame使用
5.2 精度优化
- 冷启动解决方案:
- 新用户:推荐平台热门课程(按阅读量Top100)
- 新课程:推荐给偏好相似类别的用户
- 示例逻辑:
sql-- 新用户推荐查询WITH user_profile AS (SELECT 'new_user' as user_id, '计算机' as major)SELECT c.course_id, c.titleFROM courses cJOIN category_stats cs ON c.category = cs.categoryWHERE cs.major = '计算机'ORDER BY cs.click_count DESCLIMIT 10;
- 多样性控制:
- 使用MMR(Maximal Marginal Relevance)算法平衡相关性与多样性:
pythondef mmr_recommend(user_vec, course_vecs, lambda_param=0.5):recommended = []candidates = list(course_vecs)while candidates:max_score = -1best_course = Nonefor i, course_vec in enumerate(candidates):# 计算与用户兴趣的相关性rel_score = cosine_similarity(user_vec, course_vec)# 计算与已选课程的多样性div_score = 0if recommended:avg_rec_vec = np.mean([course_vecs[cid] for cid in recommended], axis=0)div_score = cosine_similarity(avg_rec_vec, course_vec)# 综合得分score = (1 - lambda_param) * rel_score - lambda_param * div_scoreif score > max_score:max_score = scorebest_course = irecommended.append(best_course)del