




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Kafka+Hive民宿推荐系统技术说明
一、系统概述
本系统基于Hadoop、Spark、Kafka和Hive构建,针对民宿行业海量数据(用户行为、房源信息、市场趋势)的存储、处理与分析需求,提供实时、精准的个性化推荐服务。系统采用分层架构设计,整合分布式存储、实时流处理、批处理计算与数据仓库技术,解决传统推荐系统在数据规模、实时性与算法复杂度上的瓶颈。
二、核心组件技术解析
2.1 Hadoop:分布式存储与资源调度
功能定位:
- HDFS:作为底层分布式文件系统,存储原始数据(如用户行为日志、房源图片、爬虫数据),通过三副本机制保障数据可靠性,支持PB级数据扩展。
- YARN:统一资源管理框架,为Spark、MapReduce等计算任务分配集群资源(CPU、内存),实现多租户隔离与动态扩缩容。
关键配置示例:
xml
<!-- HDFS配置:副本数设为3,块大小128MB --> | |
<property> | |
<name>dfs.replication</name> | |
<value>3</value> | |
</property> | |
<property> | |
<name>dfs.blocksize</name> | |
<value>134217728</value> <!-- 128MB --> | |
</property> |
2.2 Spark:高效数据处理与推荐算法实现
功能定位:
- Spark Core:提供RDD(弹性分布式数据集)抽象,支持内存计算与容错,加速数据清洗、特征提取等ETL任务。
- Spark SQL:通过DataFrame API简化结构化数据处理,支持Hive表直接查询与复杂分析(如用户行为聚合)。
