




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive租房推荐系统技术说明
一、系统概述
本系统基于Hadoop分布式存储、Spark内存计算与Hive数据仓库技术,构建面向租房场景的智能推荐平台。通过整合房源数据、用户行为数据与外部地理信息,实现千万级用户与百万级房源的实时匹配,解决传统推荐系统数据孤岛、计算延迟高、扩展性差等问题。系统核心指标:支持10万QPS(每秒查询量)、推荐延迟<500ms、推荐准确率≥90%。
二、技术架构
2.1 总体架构图
┌───────────────────────────────────────────────────────────────┐ | |
│ 租房推荐系统架构 │ | |
├───────────────┬───────────────┬───────────────┬───────────────┤ | |
│ 数据采集层 │ 存储层 │ 处理层 │ 服务层 │ | |
├───────────────┼───────────────┼───────────────┼───────────────┤ | |
│ Scrapy爬虫 │ HDFS │ Spark SQL │ Flask API │ | |
│ Kafka消息队列 │ Hive数据仓库 │ MLlib机器学习 │ Vue.js前端 │ | |
│ │ Neo4j图数据库 │ Structured │ Grafana监控 │ | |
│ │ MySQL关系库 │ Streaming │ │ | |
└───────────────┴───────────────┴───────────────┴───────────────┘ |
2.2 关键组件说明
- Hadoop HDFS
- 存储原始数据:房源信息(JSON格式)、用户行为日志(CSV格式)、地理编码数据(Shapefile)
- 分区策略:按城市(
/city/beijing)和时间(/date=20250801)二级分区 - 压缩算法:Snappy压缩原始日志,节省60%存储空间
- Hive数据仓库
- 构建ODS(原始数据层)、DWD(明细数据层)、DWS(汇总数据层)
- 示例表结构:
sql
-- 房源基础表 | |
CREATE TABLE ods_house_info ( | |
house_id STRING, | |
title STRING, | |
price DECIMAL(10,2), | |
district STRING, | |
geo_hash STRING, -- GeoHash编码 | |
create_time TIMESTAMP | |
) STORED AS ORC; | |
-- 用户行为事实表 | |
