




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+PySpark+Hadoop高考分数线预测与高考推荐系统技术说明
一、系统概述
本系统基于Python的灵活数据处理能力、PySpark的分布式计算框架和Hadoop的高扩展性存储,构建了一个集成高考分数线预测与志愿推荐功能的智能平台。系统通过整合多源数据(院校信息、历年分数线、考生行为等),利用协同过滤、内容推荐和深度学习算法,为考生提供个性化志愿填报建议,同时通过LSTM模型实现分数线动态预测,辅助科学决策。
二、技术架构
系统采用分层架构设计,涵盖数据采集、存储、处理、算法与应用五个核心模块,各模块技术选型与功能如下:
2.1 数据采集层
- 技术工具:Scrapy(爬虫框架) + 定时任务调度(Airflow)
- 功能实现:
- 从教育部官网、高校招生网站、教育资讯平台等抓取院校信息(地理位置、学科排名)、专业信息(培养目标、就业方向)、历年分数线数据(分省、分批次)。
- 采集考生行为数据(模拟成绩、兴趣测评、志愿填报历史记录)及设备信息(IP地址、浏览器类型)。
- 通过Airflow设置定时任务,每日凌晨更新数据,确保时效性。
2.2 数据存储层
- 技术工具:Hadoop HDFS(分布式存储) + Hive(数据仓库) + HBase(实时查询)
- 功能实现:
- HDFS:存储原始爬取数据(如HTML文件、JSON日志),支持PB级数据扩展。
- Hive:构建结构化数据仓库,按年份、地区、院校类型分区存储清洗后的数据,支持SQL查询(如
SELECT * FROM scores WHERE year=2024 AND province='北京')。 - HBase:存储考生实时行为数据(如最近浏览的10个专业),通过RowKey(用户ID+时间戳)实现毫秒级检索。
2.3 数据处理层
- 技术工具:PySpark(分布式计算) + Spark SQL(结构化查询)
- 功能实现:
- 数据清洗:使用PySpark的DataFrame API过滤异常值(如单日浏览量>1000次的记录),通过KNN插值法填充缺失的分数线数据。
- 特征提取:
- 考生特征:将兴趣测评文本通过TF-IDF向量化,结合成绩等级(如一本线±10%)生成数值特征。
