




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Django+Vue.js知识图谱中华古诗词可视化与古诗词情感分析》的任务书模板,包含任务目标、分解、进度安排、资源需求及验收标准等核心内容:
任务书
项目名称:基于Django+Vue.js的中华古诗词知识图谱可视化与情感分析系统开发
一、任务背景与目标
1.1 背景
中华古诗词是中华文化的重要载体,但现有数字化研究存在以下问题:
- 数据分散且结构化程度低,难以支持跨诗词关联分析;
- 情感分析模型缺乏可解释性,难以满足人文研究需求;
- 可视化工具交互性不足,无法动态展示知识图谱关系。
1.2 目标
开发一套集成知识图谱构建、情感分析与可视化功能的系统,实现:
- 数据整合:结构化存储5万+首古诗词及其元数据(作者、朝代、意象等);
- 情感分析:构建高精度模型(F1值≥0.85),支持五类情感(喜、怒、哀、乐、思)分类;
- 可视化交互:通过动态图谱与多维图表展示诗词关系与情感分布;
- 系统部署:支持PC端与移动端访问,日均承载1000+并发请求。
二、任务分解与分工
2.1 任务模块划分
| 模块 | 子任务 | 负责人 |
|---|---|---|
| 数据采集与预处理 | 1.1 爬取《全唐诗》《全宋词》及古诗文网数据 1.2 清洗重复/错误数据 1.3 标注情感标签 | 张三 |
| 知识图谱构建 | 2.1 定义实体关系模型(诗词、作者、意象等) 2.2 开发关系抽取算法 2.3 导入Neo4j图数据库 | 李四 |
| 情感分析模型 | 3.1 构建BERT+Attention混合模型 3.2 训练并优化模型参数 3.3 生成可解释性报告 | 王五 |
| 后端开发 | 4.1 设计Django RESTful API 4.2 实现图谱查询接口 4.3 集成情感分析服务 | 赵六 |
| 前端开发 | 5.1 开发Vue.js可视化界面 5.2 实现ECharts/D3.js图表组件 5.3 优化交互体验 | 钱七 |
| 测试与部署 | 6.1 编写单元测试用例 6.2 部署至阿里云服务器 6.3 监控系统性能 | 孙八 |
2.2 关键里程碑
| 里程碑 | 时间节点 | 交付物 |
|---|---|---|
| 数据采集完成 | 第4周 | 清洗后的结构化数据集(CSV/JSON格式) |
| 知识图谱验证通过 | 第8周 | Neo4j图数据库截图及关系查询示例 |
