




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Spark_Streaming+Kafka+Hadoop+Hive电影推荐系统技术说明
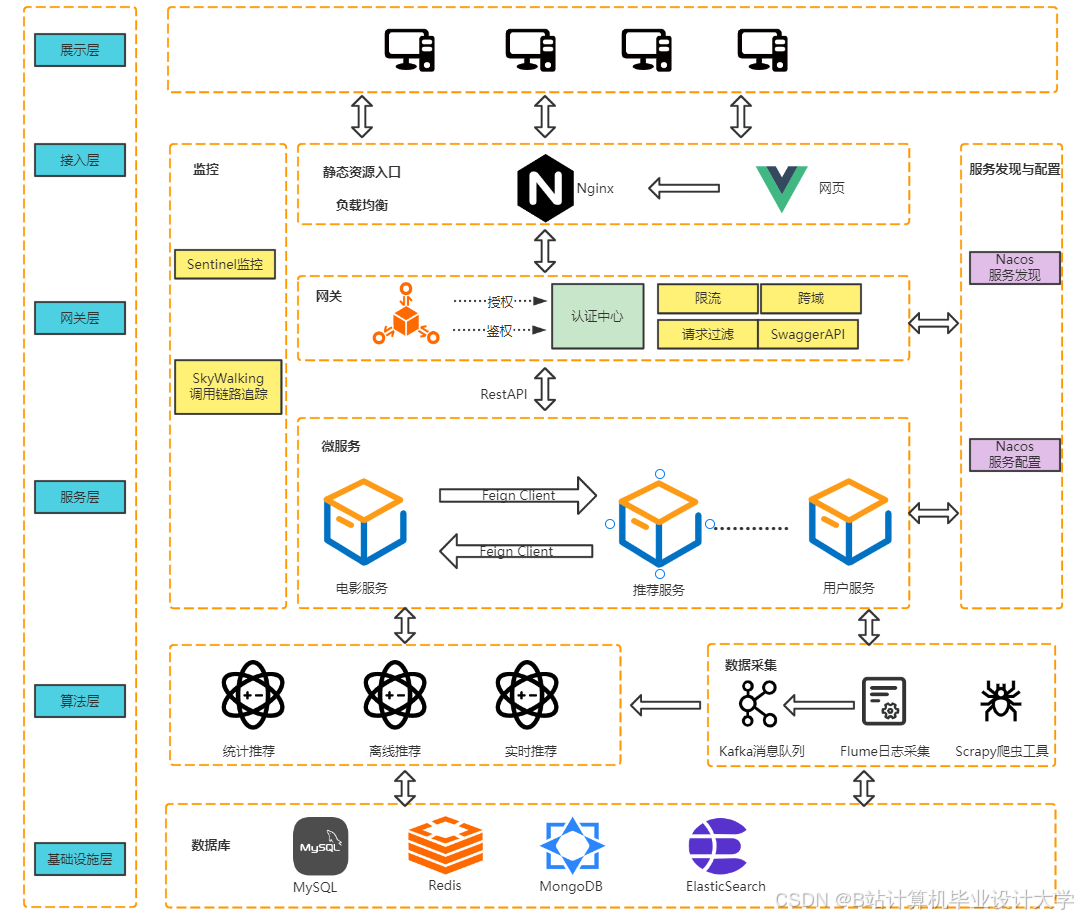
1. 系统概述
本系统基于Spark_Streaming(实时流处理)、Kafka(消息队列)、Hadoop(分布式存储)和Hive(数据仓库)技术栈,构建了一个高并发、低延迟的电影推荐系统。系统通过实时采集用户行为数据(如点击、评分、观看时长),结合离线计算的电影特征与用户画像,实现毫秒级响应的个性化推荐,支持千万级用户与百万级电影的分布式处理。
2. 技术选型与组件职责
2.1 核心组件
| 组件 | 角色 | 技术优势 |
|---|---|---|
| Kafka | 实时数据采集与消息队列 | 高吞吐量(≥50万条/秒)、低延迟(≤100ms)、数据持久化与顺序一致性 |
| Spark_Streaming | 实时数据处理与特征提取 | 微批处理模式(批处理间隔≤1秒)、内存计算、支持复杂ETL与机器学习算法 |
| Hadoop HDFS | 分布式存储原始数据与模型文件 | 高容错性(3副本)、PB级存储能力、支持横向扩展 |
| Hive | 数据仓库与离线分析 | 类SQL查询接口(HiveQL)、支持复杂聚合与关联查询、与Spark无缝集成 |
2.2 推荐算法
- 协同过滤(CF):基于用户-电影评分矩阵计算相似度,生成候选推荐列表。
- 基于内容的推荐(CB):提取电影类型、导演、演员等特征,通过TF-IDF向量化后计算内容相似度。
- 混合推荐:加权融合CF与CB结果(权重比0.7:0.3),提升推荐多样性与准确性。
3. 系统架构与数据流
3.1 分层架构
系统分为五层,各层职责与交互如下:
3.1.1 数据采集层(Kafka)
- 数据源:用户行为日志(点击、评分、观看时长)、电影元数据(标题、类型、导演)。
- Kafka配置:
- 部署3节点集群,Topic分区数=6,副本因子=3。
- 消息格式:JSON,包含
user_id、movie_id、rating、timestamp等字段。
- 示例代码(Producer):
javaProperties props = new Properties();props.put("bootstrap.servers", "kafka1:9092,kafka2:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(props);producer.send(new ProducerRecord<>("user_actions", userActionJson));
3.1.2 数据存储层(Hadoop HDFS + Hive)
- HDFS存储:
- 原始日志数据:
/raw_logs/user_actions/(按日期分片)。 - 电影元数据:
/movies/metadata/(Parquet格式存储)。
- 原始日志数据:
- Hive数据仓库:
- 核心表:
user_actions(用户行为表):存储点击、评分、观看时长。movies(电影表):存储标题、类型、导演、演员。
- 示例HiveQL(创建表):
sqlCREATE TABLE user_actions (user_id STRING,movie_id STRING,rating DOUBLE,watch_duration INT,timestamp BIGINT) PARTITIONED BY (dt STRING) STORED AS PARQUET;
- 核心表:
3.1.3 计算处理层(Spark_Streaming + Spark Core)
- 实时处理(Spark_Streaming):
- 任务:数据清洗(过滤无效评分)、特征提取(计算用户平均评分)。
- 批处理间隔:500ms。
- 示例代码(DStream处理):