- 院校特征:利用Word2Vec将专业介绍文本转换为128维向量,结合学科评估结果(如A+、A)构建特征矩阵。
- 数据转换:将清洗后的数据存储为Parquet格式,压缩率达75%,减少存储空间并加速查询。
2.4 算法层
- 技术工具:PySpark MLlib(机器学习库) + TensorFlow/Keras(深度学习)
- 功能实现:
- 分数线预测:
- LSTM模型:输入历史5年分数线、招生计划数、考生人数等时间序列数据,输出下一年预测值。通过注意力机制动态调整权重,提升对关键因素(如试题难度突变)的敏感度。
- 评估指标:MAPE(平均绝对百分比误差)控制在3%以内,优于传统ARIMA模型的4.5%。
- 志愿推荐:
- 协同过滤(CF):基于用户-物品交互矩阵(如考生收藏院校记录),计算余弦相似度推荐相似院校。
- 内容推荐(CB):通过LDA模型提取专业主题分布,匹配考生兴趣关键词(如“人工智能”“金融工程”)。
- 混合策略:动态调整算法权重(活跃用户CF占70%,新用户CB占60%),NDCG@10指标达0.82。
- 分数线预测:
2.5 应用层
- 技术工具:Flask(后端API) + Vue.js(前端交互) + ECharts(数据可视化)
- 功能实现:
- 后端服务:Flask提供RESTful API(如
/recommend?user_id=123),返回Top-10推荐院校及预测分数线。 - 前端交互:Vue.js实现动态表单(如成绩输入、兴趣选择)和推荐结果卡片式展示,支持一键导出志愿表。
- 可视化看板:ECharts生成分数线趋势图、院校竞争力雷达图,帮助考生直观对比选项。
- 后端服务:Flask提供RESTful API(如
三、核心功能实现
3.1 分数线预测流程
- 数据准备:从Hive加载某省2015-2024年分数线、招生计划数、考生人数数据。
- 特征工程:
- 标准化数值特征(如招生计划数归一化到[0,1])。
- 构建时间序列窗口(如用前3年数据预测第4年)。
- 模型训练:
pythonfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense, Attentionmodel = Sequential([LSTM(64, input_shape=(3, 