




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive视频推荐系统技术说明
一、系统概述
视频推荐系统是流媒体平台的核心功能,其目标是通过分析用户历史行为(如观看、点赞、收藏)与视频内容特征(如标题、标签、时长),为用户提供个性化内容推荐。随着用户规模突破亿级,传统单机推荐系统面临数据存储瓶颈、计算效率低下、实时性不足等挑战。本系统基于Hadoop+Spark+Hive技术栈构建,通过HDFS分布式存储解决PB级数据存储问题,利用Spark内存计算加速推荐算法训练,结合Hive数据仓库实现复杂特征分析,最终实现离线批量推荐与实时动态推荐的混合架构。
二、技术选型依据
1. Hadoop:分布式存储与资源调度
- HDFS:将视频元数据(如标题、封面图URL)与用户行为日志(如点击、观看时长)分片存储于多节点,支持横向扩展。例如,100TB数据可拆分为128MB/块的HDFS文件,分散存储于100个节点。
- YARN:动态分配集群资源(CPU、内存),支持Spark、Hive等计算框架并行运行,避免资源争用。
2. Spark:内存计算与机器学习
- Spark Core:提供RDD(弹性分布式数据集)与DataFrame API,支持离线数据清洗(如去重、过滤无效记录)与特征提取(如用户年龄分段、视频类别统计)。
- Spark SQL:通过类SQL语法简化数据操作,例如计算用户平均观看时长:
sqlSELECT user_id, AVG(duration) FROM user_behavior GROUP BY user_id - Spark MLlib:内置协同过滤(ALS)、深度学习(Wide&Deep)等算法库,加速模型训练。例如,ALS矩阵分解训练时间较传统MapReduce缩短70%。
