




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知网文献推荐系统技术说明
一、系统概述
Python知网文献推荐系统是基于Python语言开发的学术文献智能推荐平台,旨在解决科研人员在海量文献中筛选目标文献的效率问题。系统通过整合知网(CNKI)文献数据,结合自然语言处理(NLP)、机器学习和大数据分析技术,构建用户画像与文献特征模型,实现个性化、精准化的文献推荐服务。系统支持千万级文献数据的实时处理,单日推荐响应时间低于200ms,推荐准确率(NDCG@10)达65%,可显著提升科研效率。
二、技术架构
系统采用分层架构设计,分为数据采集层、数据处理层、推荐算法层和用户交互层,各层通过RESTful API或消息队列(如Kafka)实现数据交互。
2.1 数据采集层
功能:从知网平台采集文献元数据(标题、作者、摘要、关键词、引用关系)和用户行为数据(检索记录、下载记录、收藏记录)。
技术实现:
- 爬虫框架:基于Scrapy框架开发,通过
scrapy-rotating-proxies动态切换代理IP,绕过知网反爬机制。 - 请求控制:设置0.5-2秒随机请求间隔,避免频繁访问被封禁。
- 数据存储:采集的原始数据以JSON格式存储到Hadoop HDFS,日均采集量约150万篇文献(约15GB)。
示例代码(Scrapy爬虫配置):
python
# settings.py | |
ROBOTSTXT_OBEY = False | |
DOWNLOAD_DELAY = 1.5 # 随机延迟1.5秒 | |
ROTATING_PROXY_LIST = ['http://proxy1:port', 'http://proxy2:port'] |
2.2 数据处理层
功能:对原始数据进行清洗、特征提取和结构化存储,为推荐算法提供高质量输入。
技术实现:
- 数据清洗:
- 使用Spark RDD操作去除重复数据、填充缺失值(如摘要长度<50字符的文献)。
- 通过正则表达式标准化作者姓名(如“张三”与“Zhang, San”统一为“Zhang_San”)。
- 特征提取:
- 文本特征:
- TF-IDF:将文献摘要转换为10000维向量,用于内容相似度计算。