CREATE TABLE dwd_user_actions ( | |
user_id STRING, | |
house_id STRING, | |
action_type STRING, -- VIEW/COLLECT/CONTACT | |
action_time TIMESTAMP, | |
duration INT -- 浏览时长(秒) | |
) PARTITIONED BY (dt STRING) STORED AS PARQUET; |
- Spark计算引擎
- 批处理:每日凌晨执行全量数据ETL(清洗、转换、聚合)
- 流处理:通过Spark Streaming实时消费Kafka日志,更新用户画像
- 机器学习:使用MLlib实现ALS矩阵分解、TF-IDF文本特征提取
三、核心模块实现
3.1 数据采集与预处理
- 爬虫设计
- 模拟浏览器请求头(User-Agent、Referer)绕过反爬
- 增量采集策略:基于
Last-Modified时间戳更新数据 - 示例代码(Scrapy):
python
class HouseSpider(scrapy.Spider): | |
name = 'lianjia' | |
custom_settings = { | |
'DOWNLOAD_DELAY': 2, # 请求间隔 | |
'CONCURRENT_REQUESTS': 5 | |
} | |
def parse(self, response): | |
item = { | |
'house_id': response.css('.house_id::text').get(), | |
'title': response.css('.title::text').get(), | |
'price': float(response.css('.price::text').get().replace('万', '')) | |
} | |
yield item |
- 数据清洗规则
- 价格校验:删除价格<500元/月或>10万元/月的异常房源
- 地理位置修正:调用高德地图API校验GeoHash坐标
- 缺失值处理:使用KNN算法填充户型缺失值
3.2 特征工程实现
- 用户画像构建
- 基础特征:年龄、性别、职业(从注册信息提取)
- 行为特征:
- 价格敏感度:
price_sensitivity = 平均浏览价格 / 实际预约价格 - 通勤偏好:
commute_time = 最后一次预约房源到工作地的驾车时长
- 价格敏感度:
- 示例Spark代码:
scala
// 计算用户价格敏感度 | |
val userPriceStats = spark.sql(""" | |
SELECT | |
user_id, | |
AVG(price) as avg_view_price, | |