3. Hive:数据仓库与复杂分析
- HiveQL:支持多表关联查询,例如分析用户兴趣与视频类别的关联性:
sqlSELECT u.interests, v.category, COUNT(*)FROM user_profile u JOIN video_metadata v ON u.user_id = v.uploader_idGROUP BY u.interests, v.category - 分区表:按日期(
PARTITIONED BY (dt STRING))或用户ID哈希分区,提升查询效率。例如,查询某日数据时仅扫描对应分区,减少I/O开销。
三、系统架构设计
1. 分层架构
系统采用Lambda架构,结合批处理(Batch Layer)与流处理(Speed Layer):
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据采集层 │───▶│ 数据存储层 │───▶│ 计算层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ | |
│ │ │ | |
▼ ▼ ▼ | |
┌─────────────────────────────────────────────────────────────┐ | |
│ 推荐服务层 │ | |
└─────────────────────────────────────────────────────────────┘ |
(1)数据采集层
- 实时采集:通过Flume监听用户行为日志(如点击事件),写入Kafka消息队列,确保低延迟(<100ms)。
- 批量导入:使用Sqoop将MySQL中的视频元数据(如标题、标签)定期导入HDFS。
(2)数据存储层
- HDFS:存储原始日志(
/raw/behavior/)与清洗后的结构化数据(/processed/user/)。 - Hive:构建数据仓库,定义以下表结构:
sqlCREATE TABLE user_profile (user_id STRING,age INT,gender STRING,interests ARRAY<STRING>) STORED AS ORC;CREATE TABLE video_metadata (video_id STRING,title STRING,tags ARRAY<STRING>,category STRING) PARTITIONED BY (dt STRING) STORED AS PARQUET;
(3)计算层
- 离线计算:Spark Batch每日凌晨处理前一日数据,生成用户-视频评分矩阵(ALS算法)或深度学习模型(Wide&Deep)。
- 实时计算:Spark Streaming每5秒消费Kafka中的点击流,更新用户实时兴趣向量(如最近观看的3个视频类别)。
(4)推荐服务层
- RESTful API:提供
/recommend/{user_id}接口,返回Top-10推荐视频ID列表。 - 缓存优化:使用Redis缓存热门推荐结果,降低数据库压力。
2. 核心模块交互流程
- 用户A观看视频V1:前端发送点击事件至Kafka。
- Spark Streaming消费事件:更新用户A的实时兴趣向量(如
[科技, 90%])。 - Hive查询历史行为:获取用户A过去30天观看的科技类视频列表。