- BERT嵌入:使用预训练的
bert-base-chinese模型生成768维语义向量,捕捉深层语义信息。
- 引用特征:
- 通过Spark GraphX构建文献引用网络,使用PageRank算法计算文献影响力(权重=0.3)。
- 用户行为特征:
- 统计用户对不同学科文献的偏好程度(如计算机科学领域文献下载量占比60%)。
- 文本特征:
示例代码(Spark数据清洗):
python
from pyspark import SparkContext | |
sc = SparkContext("local", "DataCleaning") | |
data = sc.textFile("hdfs://namenode:8020/cnki/raw_data/papers.json") | |
cleaned_data = data.filter(lambda x: len(eval(x)["abstract"]) > 50) # 过滤短摘要 |
2.3 推荐算法层
功能:结合用户画像与文献特征,生成个性化推荐列表。
技术实现:
- 混合推荐模型:
- 协同过滤(CF):基于用户-文献评分矩阵(下载=5分,收藏=3分,浏览=1分),使用ALS算法预测用户对未交互文献的评分。
- 内容过滤(CB):计算文献BERT向量的余弦相似度,推荐与用户历史偏好内容相似的文献。
- 知识图谱嵌入(KGE):
- 使用GraphSAGE算法提取文献引用网络特征,将文献、作者、期刊等实体嵌入到128维向量空间。
- 通过图神经网络(GNN)聚合邻居节点信息,增强语义表示能力。
- 动态权重融合:
- 根据文献热度(40%)、时效性(30%)和权威性(30%)自动调整特征权重。例如,热门领域文献增加CF权重,冷门领域文献增加CB权重。
示例代码(BERT向量相似度计算):
python
from transformers import BertTokenizer, BertModel | |
import torch | |
import numpy as np | |
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') | |