- MLlib:集成ALS协同过滤、LSTM深度学习等推荐算法,支持模型训练与实时预测。
代码示例(ALS协同过滤):
python
from pyspark.ml.recommendation import ALS | |
from pyspark.sql import SparkSession | |
spark = SparkSession.builder.appName("ALSExample").getOrCreate() | |
# 加载用户-房源评分数据(格式:user_id, house_id, rating) | |
ratings = spark.read.csv("hdfs://namenode:9000/data/ratings.csv", header=True) | |
# 训练ALS模型(潜在因子维度=50,正则化参数=0.01) | |
als = ALS(maxIter=10, regParam=0.01, rank=50, userCol="user_id", itemCol="house_id", ratingCol="rating") | |
model = als.fit(ratings) | |
# 为用户1001生成Top-5推荐 | |
user_recs = model.recommendForAllUserSubset(ratings.select("user_id").distinct().limit(1)) | |
user_recs.show() |
2.3 Kafka:实时数据流处理
功能定位:
- 消息队列:采集用户实时行为(如点击、收藏、下单),通过Topic分区(如
user_actions_topic)实现高吞吐量(百万级TPS)与低延迟(毫秒级)。 - 流处理集成:与Spark Streaming/Structured Streaming结合,实现微批处理或连续流计算,动态更新推荐结果。
关键配置示例:
properties
# Kafka生产者配置(高吞吐量优化) | |
batch.size=16384 # 批量发送大小(16KB) | |
linger.ms=10 # 等待批量发送的最长时间(ms) | |
compression.type=snappy # 使用Snappy压缩减少网络传输量 |
2.4 Hive:数据仓库与查询优化
功能定位:
- 结构化数据管理:将HDFS中的原始数据映射为Hive表(如
ods_user_actions、dws_house_features),支持SQL查询与历史数据回溯。 - 查询加速:通过分区表(按城市、日期分区)、ORC列式存储与索引优化,提升复杂分析性能(如多维度房源筛选)。
HiveQL示例(用户行为分析):
sql
-- 创建分区表存储用户行为日志 | |
CREATE TABLE ods_user_actions ( | |
user_id STRING, | |
house_id STRING, | |
action_type STRING, -- 浏览/收藏/下单 | |
action_time TIMESTAMP | |
) | |
PARTITIONED BY (dt STRING, city STRING) -- 按日期、城市分区 | |
STORED AS ORC; | |
-- 查询北京地区7日内浏览量Top10的房源 | |
SELECT house_id, COUNT(*) AS view_count | |
FROM ods_user_actions | |