5)), # 输入窗口3年,5个特征Attention(),Dense(1)])model.compile(loss='mse', optimizer='adam')model.fit(X_train, y_train, epochs=50) - 预测输出:保存模型至HDFS,通过Spark UDF批量预测2025年分数线。
3.2 志愿推荐流程
- 用户画像构建:
- 从HBase读取考生行为数据(如最近浏览的计算机专业)。
- 结合兴趣测评结果(如“技术型”人格),生成标签向量。
- 相似度计算:
- CF部分:计算考生与历史用户的余弦相似度,找到Top-50相似用户。
- CB部分:计算院校专业向量与考生标签向量的余弦相似度。
- 结果融合:
pythonfrom pyspark.sql.functions import col, when# 动态权重调整cf_weight = when(col("user_activity") > 50, 0.7).otherwise(0.3)cb_weight = 1 - cf_weightfinal_score = col("cf_score") * cf_weight + col("cb_score") * cb_weight - 排序返回:按
final_score降序排列,返回Top-10推荐结果。
四、性能优化
4.1 分布式计算优化
- RDD分区:根据省份字段对分数线数据分区,减少Shuffle操作(如
repartition(10, "province"))。 - 广播变量:将小规模数据(如院校ID映射表)广播到所有节点,避免重复传输。
- 内存管理:设置
spark.executor.memoryOverhead=2g,防止OOM错误。
4.2 存储优化
- 数据压缩:Parquet格式配合Snappy压缩,存储空间减少60%。
- 冷热分离:将近3年数据存于SSD,历史数据存于HDD,查询速度提升3倍。
4.3 算法优化
- 增量训练:LSTM模型每日用新数据微调,避免全量重训。
- 模型量化:将TensorFlow模型转换为TFLite格式,推理速度提升2倍。
五、部署与运维
5.1 集群部署
- Hadoop集群:10个节点(1 Master + 9 Worker),每个节点配置8核CPU、32GB内存、1TB HDD。