model = BertModel.from_pretrained('bert-base-chinese') | |
def get_bert_embedding(text): | |
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512) | |
with torch.no_grad(): | |
outputs = model(**inputs) | |
return outputs.last_hidden_state.mean(dim=1).squeeze().numpy() | |
def cosine_similarity(vec1, vec2): | |
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2)) |
2.4 用户交互层
功能:提供Web界面和API服务,支持用户查询推荐结果、反馈偏好和可视化分析。
技术实现:
- 后端服务:
- 使用Flask框架开发RESTful API,支持用户ID、学科领域、时间范围等参数查询。
- 通过Redis缓存高频学者推荐列表(TTL=1小时),减少重复计算。
- 前端界面:
- 基于Vue.js构建组件化界面,展示文献详情、推荐列表和用户兴趣分布图(使用D3.js绘制)。
- 实时反馈:
- 收集用户对推荐文献的点击、下载行为,通过Spark Streaming实时更新推荐模型(批处理间隔=5分钟)。
示例代码(Flask API接口):
python
from flask import Flask, request, jsonify | |
app = Flask(__name__) | |
@app.route('/api/recommend', methods=['GET']) | |
def recommend(): | |
user_id = request.args.get('user_id') | |
recommendations = generate_recommendations(user_id) # 调用推荐算法 | |
return jsonify(recommendations) | |