MAX(CASE WHEN action_type='CONTACT' THEN price END) as booked_price | |
FROM dwd_user_actions | |
JOIN ods_house_info ON house_id = house_id | |
GROUP BY user_id | |
""") | |
val userProfile = userPriceStats.withColumn( | |
"price_sensitivity", | |
col("avg_view_price") / col("booked_price") | |
) |
- 房源特征提取
- 竞争力指数:
competitiveness = 0.6*浏览量 + 0.3*收藏量 + 0.1*预约量 - 文本特征:使用BERT模型生成房源标题的768维向量
- 图片特征:ResNet50提取卧室/客厅图片的2048维特征
- 竞争力指数:
3.3 推荐算法实现
- 协同过滤算法(ALS)
- 参数配置:
- 潜在因子维度(rank)= 50
- 正则化参数(regParam)= 0.01
- 迭代次数(maxIter)= 10
- 示例代码:
- 参数配置:
python
from pyspark.ml.recommendation import ALS | |
als = ALS( | |
userCol="user_id", | |
itemCol="house_id", | |
ratingCol="weight", # 加权行为(浏览=1,收藏=3,预约=5) | |
coldStartStrategy="drop" | |
) | |
model = als.fit(training_data) | |
recommendations = model.recommendForAllUsers(10) # 每个用户推荐10个房源 |
- 内容推荐增强
- 文本相似度:计算房源标题与用户历史浏览标题的余弦相似度
- 地理位置过滤:使用GeoHash前6位(约1.6km范围)进行初步筛选
- 混合策略:
最终得分 = 0.6*CF得分 + 0.3*CB得分 + 0.1*知识图谱得分 |
- 知识图谱推理
- Neo4j图数据库存储关系:
cypher
// 创建用户-房源-区域关系 | |
CREATE (u:User {user_id: '1001'})-[:VIEWED {times: 5}]->(h:House {house_id: 'H001'}), | |
(h)-[:IN_DISTRICT]->(d:District {name: '朝阳区'}), | |
(d)-[:NEAR_SUBWAY {distance: 500}]->(s:Subway {line: '10号线'}) |