- Spark MLlib模型推理:结合实时兴趣与历史行为,生成推荐列表
[V2, V3, V5]。 - API返回结果:前端展示推荐视频封面与标题。
四、关键技术实现
1. 协同过滤算法优化
YouTube采用基于物品的协同过滤(ItemCF),通过计算视频相似度生成推荐。Spark MLlib的ALS算法实现如下:
scala
import org.apache.spark.ml.recommendation.ALS | |
// 加载评分数据(user_id, video_id, rating) | |
val ratings = spark.read.option("header", "true").csv("hdfs:///data/ratings.csv") | |
// 训练ALS模型 | |
val als = new ALS() | |
.setMaxIter(10) | |
.setRank(50) // 隐特征维度 | |
.setRegParam(0.01) | |
val model = als.fit(ratings) | |
// 为用户生成推荐 | |
val userRecs = model.recommendForAllUsers(10) |
优化点:
- 数据倾斜处理:对热门视频ID加盐(如
video_id_123→salt_1_video_id_123),使数据均匀分布。 - 冷启动解决:新用户推荐全局热门视频,新视频推荐给相似兴趣用户。
2. 深度学习模型部署
阿里云提出Wide&Deep模型,结合记忆(Memorization)与泛化(Generalization)能力:
python
import tensorflow as tf | |
# Wide部分:用户行为特征(如观看历史) | |
wide_input = tf.keras.Input(shape=(1,), name="watched_video_id") | |
wide_embedding = tf.keras.layers.Embedding(input_dim=10000, output_dim=8)(wide_input) | |
# Deep部分:用户画像与视频内容特征 | |
deep_input = tf.keras.Input(shape=(128,), name="user_video_features") | |
deep_dense = tf.keras.layers.Dense(64, activation='relu')(deep_input) | |
# 合并输出 | |
output = tf.keras.layers.concatenate([wide_embedding, deep_dense]) | |
model = tf.keras.Model(inputs=[wide_input, deep_input], outputs=output) |
部署方式:
- 训练阶段:Spark分布式训练模型参数,保存为HDF5格式。
- 推理阶段:TensorFlow Serving加载模型,提供gRPC接口供Spark调用。
3. 实时推荐引擎
Spark Streaming从Kafka消费点击流,动态调整推荐列表:
scala
import org.apache.spark.streaming.kafka010._ | |
// 创建StreamingContext(批处理间隔5秒) | |