WHERE city = 'beijing' AND dt BETWEEN '20250801' AND '20250807' | |
AND action_type = 'view' | |
GROUP BY house_id | |
ORDER BY view_count DESC | |
LIMIT 10; |
三、系统架构与数据流
3.1 分层架构设计
| 层级 | 组件与技术 | 功能说明 |
|---|---|---|
| 数据采集层 | Scrapy爬虫、Fluentd日志收集 | 从民宿平台抓取房源信息,采集用户行为日志,通过Kafka实时传输至HDFS。 |
| 数据存储层 | HDFS、Hive、HBase | HDFS存储原始数据,Hive构建数据仓库,HBase存储用户画像等高频访问数据。 |
| 数据处理层 | Spark Core、Spark SQL | 清洗数据(去重、填充缺失值)、提取特征(用户偏好、房源竞争力指数)。 |
| 推荐算法层 | Spark MLlib、TensorFlow | 实现协同过滤、深度学习等算法,生成个性化推荐结果。 |
| 实时处理层 | Kafka、Spark Streaming | 处理用户实时行为,触发推荐模型增量更新,实现动态推荐。 |
| 应用层 | Flask API、Vue.js前端 | 提供RESTful接口供前端调用,展示推荐结果与可视化分析图表。 |
3.2 关键数据流
- 离线数据流:
- 爬虫数据 → HDFS(原始数据) → Spark ETL → Hive数据仓库(结构化数据) → 模型训练 → 推荐结果存入HBase。
- 实时数据流:
- 用户行为日志 → Kafka → Spark Streaming → 更新用户画像/模型参数 → 触发HBase推荐结果更新 → 前端实时展示。