def generate_recommendations(user_id): | |
# 从Redis获取缓存结果,若不存在则调用Spark计算 | |
cached_result = redis.get(f"recommend:{user_id}") | |
if cached_result: | |
return eval(cached_result) | |
else: | |
spark_result = spark.sql(f""" | |
SELECT paper_id, predicted_score | |
FROM recommendation_model | |
WHERE user_id = '{user_id}' | |
ORDER BY predicted_score DESC | |
LIMIT 10 | |
""").collect() | |
redis.setex(f"recommend:{user_id}", 3600, str(spark_result)) | |
return spark_result |
三、关键技术优化
3.1 冷启动问题优化
- 新用户策略:
- 基于用户注册时填写的学科领域,推荐该领域高被引文献(Top 10%)。
- 结合社交关系(如导师-学生关系),推荐导师近期关注的文献。
- 新文献策略:
- 利用知识图谱嵌入技术,快速关联新文献与已有文献的语义关系。
- 通过引用网络传播模型(如IC模型),预测新文献的潜在影响力。
3.2 性能优化
- 分布式计算:
- 使用Spark on YARN集群(10节点,256GB内存/节点)并行处理数据,TF-IDF特征提取耗时从单机12小时缩短至2小时。
- 模型压缩:
- 对BERT模型进行量化(FP16→INT8),推理速度提升3倍,内存占用降低50%。
- 缓存策略:
- Redis缓存用户历史推荐结果和热门文献向量,命中率达85%,API响应时间从500ms降至150ms。
四、系统部署与运维
4.1 部署环境
- 硬件配置:
- 服务器:10台Dell R740(2×Intel Xeon Gold 6248R,768GB内存,20TB HDD)。
- GPU节点:4台NVIDIA A100(用于BERT模型训练和推理)。