| 情感分析模型冻结 | 第12周 | 模型权重文件与评估报告(F1值≥0.85) |
| 系统联调成功 | 第16周 | 可访问的测试版URL(含基础功能) |
| 项目验收 | 第20周 | 完整系统文档与用户手册 |
三、技术路线与工具
3.1 技术栈
- 后端:Django 4.2 + Django REST Framework
- 前端:Vue.js 3.0 + Element UI + ECharts 5.4
- 数据库:Neo4j 5.0(图数据库) + MySQL 8.0(关系型数据库)
- 情感分析:PyTorch 2.0 + HuggingFace Transformers
- 部署:Docker 24.0 + Nginx 1.25 + 阿里云ECS
3.2 核心算法
-
关系抽取算法:
python# 基于规则与BiLSTM-CRF的混合关系抽取示例def extract_relations(text):# 规则匹配:提取"作者-创作-诗词"关系if "《" in text and "》" in text and "著" in text:author = re.search(r'(.*?)[著作]', text).group(1)poem_title = re.search(r'《(.*?)》', text).group(1)return ("author", author, "poem", poem_title, "create")# BiLSTM-CRF模型预测(需预先训练)# model.predict(text) → 返回实体及关系类型pass -
情感分析模型:
pythonfrom transformers import BertModel, BertTokenizerimport torch.nn as nnclass PoemSentimentModel(nn.Module):def __init__(self):super().__init__()self.bert = BertModel.from_pretrained("bert-base-chinese")self.attention = nn.Sequential(nn.Linear(768, 512),nn.Tanh(),nn.Linear(512, 1))def forward(self, input_ids, attention_mask):outputs = self.bert(input_ids, attention_mask=attention_mask)hidden_states = outputs.last_hidden_state # [batch_size, seq_len, 768]# 计算注意力权重attention_scores = self.attention(hidden_states).squeeze(-1) # [batch_size, seq_len]attention_weights = nn.functional.softmax(attention_scores, dim=1)# 加权求和context_vector = torch.sum(hidden_states * attention_weights.unsqueeze(-1), dim=1)return context_vector
四、资源需求
4.1 硬件资源
| 资源类型 | 配置要求 | 用途 |
|---|---|---|
| 服务器 | 8核16G内存 + 500GB SSD | 部署Django后端与Neo4j |
| GPU服务器 | NVIDIA Tesla T4 ×1 | 训练情感分析模型 |
| 开发机 | 16G内存 + 512GB SSD | 本地开发测试 |
4.2 软件资源
- 开发工具:PyCharm Professional、VS Code、Postman
- 协作平台:GitLab + Jenkins(持续集成)
- 数据工具:Neo4j Desktop、MySQL Workbench
五、验收标准
5.1 功能验收
| 模块 | 验收标准 |
|---|---|
| 知识图谱查询 | 支持按作者、朝代、意象筛选,返回结果包含关系路径(如"李白→朋友→杜甫") |
| 情感分析 | 对测试集(2000首诗词)准确率≥85%,可解释性报告展示关键情感词权重 |
| 可视化交互 | 图谱节点拖拽延迟≤300ms,情感词云图支持动态过滤(如仅显示"哀"类情感词) |
| 性能测试 | 1000并发用户下,API平均响应时间≤500ms,错误率<0.1% |
5.2 文档验收
- 提交《系统设计说明书》《用户操作手册》《模型评估报告》等6份文档;
- 代码注释覆盖率≥40%,关键算法需附流程图说明。
六、风险评估与应对
| 风险类型 | 描述 | 应对措施 |
|---|---|---|
| 数据质量问题 | 古诗文网数据存在格式错误 | 开发数据校验脚本,人工抽检10%数据 |