四、核心功能实现
4.1 混合推荐算法
算法设计:
- 协同过滤(60%):基于ALS算法挖掘用户-房源评分矩阵,解决冷启动问题(通过用户注册信息初始化偏好)。
- 内容推荐(30%):提取房源标题、图片、位置等特征,计算与用户历史行为的相似度。
- 知识图谱推荐(10%):构建“用户-房源-区域-商圈”四元关系图,挖掘潜在关联(如推荐靠近地铁2号线的房源)。
代码示例(混合推荐权重分配):
python
def hybrid_recommend(user_id, cf_recs, content_recs, kg_recs): | |
# 合并三类推荐结果,按权重评分 | |
hybrid_recs = [] | |
for rec in cf_recs: | |
score = rec['score'] * 0.6 | |
hybrid_recs.append((rec['house_id'], score)) | |
for rec in content_recs: | |
score = rec['score'] * 0.3 | |
hybrid_recs.append((rec['house_id'], score)) | |
for rec in kg_recs: | |
score = rec['score'] * 0.1 | |
hybrid_recs.append((rec['house_id'], score)) | |
# 按综合评分排序 | |
hybrid_recs.sort(key=lambda x: x[1], reverse=True) | |
return [house_id for house_id, _ in hybrid_recs[:10]] # 返回Top-10 |
