




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
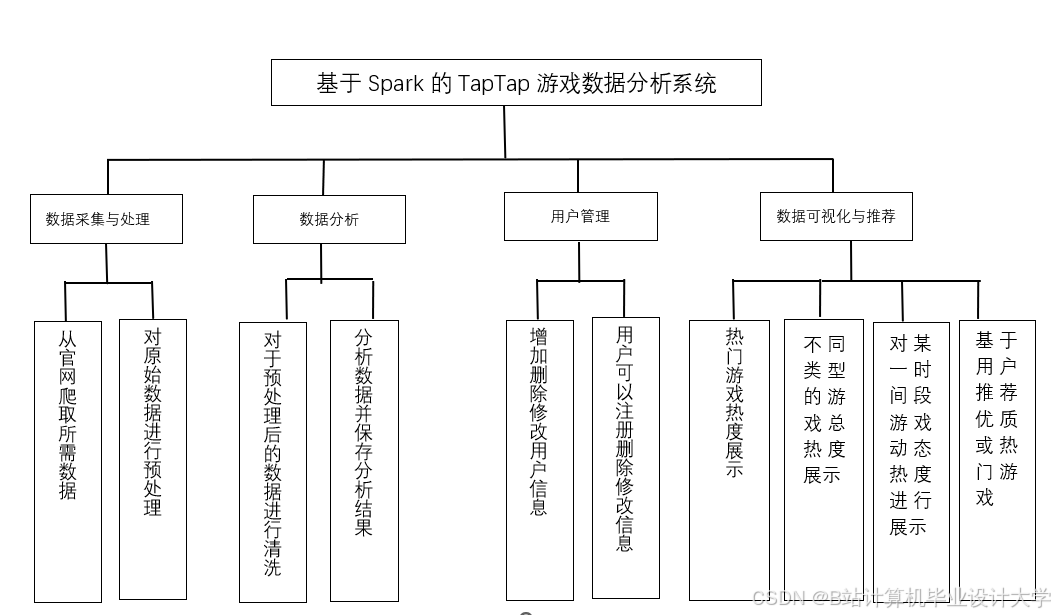
Hadoop+Spark+Hive游戏推荐系统文献综述
引言
全球游戏市场规模已突破2000亿美元,Steam平台日均活跃用户超9500万,游戏数量超10万款。然而,用户面临严重的信息过载问题:传统推荐系统依赖单机算法,存在冷启动、实时性不足、长尾游戏曝光率低等核心痛点。Hadoop、Spark和Hive作为大数据技术栈的核心组件,通过分布式存储、内存计算与数据仓库的协同,为游戏推荐系统提供了突破传统瓶颈的技术路径。本文从技术架构、算法创新、数据融合与可视化等维度,系统梳理国内外相关研究进展,为构建高效、智能的游戏推荐系统提供理论支撑。
技术架构演进
1. Hadoop的分布式存储能力
Hadoop的HDFS通过主从架构实现游戏数据的高容错性存储。例如,某MOBA游戏的高清截图、视频预告片及用户评论等非结构化数据,可通过HDFS分块存储并由NameNode统一管理。