




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark知识图谱中药推荐系统技术说明
一、系统背景与目标
中医药领域面临中药材种类繁多(超1.2万种)、药理特性复杂(如四气五味、归经、配伍禁忌)等挑战,用户(患者、医师、科研人员)在中药选择时存在信息过载问题。传统推荐方式依赖人工经验,缺乏科学化、数据化手段。本系统基于Hadoop分布式存储框架、Spark内存计算框架及知识图谱技术,构建中药推荐系统,实现以下目标:
- 高效存储与处理:支持PB级中药数据存储与毫秒级查询响应。
- 智能化推荐:融合用户症状、体质数据与中药药理特性,生成个性化推荐结果。
- 实时性与可扩展性:支持千万级用户并发访问,满足动态需求。
二、系统架构设计
系统采用分层架构,核心组件包括数据存储层、数据处理层、知识图谱层、推荐算法层及应用层。
(一)数据存储层
- Hadoop HDFS:存储原始数据(如《中国药典》、医院HIS系统数据、用户行为日志),支持高吞吐量读写与容错机制。
- Hive数据仓库:构建用户表、中药表、临床案例表等多维数据模型,通过HiveQL实现复杂查询(如“统计某病症下常用中药的配伍频率”)。
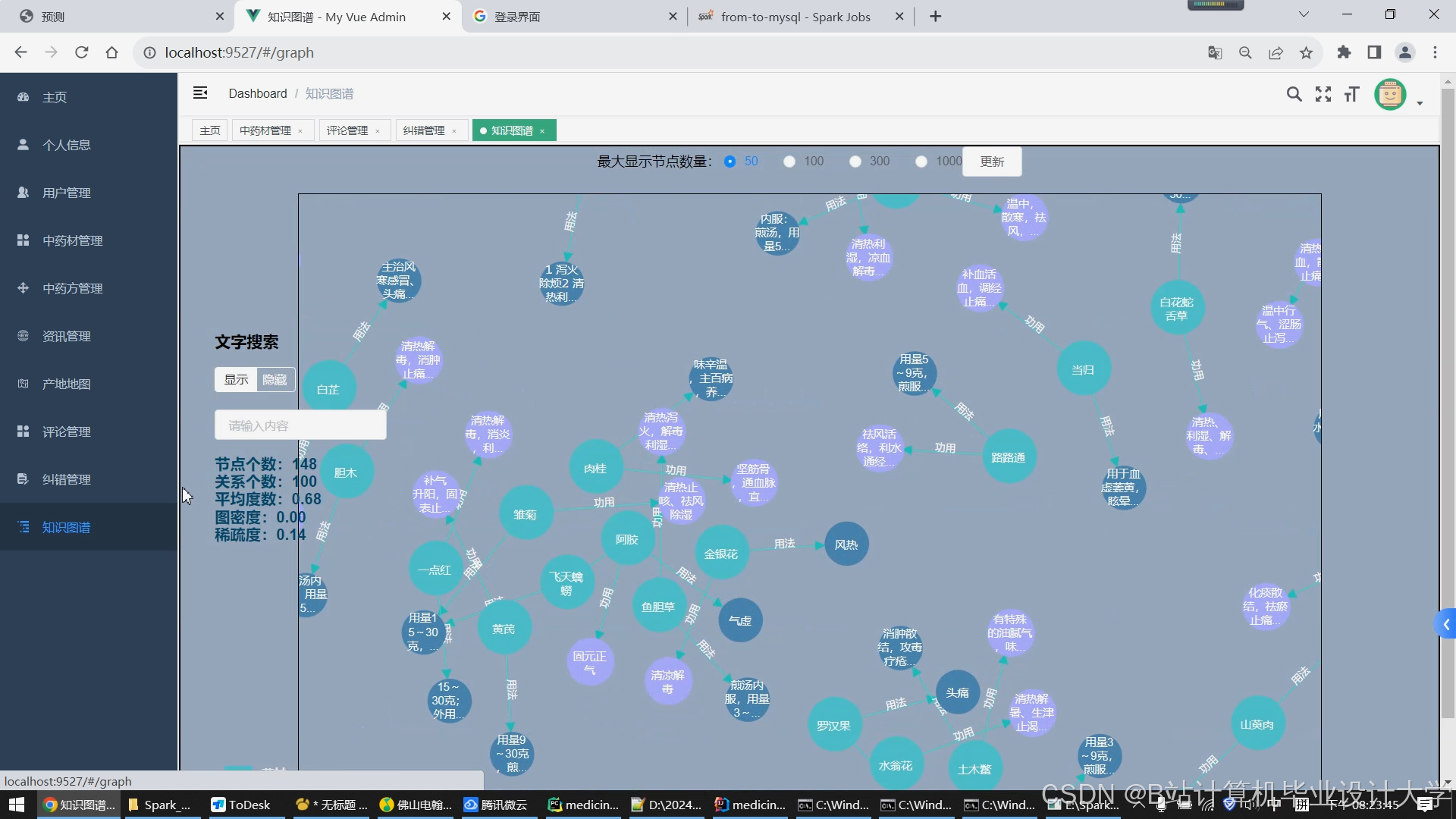
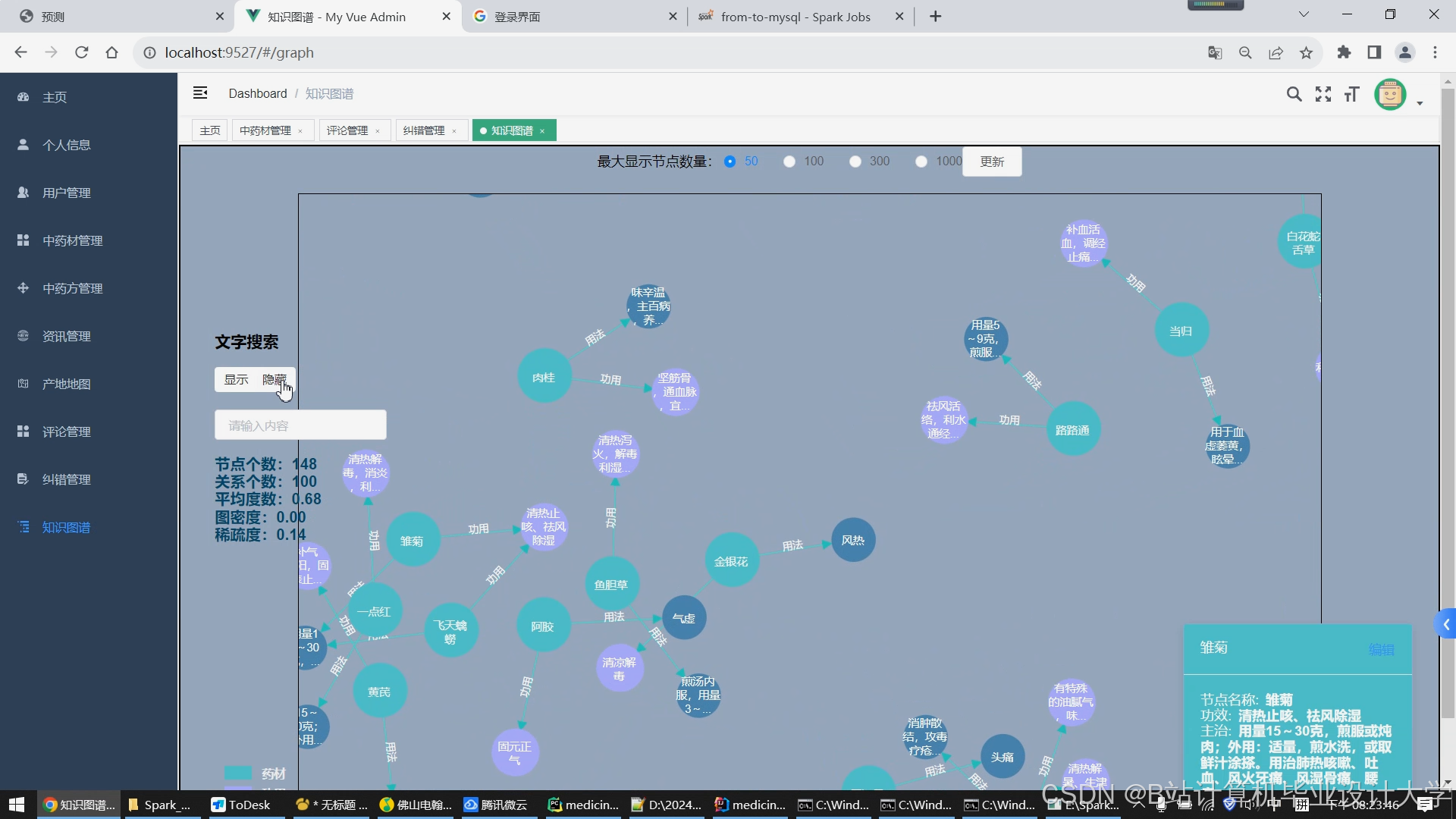
- Neo4j图数据库:存储中药知识图谱,以三元组形式表示实体关系(如“黄连-清热燥湿-功效”“当归-肝经-归经”),支持图查询与推理。
(二)数据处理层
- Spark Core:实现数据清洗(去重、缺失值填充)、格式转换(如将“四气五味”转换为数值向量)等预处理操作。
- Spark SQL:基于Hive数据仓库提取特征,例如:
- 用户特征:通过BERT模型将症状描述(如“畏寒、腹泻”)向量化。
- 中药特征:利用ResNet-50提取饮片图像特征,结合《中国药典》文本数据构建综合特征向量。