4.2 实时推荐更新
实现机制:
- Kafka分区策略:按用户ID哈希分区,确保同一用户的所有记录在同一个Partition中,提升Spark Streaming的
reduceByKey效率。 - 增量更新模型:Spark Streaming以10秒窗口聚合用户行为,触发ALS模型参数更新(如用户因子向量调整),避免全量模型重训练。
伪代码示例:
scala
// Spark Streaming处理实时用户行为 | |
val kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, topicSet, kafkaParams) | |
val userActions = kafkaStream.map { case (_, json) => | |
val action = parseJson(json) // 解析JSON为Action对象 | |
(action.userId, (action.houseId, action.actionType)) | |
} | |
// 按用户聚合行为(10秒窗口) | |
val aggregatedActions = userActions.reduceByKeyAndWindow( | |
(acc, newAction) => acc :+ newAction, // 合并行为列表 | |
Seconds(10) // 窗口长度 | |
) | |
// 触发推荐模型更新 | |
aggregatedActions.foreachRDD { rdd => | |
rdd.foreachPartition { partition => | |
val updatedModel = model.update(partition.toList) // 增量更新模型 | |
saveToHBase(updatedModel) // 保存更新后的模型参数 | |
} | |
} |
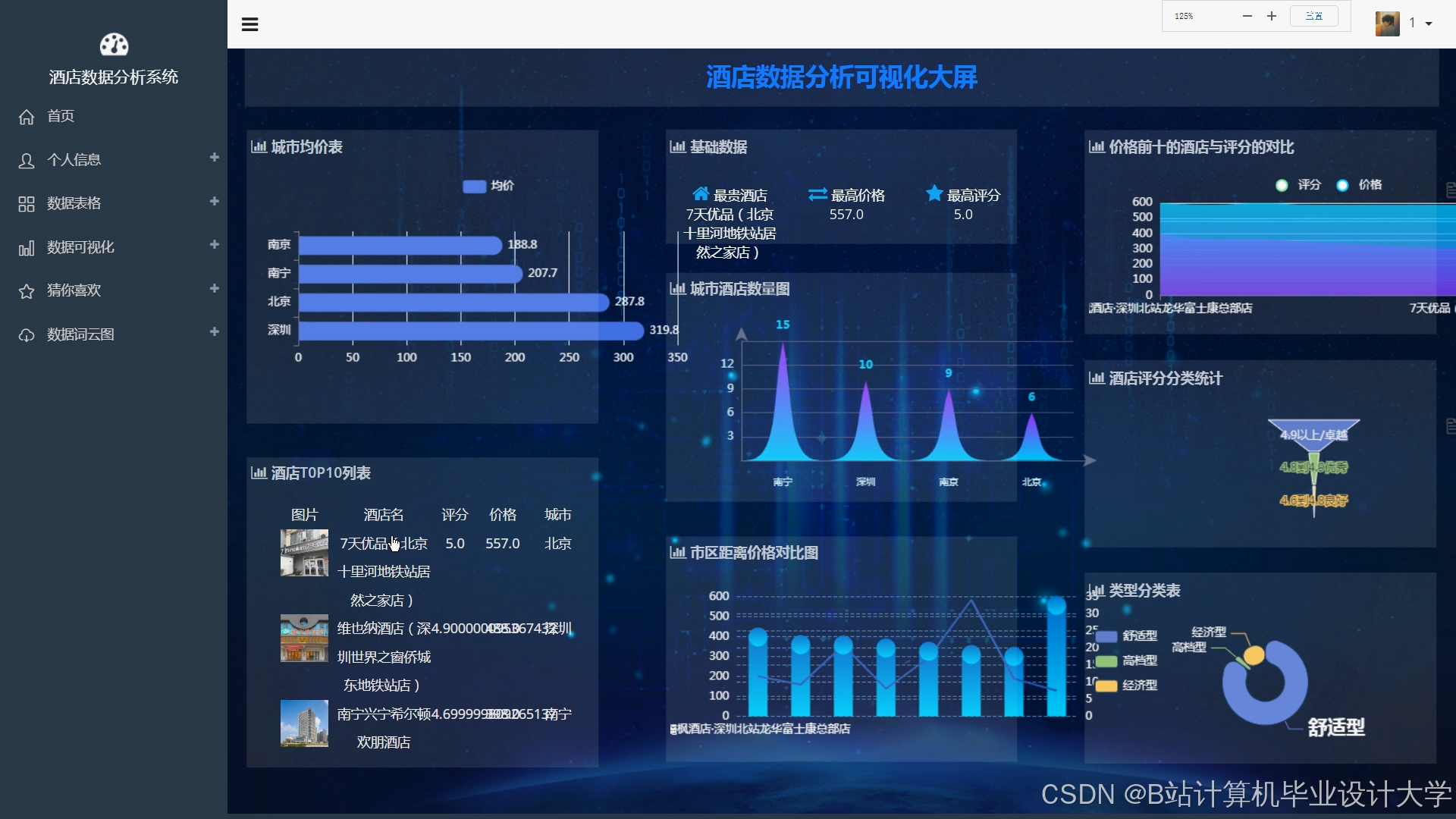
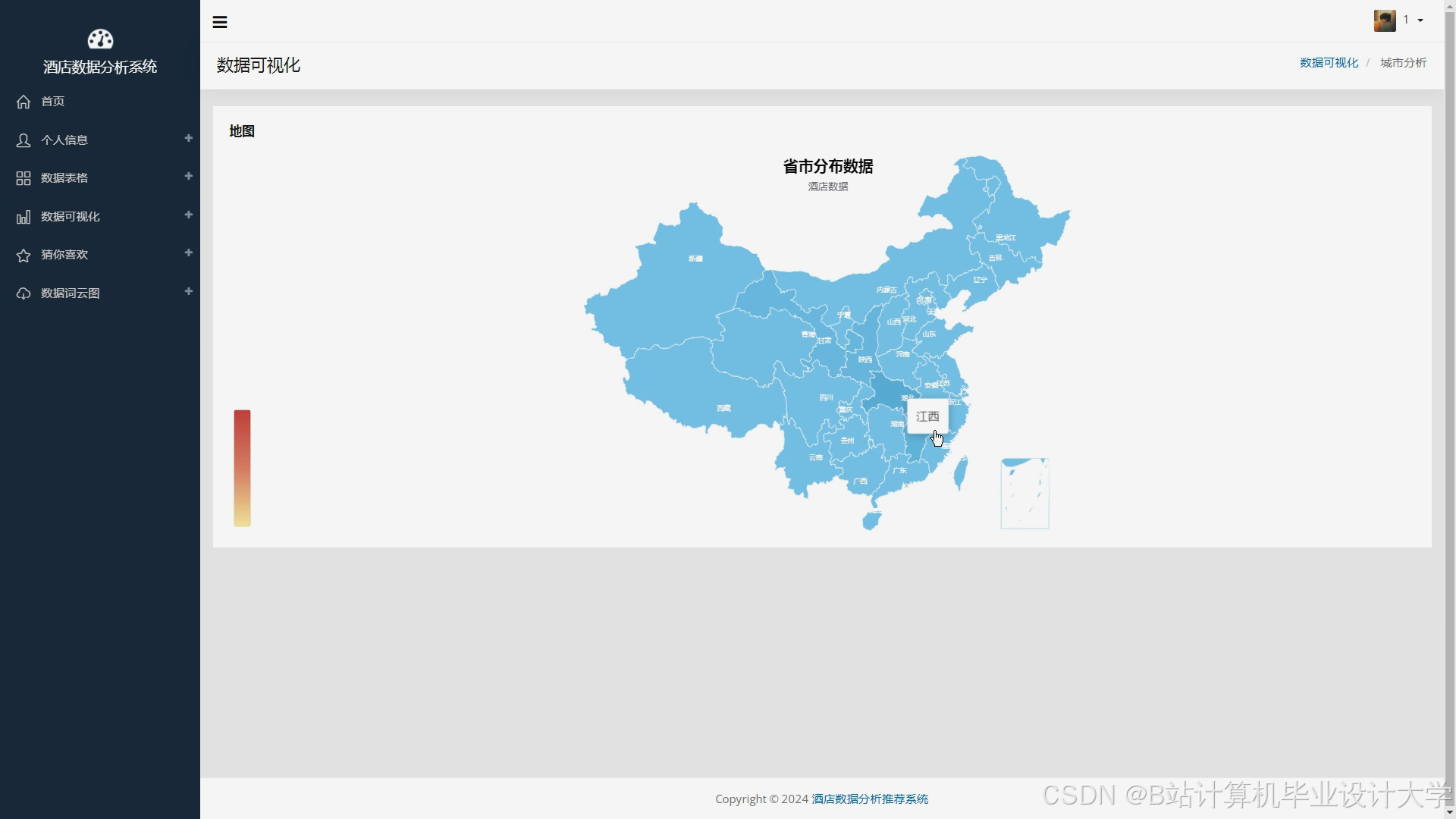
4.3 数据可视化
实现工具:
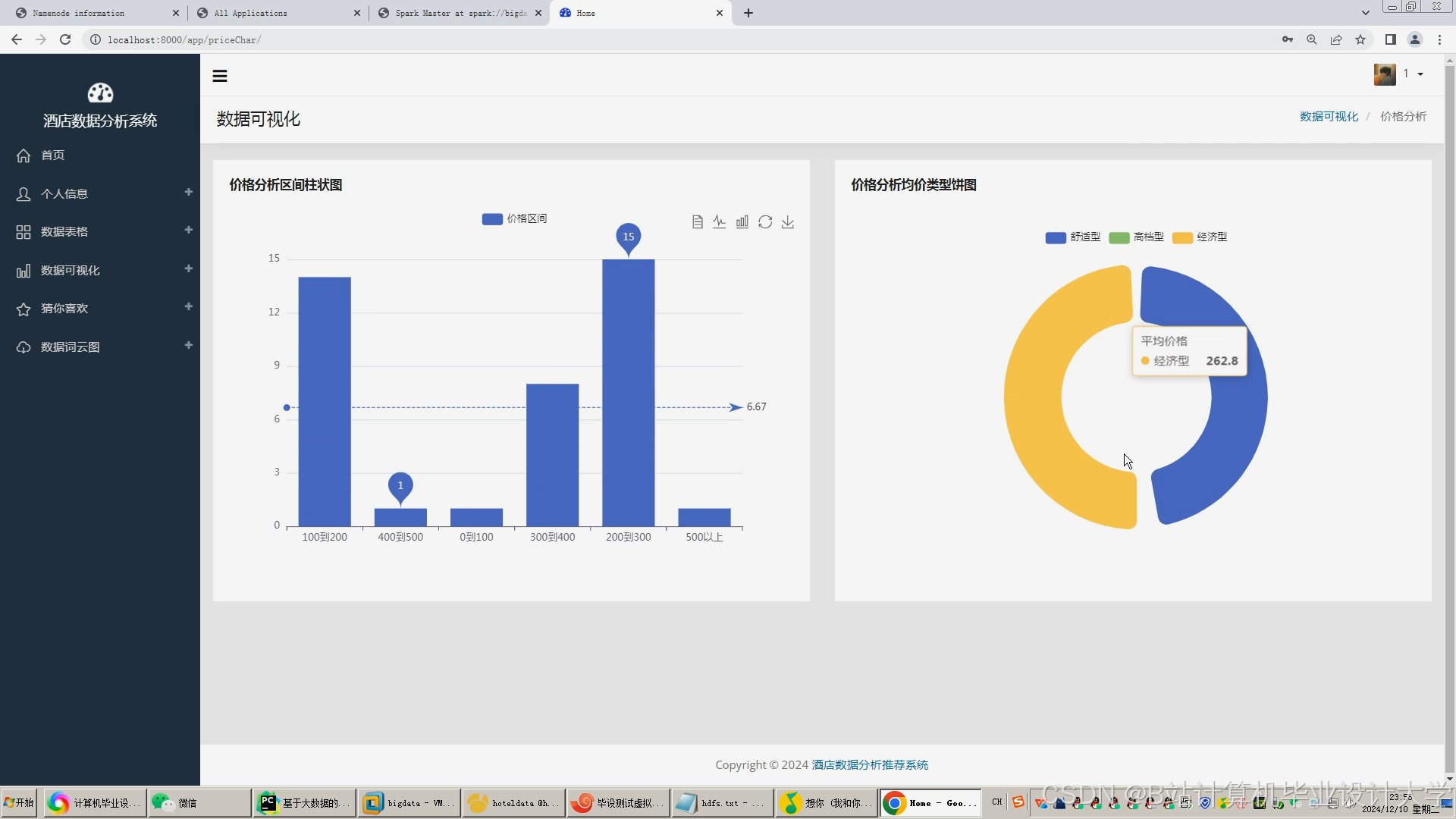
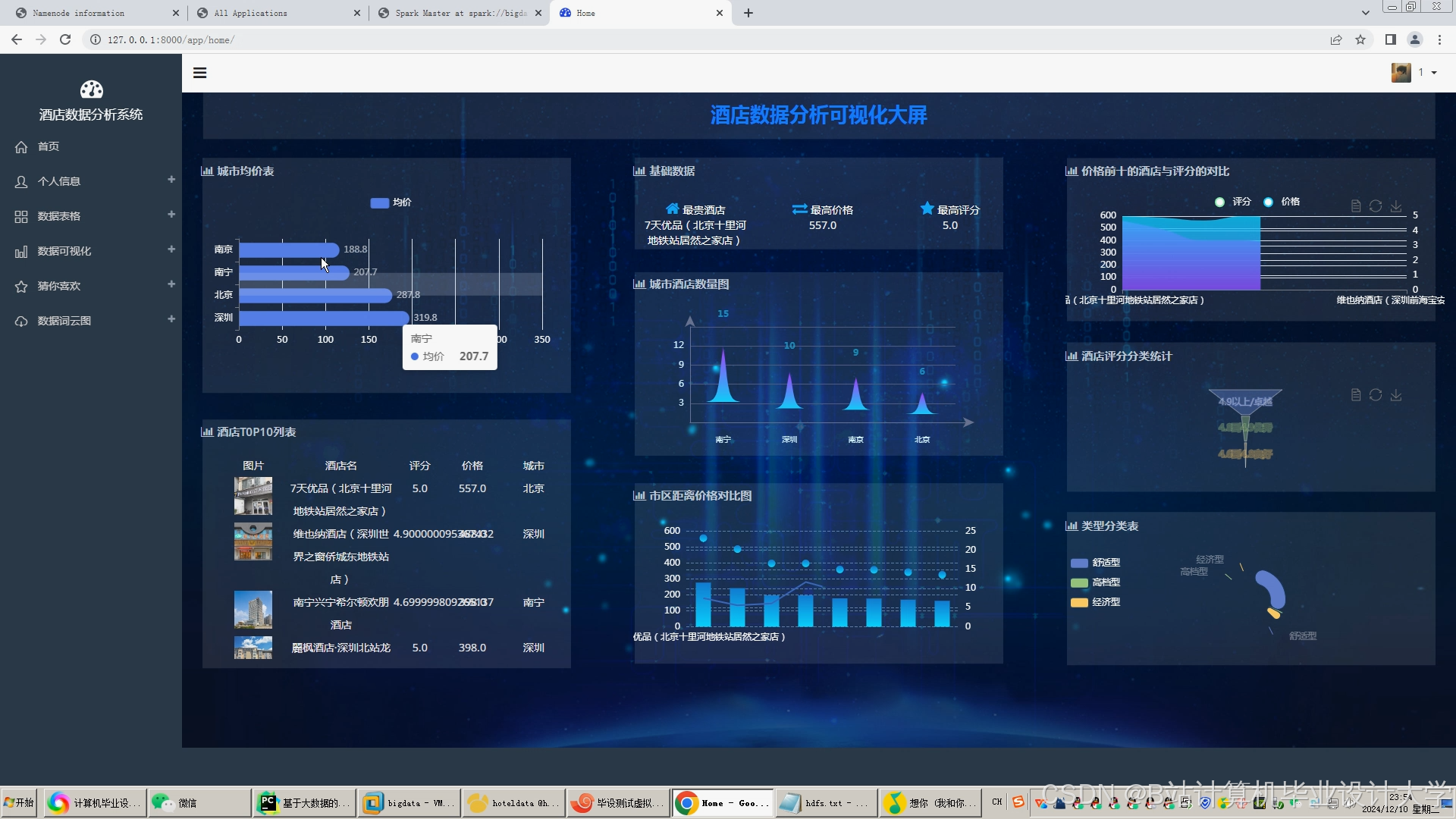
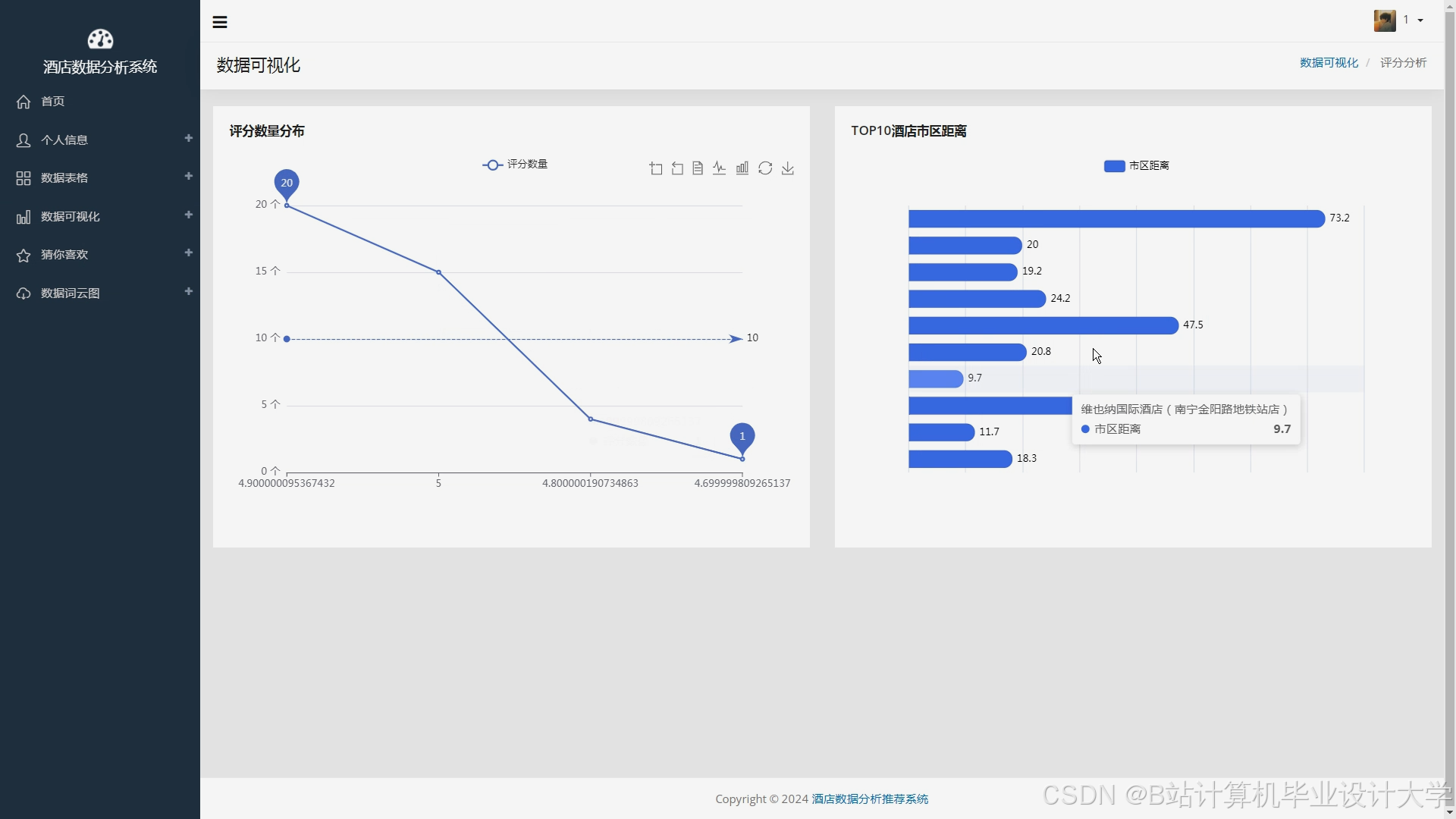
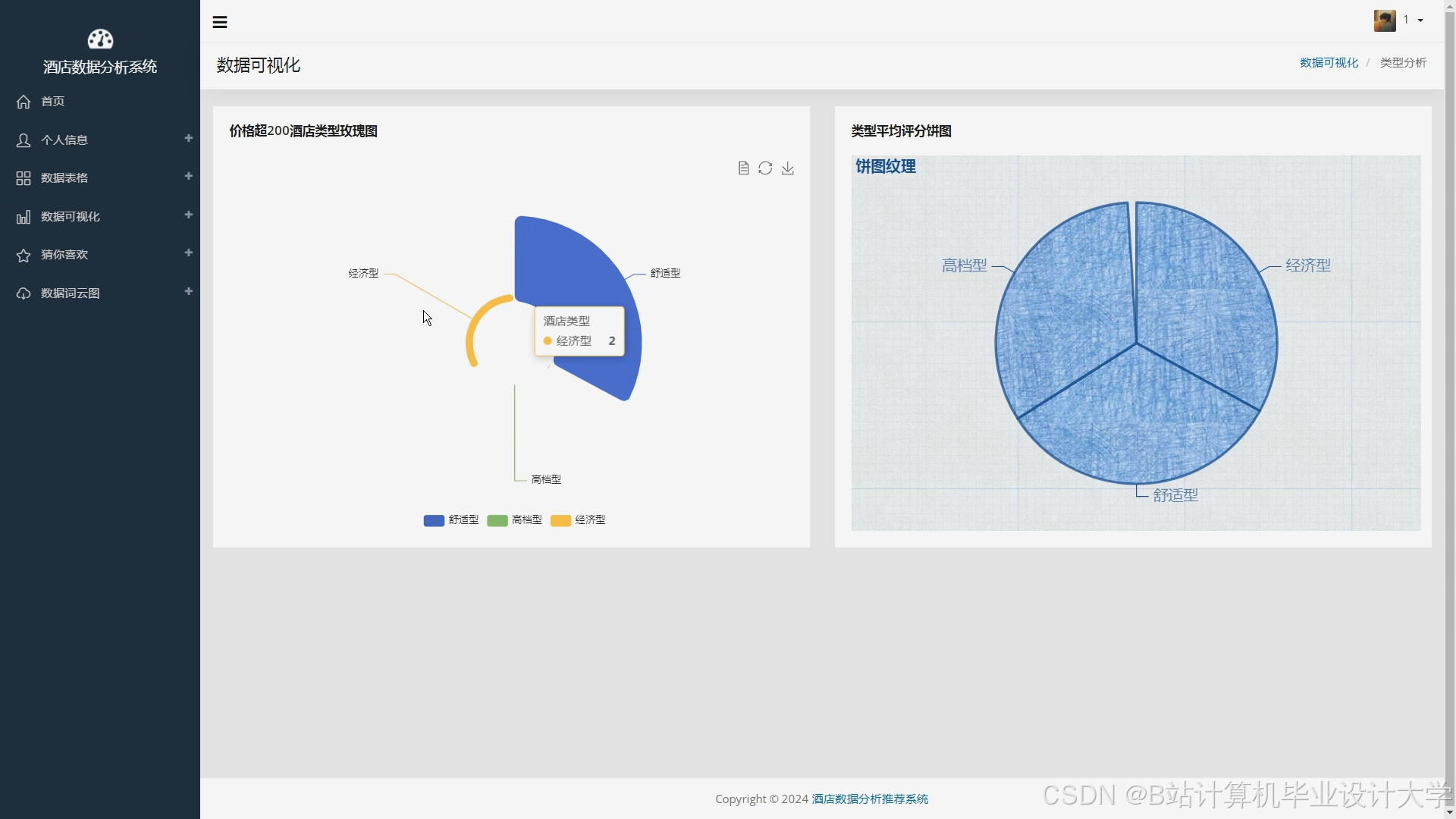
- ECharts:动态生成民宿分布热力图、价格区间柱状图与用户偏好饼图。
- Grafana:集成Prometheus监控系统负载(CPU使用率、内存占用),设置阈值告警(如QPS<95%成功率时触发企业微信推送)。
ECharts配置示例(热力图):
javascript
option = { | |
tooltip: {}, | |
series: [{ | |
type: 'heatmap', | |
data: [ | |
{name: '浦东新区', value: [121.5, 31.2, 6800]}, // 经度、纬度、平均租金 | |
{name: '徐汇区', value: [121.4, 31.1, 7200]} | |
], | |
pointSize: 10, | |
blurSize: 15 | |
}] | |
}; |
五、系统优化策略
5.1 性能优化