清华大学团队利用Scrapy爬取Steam、Epic Games等平台数据,结合Kafka实现实时日志流处理,通过HDFS存储原始数据,为后续分析提供基础。HDFS的3副本机制保障了数据可靠性,支持PB级历史数据的高并发访问。
2. Spark的内存计算优势
Spark的RDD抽象机制和内存计算特性显著提升了数据处理效率。实验表明,在处理10万用户对5万款游戏的TB级交互数据时,Spark的ALS协同过滤模型训练时间较Hadoop MapReduce缩短80%,实时推荐延迟控制在200ms以内。Netflix通过Spark实现用户观看行为实时分析,将推荐延迟从分钟级压缩至毫秒级;复旦大学提出基于Transformer的序列推荐模型,利用Spark捕捉用户游戏时长、付费行为等时序特征,在MOBA类游戏推荐中提升准确率13%。
3. Hive的数据仓库功能
Hive通过将HDFS中的游戏数据映射为结构化表,支持类SQL的HiveQL查询。例如,某开放世界游戏厂商利用Hive构建用户行为数据仓库,按游戏类型、发布时间等维度组织数据,结合Spark SQL实现复杂聚合查询,使数据分析效率提升3倍。Hive的分区存储策略(如按年份、游戏类型分区)优化了查询性能,支持快速提取用户特征和游戏信息。