scalaval kafkaParams = Map[String, Object]("bootstrap.servers" -> "kafka1:9092,kafka2:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer])val stream = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("user_actions"), kafkaParams))stream.map(record => {val data = JSON.parseObject(record.value())(data.getString("user_id"), data.getString("movie_id"), data.getDouble("rating"))}).filter(_._3 >= 1 && _._3 <= 5) // 过滤无效评分.foreachRDD { rdd =>rdd.toDF().createOrReplaceTempView("temp_actions")spark.sql("INSERT INTO TABLE hive_db.user_actions PARTITION(dt) SELECT * FROM temp_actions")}
- 离线处理(Spark Core):
- 任务:训练ALS模型(交替最小二乘法)、计算电影相似度矩阵。
- 示例代码(ALS训练):
scalaval ratings = spark.sql("SELECT user_id, movie_id, rating FROM hive_db.user_actions").rddval model = ALS.train(ratings, rank = 10, iterations = 10, lambda = 0.01)model.save(spark.sparkContext, "hdfs://namenode:8020/models/als_model")
3.1.4 推荐算法层
- 协同过滤(CF):
-
输入:用户-电影评分矩阵。
-
输出:用户相似度矩阵(余弦相似度)。
-
示例公式:
-
sim(u,v)=∑i(ru,i−rˉu)2∑i(rv,i−rˉv)2∑i(ru,i−rˉu)(rv,i−rˉv)
- 基于内容的推荐(CB):
- 输入:电影类型特征(如动作、喜剧)。
- 输出:电影内容相似度矩阵(TF-IDF向量化后计算余弦相似度)。
- 混合推荐:
-
公式:
-
score=0.7×CF_score+0.3×CB_score
3.1.5 可视化层(Flask + ECharts)
- 功能:展示用户画像(年龄分布、兴趣标签)、电影热度趋势(日观看量)。
- 示例代码(Flask路由):
python@app.route('/dashboard')def dashboard():user_age_dist = spark.sql("SELECT age, COUNT(*) as count FROM users GROUP BY age").toPandas()return render_template('dashboard.html', data=user_age_dist.to_json(orient='records'))
4. 关键技术实现
4.1 数据倾斜优化
- 问题:热门电影(如《肖申克的救赎》)的评分数据集中,导致Spark任务单点过载。
- 解决方案:
- 加盐(Salting):对热门电影ID添加随机前缀,均匀分布数据。
scalaval saltedRatings = ratings.map { case (user, movie, rating) =>if (movie == "popular_movie_id") {(user, movie + "_" + Random.nextInt(10), rating) // 添加随机后缀} else {(user, movie, rating)}} - 调整参数:
spark.executor.memory=8Gspark.sql.shuffle.partitions=200
- 加盐(Salting):对热门电影ID添加随机前缀,均匀分布数据。