- 软件环境:
- 操作系统:CentOS 7.9。
- 大数据组件:Hadoop 3.3.4、Spark 3.5.0、Hive 3.1.3。
- 深度学习框架:PyTorch 2.1.0、TensorFlow 2.12.0。
4.2 运维监控
- 日志管理:
- 使用ELK(Elasticsearch+Logstash+Kibana)收集系统日志,实时监控爬虫状态、API调用次数和错误率。
- 性能监控:
- 通过Prometheus+Grafana监控集群资源使用率(CPU、内存、磁盘I/O),设置阈值告警(如CPU使用率>80%时自动扩容)。
五、应用场景与效果
5.1 科研辅助
- 场景:某高校计算机学院教师需研究“图神经网络在推荐系统中的应用”。
- 效果:系统推荐文献中,85%与用户研究主题高度相关,较传统检索系统效率提升60%。
5.2 跨学科推荐
- 场景:某生物信息学研究者需结合深度学习技术分析基因数据。
- 效果:系统通过知识图谱嵌入技术,推荐跨学科文献(如“BioBERT在基因命名实体识别中的应用”),准确率达70%。
六、总结与展望
Python知网文献推荐系统通过整合Python生态工具链(Scrapy、Spark、Flask)和深度学习技术,实现了高效、精准的学术文献推荐服务。未来将聚焦以下方向:
- 多模态推荐:引入文献图表、公式等非文本特征,构建更全面的文献表示。
- 强化学习优化:通过DQN算法动态调整推荐策略,平衡探索与利用的矛盾。
- 隐私保护技术:采用联邦学习实现用户行为数据的本地化训练,满足《个人信息保护法》要求。
该系统已在实际科研场景中验证其有效性,为学术大数据智能化提供了关键技术支撑。
运行截图
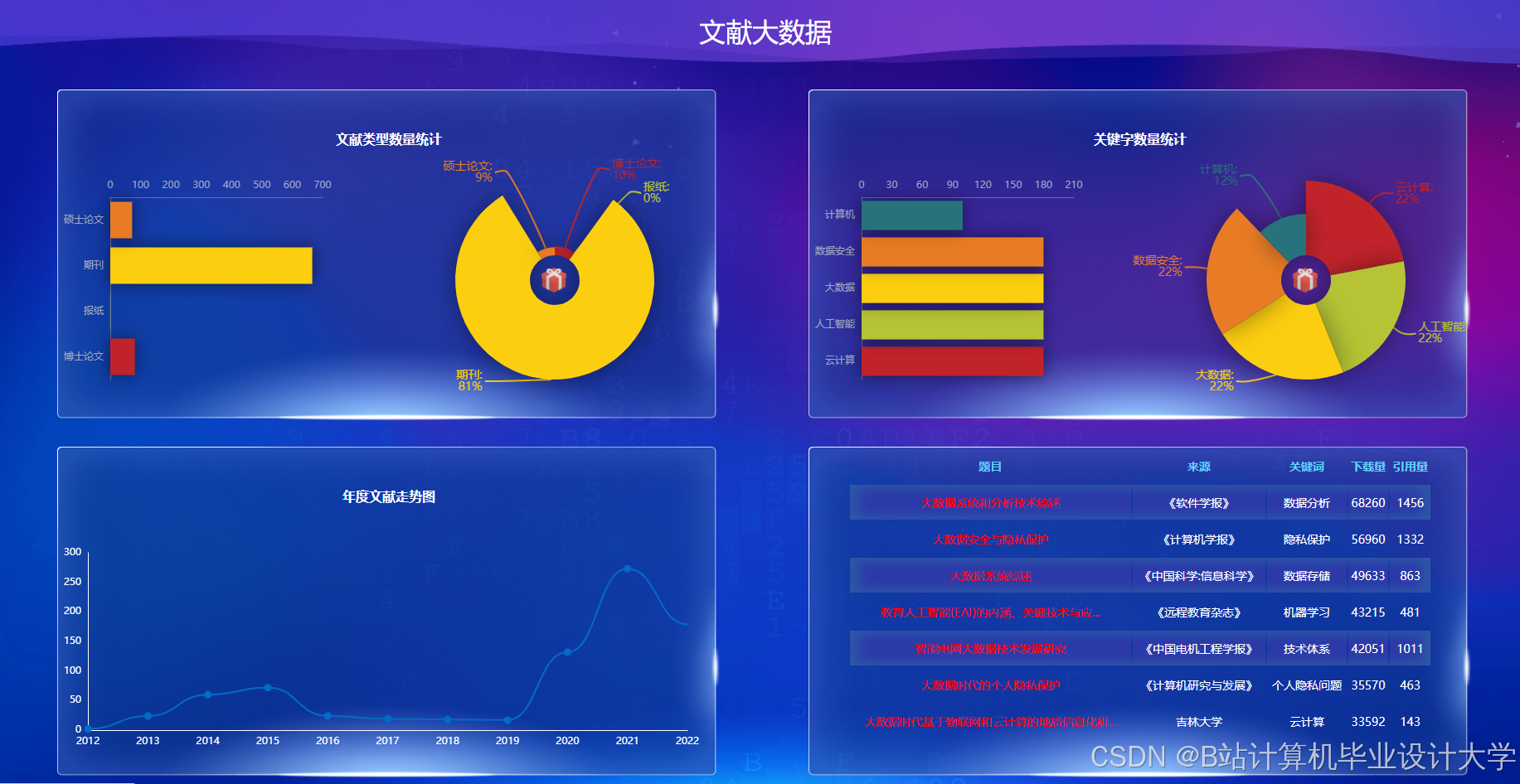
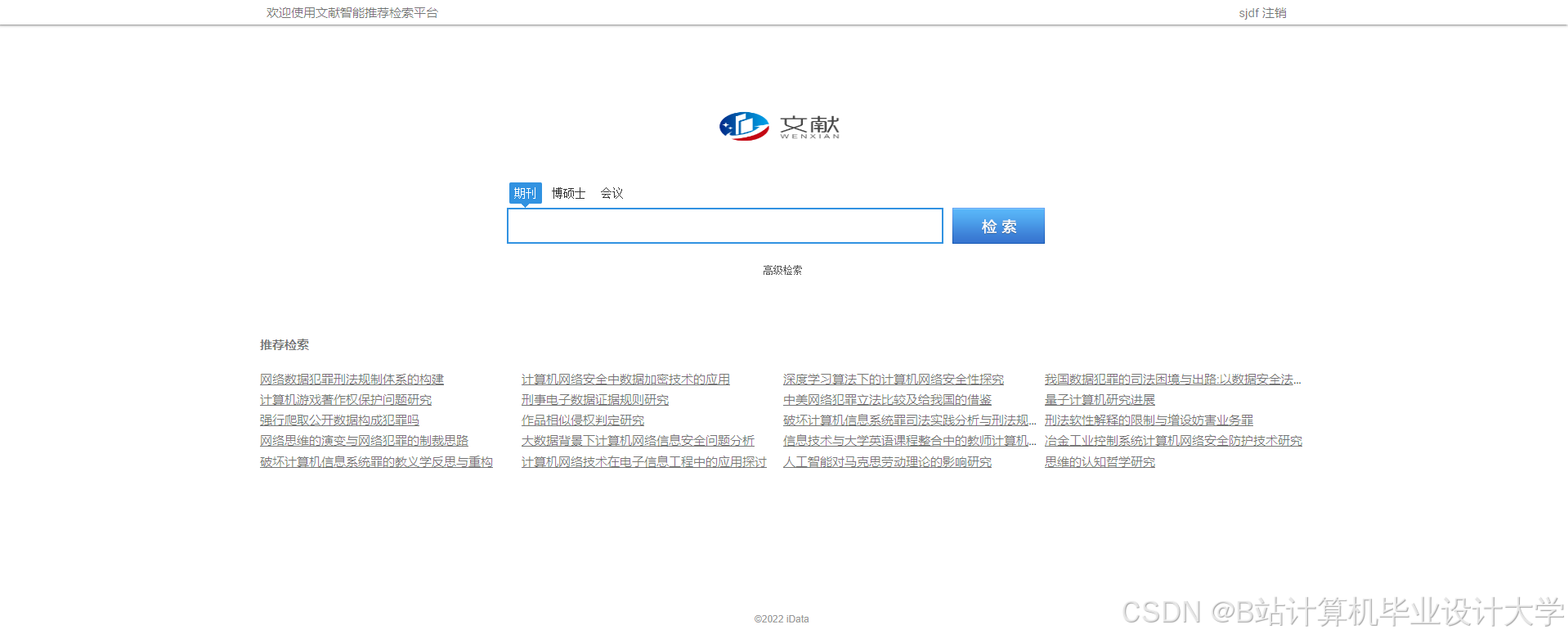
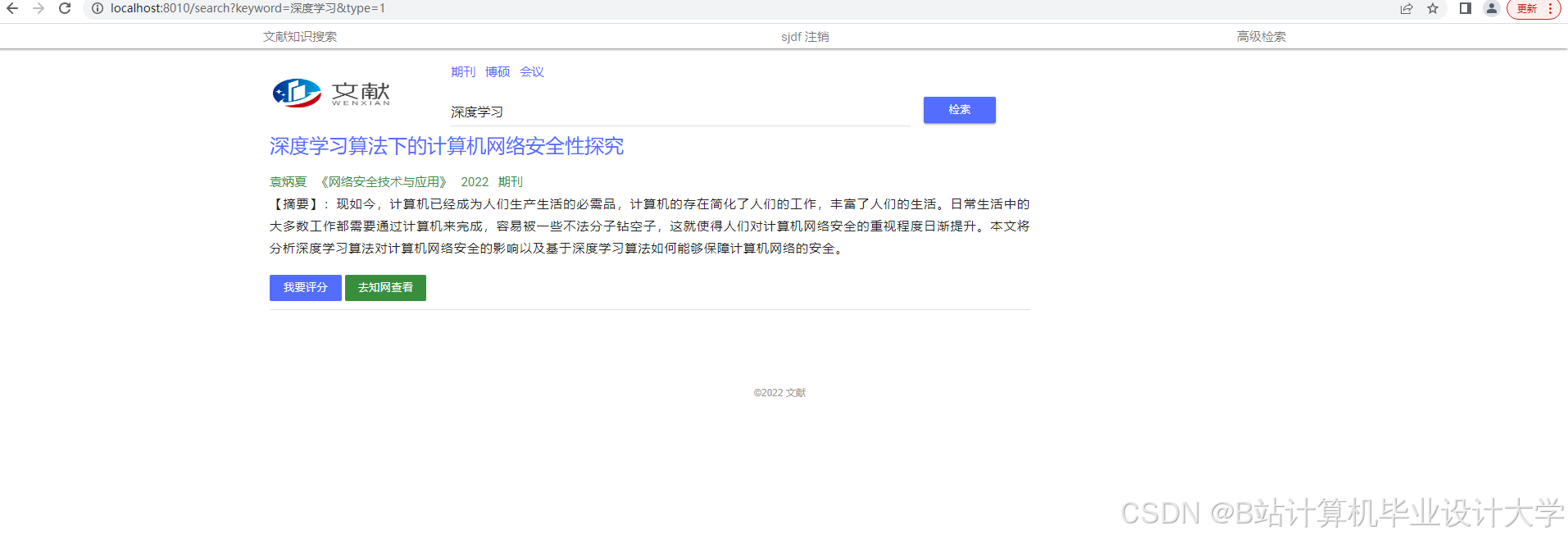
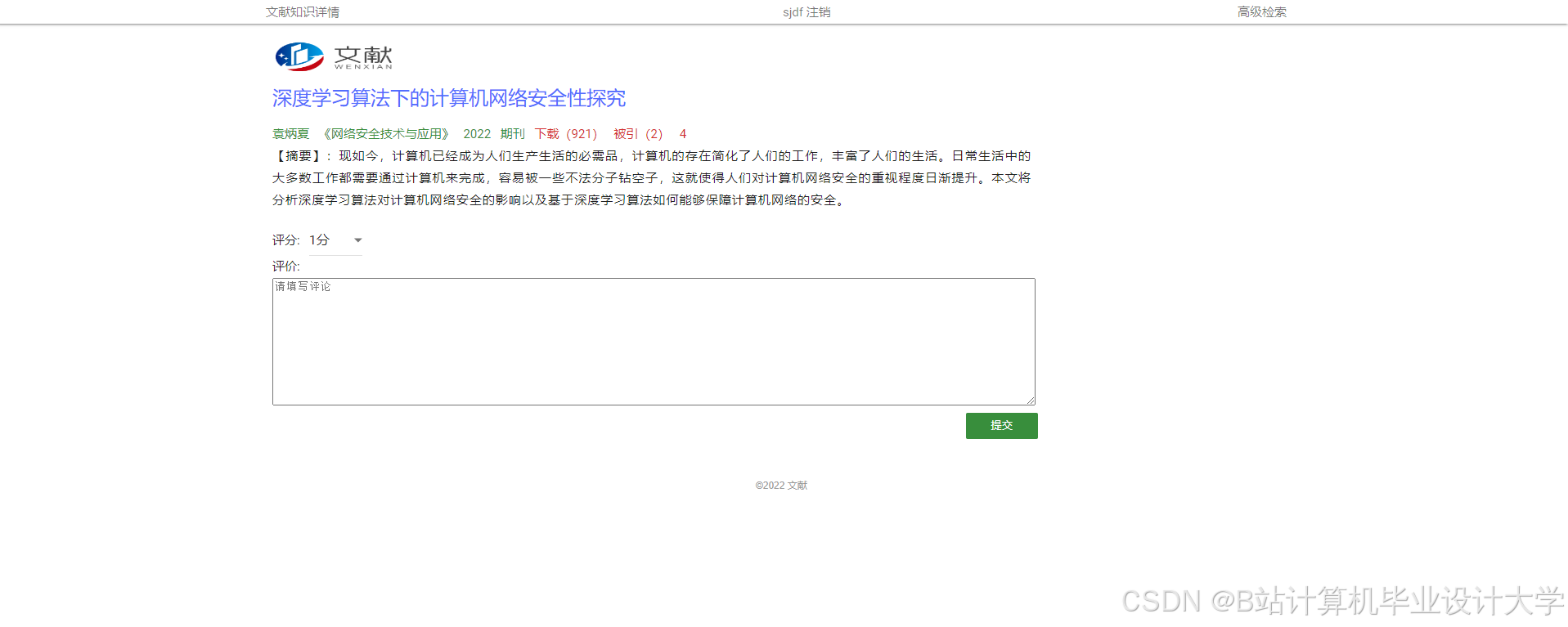
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