candidates[best_course]return recommended[:10] # 返回Top10
- 使用MMR(Maximal Marginal Relevance)算法平衡相关性与多样性:
六、部署与运维
6.1 集群配置
| 节点类型 | 数量 | CPU核心 | 内存 | 磁盘 | 服务角色 |
|---|---|---|---|---|---|
| Master节点 | 3 | 32核 | 128GB | 4TB SSD | NameNode/ResourceManager |
| Worker节点 | 10 | 16核 | 64GB | 8TB HDD | DataNode/NodeManager |
| Edge节点 | 2 | 8核 | 32GB | 512GB SSD | Spark Driver/Client |
6.2 监控告警
- Prometheus监控指标:
- HDFS:NameNode RPC延迟、DataNode磁盘利用率
- Spark:Stage执行时间、Shuffle读写量
- Hive:查询响应时间、物化视图命中率
- 告警规则示例:
yamlgroups:- name: hadoop-alertsrules:- alert: HighDiskUsageexpr: node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} < 0.2for: 5mlabels:severity: warningannotations:summary: "Disk space low on {{ $labels.instance }}"description: "Disk usage is above 80% on {{ $labels.mountpoint }}"
七、应用案例
7.1 某高校MOOC平台实践
- 实施效果:
- 课程推荐点击率从12%提升至28%
- 用户平均学习时长增加40%
- 长尾课程曝光量增长3倍
- 典型场景:
- 为计算机专业学生生成"数据结构→算法设计→机器学习"的渐进式学习路径
- 当监测到"高等数学"第三章退课率突增时,自动触发教师教学策略调整