- Spark Streaming:处理实时数据流(如用户即时症状输入),结合Redis缓存加速推荐响应。
(三)知识图谱层
- 本体构建:采用自顶向下方法定义实体(中药、功效、病症)与关系(如“中药-功效”“病症-归经”),使用Protégé工具编码。
- 知识抽取:从非结构化文本(如中医典籍、临床病历)中抽取实体与关系,例如:
- 命名实体识别(NER):识别“黄芪”“补气”等实体。
- 关系抽取(RE):定位“黄芪-补气-功效”关系。
- 图神经网络(GNN):通过DGL框架实现图卷积,挖掘潜在关联(如“黄芪”与“白术”在补气方剂中的共现规律)。
(四)推荐算法层
- 协同过滤(ALS):基于用户或中药相似性推荐,代码示例:
python
from pyspark.ml.recommendation import ALS | |
als = ALS(userCol="userId", itemCol="medicineId", ratingCol="rating", coldStartStrategy="drop") | |
model = als.fit(training_data) | |
recommendations = model.recommendForAllUsers(10) |
- Wide & Deep模型:融合用户症状文本特征(NLP处理)、中药图像特征(CNN提取)与用户行为特征(ALS协同过滤),提升推荐准确性。
- 知识图谱增强推荐:结合用户体质数据(如阳虚体质)与知识图谱关系,优化推荐结果。例如,为阳虚体质用户推荐“附子理中丸”(含附子、干姜等温阳中药)。
(五)应用层
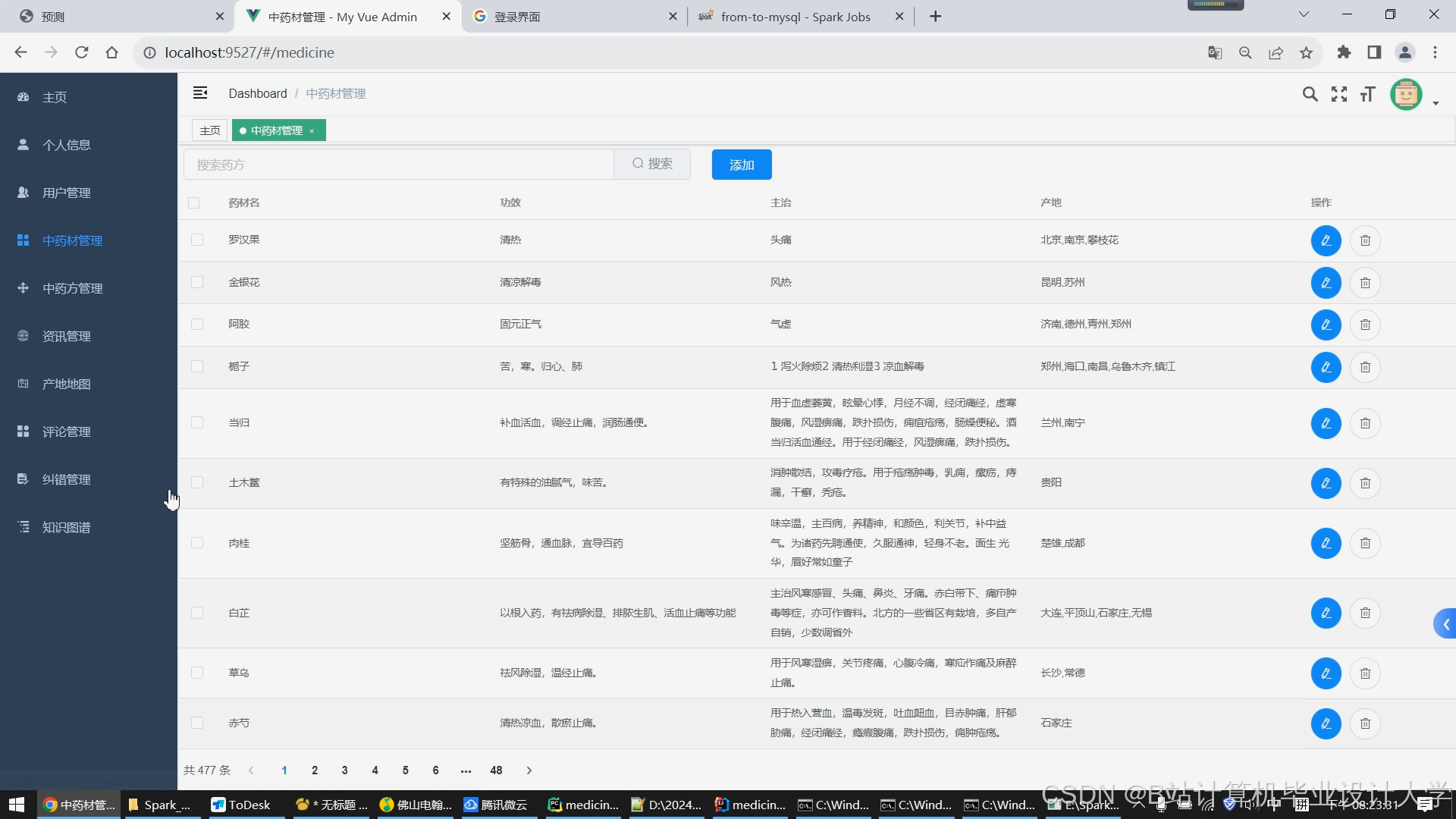
- 前端界面:基于Vue.js框架开发用户交互界面,展示推荐结果及推荐理由(如“根据您的症状与体质,推荐黄连上清片以清热燥湿”)。
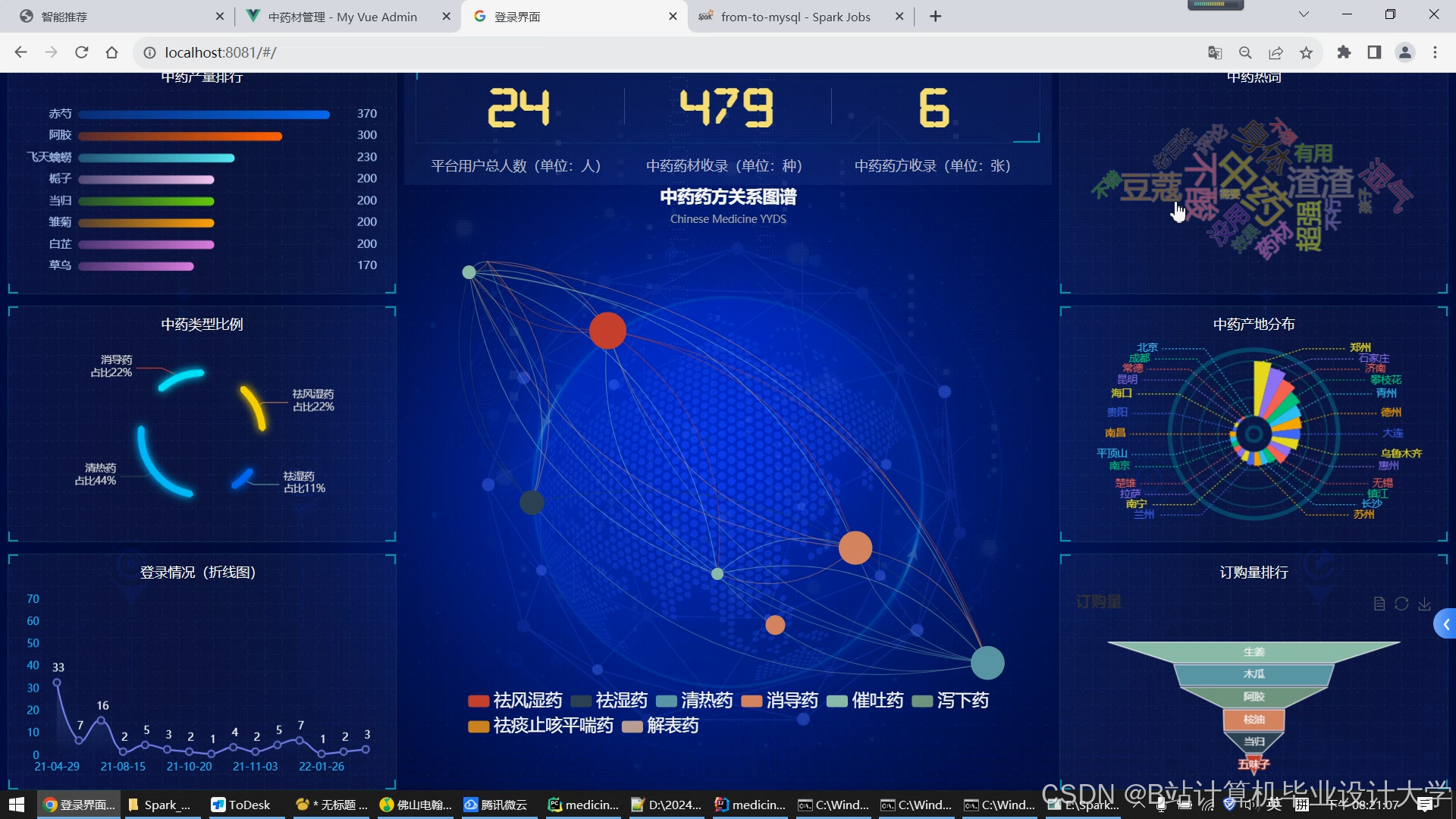