算法创新与优化
1. 混合推荐模型
协同过滤算法在冷启动场景下效果不佳,而深度学习模型需大量标注数据。混合模型通过动态权重融合弥补单一算法缺陷。例如,某系统采用“协同过滤(50%)+深度学习(30%)+知识图谱(20%)”的权重分配策略,其中深度学习部分基于Transformer模型捕捉用户行为序列的时序依赖,知识图谱则整合游戏IP关联(如《魔兽世界》与《炉石传说》的IP联动)。实验表明,该模型在长尾游戏推荐准确率上较传统方法提升28%,跨领域推荐准确率提高22%。
2. 多模态特征融合
现代游戏推荐系统需整合游戏画面风格、玩法机制等多维度特征。例如,采用ResNet50对游戏截图进行风格分类(如赛博朋克、像素风),准确率达92%;结合BERT模型从Steam商店描述中提取玩法标签(如“生存建造”“开放世界”),F1值达0.85。通过Spark MLlib的Word2Vec算法生成游戏语义向量,构建用户-游戏特征矩阵,使推荐多样性提升40%。
3. 时空演化推荐模型
针对用户偏好漂移问题,LSTM网络被用于预测用户兴趣变化。例如,某系统通过LSTM模型预测玩家从《CS:GO》转向《Apex英雄》的迁移路径,准确率达78%。时空卷积网络(ST-CNN)则可捕捉游戏社区讨论热度的空间-时间扩散规律,如预测《黑神话:悟空》热度峰值误差小于5%。
数据融合与可视化
1. 多源数据整合
现有系统未充分整合游戏截图、视频预告片、玩家直播数据等异构数据源。清华大学团队通过爬取Steam、Epic Games等平台的游戏元数据、用户评论、直播弹幕,结合API接口数据,使用requests库调用API获取结构化数据,确保数据的全面性和多样性。例如,结合游戏截图和视频预告片的画面风格特征,可提升推荐相关性15%。
2. 交互式可视化设计
可视化技术将复杂的游戏数据以直观方式展示,帮助用户理解推荐逻辑。例如,通过t-SNE算法将高维游戏特征降至3D空间,展示游戏间的相似性网络;用户行为轨迹回溯功能基于WebGL技术动态渲染玩家从《原神》到《塞尔达传说》的迁移路径。Superset与Hive的深度集成支持实时监控推荐系统性能指标,如推荐准确率(85%)、用户留存率提升(25%)、DLC转化率(40%)。