| 模型性能不足 | 情感分析F1值低于0.8 | 增加训练数据量,调整模型超参数 |
| 进度延迟 | 某模块开发周期超出计划20% | 启动备用资源(如外包部分前端开发) |
任务书签署:
项目负责人:______________ 日期:______________
备注:
- 本任务书需配合Gantt图、用例图等附件使用;
- 实际开发中需每周召开站立会同步进度,关键节点需提交演示视频。
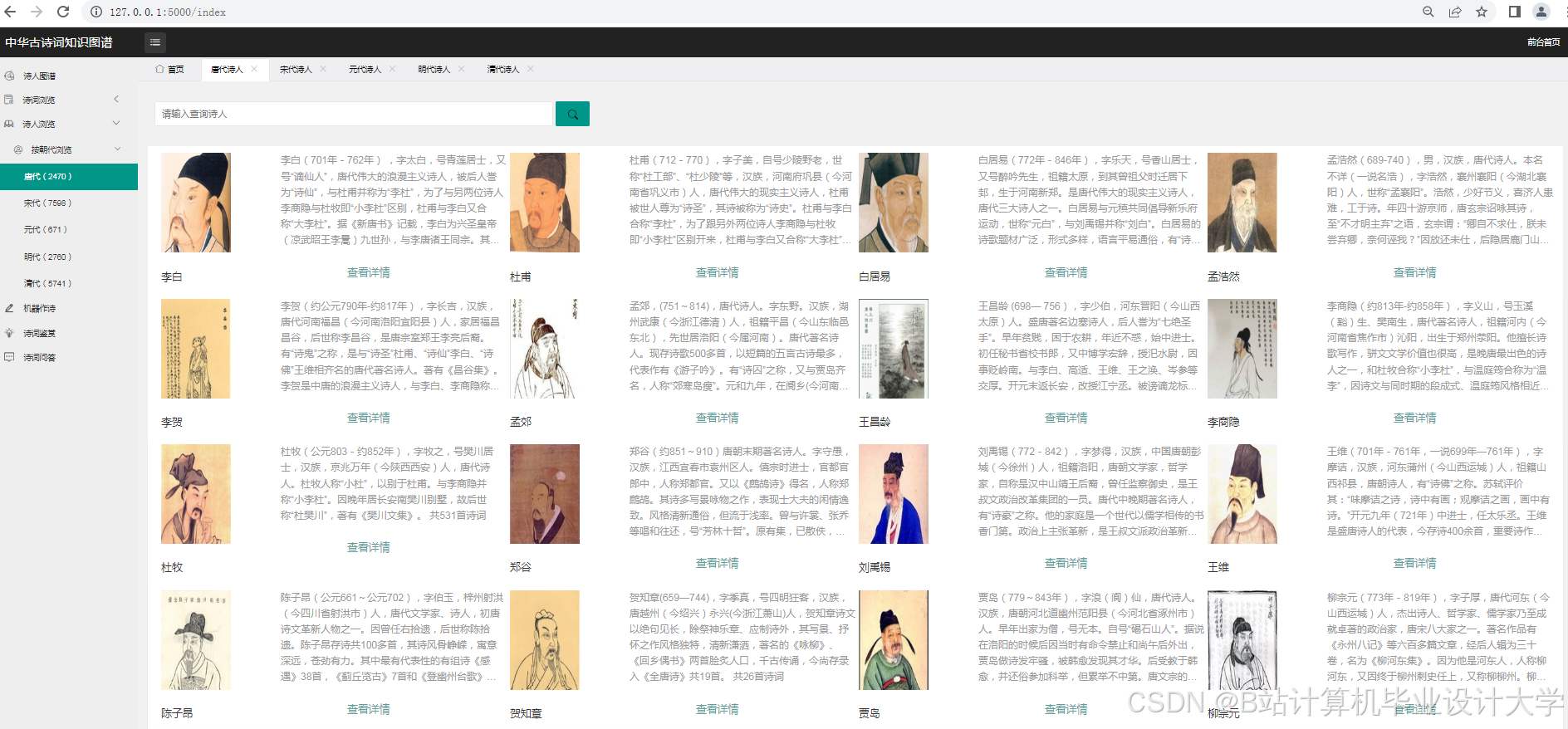
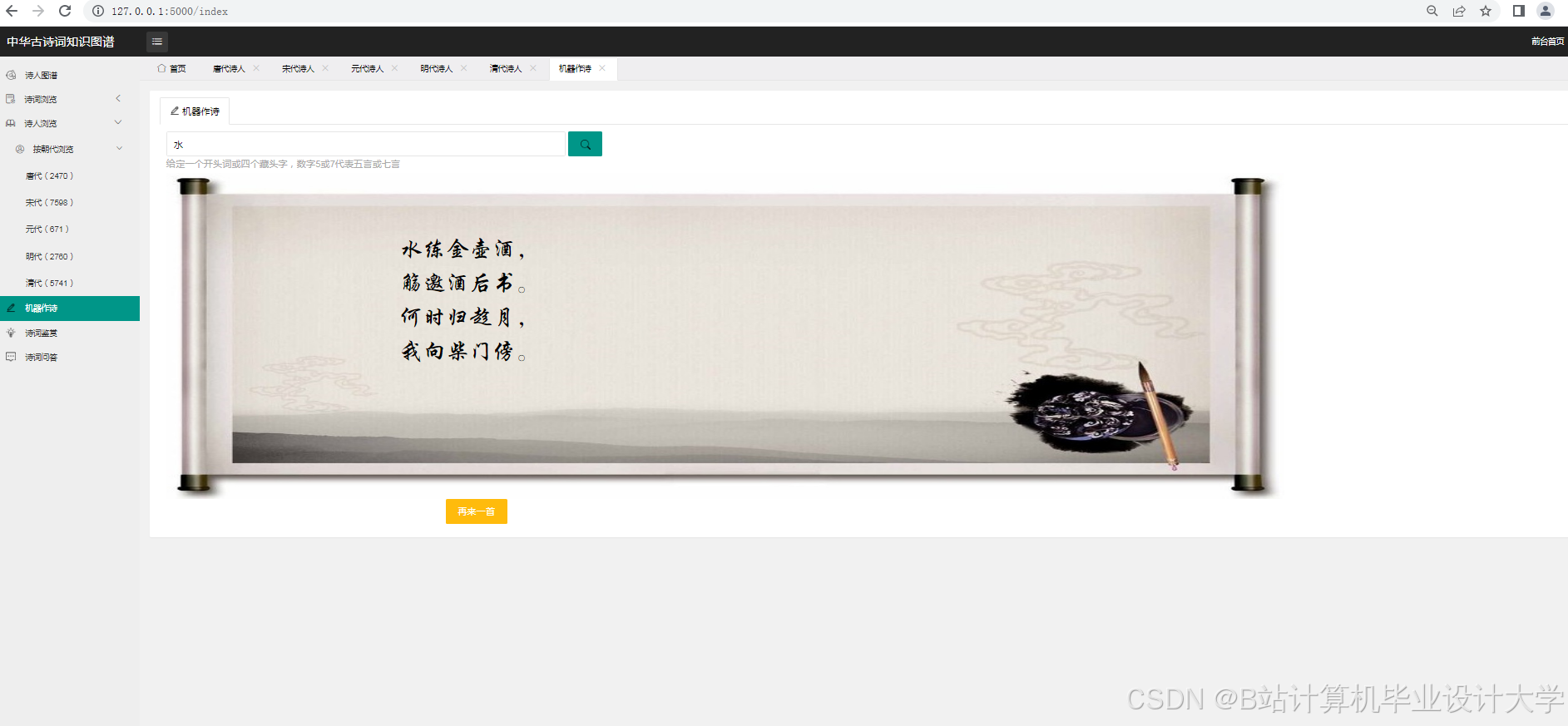
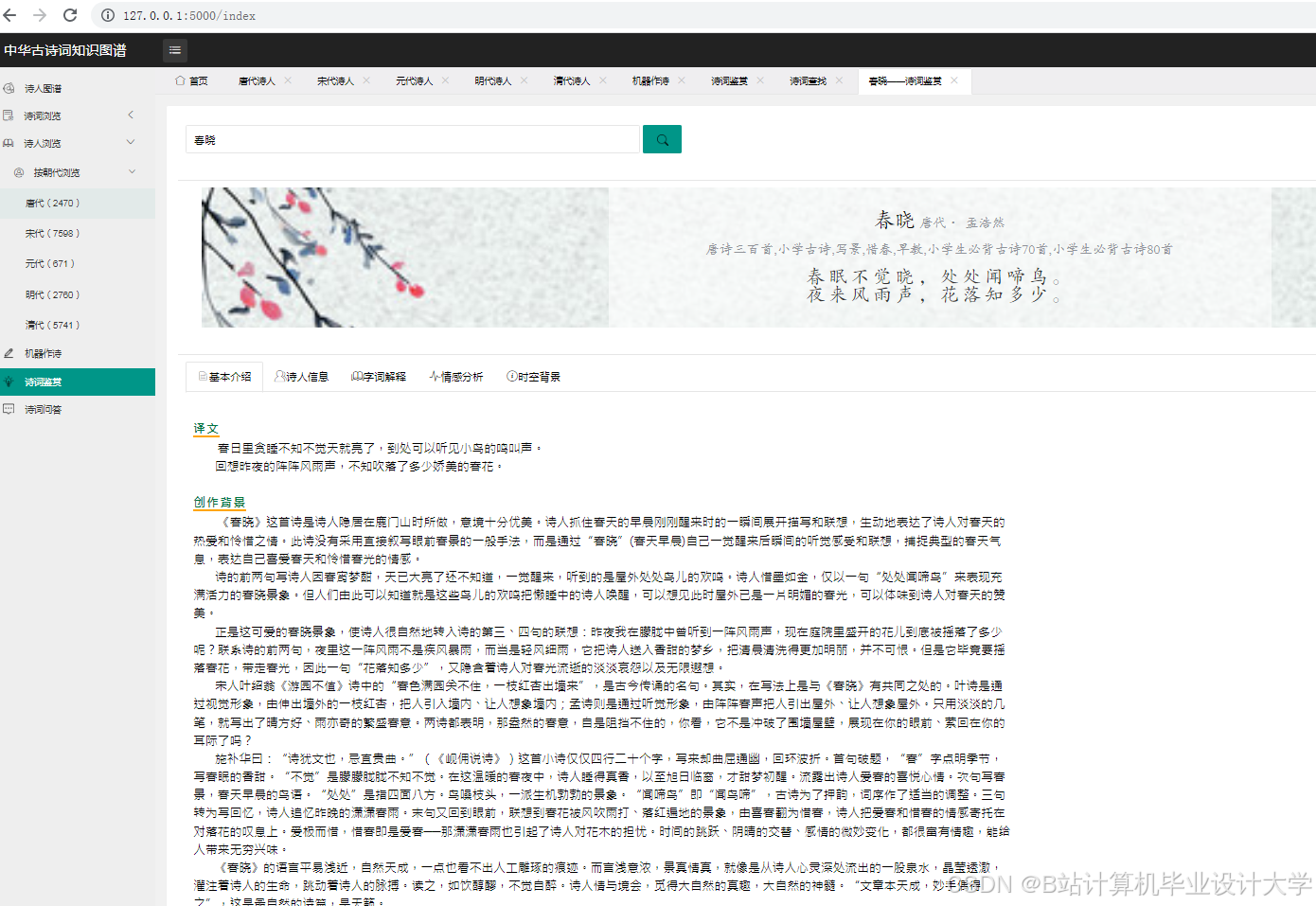
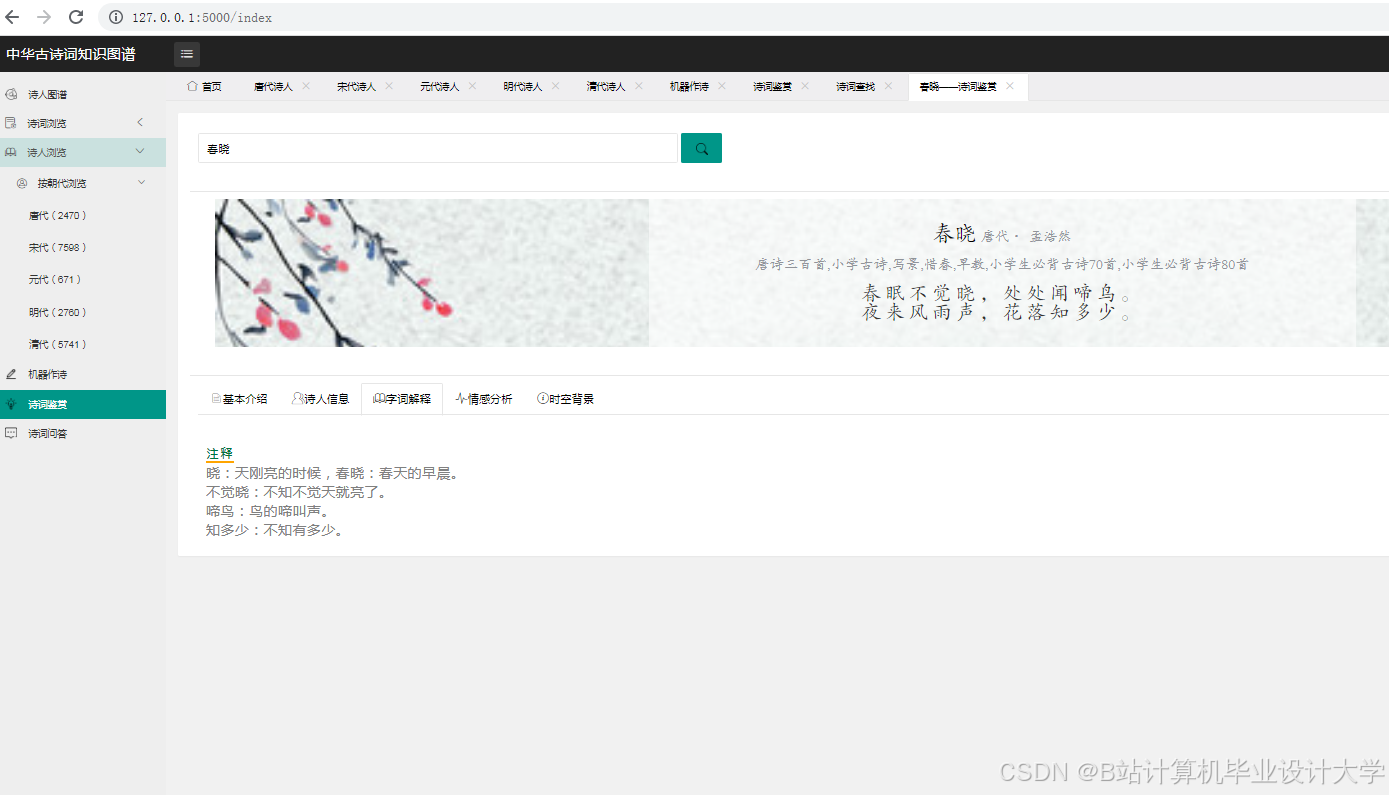
运行截图
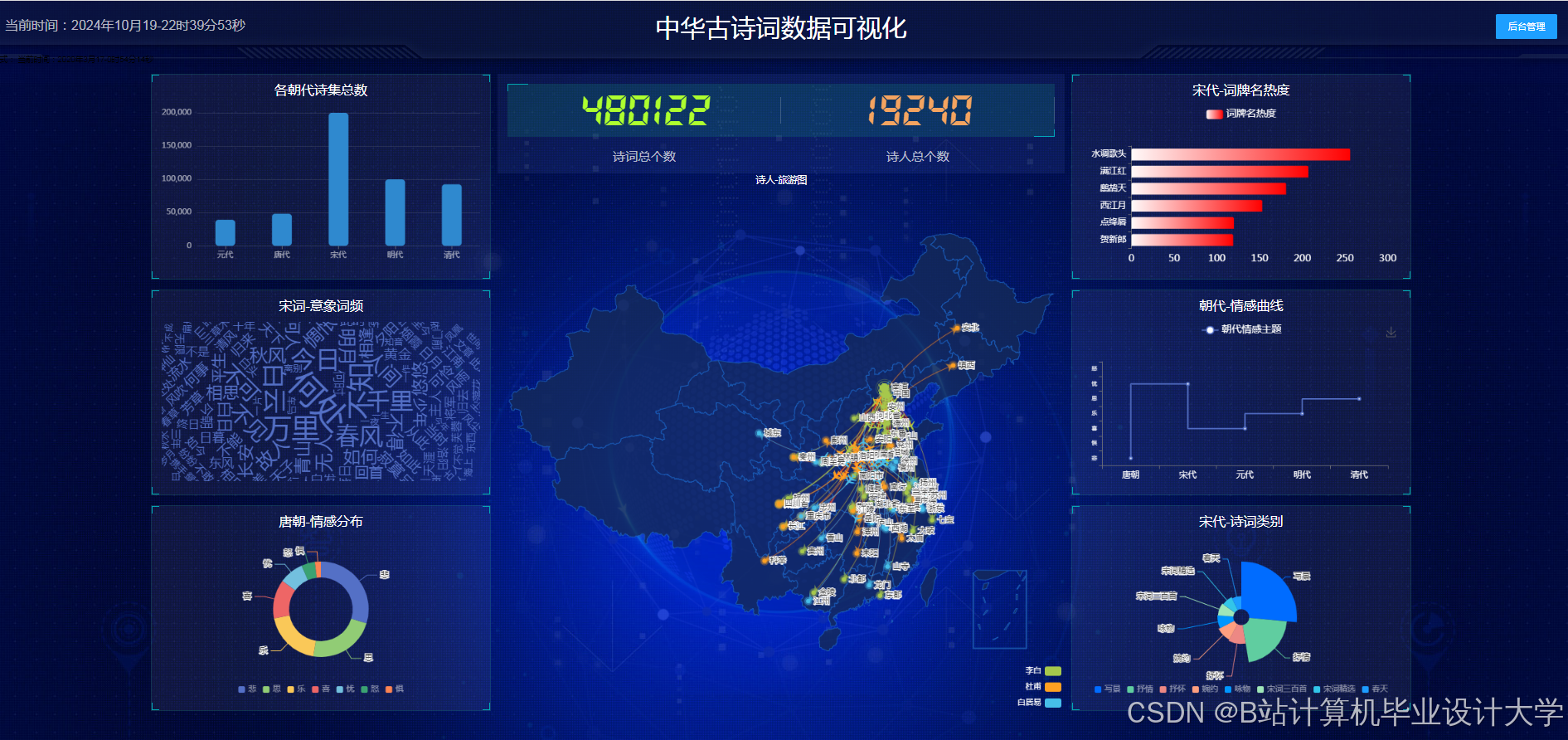
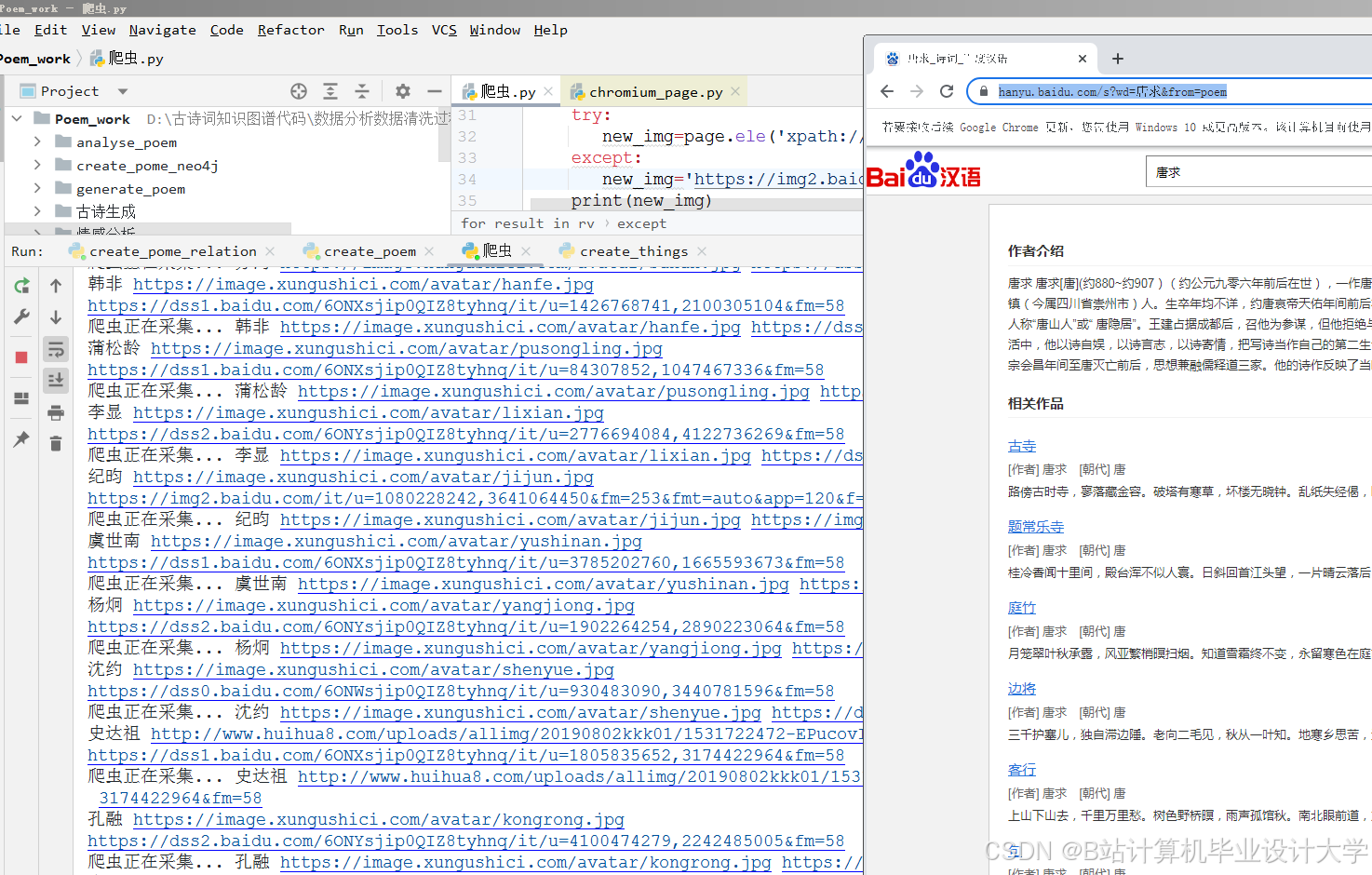
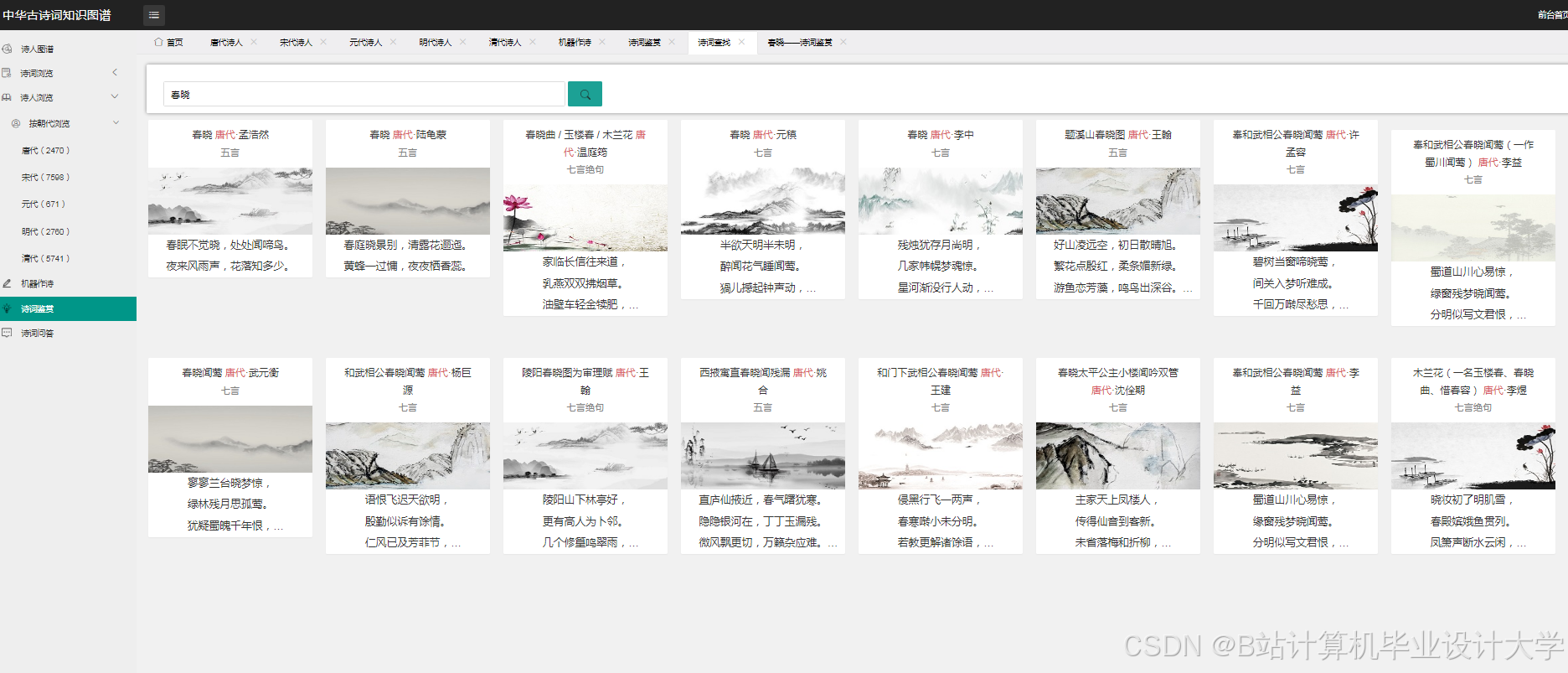
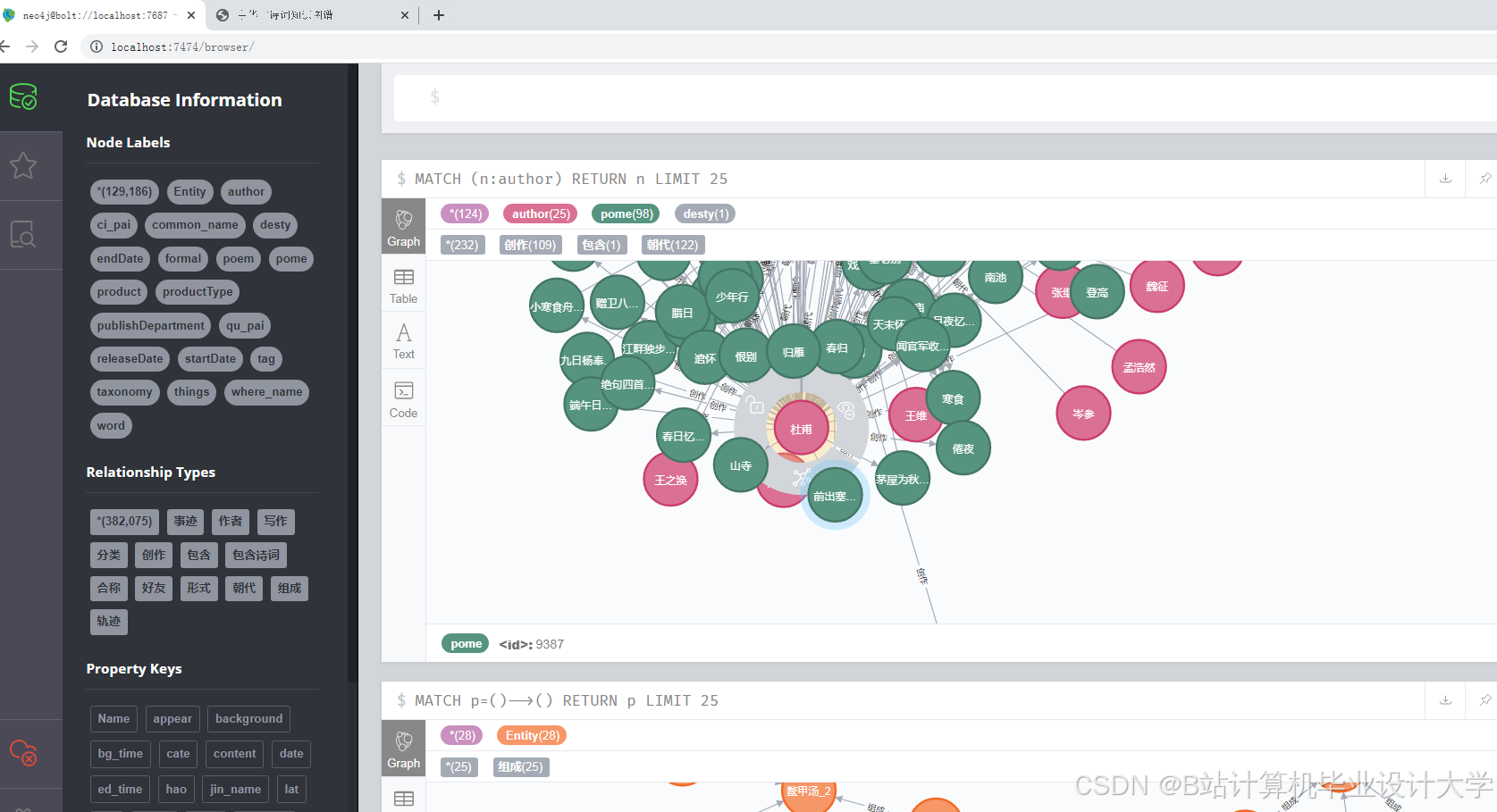