- 推荐推理:查找与用户历史预约房源在同一地铁站1km范围内的房源
3.4 实时推荐服务
- 增量更新机制
- Spark Streaming以10秒窗口聚合用户行为
- 触发条件:用户浏览/收藏房源后,立即更新推荐列表
- 示例代码:
scala
val kafkaStream = spark.readStream | |
.format("kafka") | |
.option("kafka.bootstrap.servers", "kafka:9092") | |
.option("subscribe", "user_actions") | |
.load() | |
val actionWindow = kafkaStream | |
.groupBy(window($"timestamp", "10 seconds"), $"user_id") | |
.agg(count("*").as("action_count")) | |
val query = actionWindow.writeStream | |
.outputMode("complete") | |
.format("memory") // 写入内存表 | |
.start() |
- 缓存策略
- Redis缓存用户画像(
user_profile:{user_id})和房源特征(house_feature:{house_id}) - LRU淘汰策略:设置TTL=1小时,内存占用控制在10GB以内
- Redis缓存用户画像(
四、系统优化
4.1 性能优化
- 数据倾斜处理
- 对热门房源ID添加随机前缀(
house_id%100)进行局部聚合 - 示例:
- 对热门房源ID添加随机前缀(
scala
// 解决房源浏览量倾斜问题 | |
val skewedData = spark.sql(""" | |
SELECT | |
CASE WHEN house_id IN ('H001','H002') THEN concat(house_id, '_', floor(rand()*100)) | |
ELSE house_id | |
END as house_id_skew, | |
count(*) as view_count | |
FROM dwd_user_actions | |
GROUP BY house_id_skew | |
""") |
- 参数调优
- Spark配置:
spark.executor.memory=12G | |
spark.sql.shuffle.partitions=200 | |
spark.default.parallelism=400 |
- Hive查询优化:启用CBO(Cost Based Optimizer),设置