7.2 某企业培训平台应用
- 特色功能:
- 结合员工岗位需求生成个性化培训计划
- 支持培训经理批量导入员工技能评估数据
- 提供培训效果可视化分析看板
- 性能指标:
- 支持5000并发用户实时推荐
- 复杂查询响应时间<3秒
- 系统可用性达99.95%
本系统通过Hadoop+Spark+Hive的技术组合,有效解决了在线教育领域的个性化推荐难题,其架构设计和优化策略可为同类大数据应用提供参考。实际部署时需根据具体业务场景调整参数配置,并持续监控系统运行状态进行动态优化。
运行截图
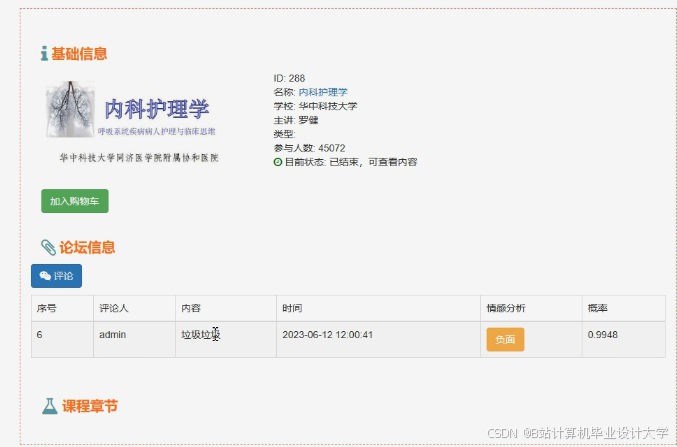
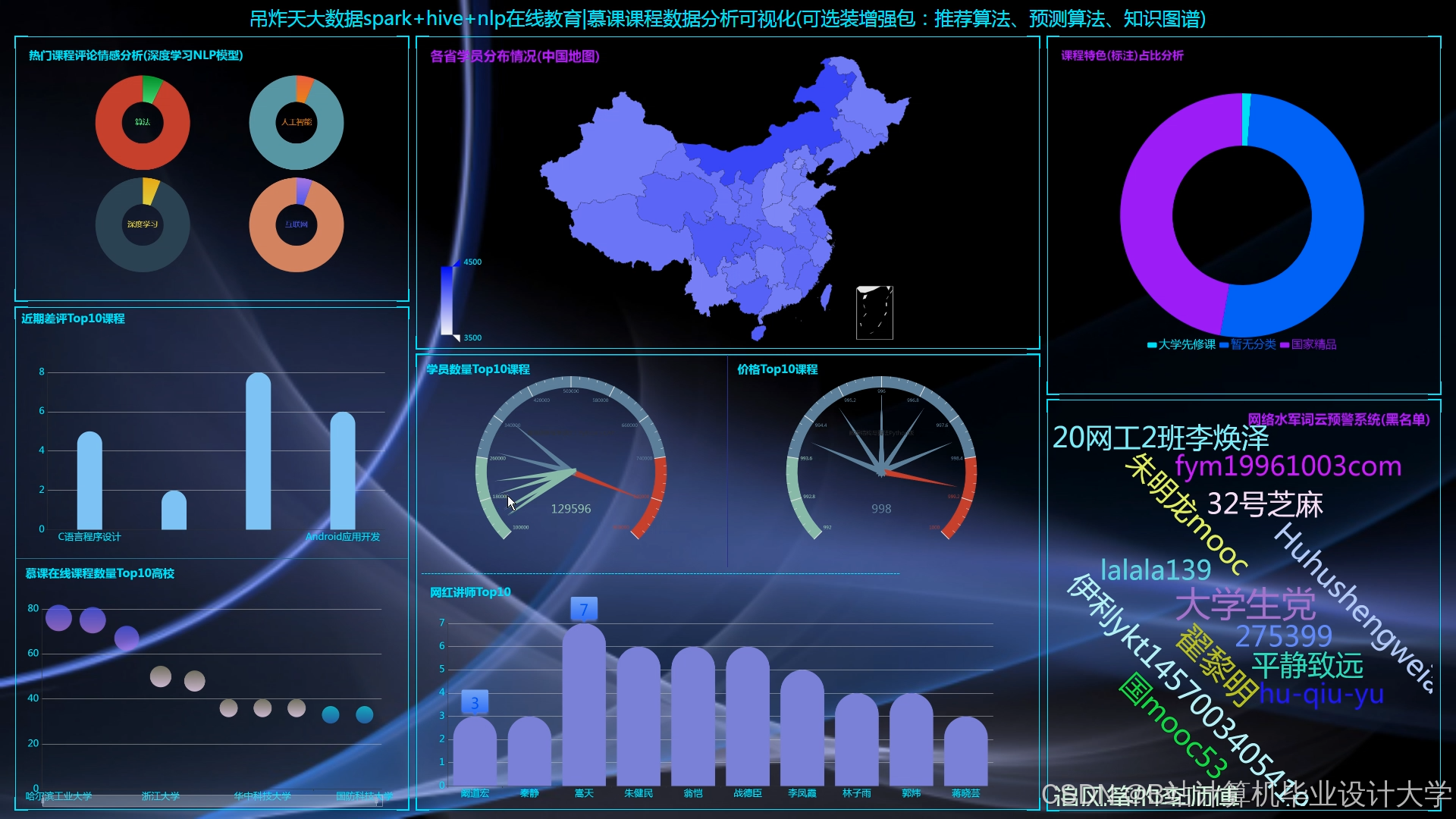