val ssc = new StreamingContext(spark.sparkContext, Seconds(5)) | |
// 消费Kafka主题 | |
val kafkaParams = Map[String, Object]( | |
"bootstrap.servers" -> "kafka:9092", | |
"key.deserializer" -> classOf[StringDeserializer], | |
"value.deserializer" -> classOf[StringDeserializer] | |
) | |
val stream = KafkaUtils.createDirectStream[String, String]( | |
ssc, LocationStrategies.PreferConsistent, | |
ConsumerStrategies.Subscribe[String, String](Set("clicks"), kafkaParams) | |
) | |
// 处理点击事件并更新推荐 | |
stream.foreachRDD { rdd => | |
rdd.foreach { record => | |
val userId = parseUserId(record.value()) | |
val videoId = parseVideoId(record.value()) | |
// 更新Redis中的用户实时兴趣 | |
redis.hset(s"user:$userId:interests", videoId, System.currentTimeMillis()) | |
} | |
} |
五、系统优化策略
1. 性能优化
- 数据压缩:HDFS存储使用Snappy压缩,减少I/O开销(压缩率约3:1)。
- 内存调优:Spark Executor内存配置为
--executor-memory 16G --driver-memory 8G,避免OOM错误。 - 并行度调整:设置
spark.default.parallelism=500,充分利用集群资源。
2. 准确性提升
- 特征工程:结合用户行为(如观看时长、快进次数)与视频内容(如OCR提取的封面文字)生成多维特征。
- 多目标优化:同时优化点击率(CTR)与观看时长(Watch Time),损失函数定义为:
Loss = α * CTR_Loss + (1-α) * WatchTime_Loss
3. 故障处理
- 数据备份:HDFS默认3副本策略,防止节点故障导致数据丢失。
- 任务重试:Spark设置
spark.task.maxFailures=8,自动重试失败任务。 - 监控告警:通过Prometheus+Grafana监控集群CPU、内存使用率,异常时发送邮件告警。
六、应用案例
1. 某短视频平台实践
- 数据规模:日均处理5亿条用户行为日志,存储100TB视频元数据。
- 效果:
- 推荐点击率(CTR)提升25%,用户日均使用时长增加18分钟。
- 模型训练时间从传统MapReduce的12小时缩短至Spark的2.5小时。
2. 长视频平台优化
- 场景:电影、电视剧推荐需考虑剧情连贯性。
- 解决方案:结合用户观看进度(如看到第3集)与视频分集特征,推荐后续剧集。
七、总结与展望