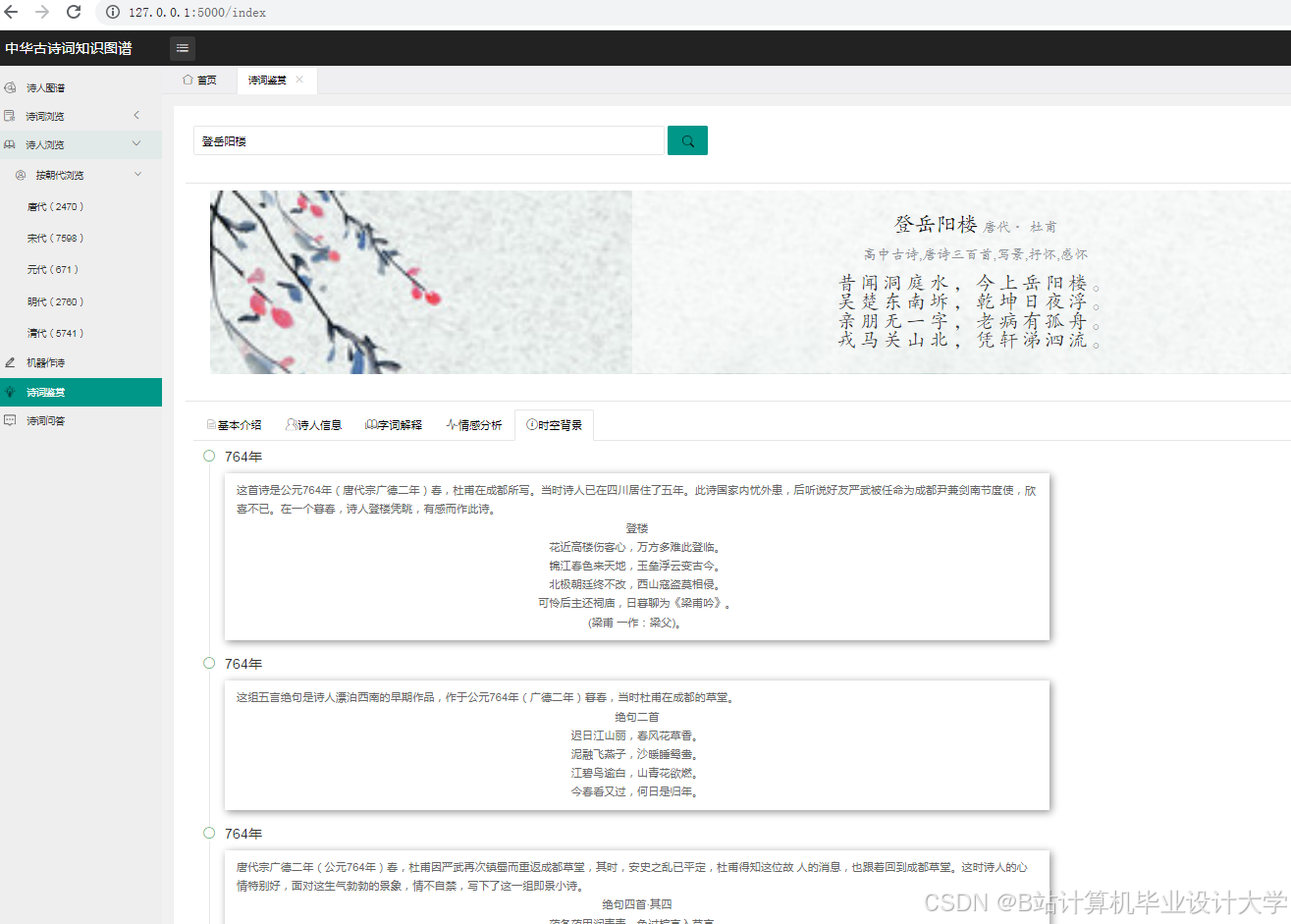
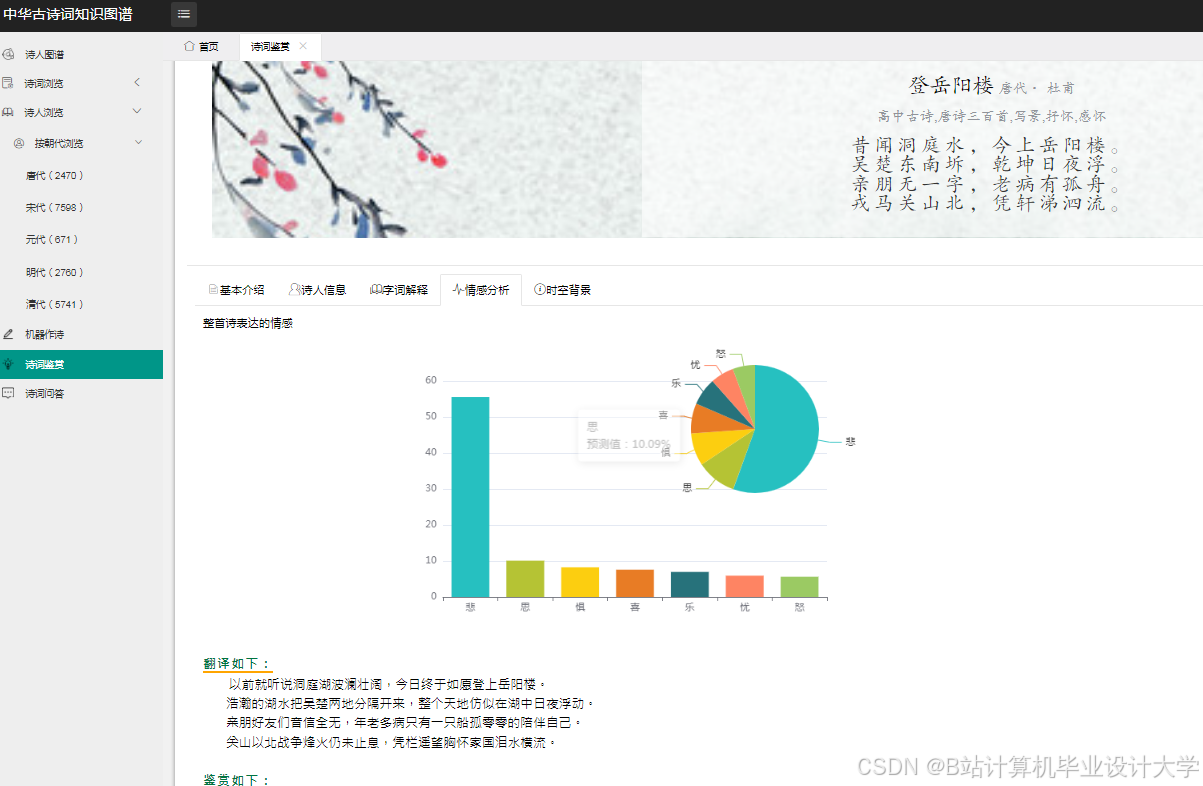
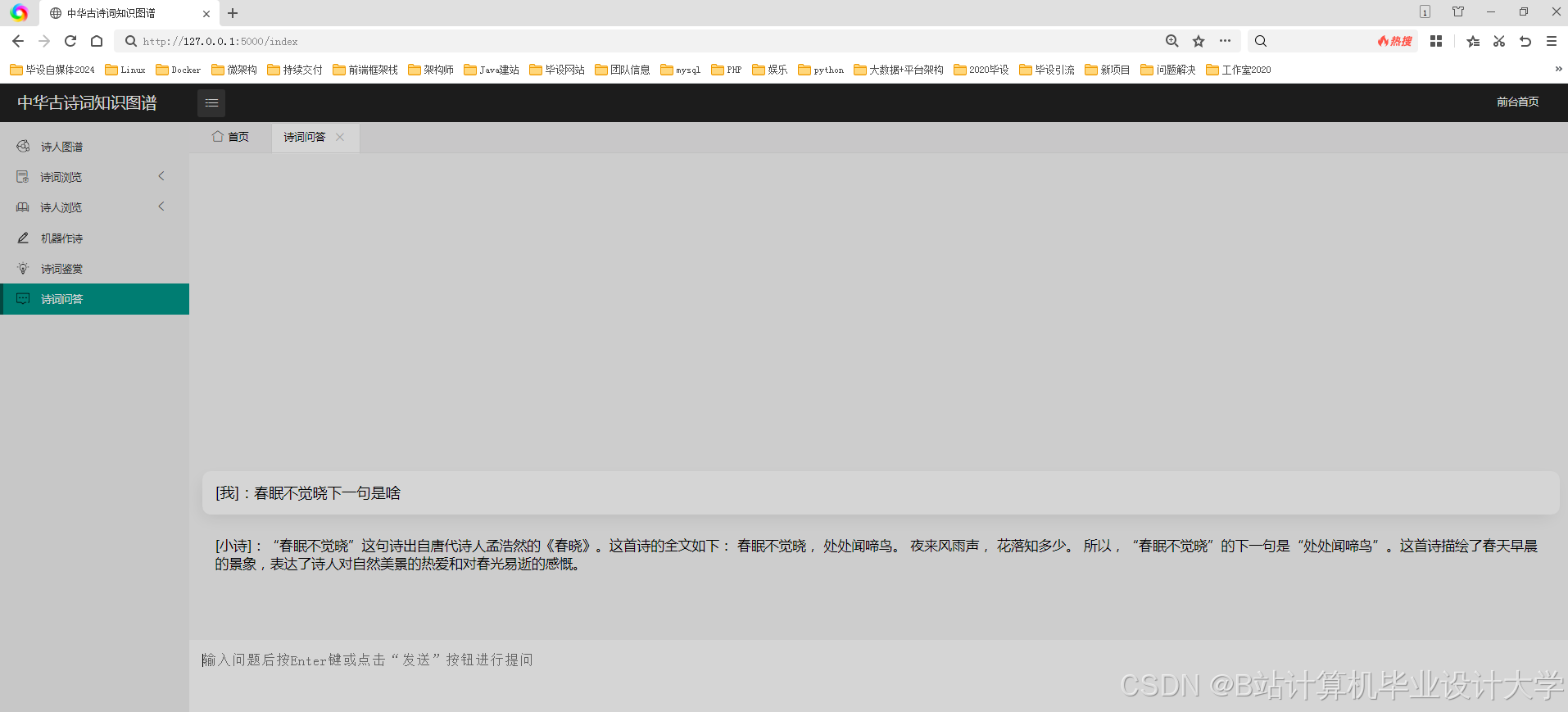
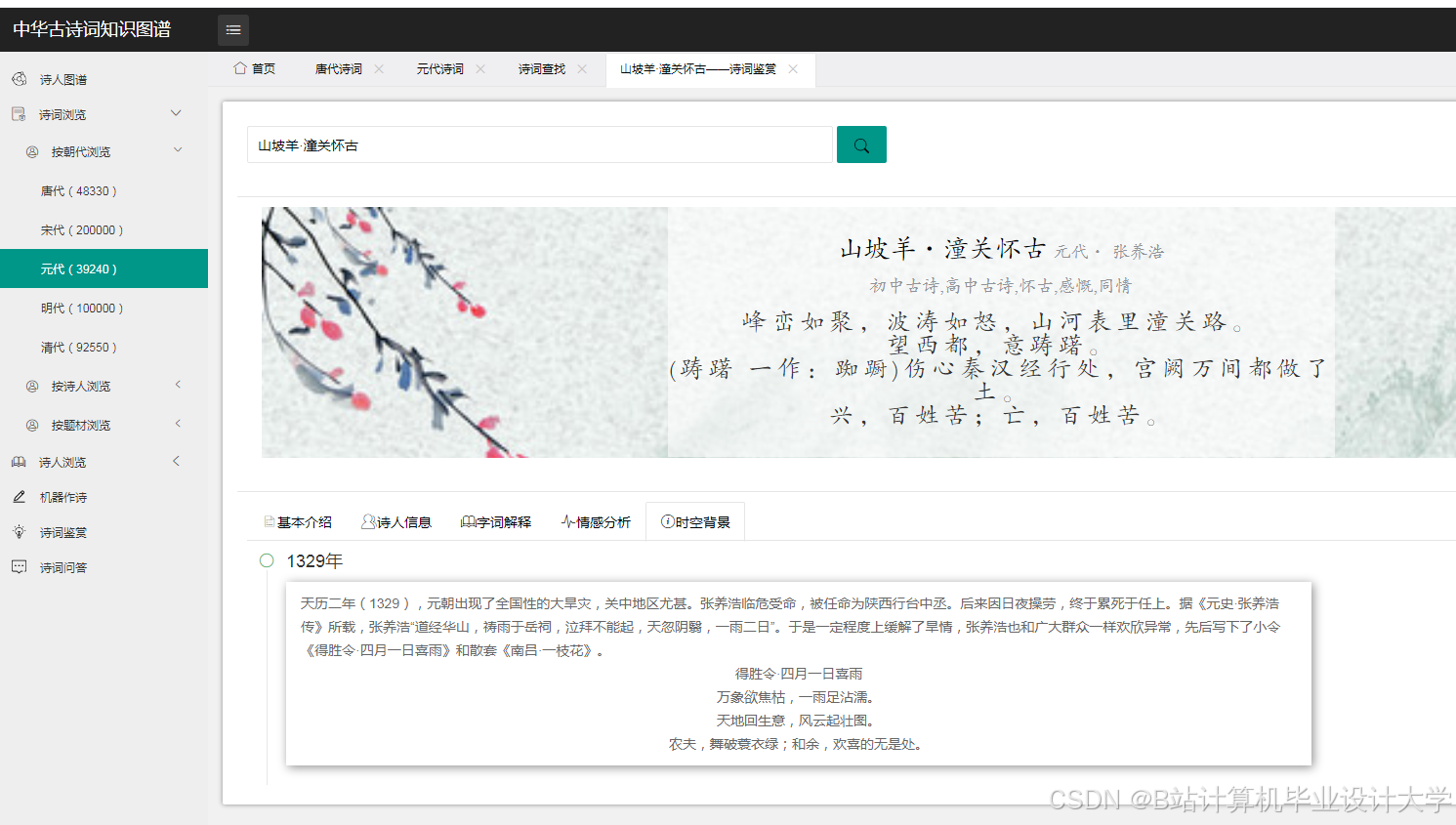
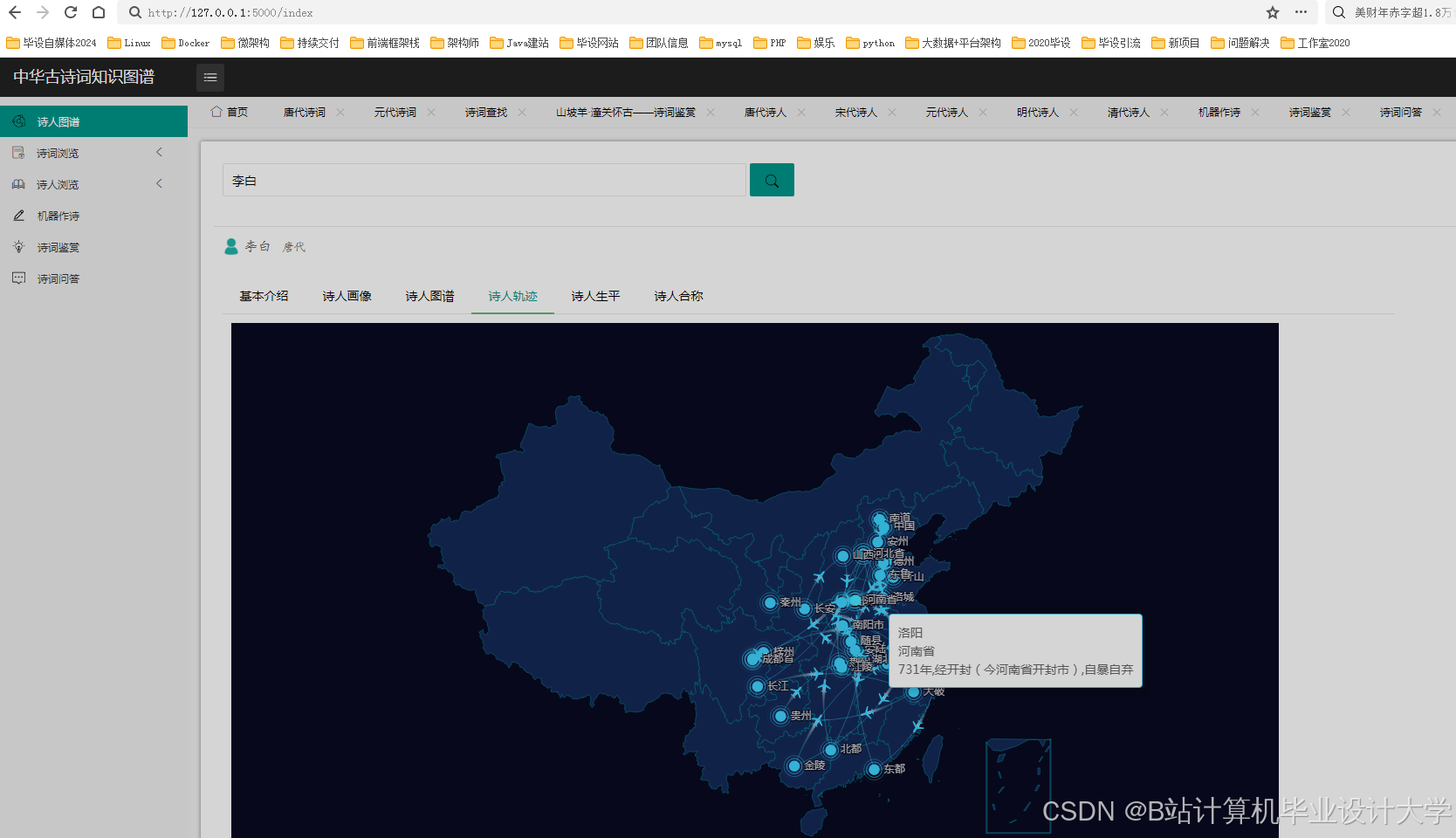
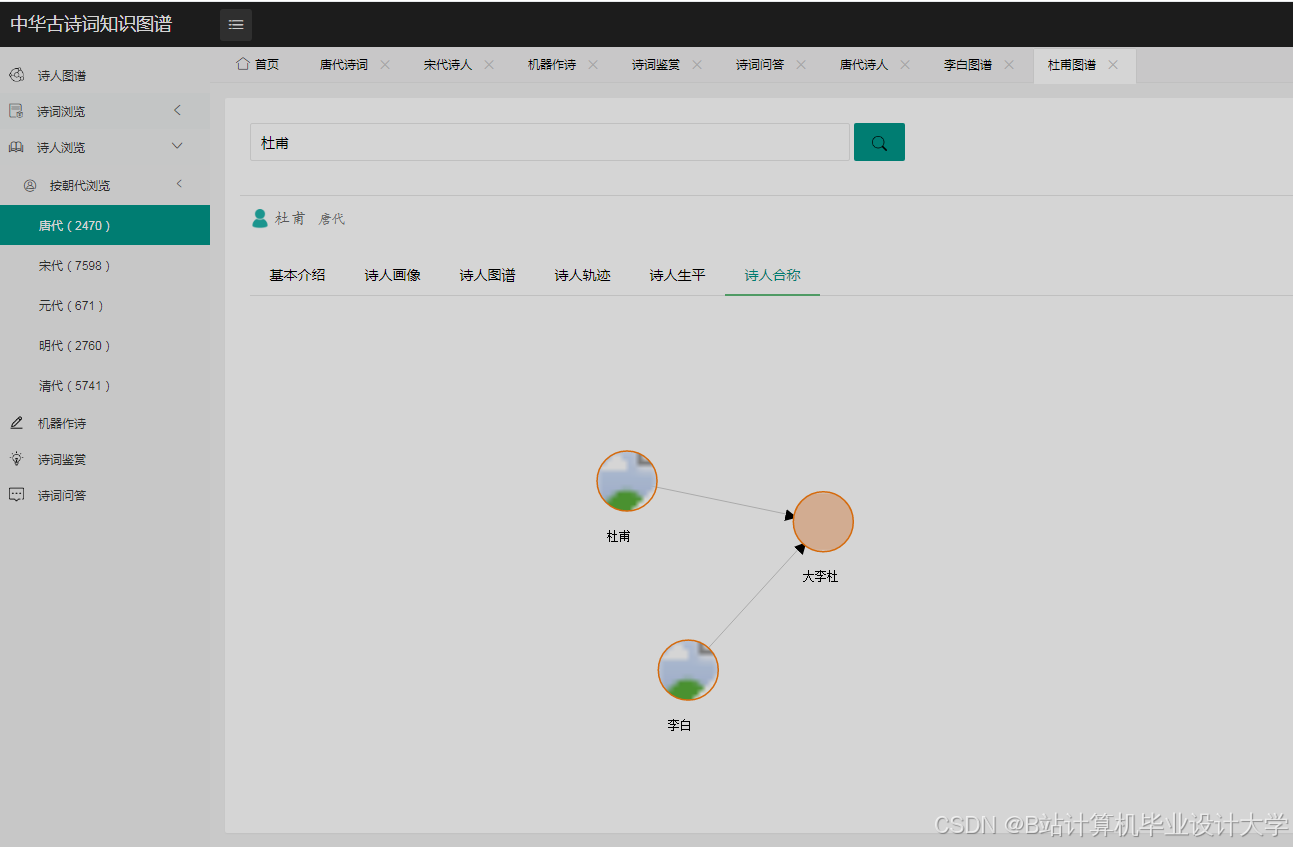
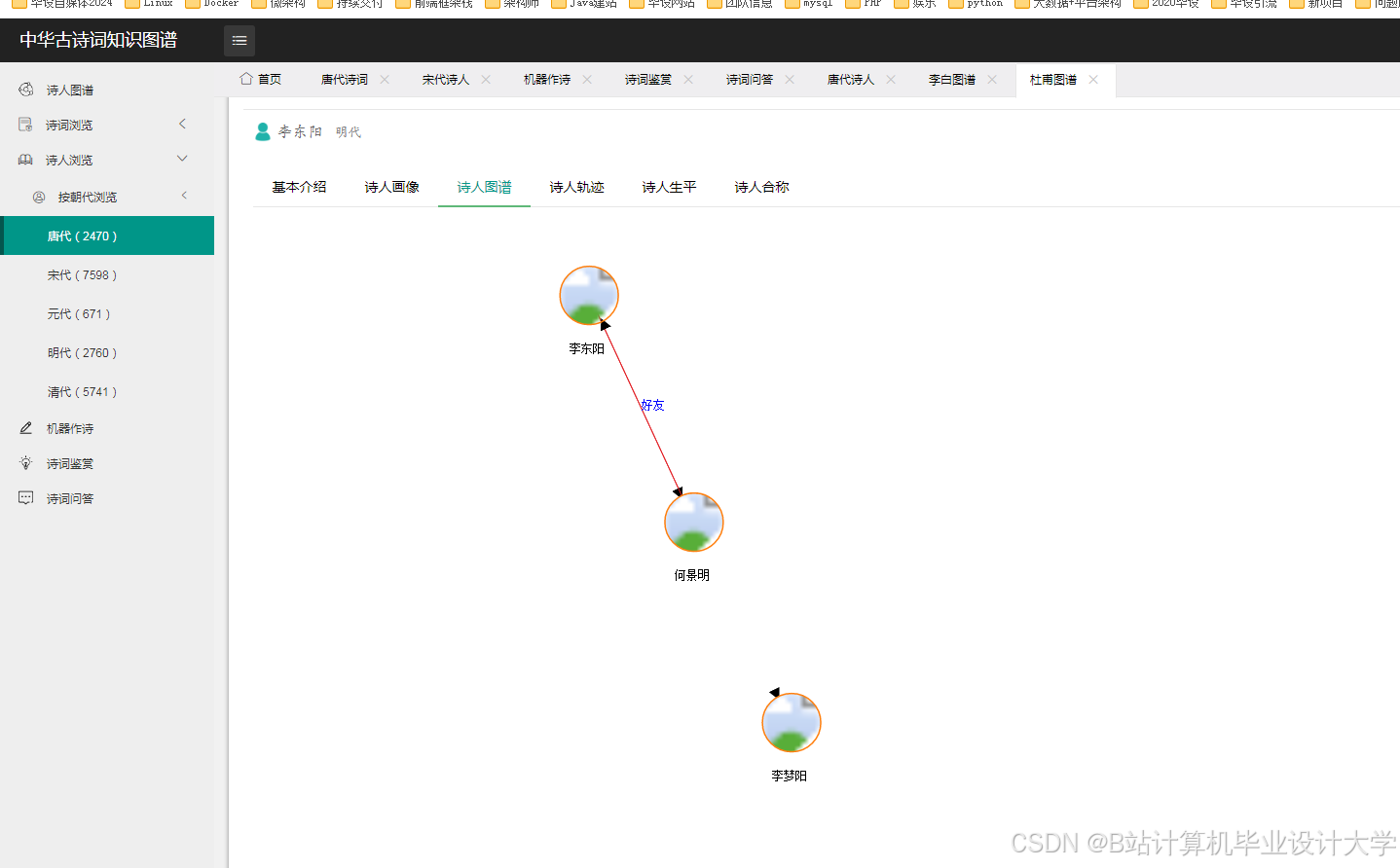
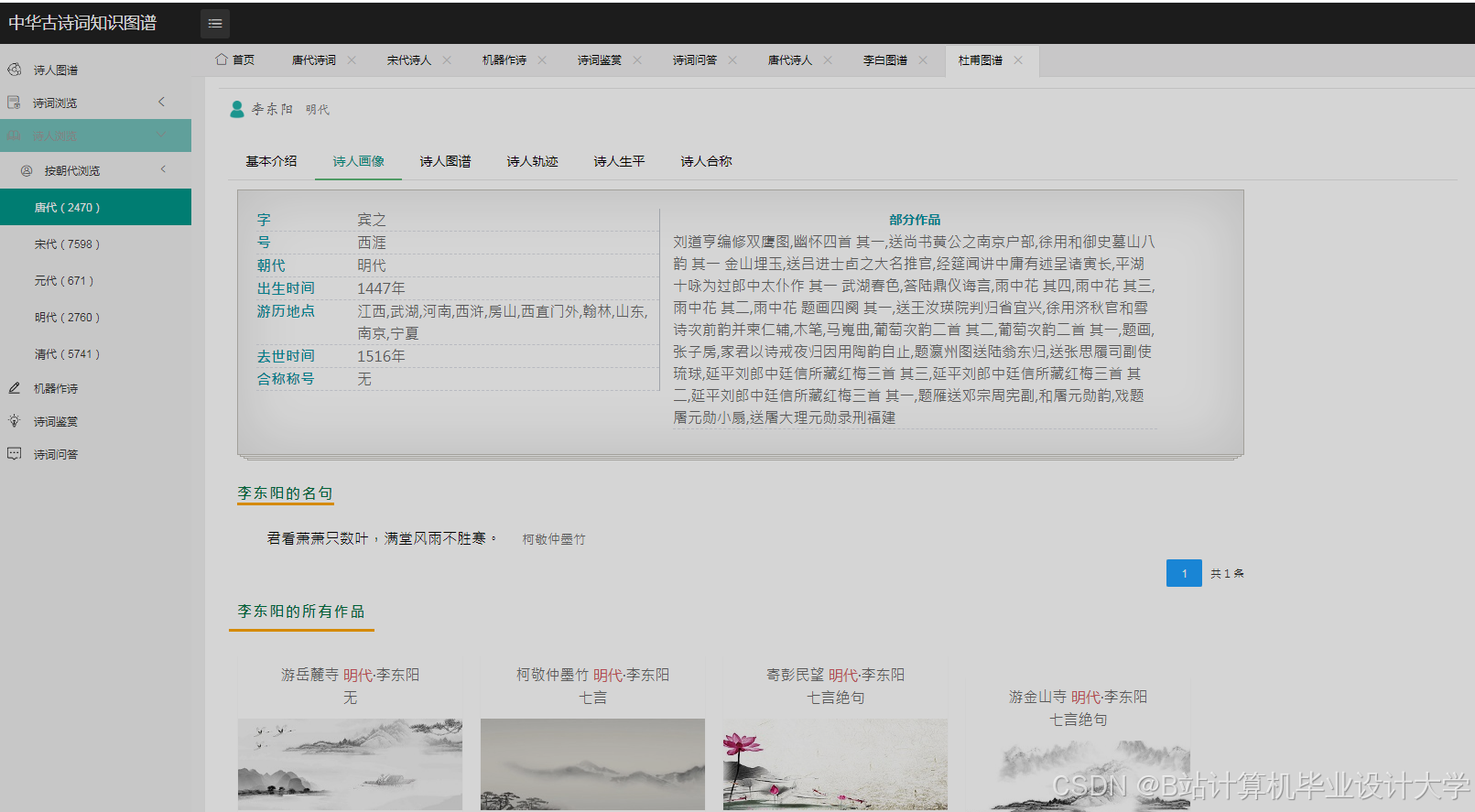
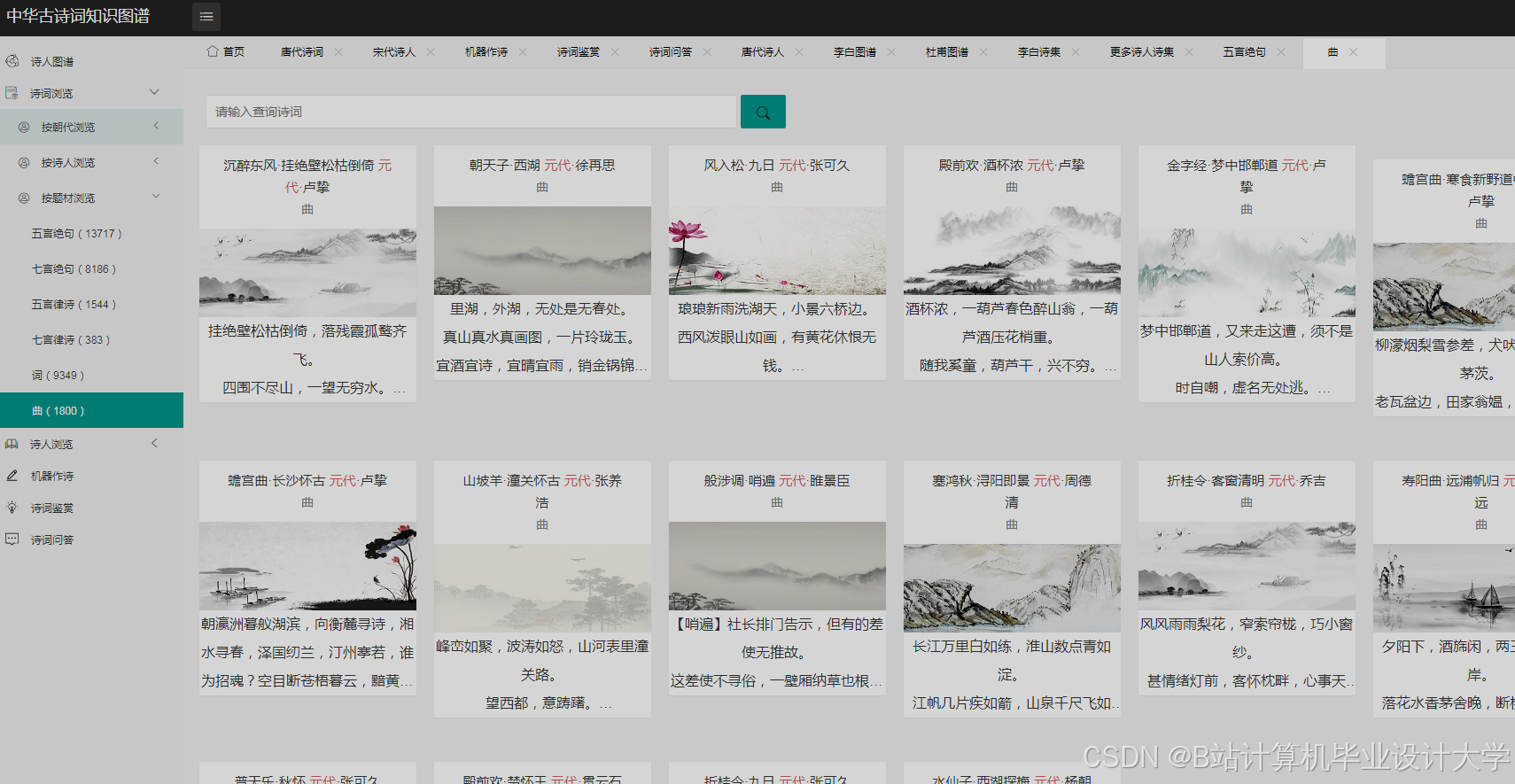
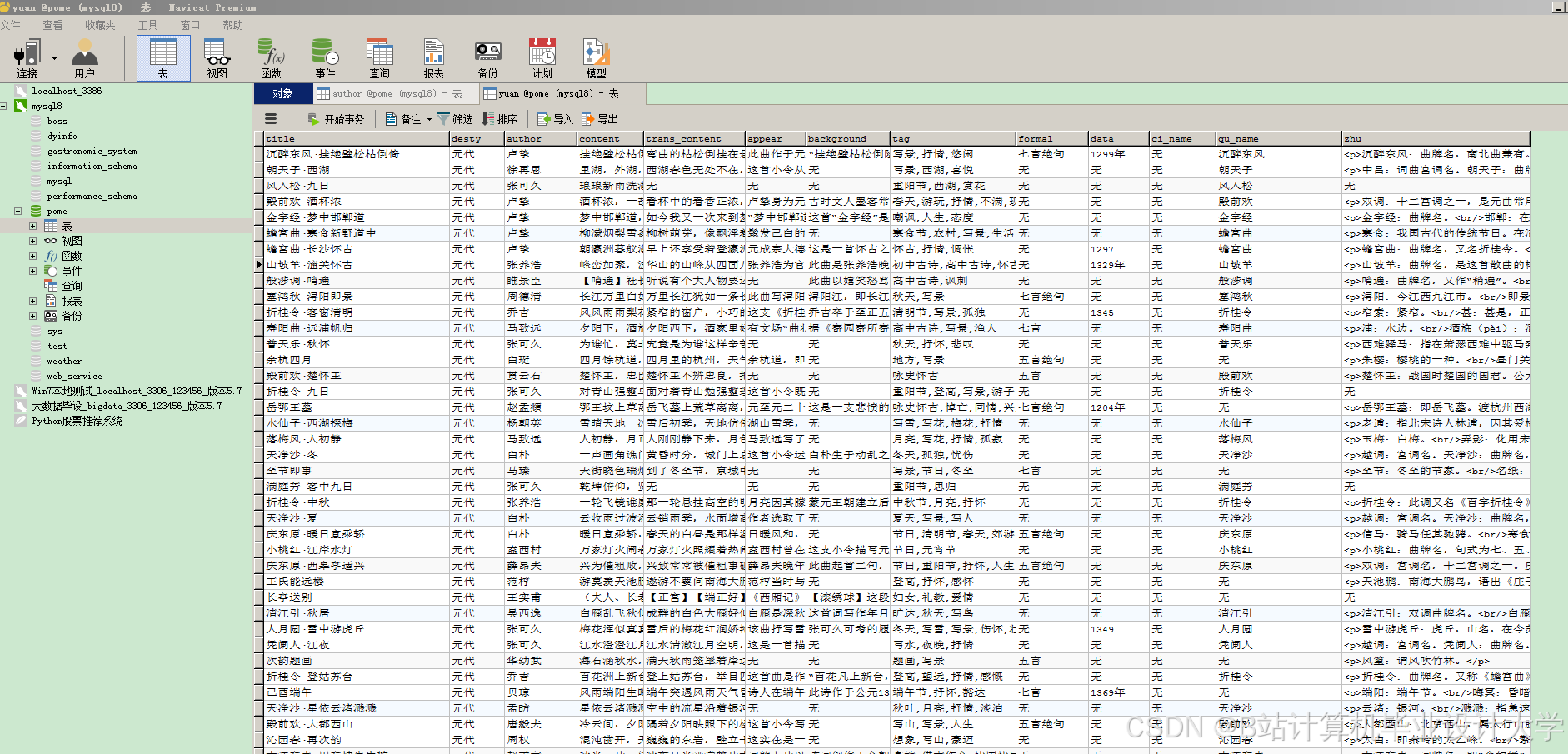
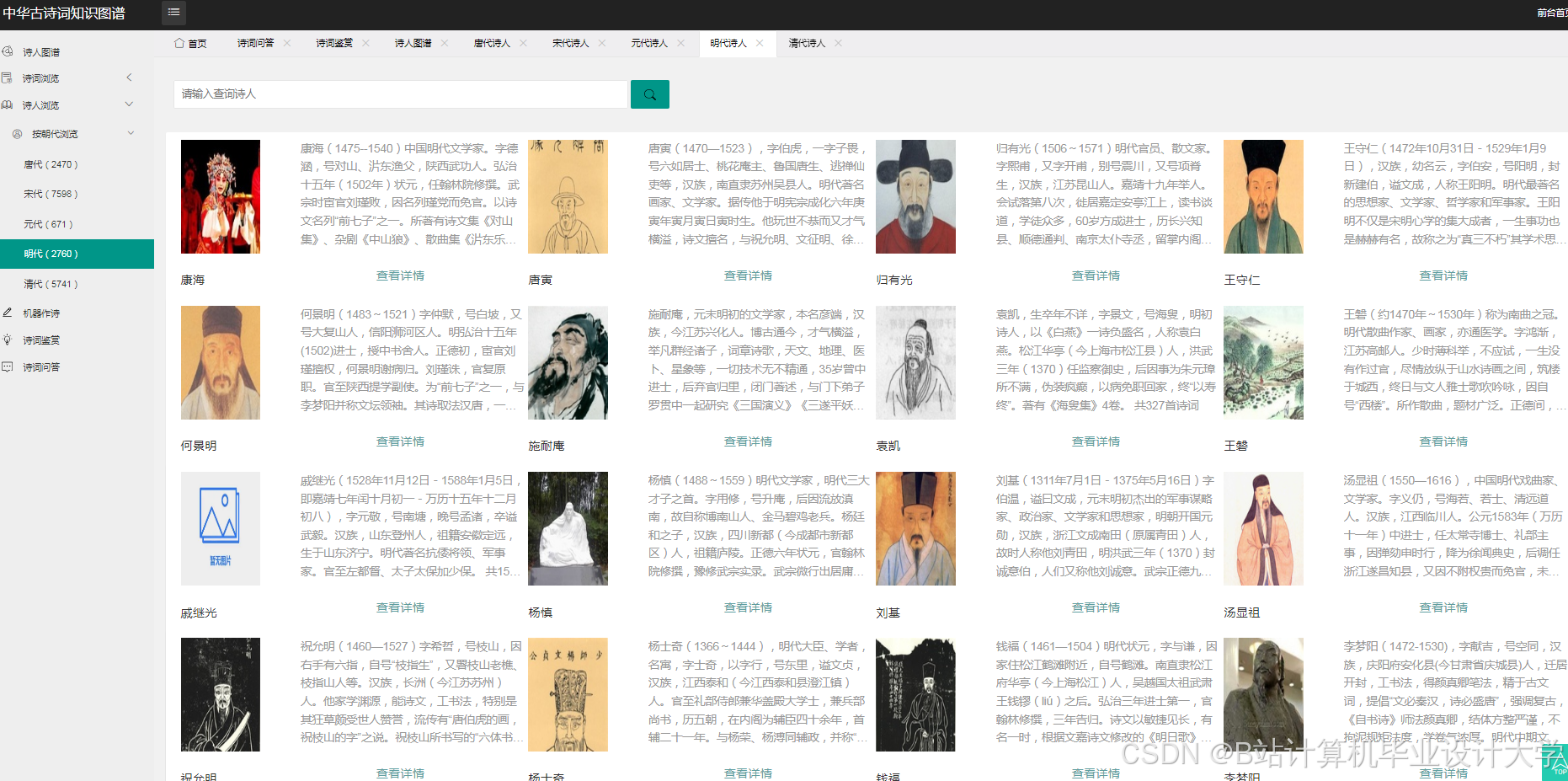
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