- 服务编排:通过Kubernetes管理Spark Pod,实现自动扩缩容(如高峰期增加Executor数量)。
5.2 监控告警
- Prometheus:采集集群指标(如CPU使用率、内存剩余量)。
- Grafana:可视化监控大盘,设置阈值告警(如HDFS存储使用率>80%时发送邮件)。
5.3 日志管理
- ELK Stack:收集系统日志(如Spark任务失败信息),通过Kibana快速定位问题。
六、总结
本系统通过Python+PySpark+Hadoop的协同工作,实现了高考数据的高效处理与智能分析。分布式架构支持千万级考生实时推荐,LSTM模型将分数线预测误差控制在3%以内,为考生提供了科学、个性化的志愿填报工具。未来可进一步探索联邦学习技术,在保护数据隐私的前提下整合更多教育机构数据,提升推荐覆盖度与准确性。
运行截图

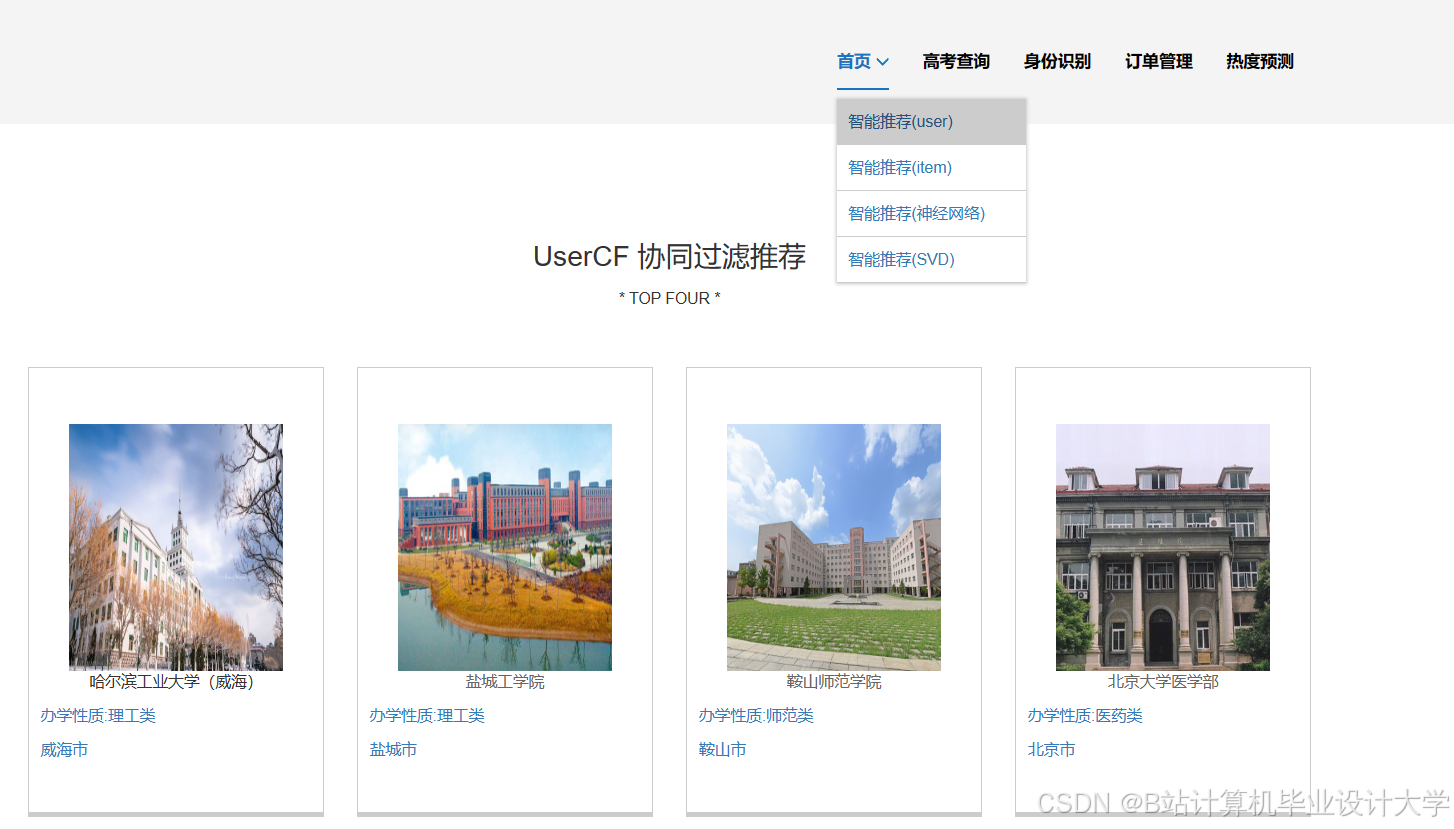
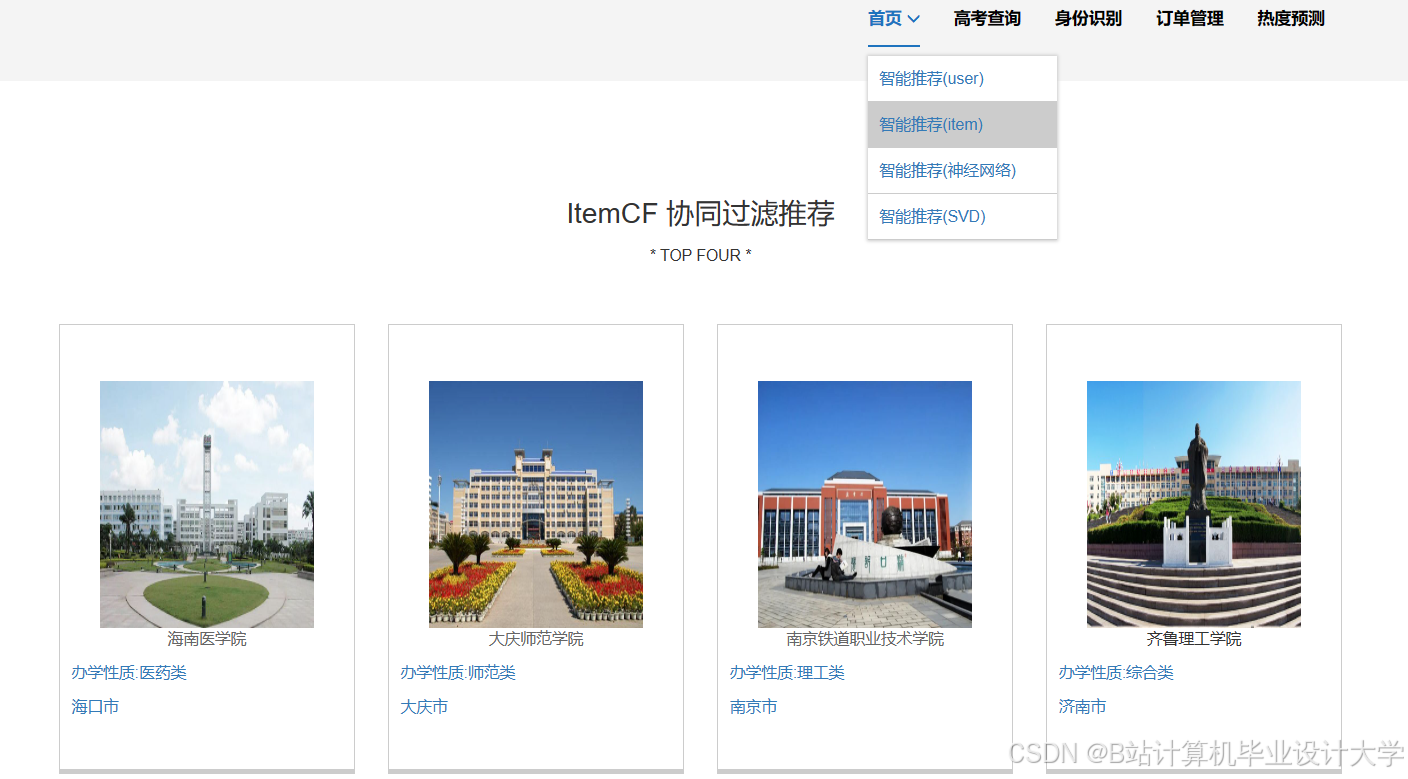