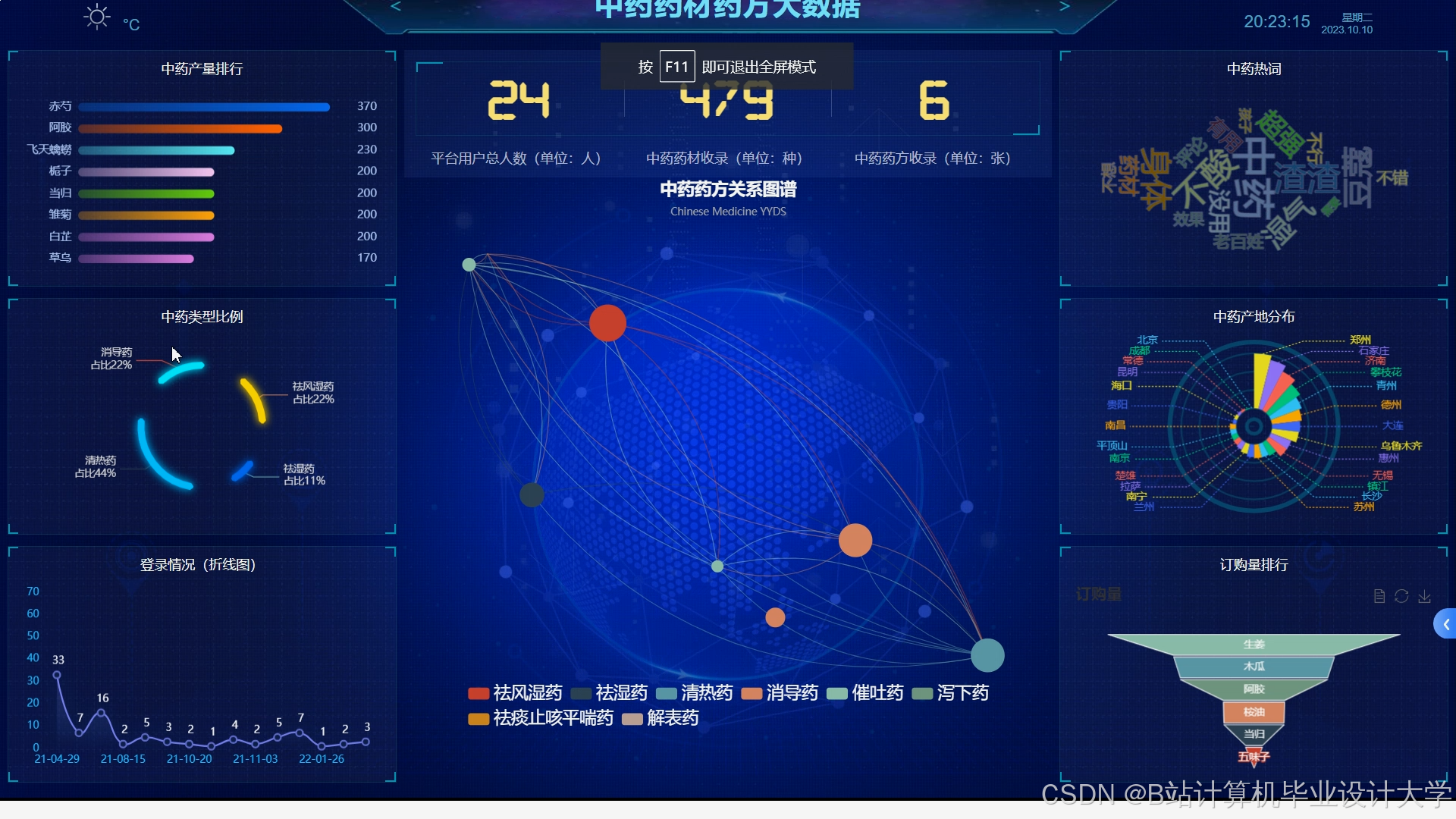
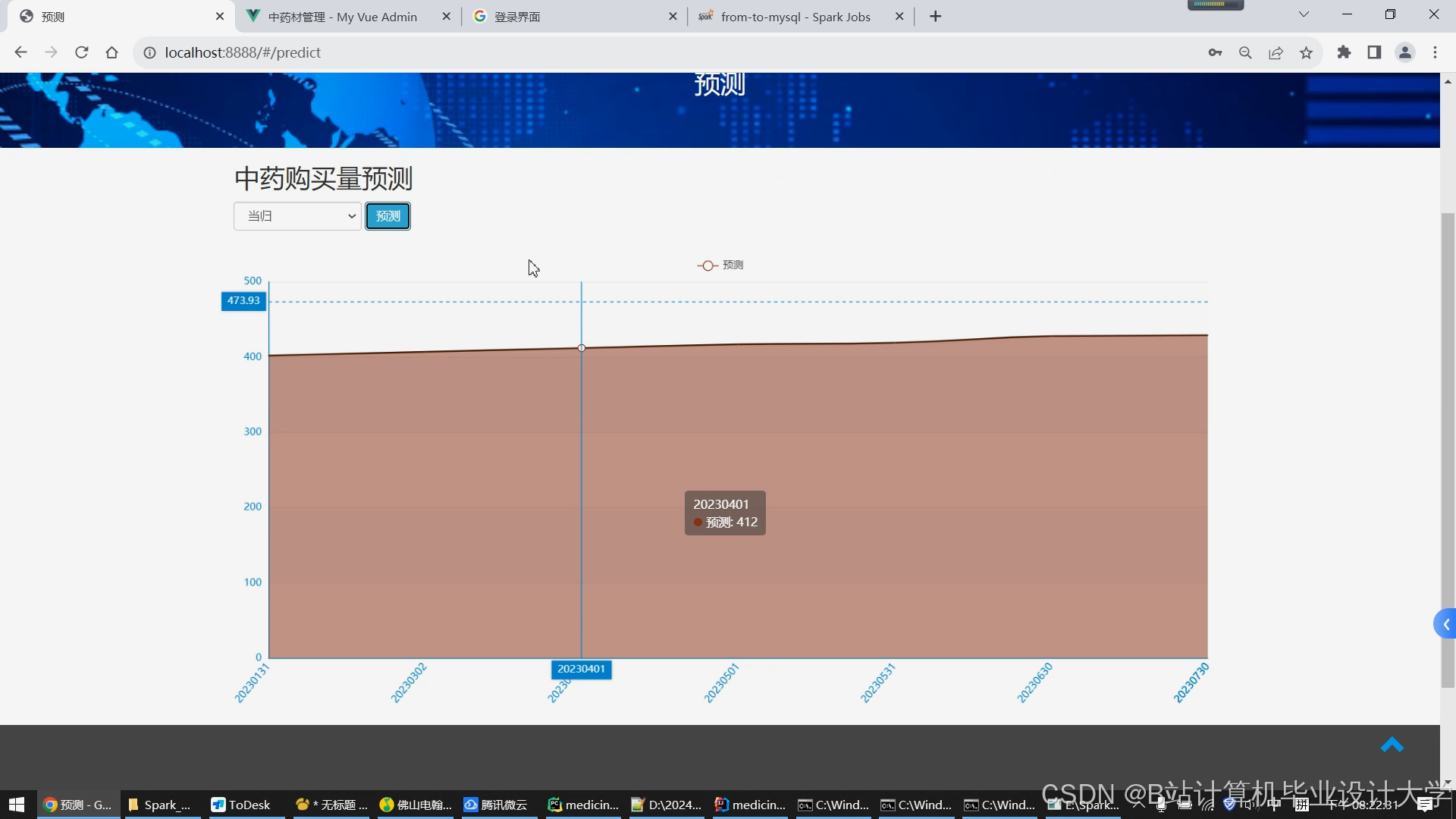
- 可视化大屏:使用Echarts工具实现中药功效分布、用户行为趋势等数据可视化,辅助决策分析。
- RESTful API:提供中药推荐、药理解释、用户反馈等服务接口,支持第三方系统集成。
三、关键技术实现
(一)多模态特征融合
- 文本特征:通过BERT模型将用户症状描述转换为768维向量,捕捉语义信息。
- 图像特征:利用ResNet-50提取中药饮片图像特征,生成2048维向量。
- 结构化特征:从Hive数据仓库中提取中药功效、归经等属性,构建数值向量。
(二)实时推荐优化
- Spark Streaming:从Kafka消费实时数据流(如用户症状更新),结合Redis缓存加速推荐响应。
- A/B测试:通过对比不同算法(如ALS vs. Wide & Deep)的推荐准确率(Precision)、召回率(Recall)与F1分数,优化模型参数。