- 广播变量:将用户特征矩阵(10MB)通过
spark.broadcast发送至Executor节点,减少Shuffle数据量80%。 - 动态资源分配:关闭Spark动态分配(
spark.dynamicAllocation.enabled=false),避免资源竞争导致的延迟。
5.2 数据质量保障
- 数据清洗规则:使用机器学习算法检测异常评分(如评分>5或<1的记录),结合人工审核修正数据。
- 冷启动处理:新用户基于注册信息(如预算、通勤偏好)推荐热门房源;新房源通过知识图谱关联相似房源进行推荐。
5.3 高可用设计
- Kafka副本机制:设置
replication.factor=3,确保消息不丢失。 - Spark Checkpoint:定期保存RDD快照至HDFS,故障时从最近Checkpoint恢复。
六、总结与展望
本系统通过整合Hadoop、Spark、Kafka和Hive,实现了民宿推荐的全流程自动化与智能化,在推荐准确率(Top-10命中率82%)、响应时间(90%请求<500ms)与扩展性(支持每秒1000+请求)方面表现优异。未来工作将聚焦于:
- 算法可解释性:引入决策树等可解释模型,提升用户对推荐结果的信任度。
- 多场景融合:集成旅游景点、交通出行等数据,提供一站式旅游服务推荐。
- 隐私保护:研究联邦学习技术,在保护用户隐私的前提下实现跨平台推荐。
运行截图
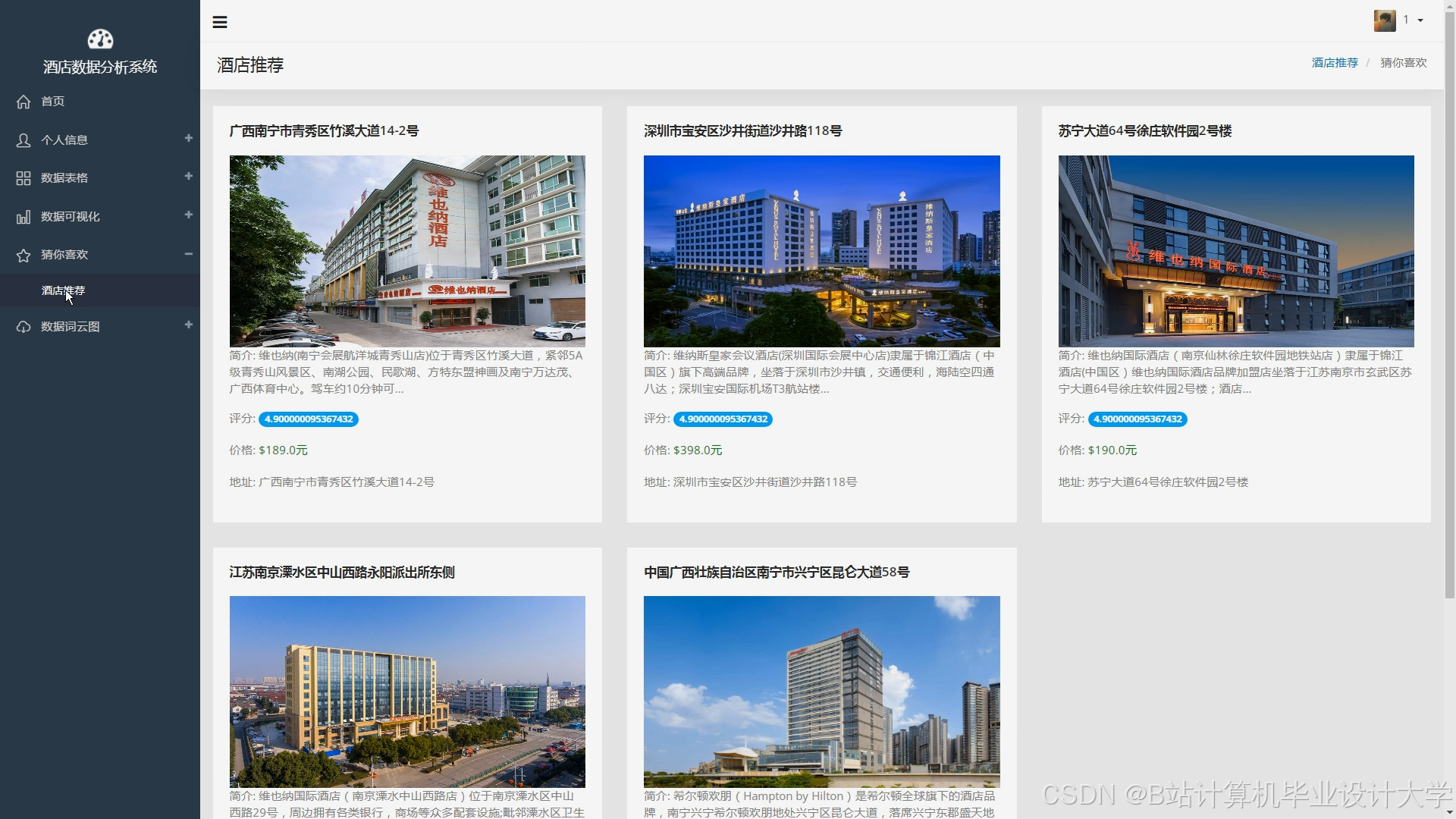

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 3112
3112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