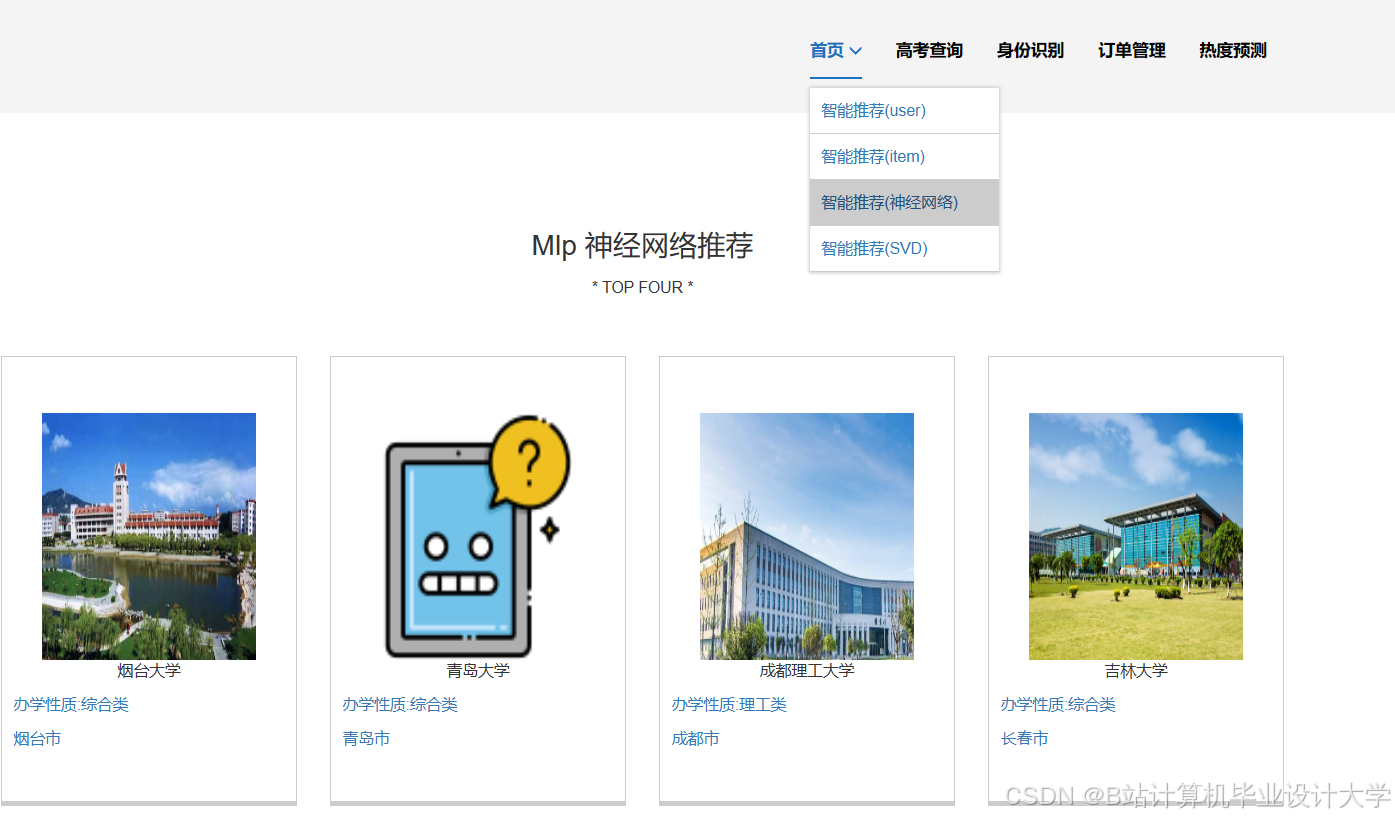
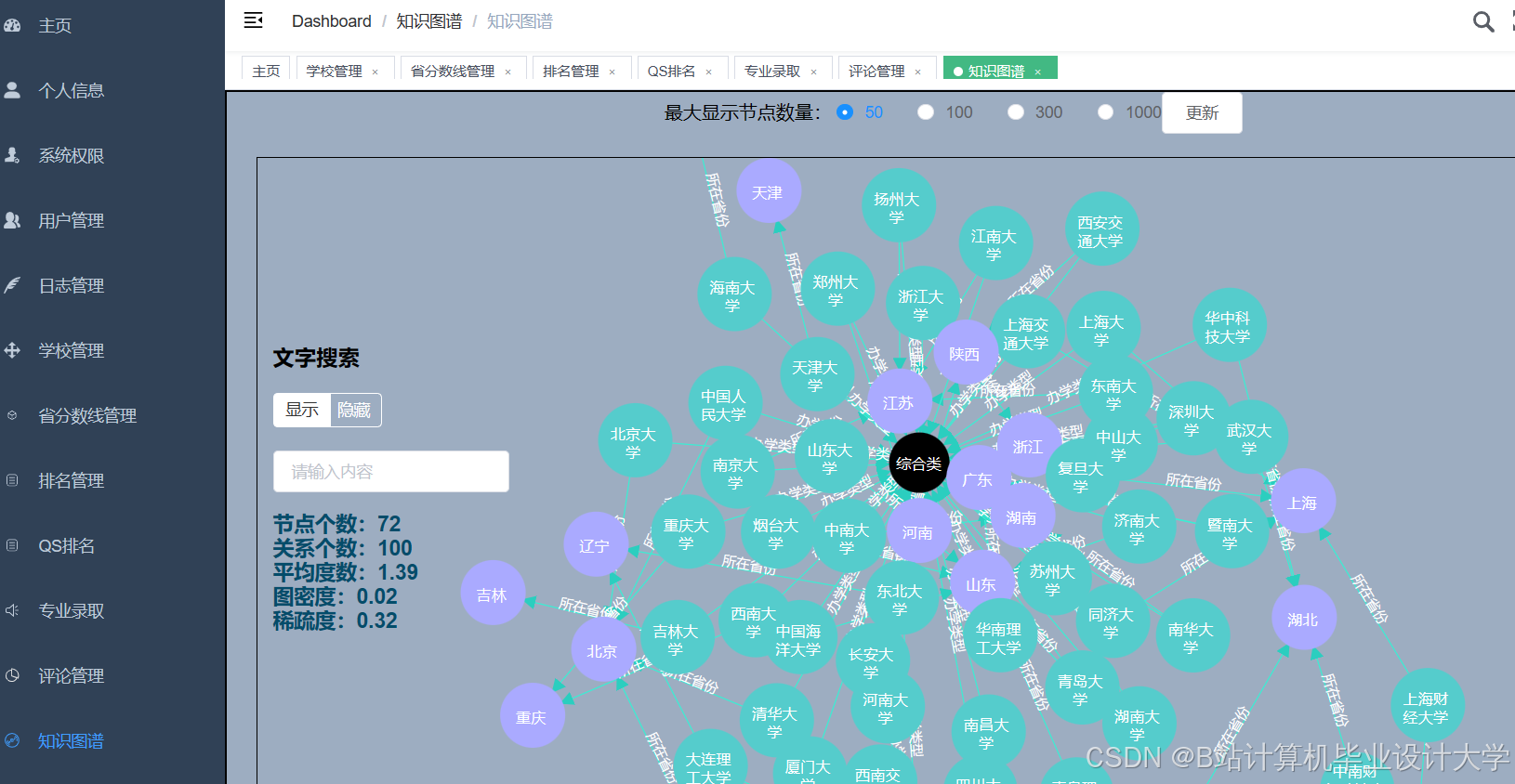
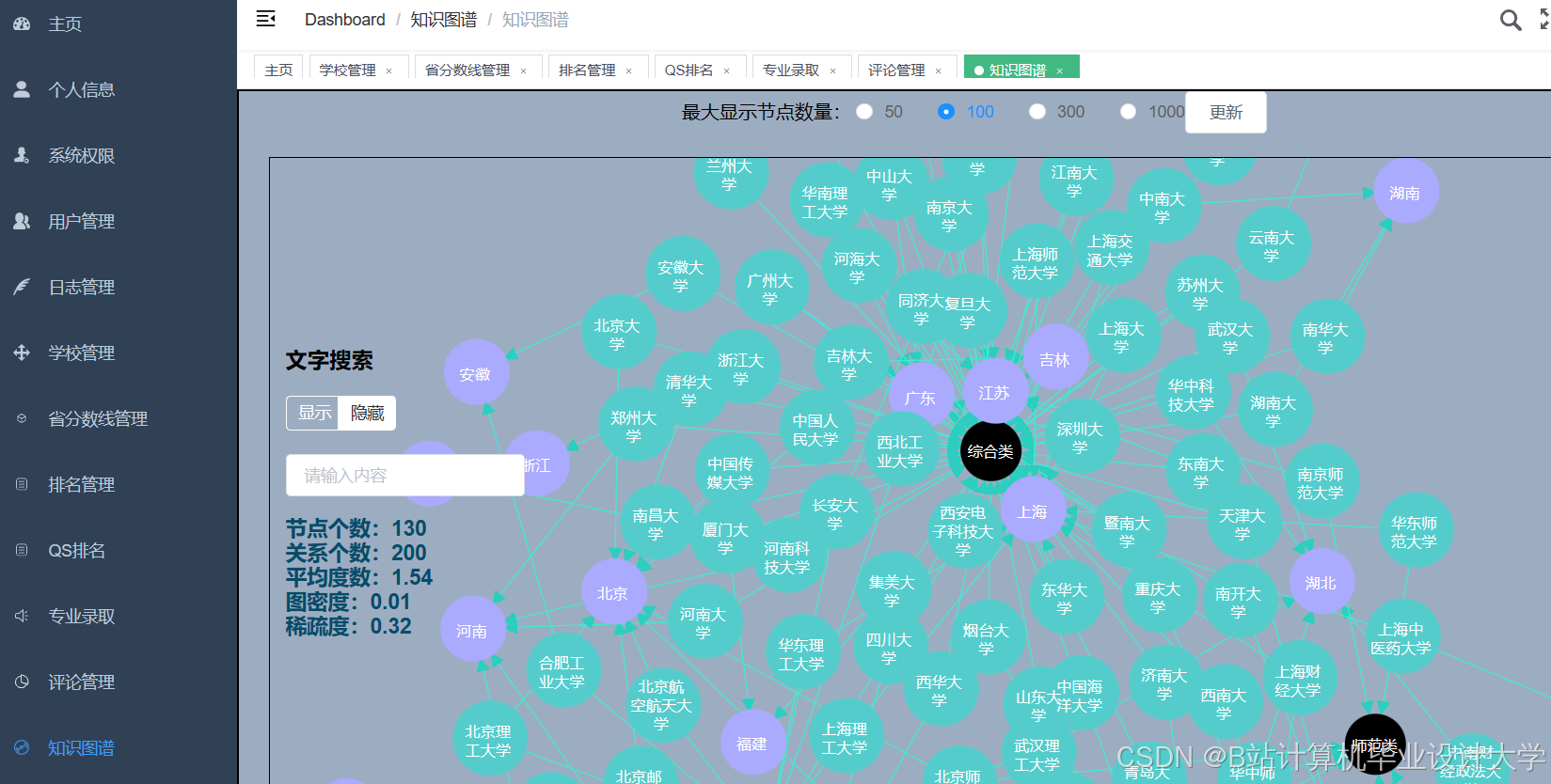
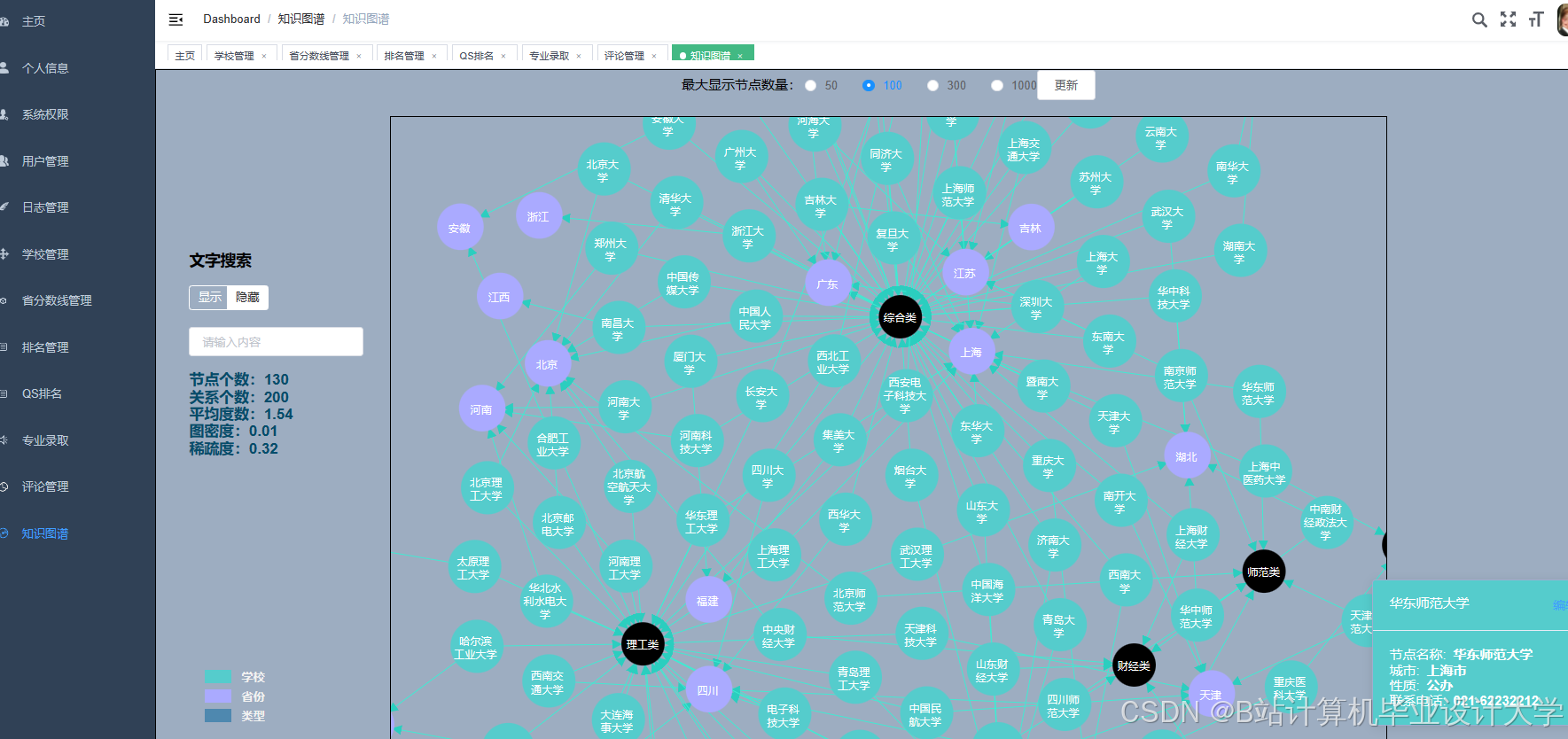
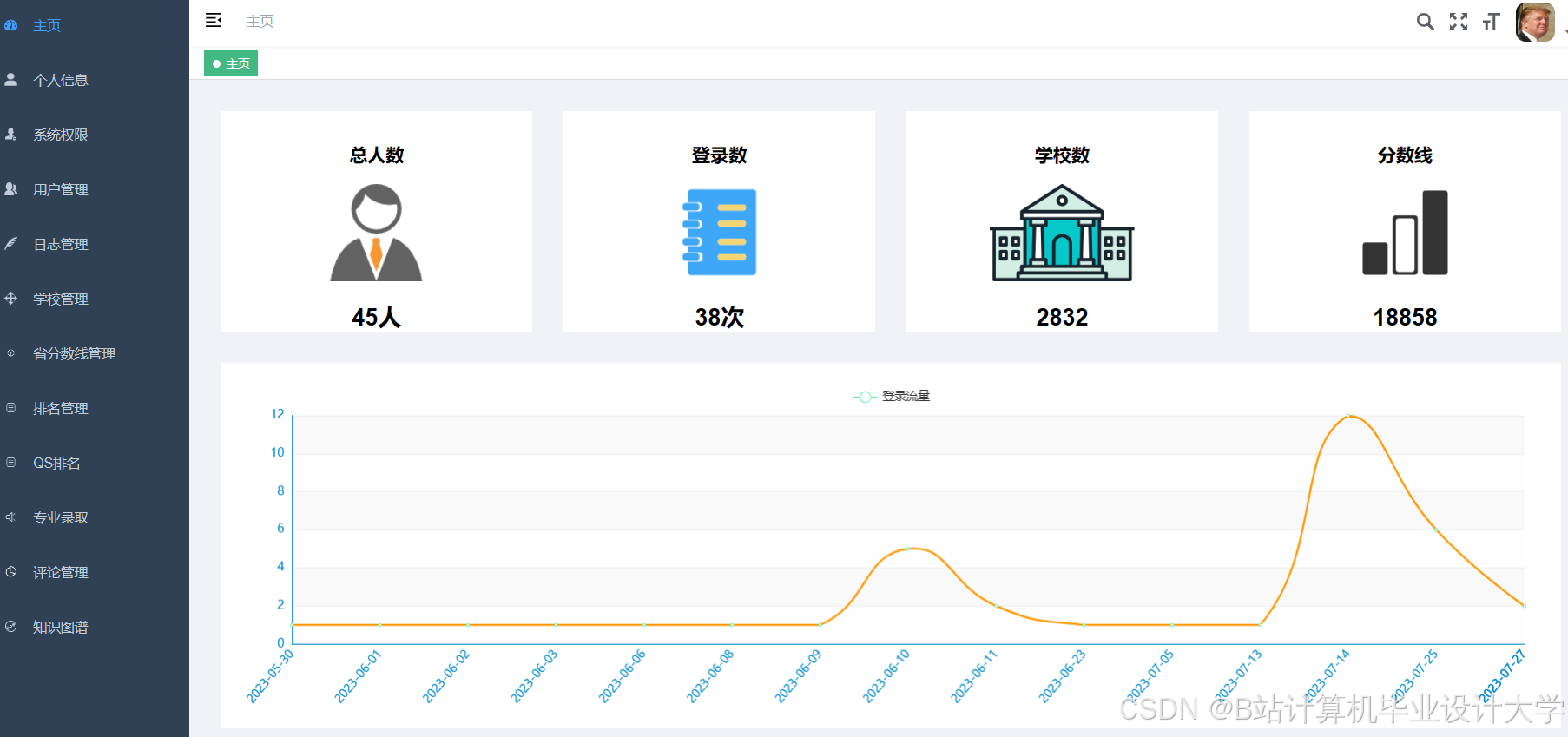
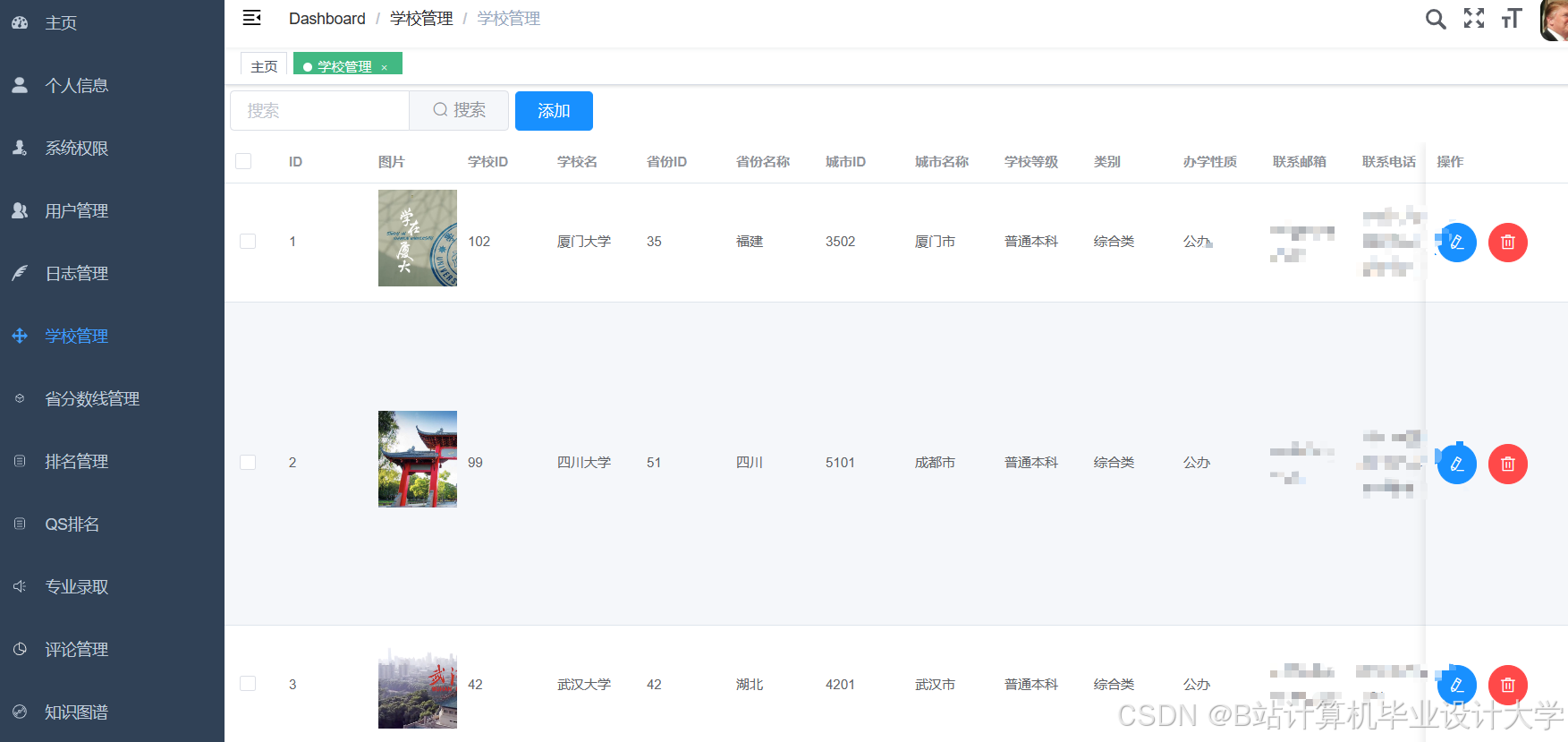
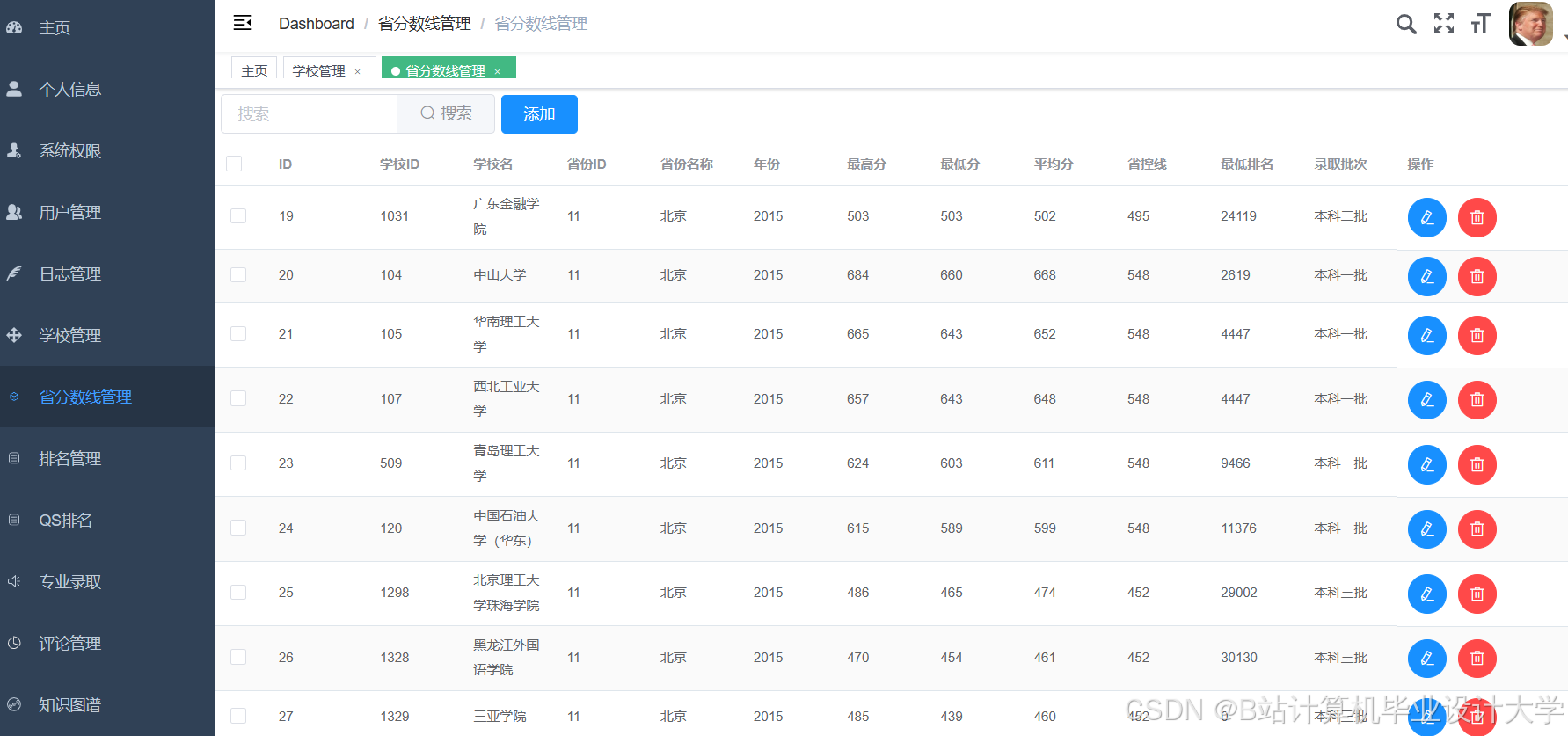
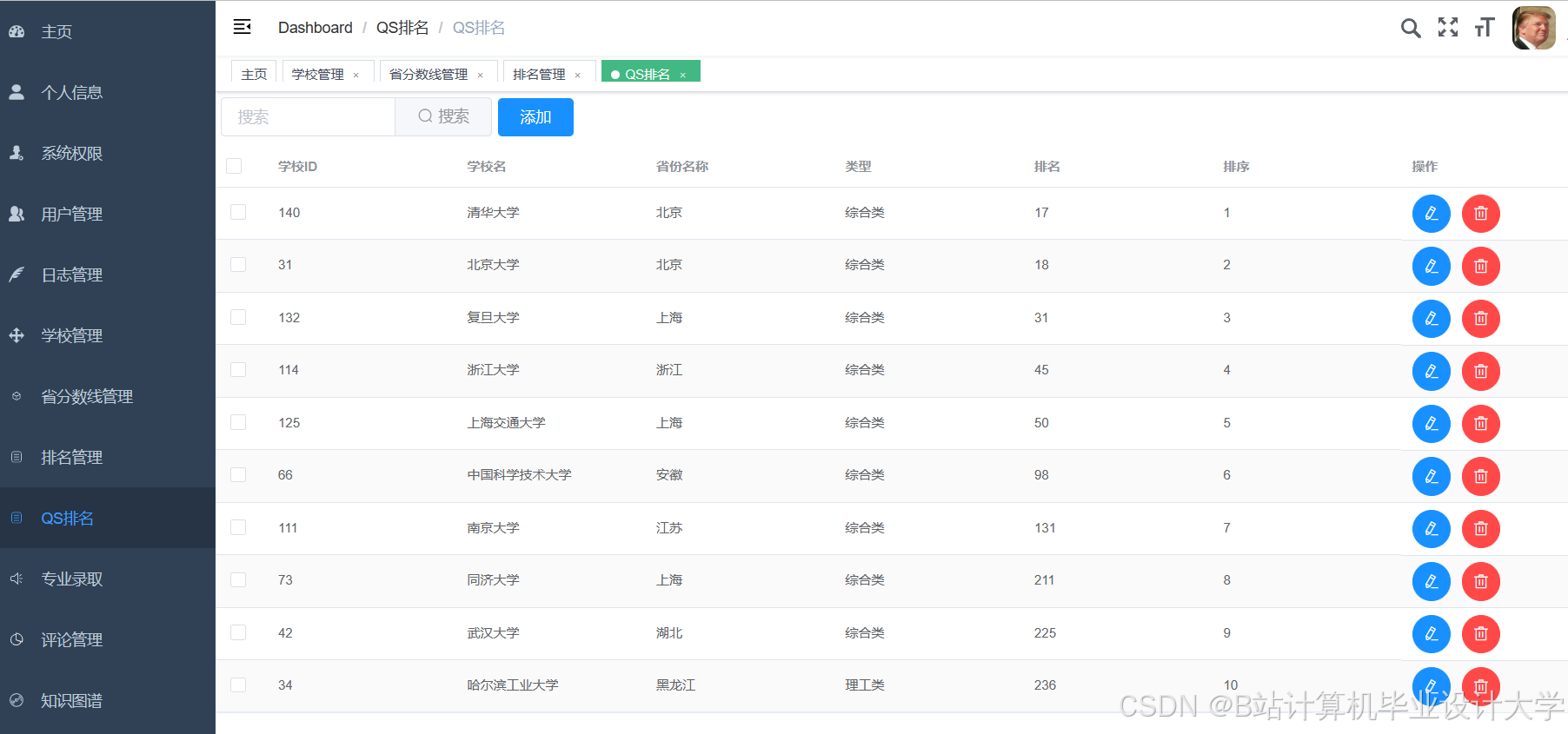
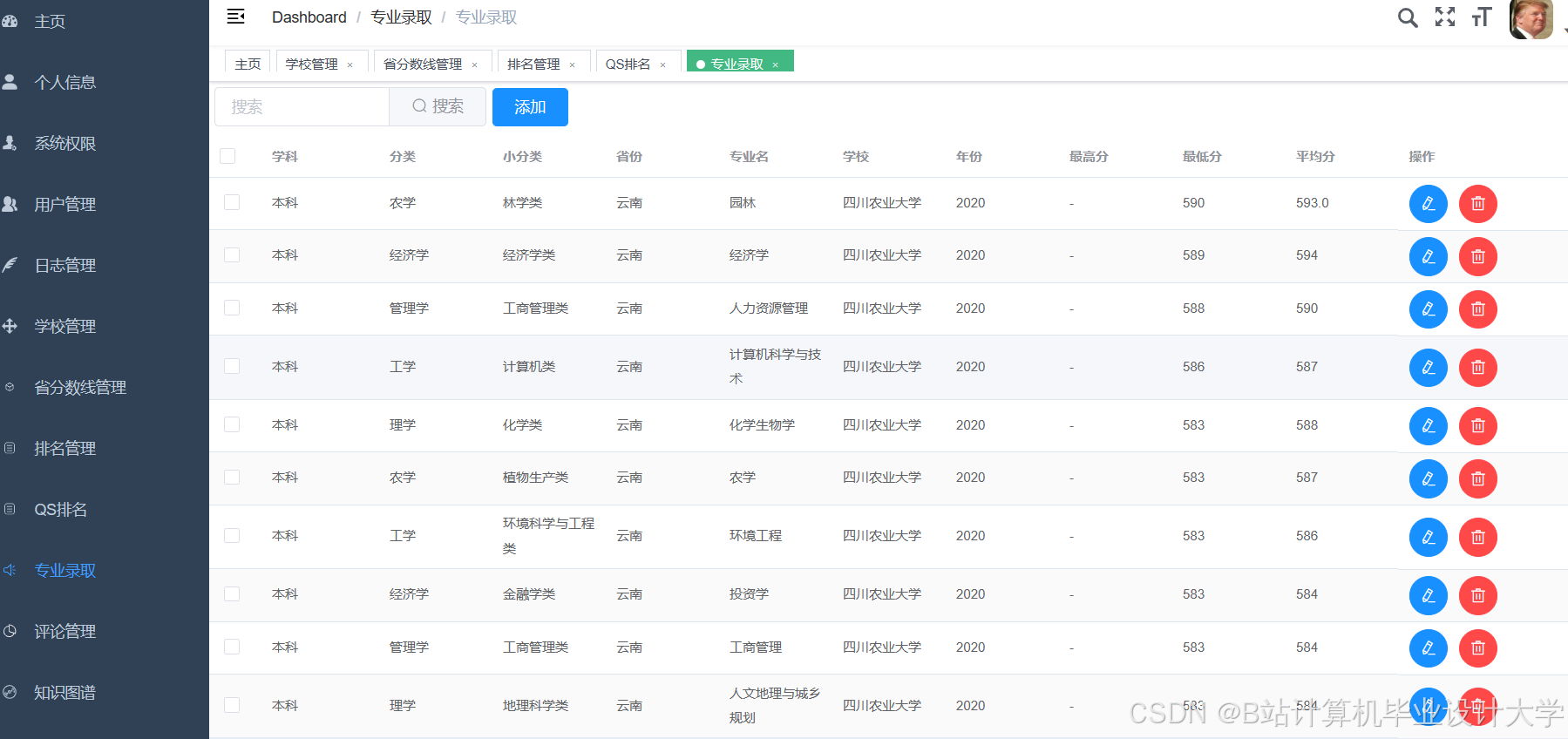
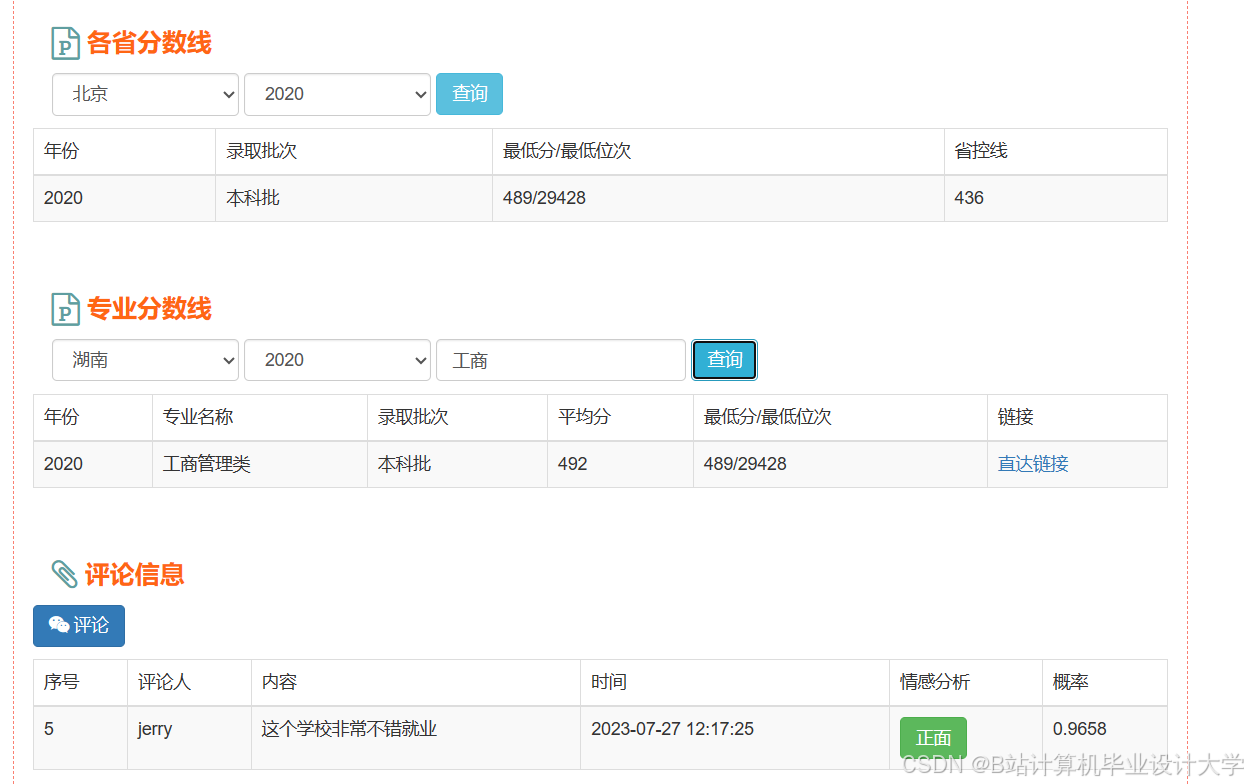
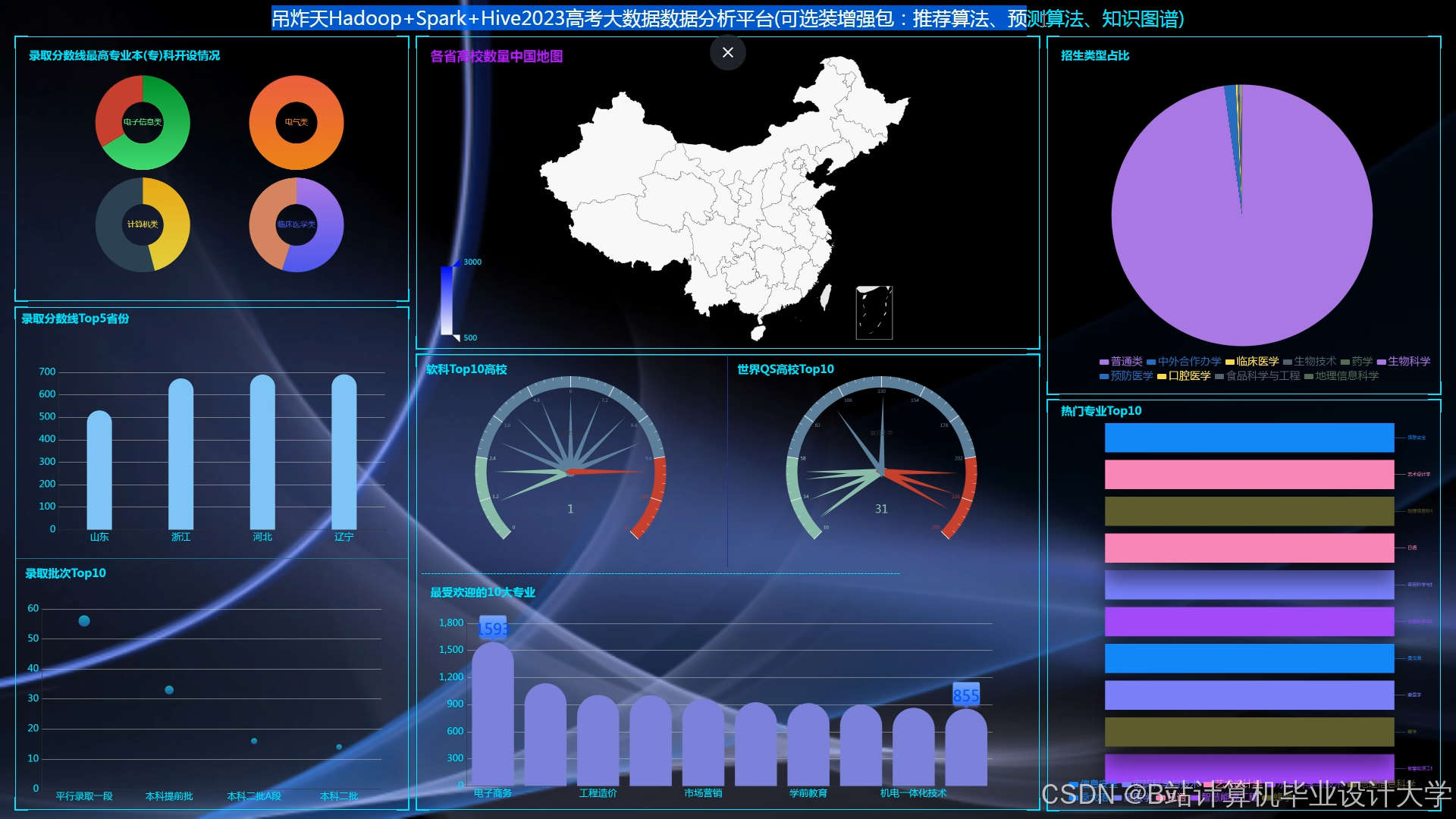
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