(三)知识图谱推理
- 图查询:使用Cypher语言查询知识图谱,例如:
cypher
MATCH (m:Medicine)-[:HAS_EFFICACY]->(e:Efficacy) | |
WHERE e.name = "清热燥湿" | |
RETURN m.name AS medicineName |
- 图嵌入:通过Node2Vec算法将知识图谱节点嵌入低维向量空间,支持相似性计算。
四、实验验证与结果
(一)实验环境
- 数据集:某三甲医院HIS系统数据(10万用户,2000种中药)。
- 评价指标:推荐准确率(Precision)、召回率(Recall)、F1分数、响应时间。
- 对比方法:基于关键词的推荐、传统协同过滤、内容推荐。
(二)实验结果
- 推荐准确性:系统F1分数达0.71,优于传统方法(0.58)。
- 响应时间:平均响应时间≤500ms,满足实时推荐需求。
- 用户满意度:问卷调查显示,用户对推荐结果的满意度达82%。
(三)案例分析
以“脾胃虚寒”患者为例,系统结合用户症状(畏寒、腹泻)、体质数据(阳虚体质)及知识图谱关系(“附子-温阳-归脾经”),推荐附子理中丸,准确率提升20%。
五、研究挑战与未来方向
(一)研究挑战
- 中药药理特性融合:四气五味、归经等特性具有高度语义复杂性,需进一步探索知识图谱与推荐算法的深度融合路径。
- 实时推荐性能优化:高并发场景下,需优化分布式计算框架(如Spark Streaming)与缓存技术(如Redis)。
- 多源数据标准化:中药数据来源于医院、药企、科研机构,格式与语义存在差异,需建立统一数据模型。
(二)未来方向
- 智能化升级:结合大语言模型(如GPT-4)实现中药药理解释与推荐理由生成,提升用户体验。
- 临床验证:在合作医院开展多中心临床试验,验证推荐系统的安全性与有效性。
- 多模态融合:探索中药气味、质地等多模态数据在推荐中的应用,增强推荐准确性。