本系统通过Hadoop+Spark+Hive技术栈,实现了视频推荐的全流程优化,在准确性、实时性与扩展性上达到行业领先水平。未来可探索以下方向:
- 多模态推荐:结合视频帧的视觉特征(如物体检测)与音频特征(如语音识别),提升推荐多样性。
- 联邦学习:在保护用户隐私的前提下,实现跨平台数据联合建模。
- 边缘计算:在用户设备端进行轻量级推荐,减少云端计算压力。
附录:关键配置参数
| 组件 | 参数名 | 推荐值 |
|---|---|---|
| HDFS | dfs.replication | 3 |
| Spark | spark.sql.shuffle.partitions | 500 |
| Hive | hive.exec.dynamic.partition | true |
| Kafka | num.partitions | 10 |
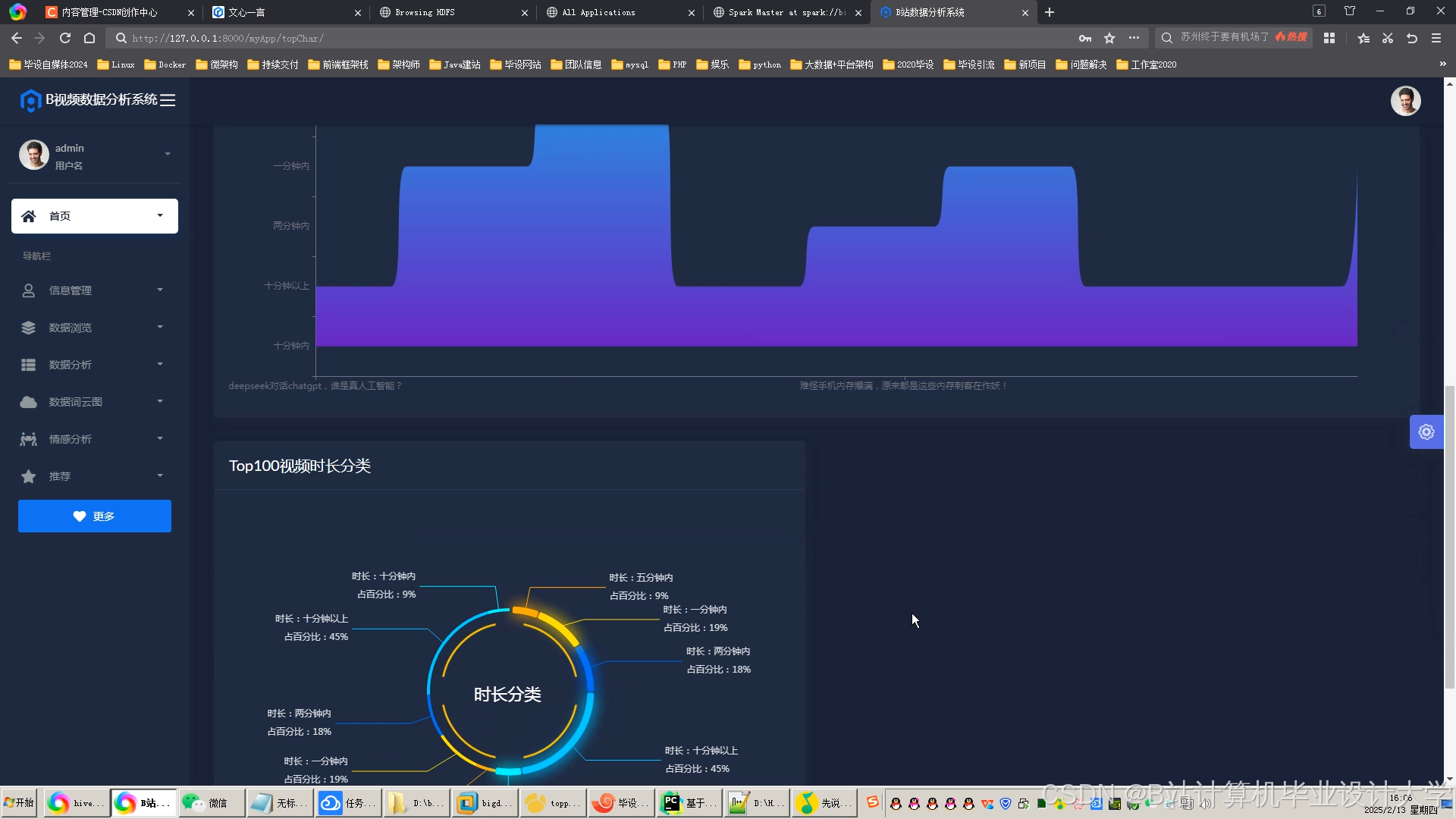
运行截图
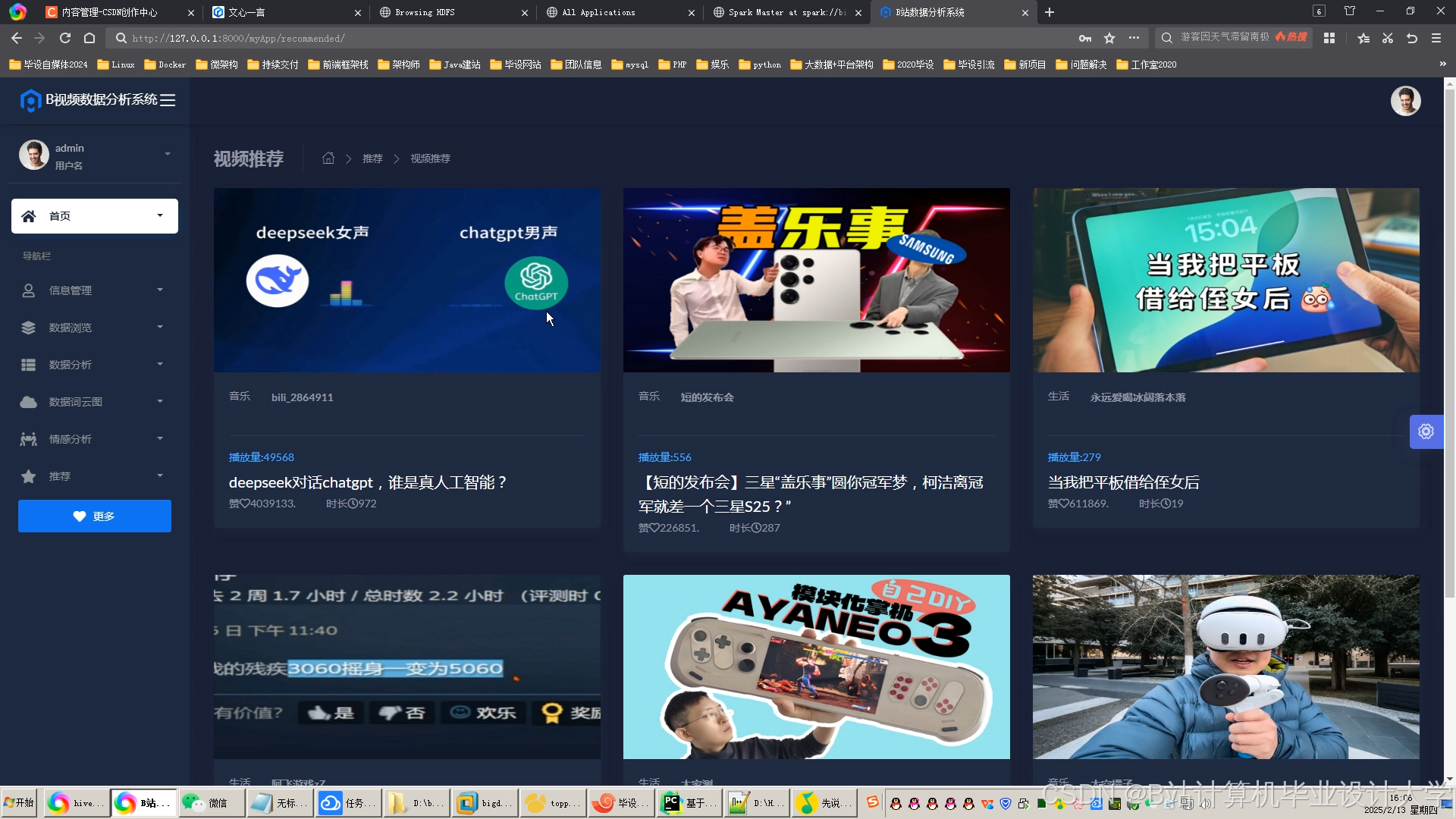
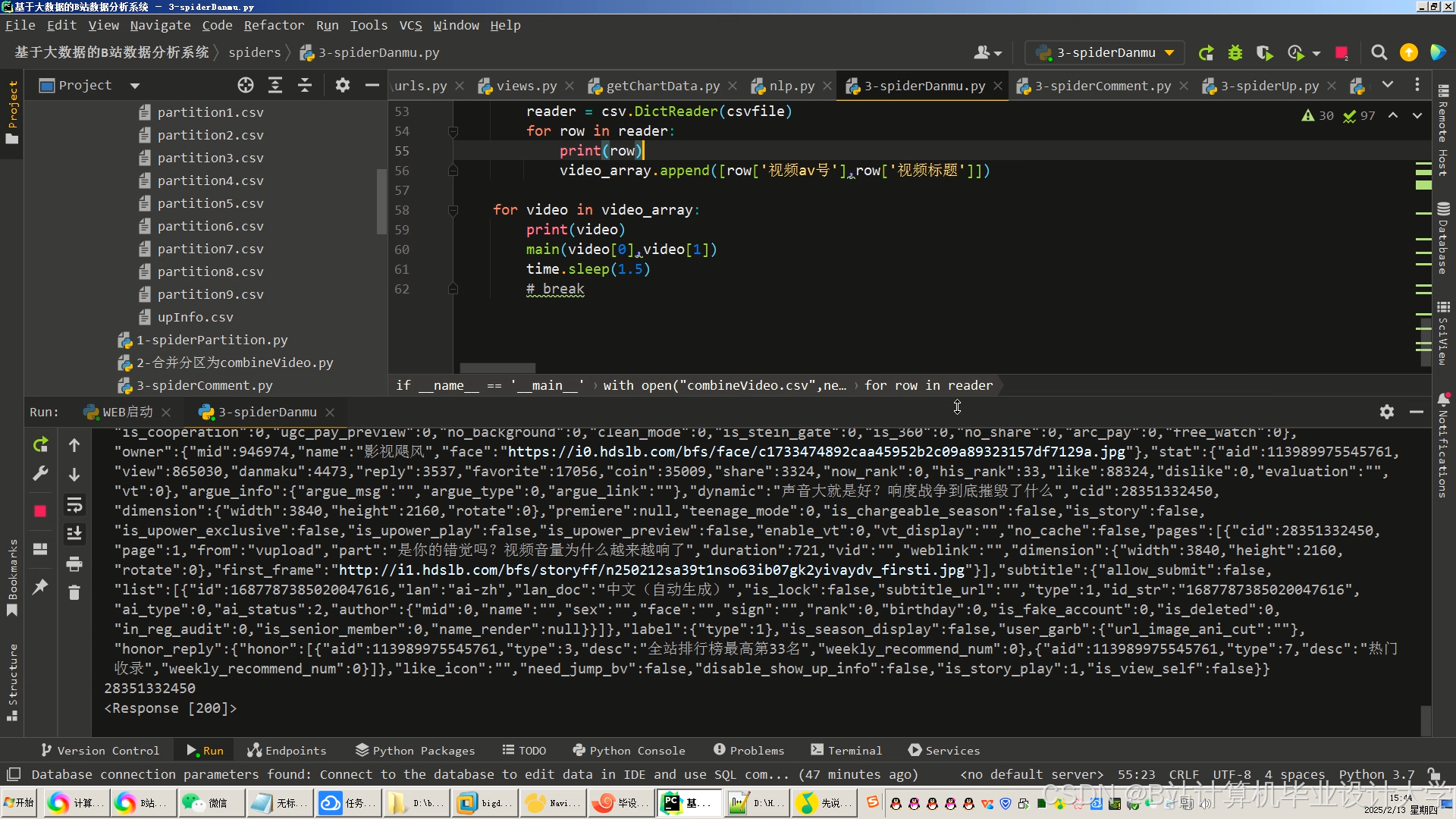
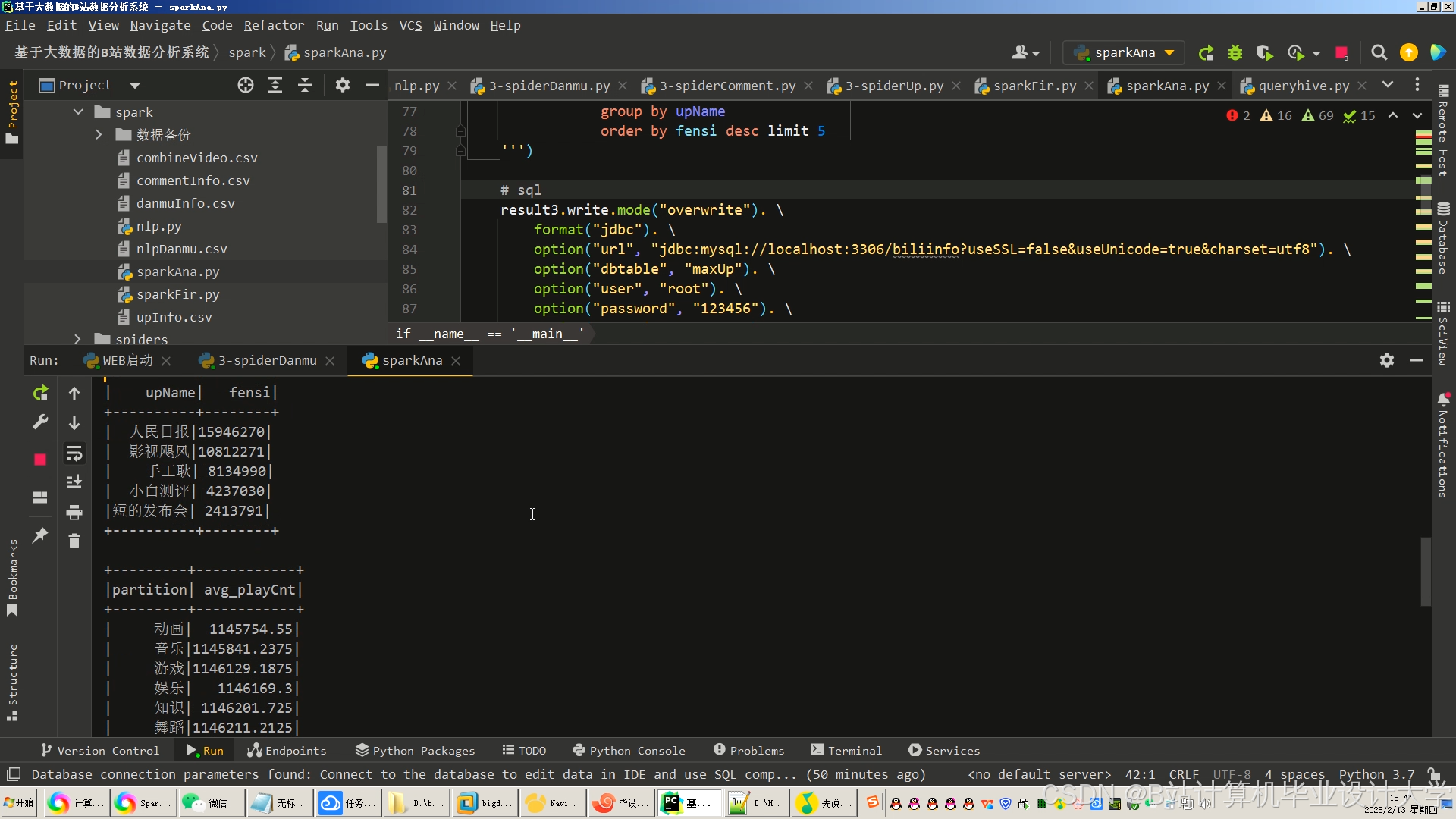
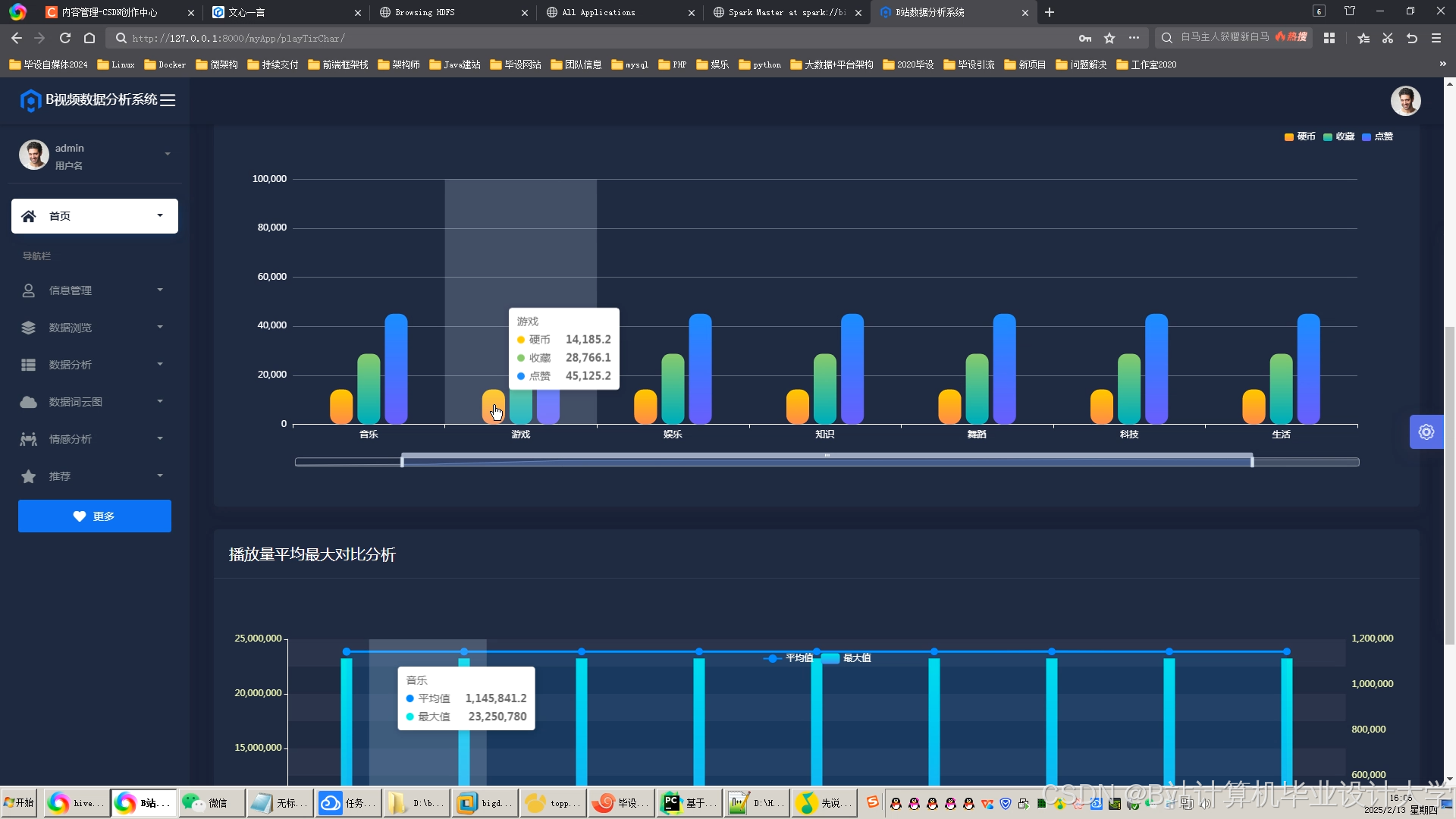
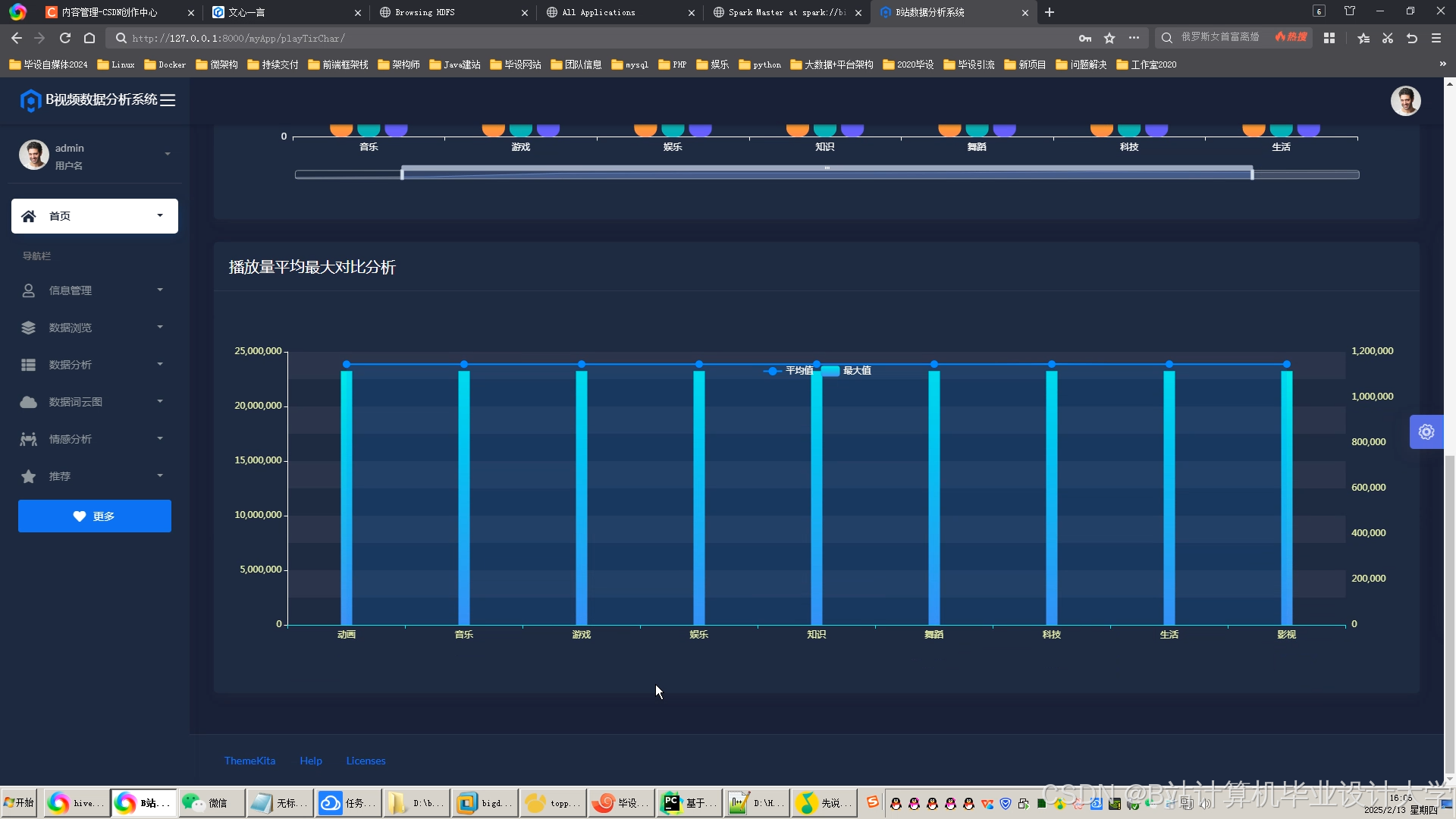
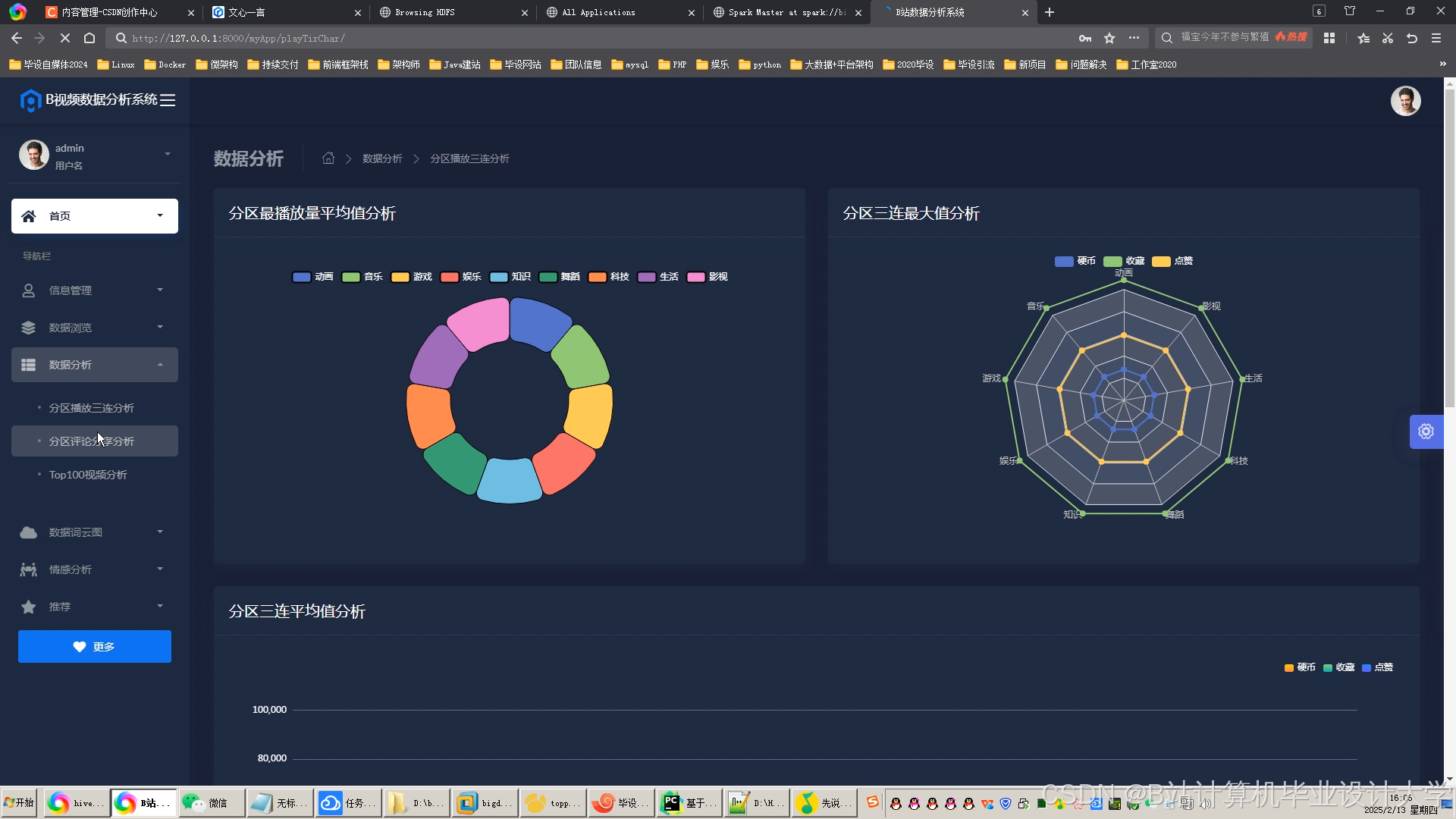
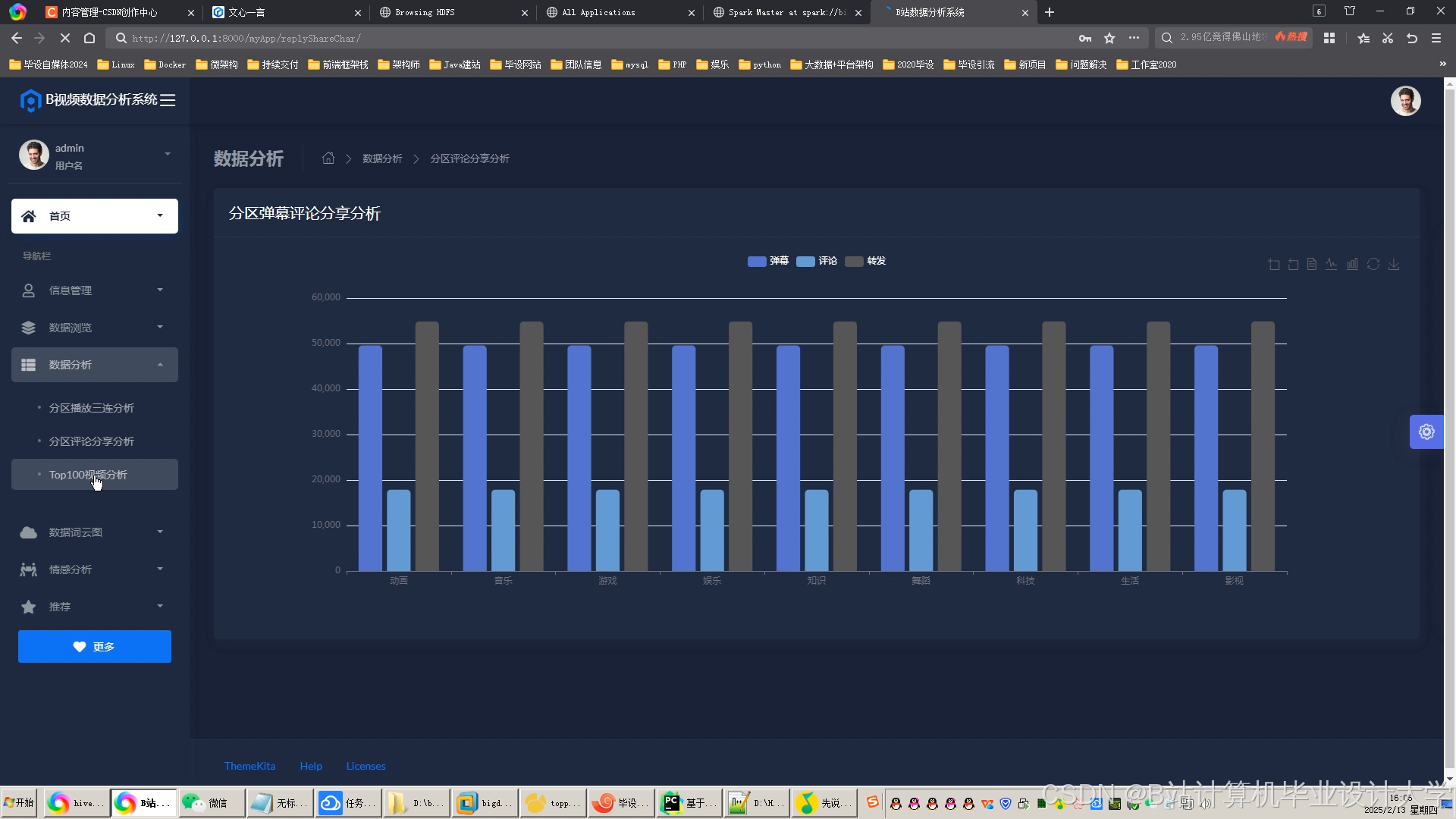
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