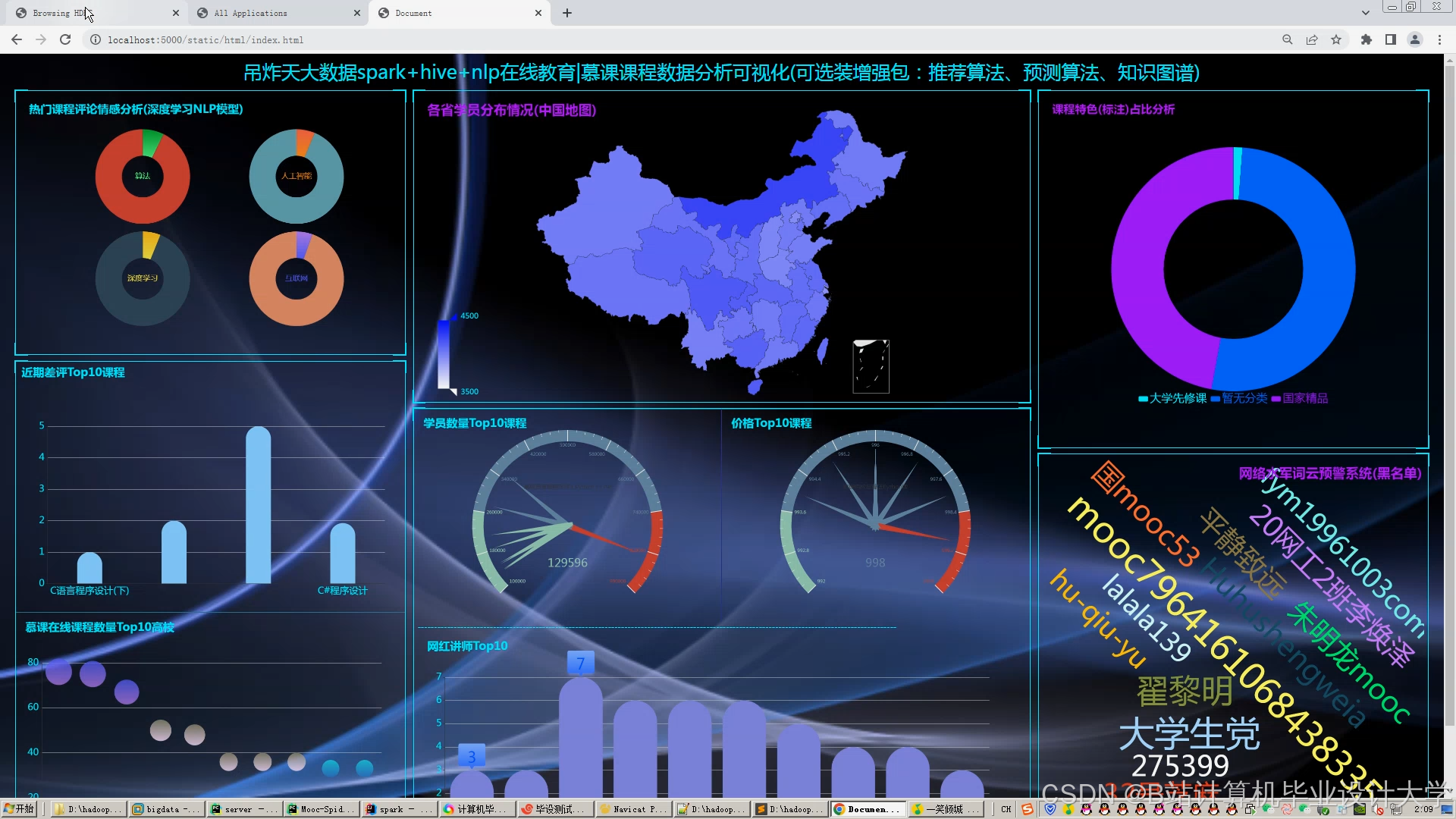
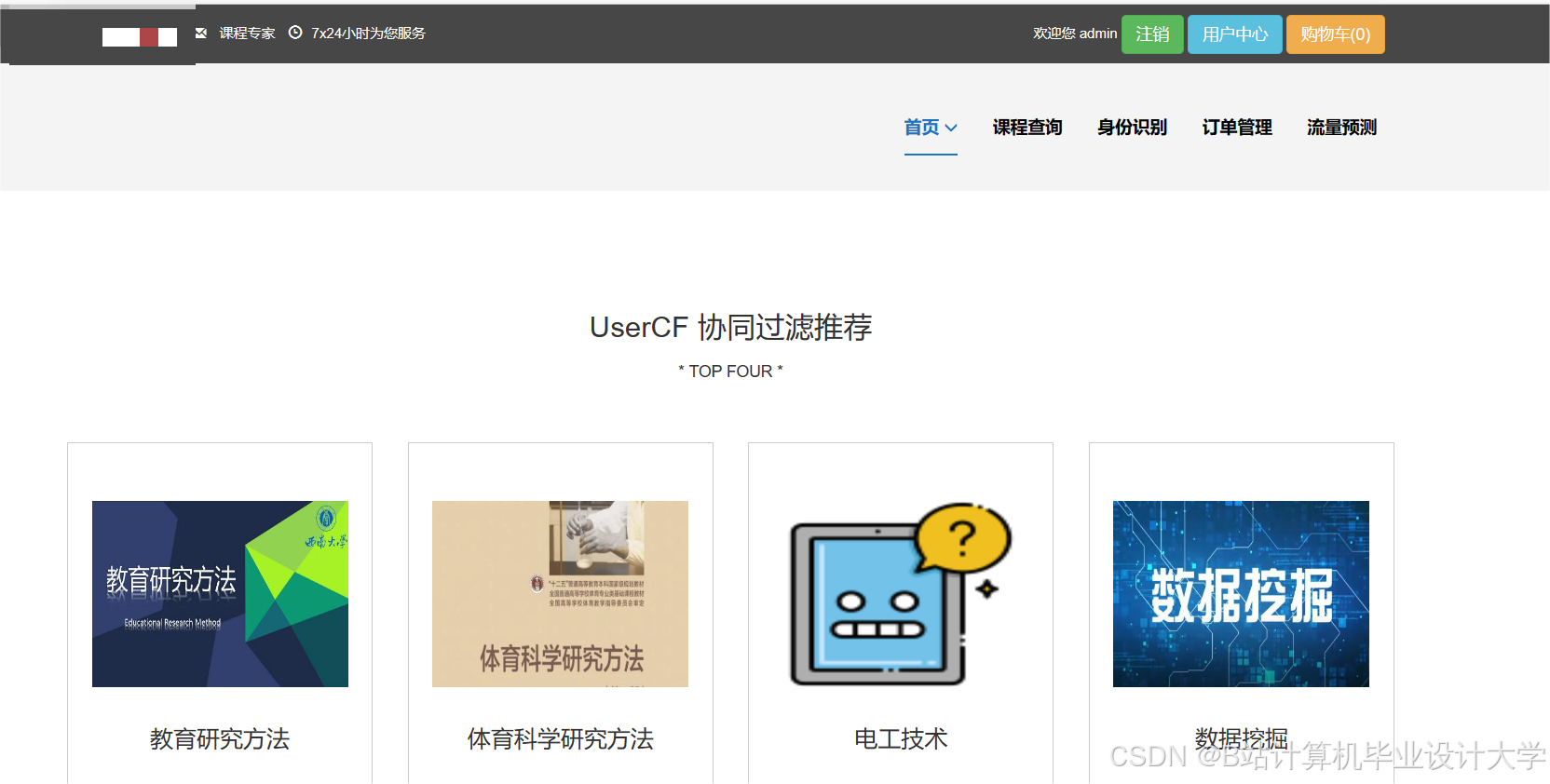
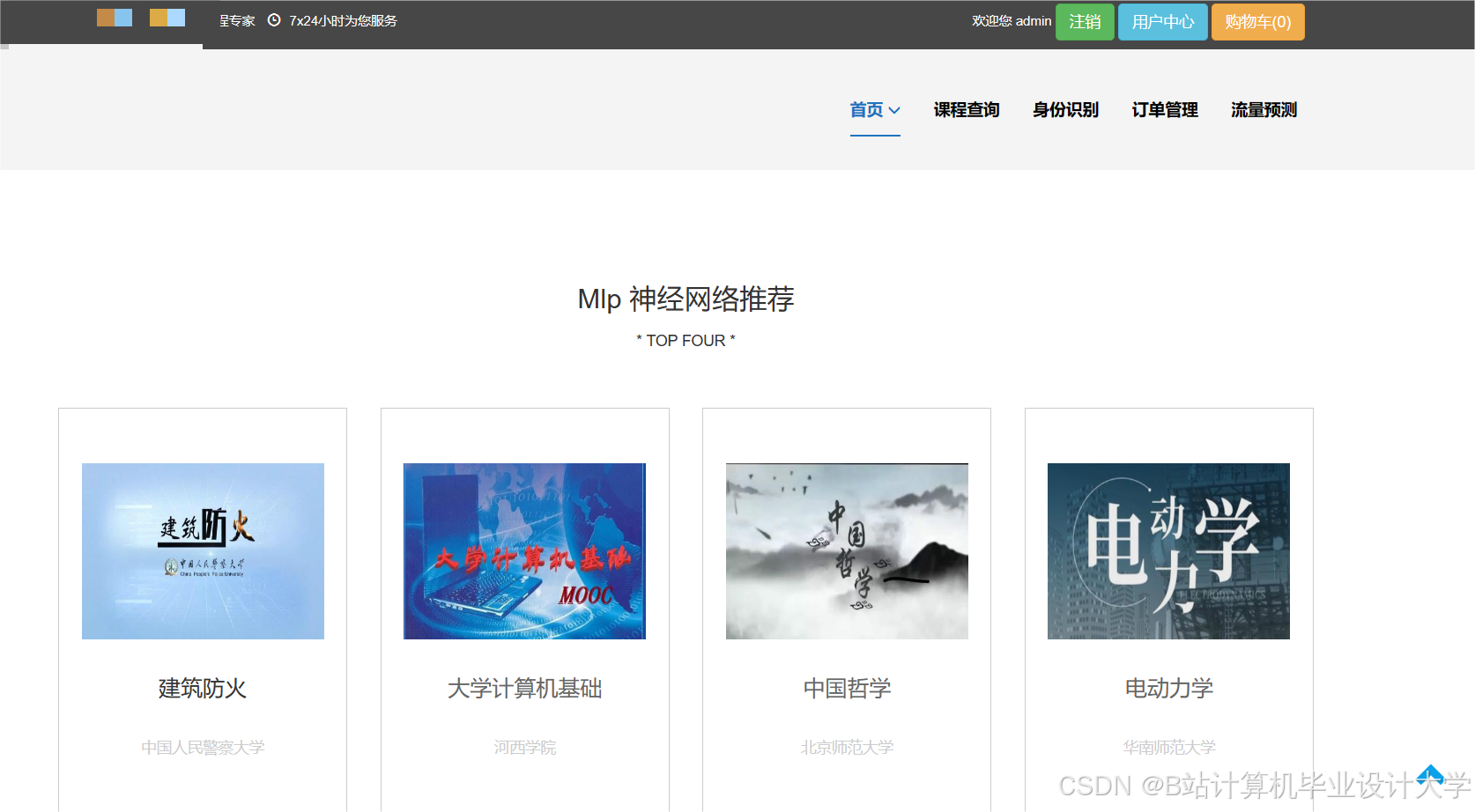
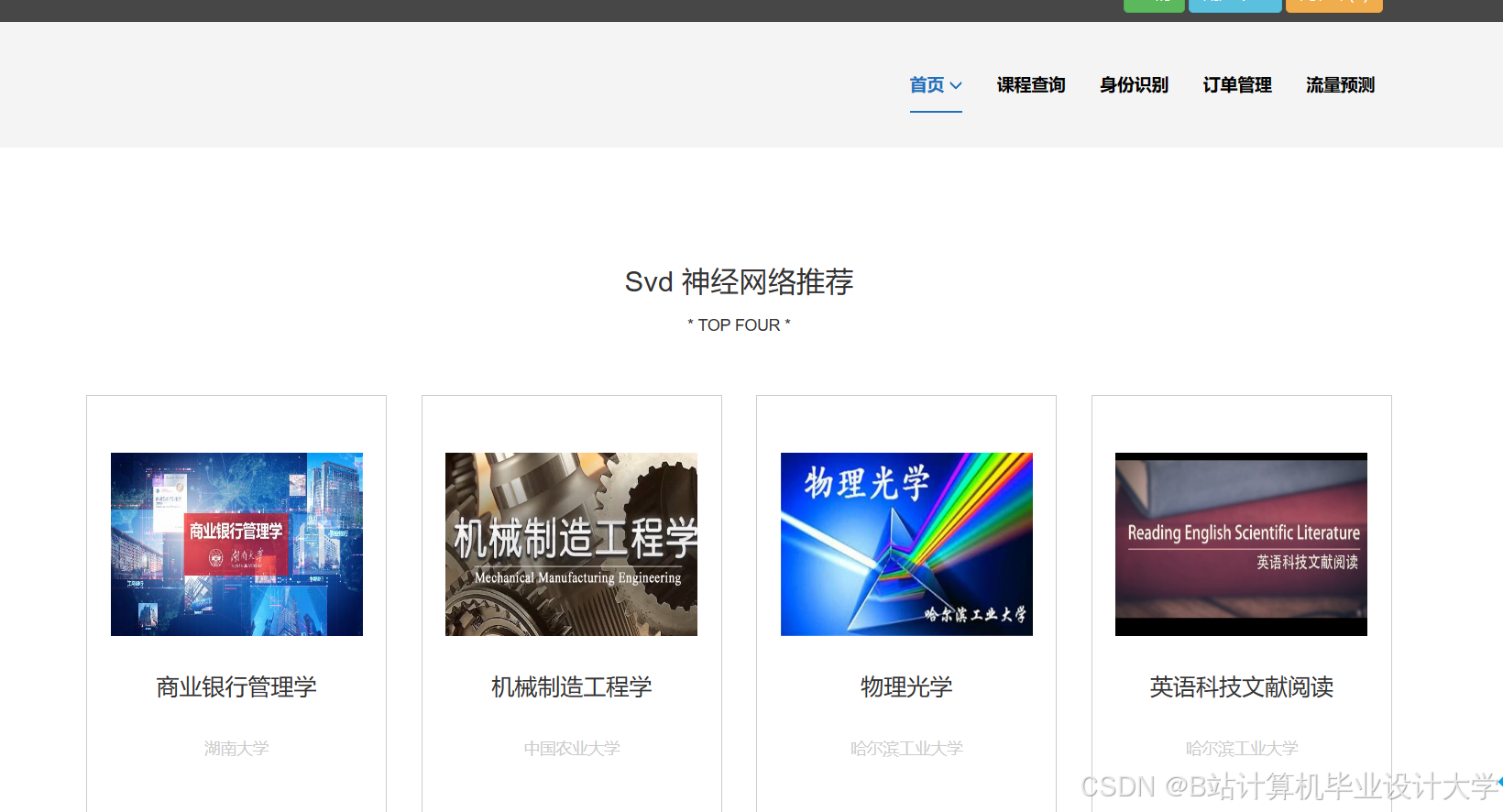
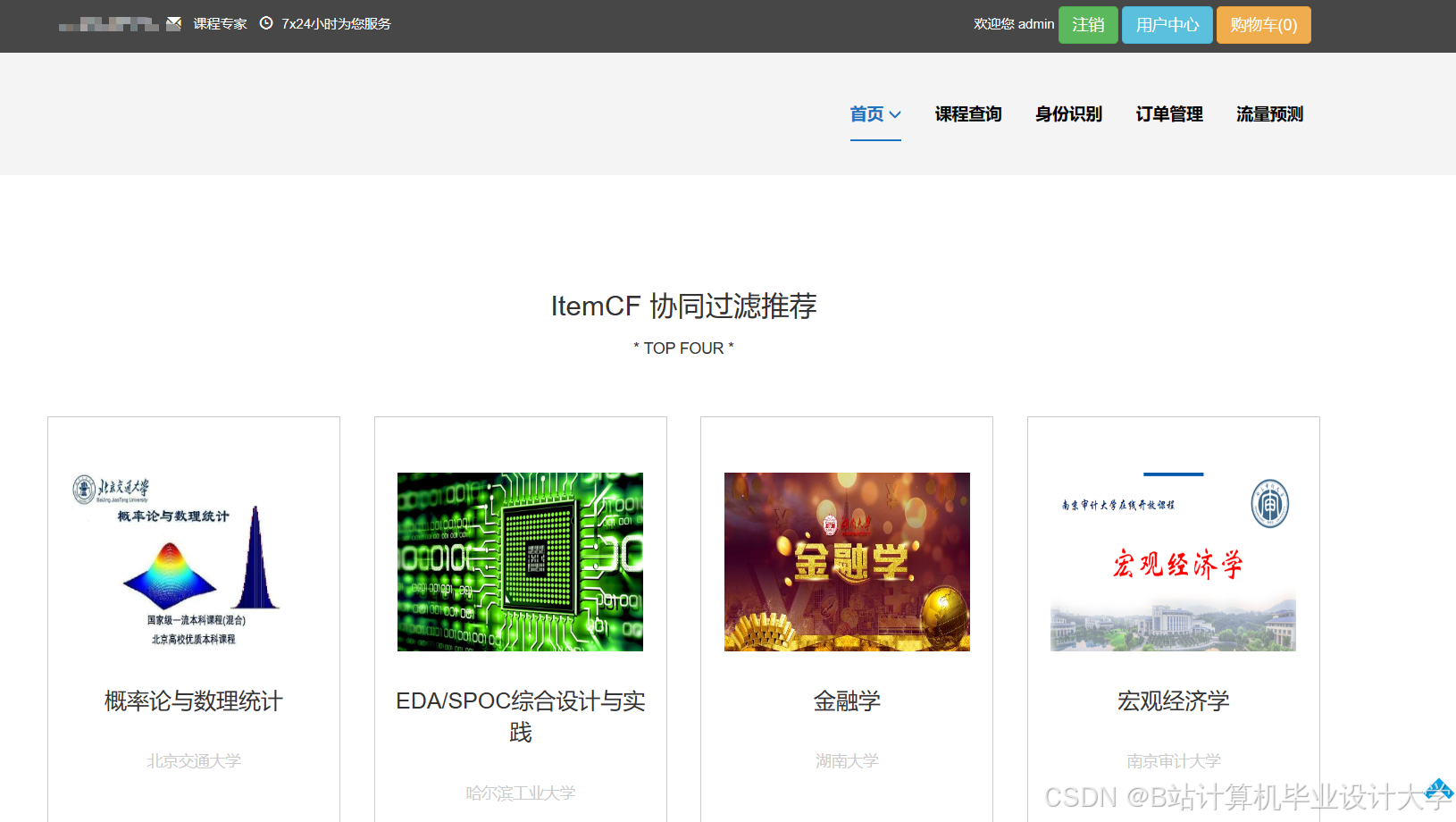
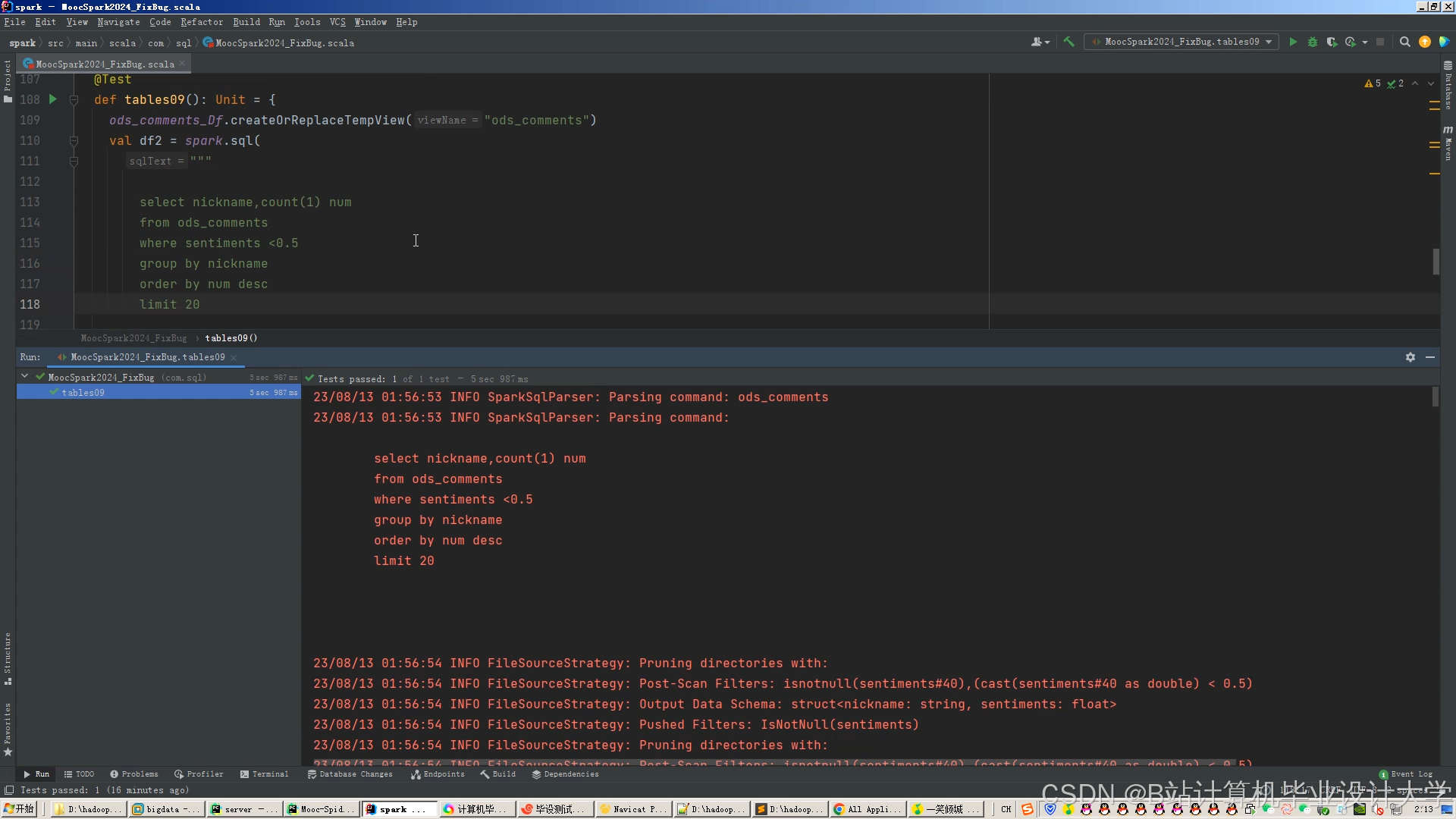
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