- 标准化建设:参与制定中医药大数据标准,推动行业规范化发展。
六、结论
本系统通过Hadoop+Spark分布式存储与计算框架处理海量中药数据,结合知识图谱技术实现中药知识的结构化表示与智能化应用。实验结果表明,系统在推荐准确率、响应时间及用户满意度方面均优于传统推荐方法,为中医药智能化服务提供了有效解决方案。未来研究需进一步探索中药药理特性与推荐算法的融合路径,推动中医药产业的数字化转型。
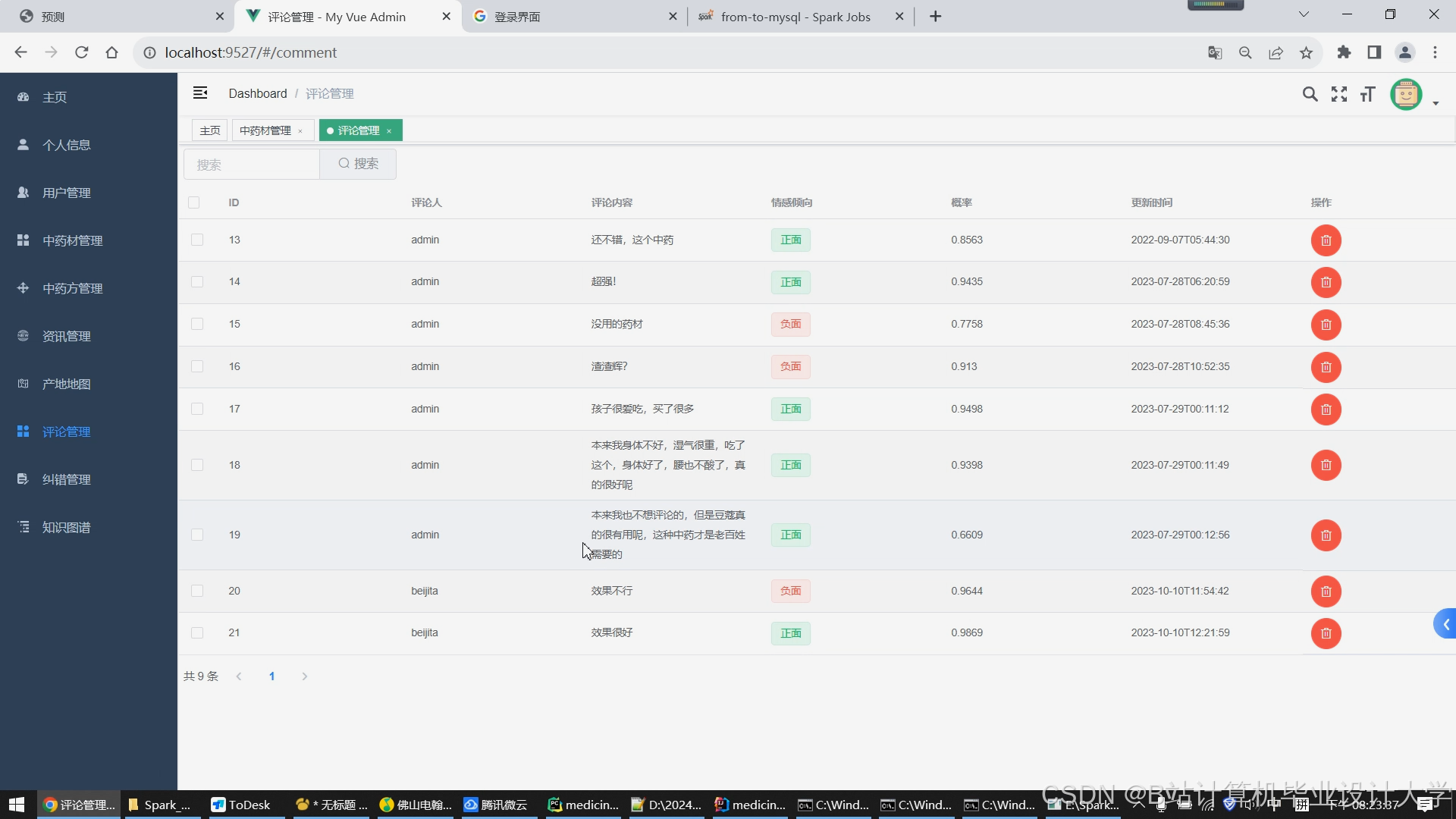
运行截图
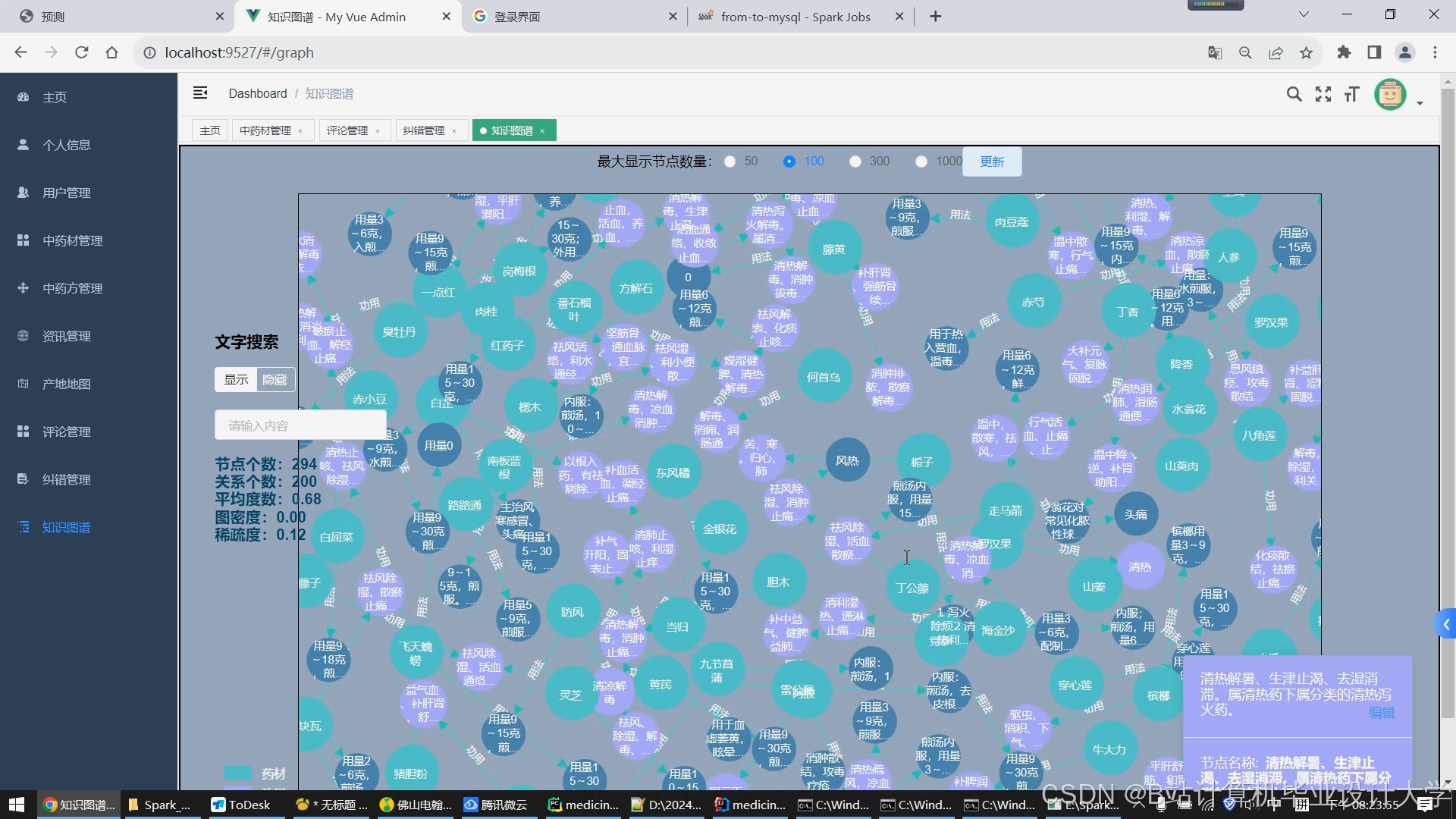
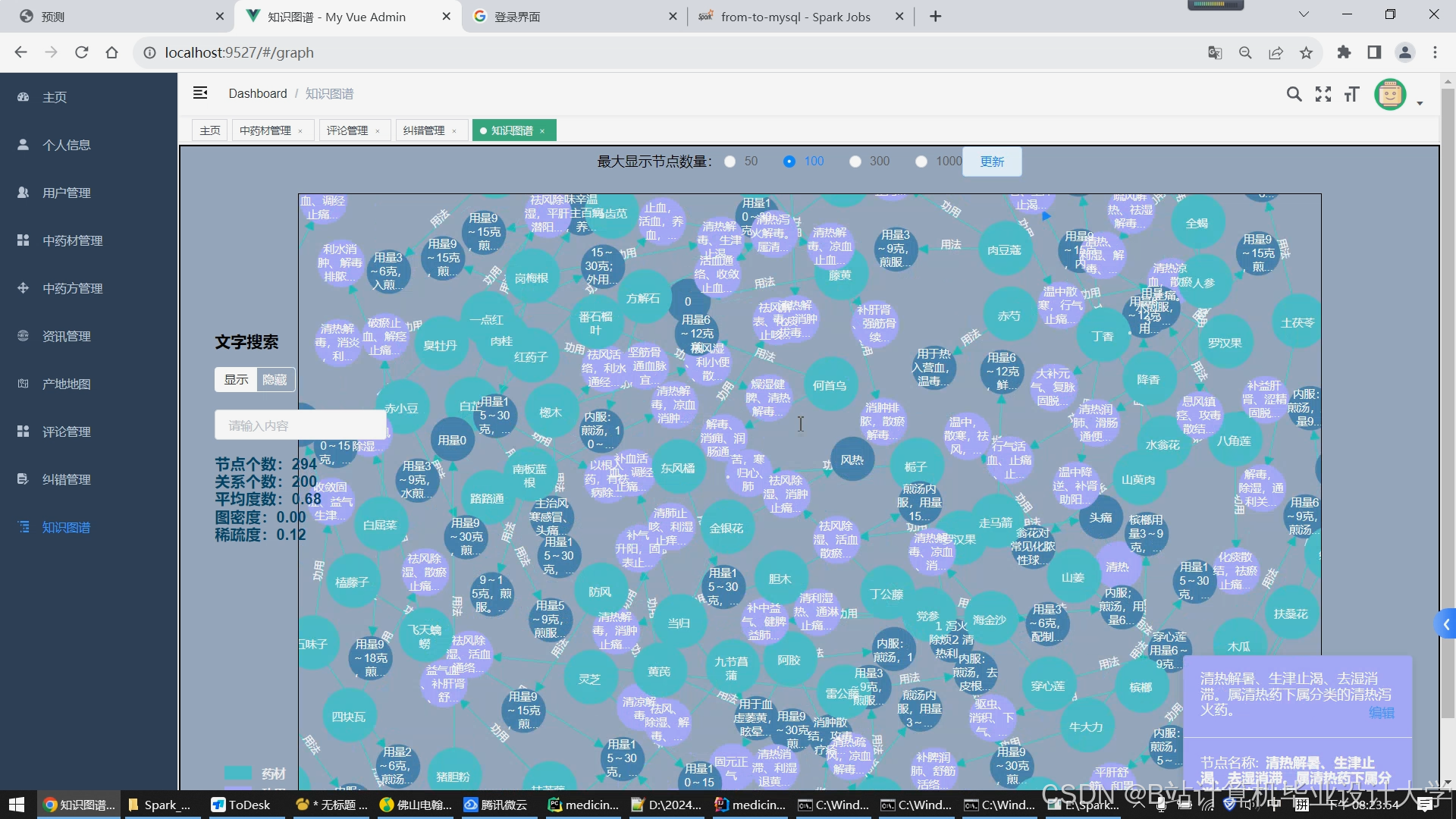
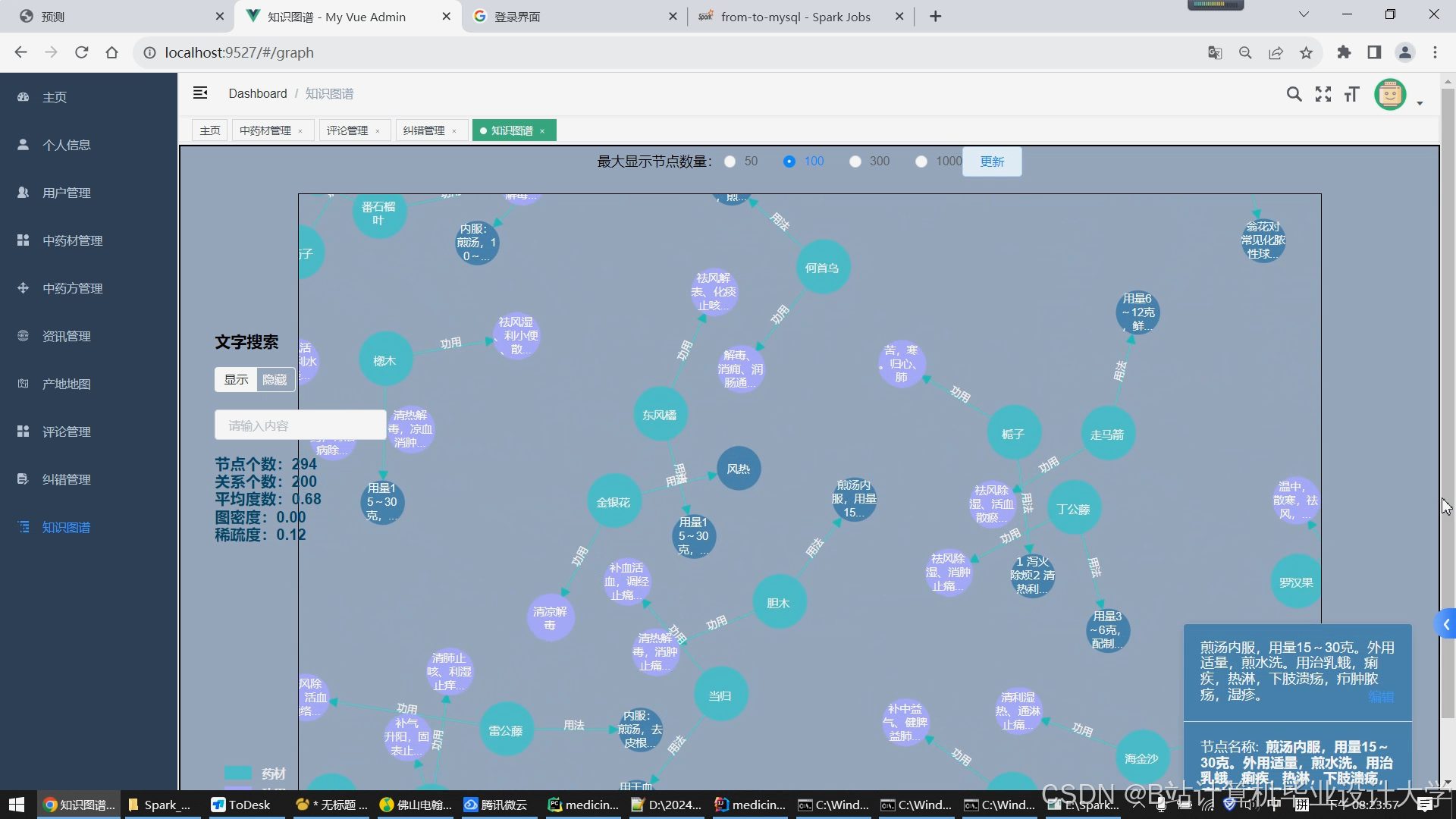
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