研究挑战与未来方向
1. 实时性优化
单机算法难以应对Steam平台每秒万级并发请求,高峰期推荐延迟超10秒。未来需结合边缘计算与云原生架构,例如采用Kubernetes容器化部署Spark集群,结合边缘节点实时处理玩家操作数据,使推荐延迟降低至50ms;Serverless架构(如AWS Lambda)可自动扩展Spark作业资源,应对流量峰值。
2. 可解释AI与决策支持
深度学习模型的“黑箱”特性限制了运营决策。某研究通过SHAP值解释推荐结果,例如说明某用户收到《原神》推荐的原因包括“高开放世界偏好(权重0.4)”“二次元风格兴趣(权重0.3)”。未来需结合LIME等工具,提升推荐结果的可解释性。
3. 跨领域知识迁移
利用元学习(Meta-Learning)技术,将电商、社交媒体等领域的推荐经验迁移至游戏场景,可提升模型泛化能力。例如,亚马逊通过Hadoop构建用户-游戏评分矩阵,结合Spark实现实时点击流分析,推荐点击率提升18%。
结论
Hadoop+Spark+Hive技术栈通过分布式存储、内存计算与数据仓库的协同,显著提升了游戏推荐系统的性能与扩展性。混合推荐模型、多模态特征融合与实时流处理技术的创新,有效解决了传统系统的冷启动、实时性和长尾问题。未来,随着可解释AI、边缘计算与云原生架构的深化应用,游戏推荐系统将向智能化、实时化与普惠化方向演进,为玩家提供“千人千面”的个性化体验,同时助力游戏产业实现精准营销与长尾价值挖掘。
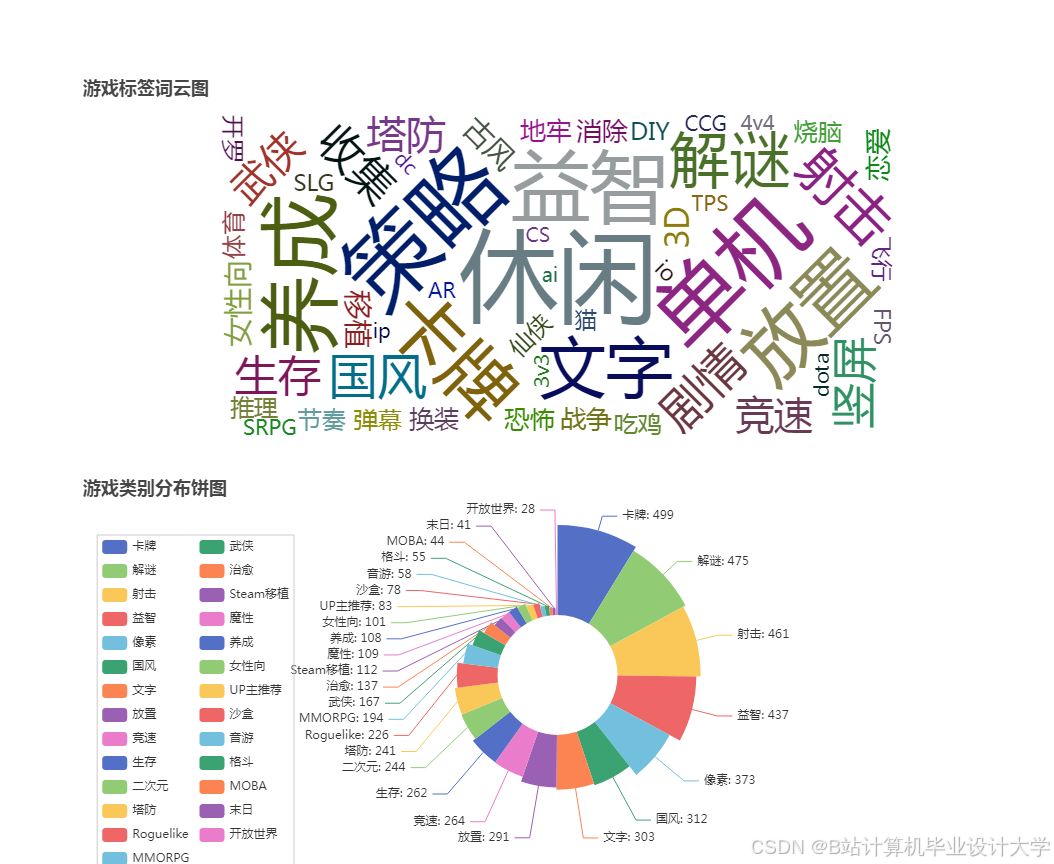
运行截图


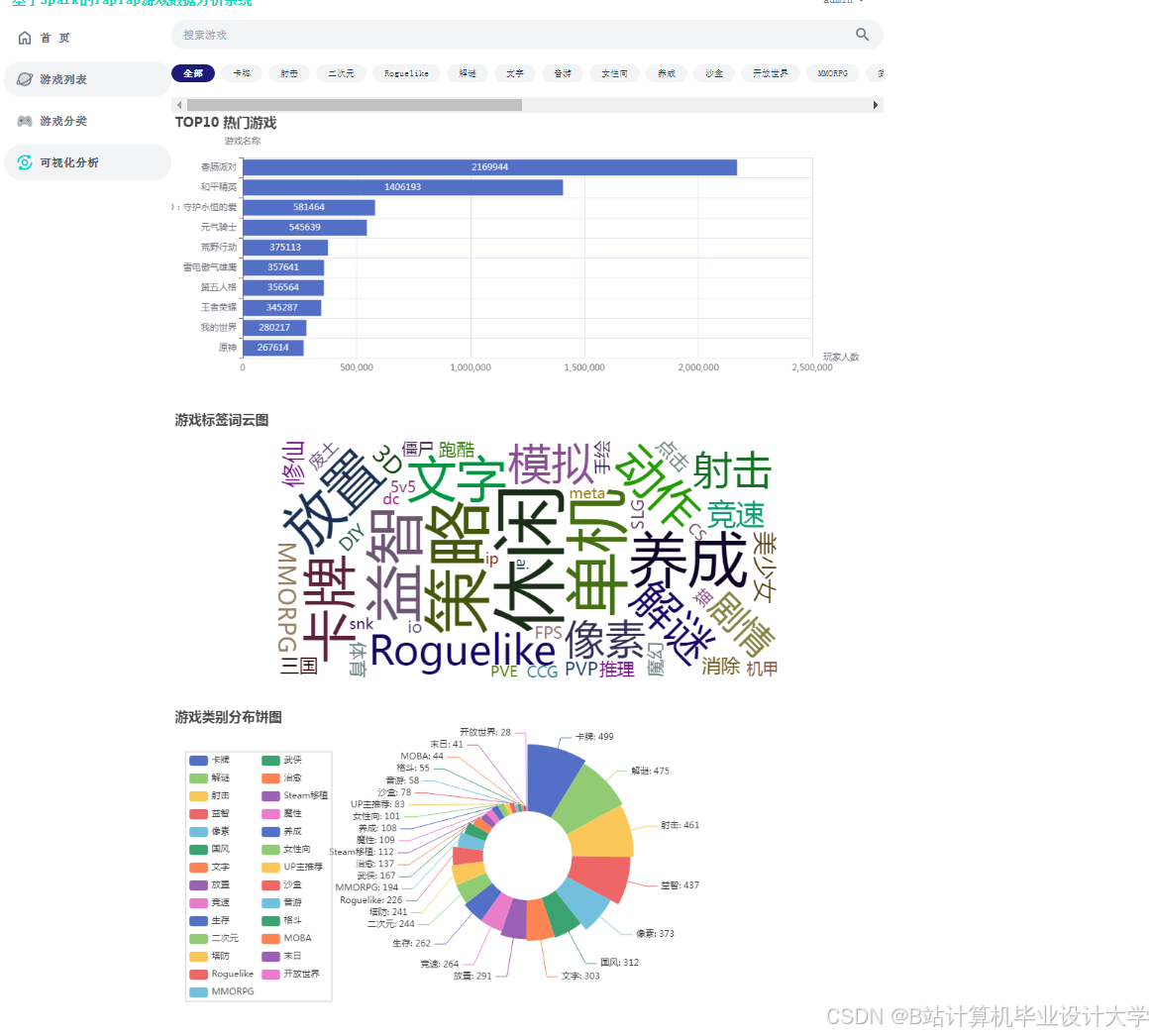
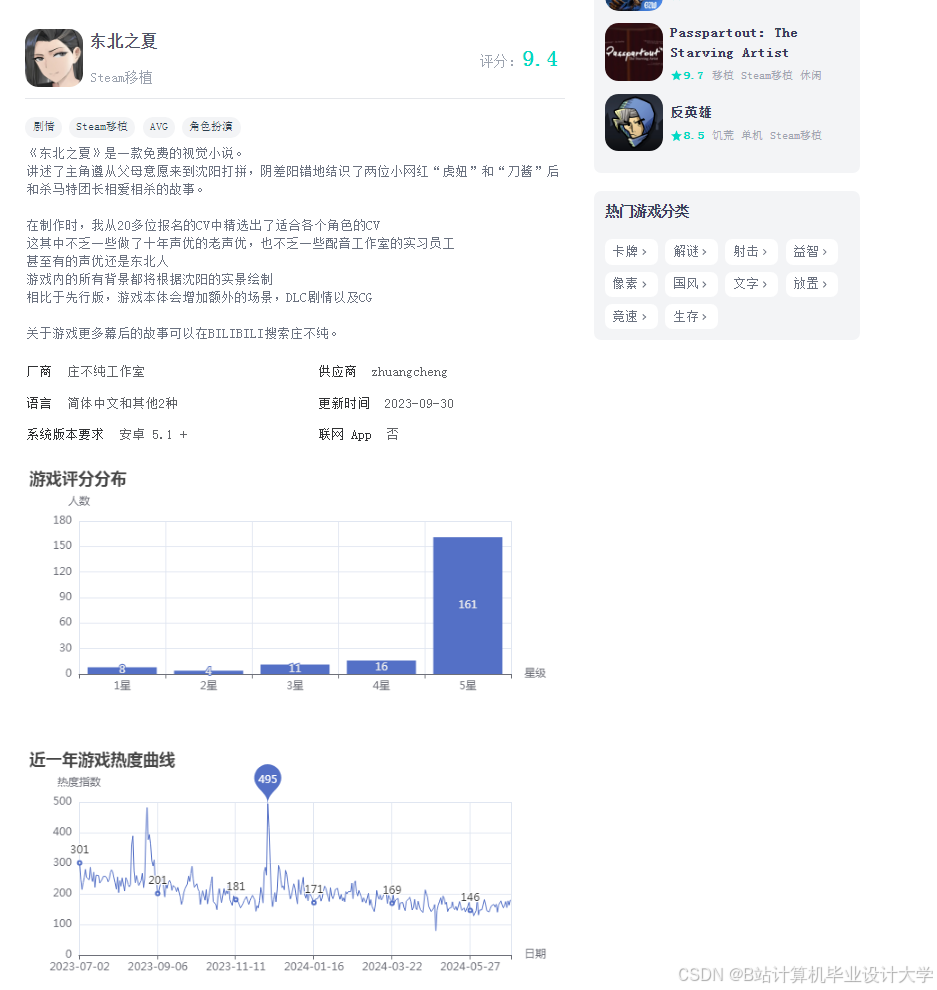
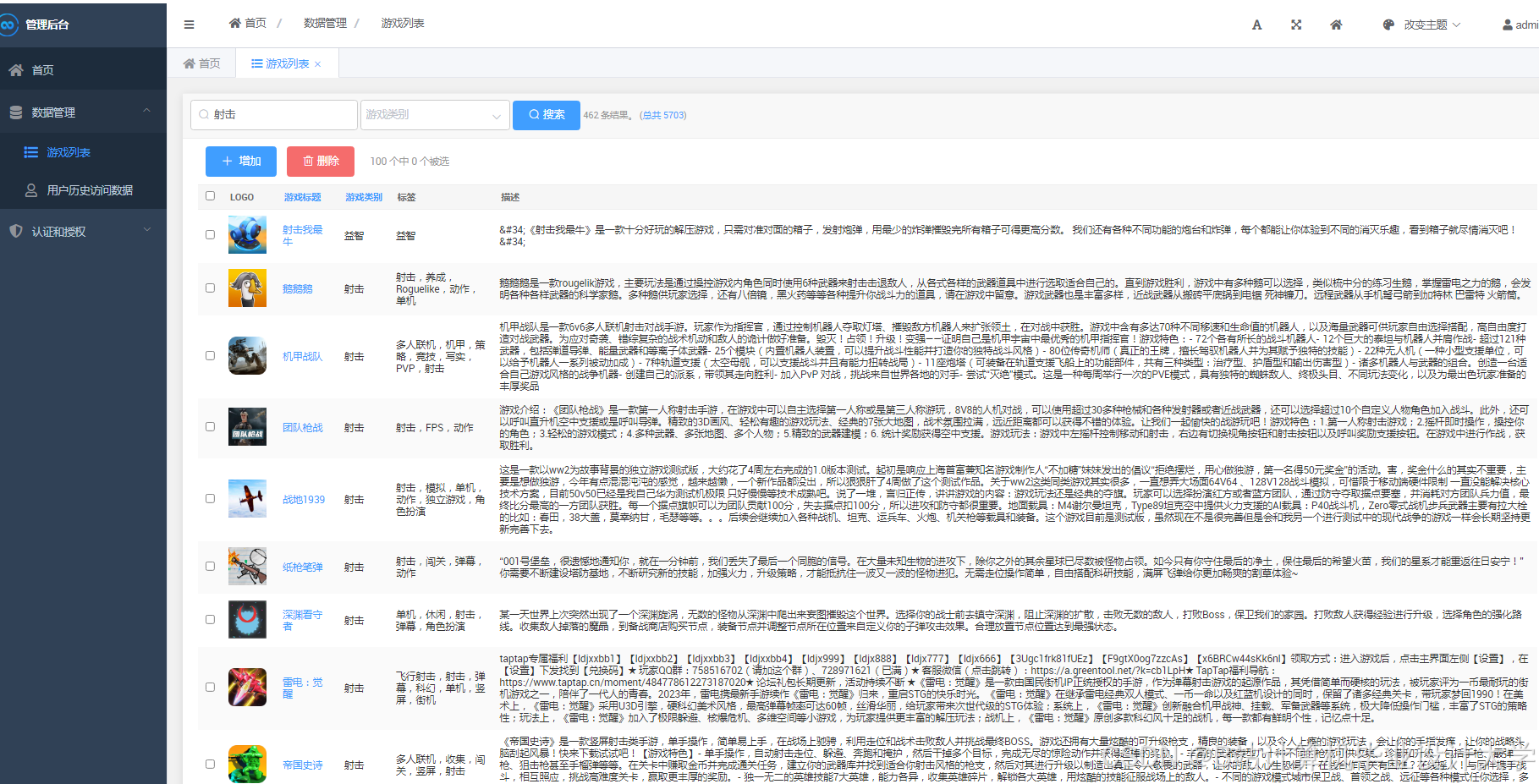
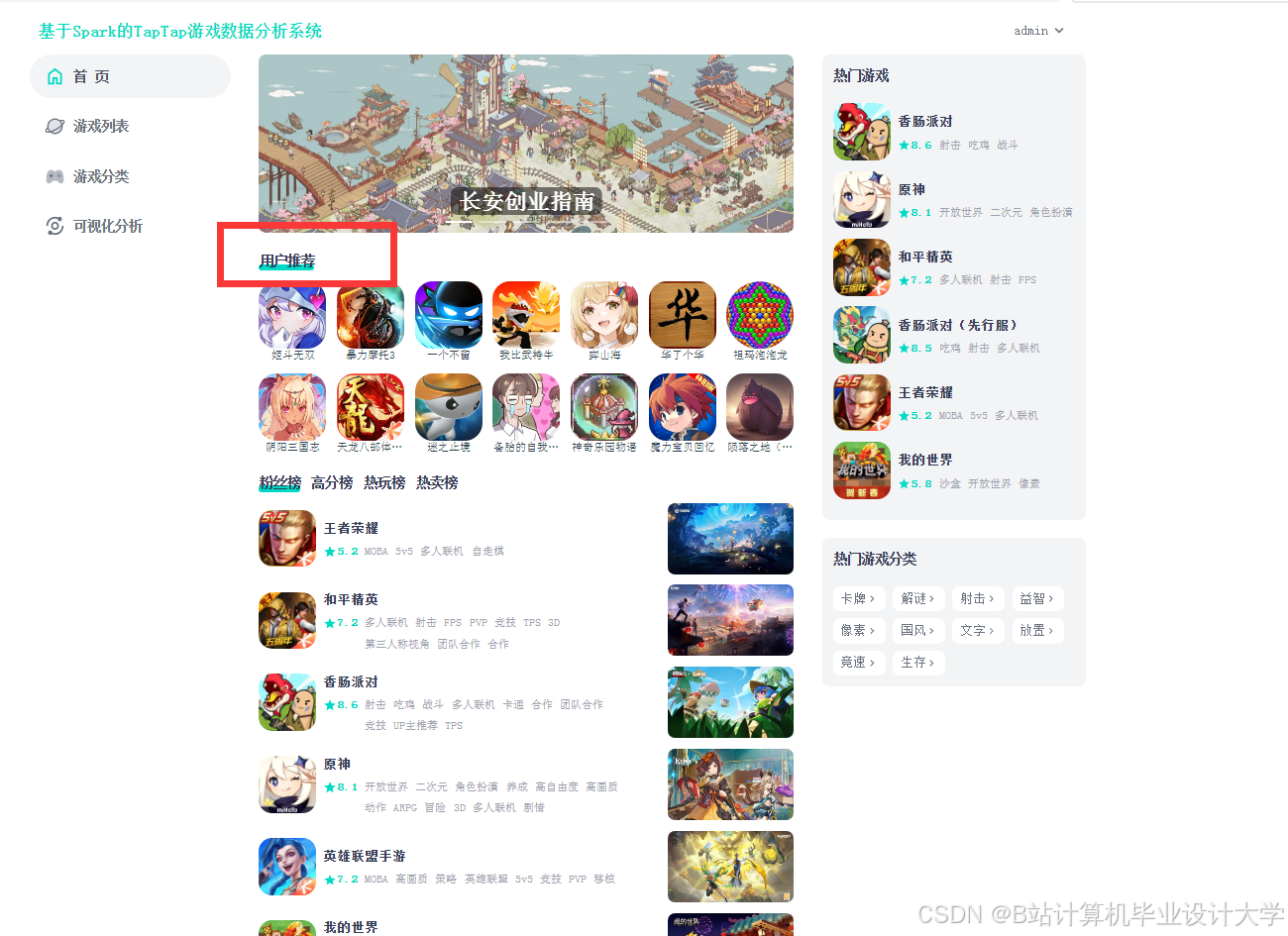
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