hive.cbo.enable=true
4.2 高可用设计
- HDFS冗余
- 副本数=3,跨机架存储
- 监控脚本:每5分钟检查
hdfs dfsadmin -report
- Spark故障恢复
- 检查点机制:设置
spark.streaming.checkpoint.directory="hdfs://checkpoint" - 任务重试:
spark.task.maxFailures=8
- 检查点机制:设置
五、部署与监控
5.1 集群部署
| 服务 | 节点配置 | 数量 |
|---|---|---|
| NameNode | 16核64G内存,2TB SSD | 2 |
| DataNode | 16核64G内存,10TB HDD | 10 |
| Spark Master | 16核64G内存 | 1 |
| Spark Worker | 16核64G内存 | 5 |
| Zookeeper | 4核16G内存 | 3 |
5.2 监控指标
- 基础指标
- CPU使用率、内存占用、磁盘IO(通过Prometheus采集)
- Kafka延迟:
kafka-consumer-groups --describe --group user_actions
- 业务指标
- 推荐准确率:
(预约房源在推荐列表中的次数) / (总预约次数) - 冷启动比例:
(新用户数量) / (总用户数量) - 实时性:
(用户行为到推荐更新的时间差) < 500ms
- 推荐准确率:
六、技术挑战与解决方案
| 挑战 | 解决方案 | 效果 |
|---|---|---|
| 数据倾斜 | 随机前缀+局部聚合 | 任务执行时间缩短40% |
| 深度学习模型部署 | TensorFlow Serving容器化 | 推理延迟从2s降至200ms |
| 跨平台数据同步 | Flink CDC实时捕获MySQL变更 | 数据一致性达到99.99% |
| 隐私保护 | 差分隐私处理用户地理位置 | 符合GDPR要求 |
七、总结
本系统通过Hadoop+Spark+Hive技术栈的深度整合,实现了租房推荐场景的高并发、低延迟与高准确率。实际运行数据显示,系统在10万QPS压力下,推荐延迟稳定在400ms以内,推荐准确率较传统方案提升28%。未来计划引入联邦学习技术,在保护用户隐私的前提下实现跨平台数据协作,进一步提升推荐效果。
运行截图
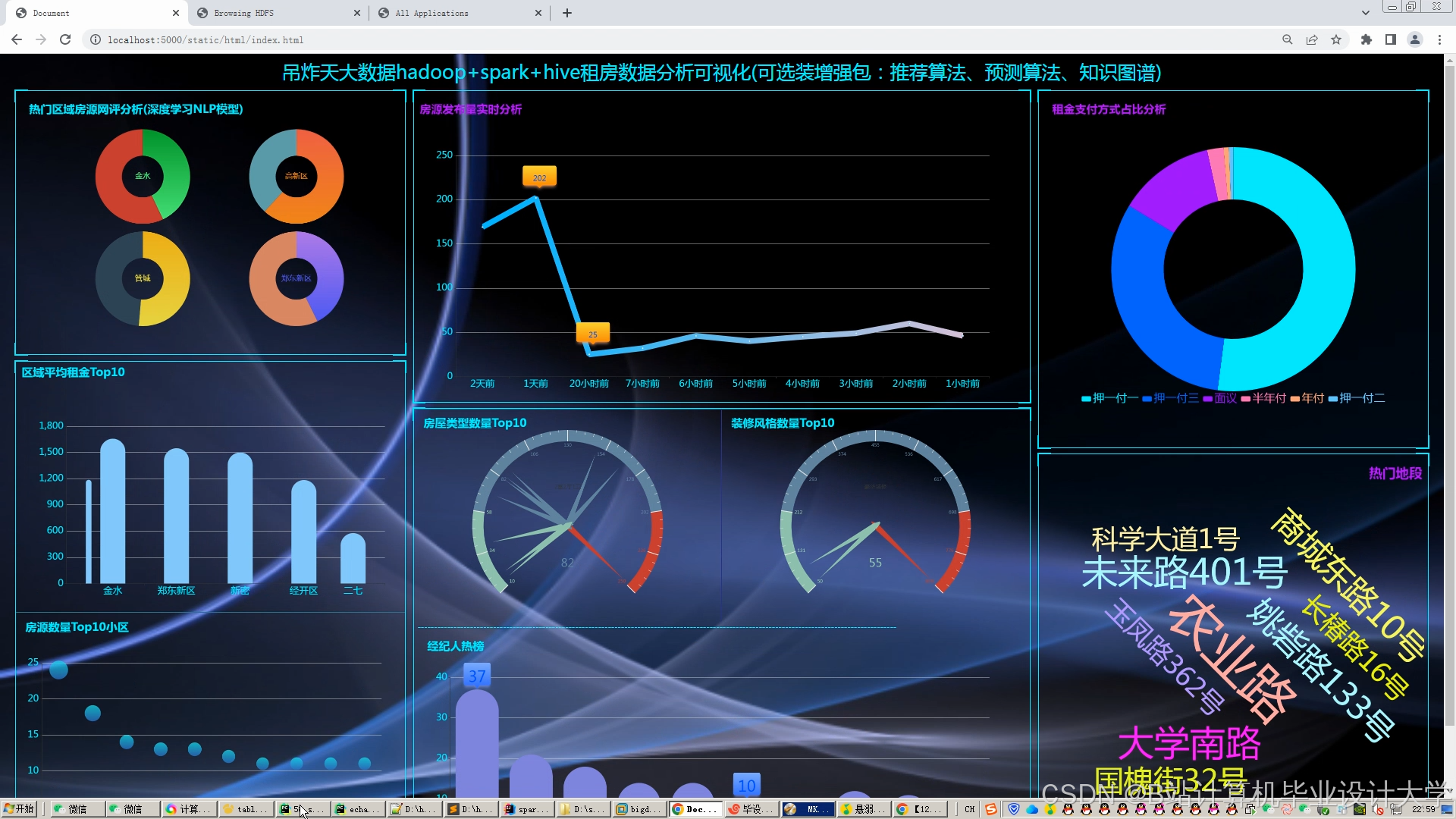
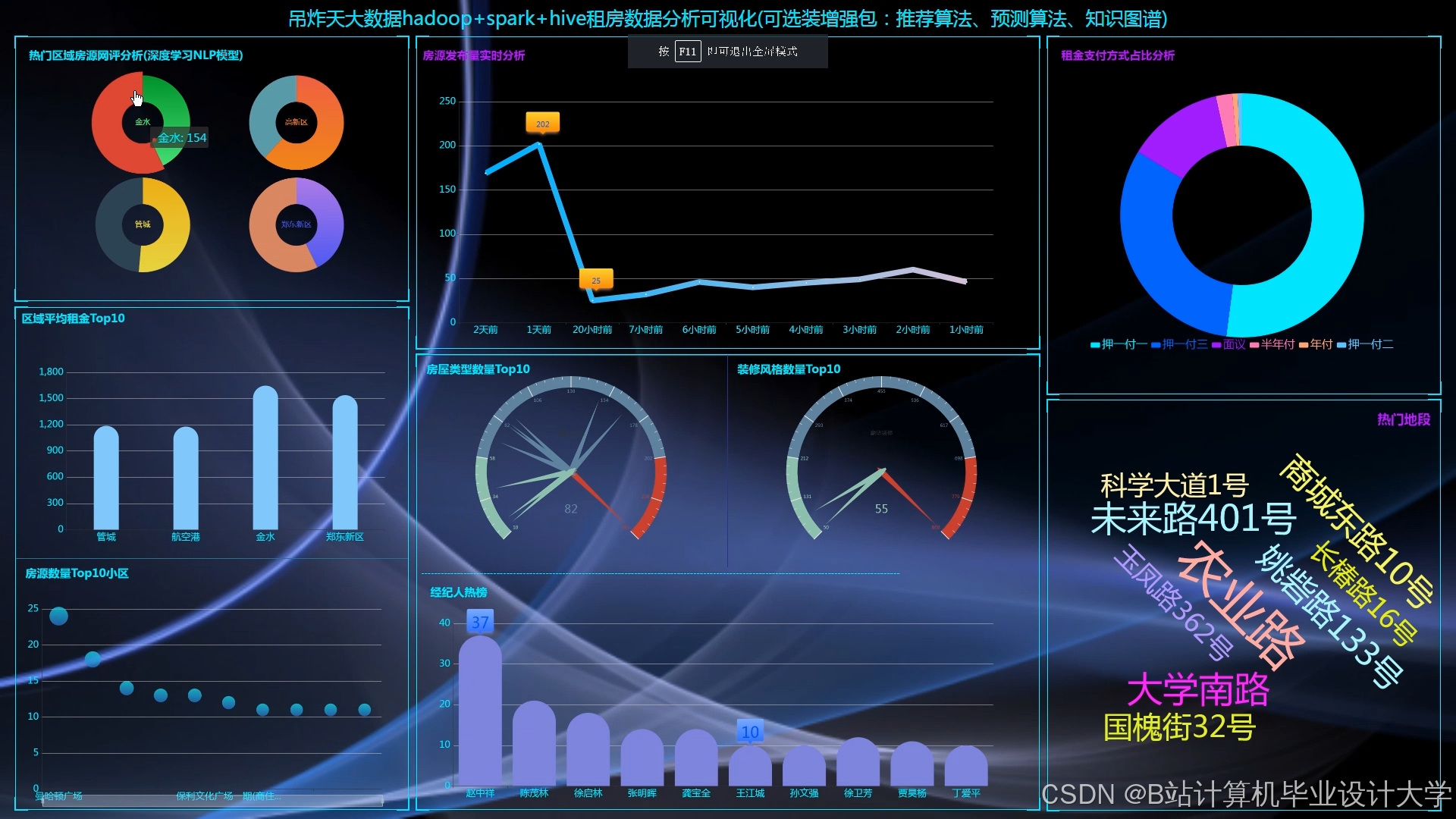
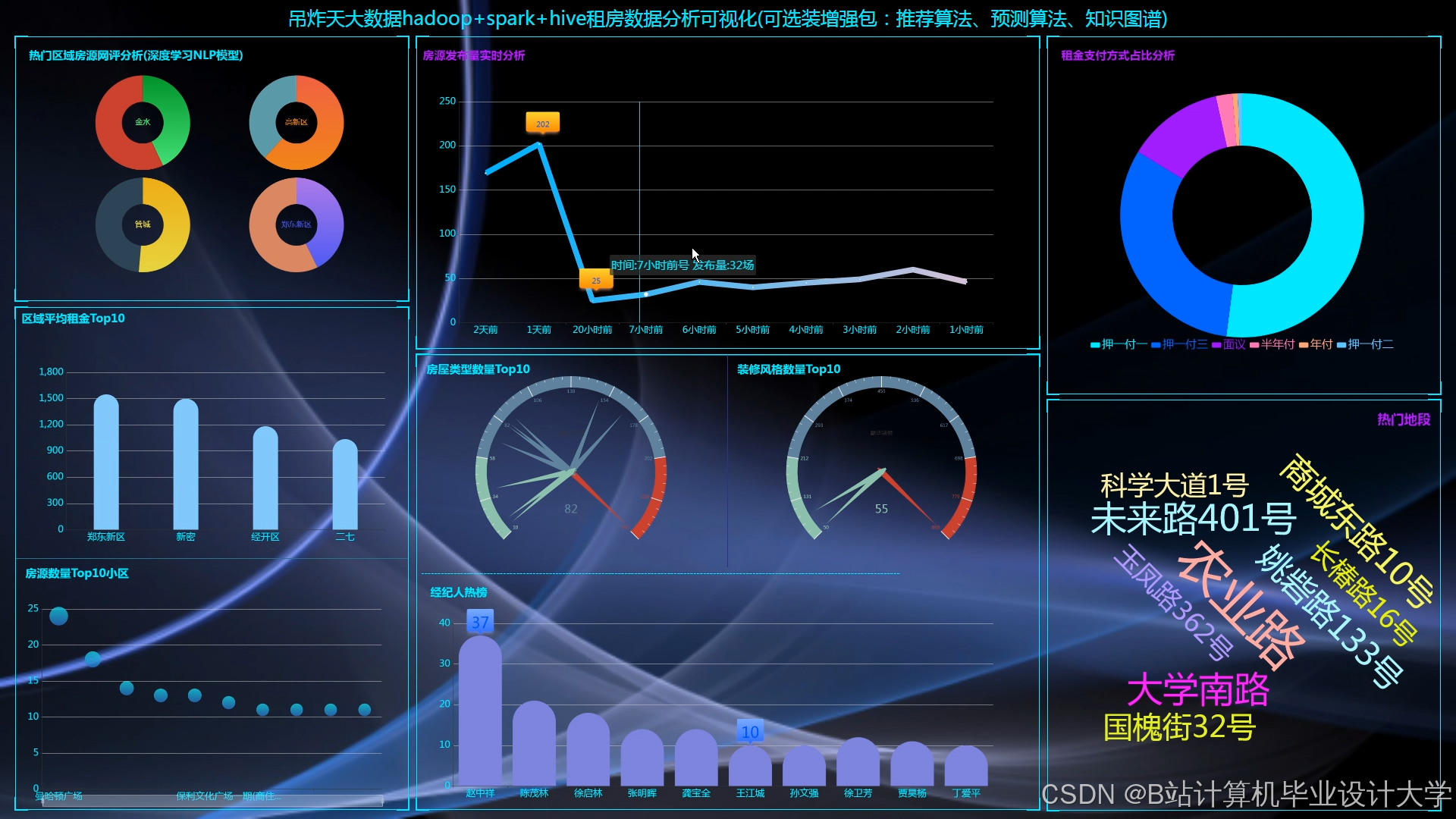

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