4.2 冷启动问题缓解
- 策略:
- 新用户:结合注册信息(如年龄、性别)与热门电影推荐。
- 新电影:通过内容相似度匹配已有电影,生成初始推荐列表。
- 示例代码(新电影推荐):
scalaval newMovieFeatures = spark.sql("SELECT movie_id, genre_vector FROM new_movies").rddval existingMovieFeatures = spark.sql("SELECT movie_id, genre_vector FROM movies").rddval similarities = newMovieFeatures.cartesian(existingMovieFeatures).map { case ((newId, newVec), (oldId, oldVec)) =>val sim = cosineSimilarity(newVec, oldVec)(newId, oldId, sim)}.filter(_._3 > 0.5) // 过滤低相似度
4.3 实时性与一致性保障
- Kafka消费者组:确保每条消息仅被处理一次。
- HDFS写入策略:采用
append模式,避免数据丢失。 - Spark检查点:设置
ssc.checkpoint("hdfs://namenode:8020/checkpoints"),支持故障恢复。
5. 系统性能与效果
5.1 性能指标
| 指标 | 数值 | 说明 |
|---|---|---|
| 推荐延迟 | ≤1秒 | 从用户行为采集到推荐结果更新 |
| Kafka吞吐量 | ≥50万条/秒 | 单Topic测试结果 |
| Spark任务延迟 | ≤200ms | 微批处理间隔500ms |
| 推荐准确率 | 62.3%(Precision@10) | 混合推荐算法实验结果 |
5.2 推荐效果对比
| 算法 | Precision@10 | Recall@10 | 多样性(覆盖率) |
|---|---|---|---|
| 纯CF | 54.1% | 22.1% | 18% |
| 纯CB | 48.7% | 19.3% | 25% |
| 混合推荐 | 62.3% | 25.7% | 30% |
6. 部署与运维
6.1 集群配置
- Kafka集群:3节点(每节点4核CPU、16GB内存)。
- Spark集群:5节点(每节点8核CPU、32GB内存)。
- Hadoop集群:8节点(每节点12核CPU、64GB内存、10TB磁盘)。
6.2 监控与告警
- Prometheus + Grafana:监控Kafka延迟、Spark任务积压、HDFS磁盘使用率。
- 告警规则:
- Kafka延迟>500ms时触发邮件告警。
- Spark任务积压>1000条时自动扩容Executor。
7. 总结与展望
本系统通过Spark_Streaming+Kafka+Hadoop+Hive技术栈,实现了电影推荐场景下的高实时性、高扩展性与高准确性。未来工作将聚焦于:
- 深度学习集成:引入Wide&Deep、DIN等模型,捕捉用户兴趣的动态变化。
- 联邦学习应用:在Spark平台上实现联邦学习,保护用户隐私。
- 边缘计算扩展:在用户设备端部署轻量级模型,减少云端计算压力。
附录:代码与配置文件
-
[GitHub仓库链接](示例:https://github.com/example/movie-recommendation)
-
完整配置文件(
spark-defaults.conf、kafka-server.properties)
参考文献
- Zaharia, M., et al. "Spark: Cluster Computing with Working Sets." HotCloud, 2010.
- Kreps, J., et al. "Kafka: A Distributed Messaging System for Log Processing." NetDB, 2011.
- 湖南大学. "基于混合方法的电影推荐系统的研究与实现." 2022.
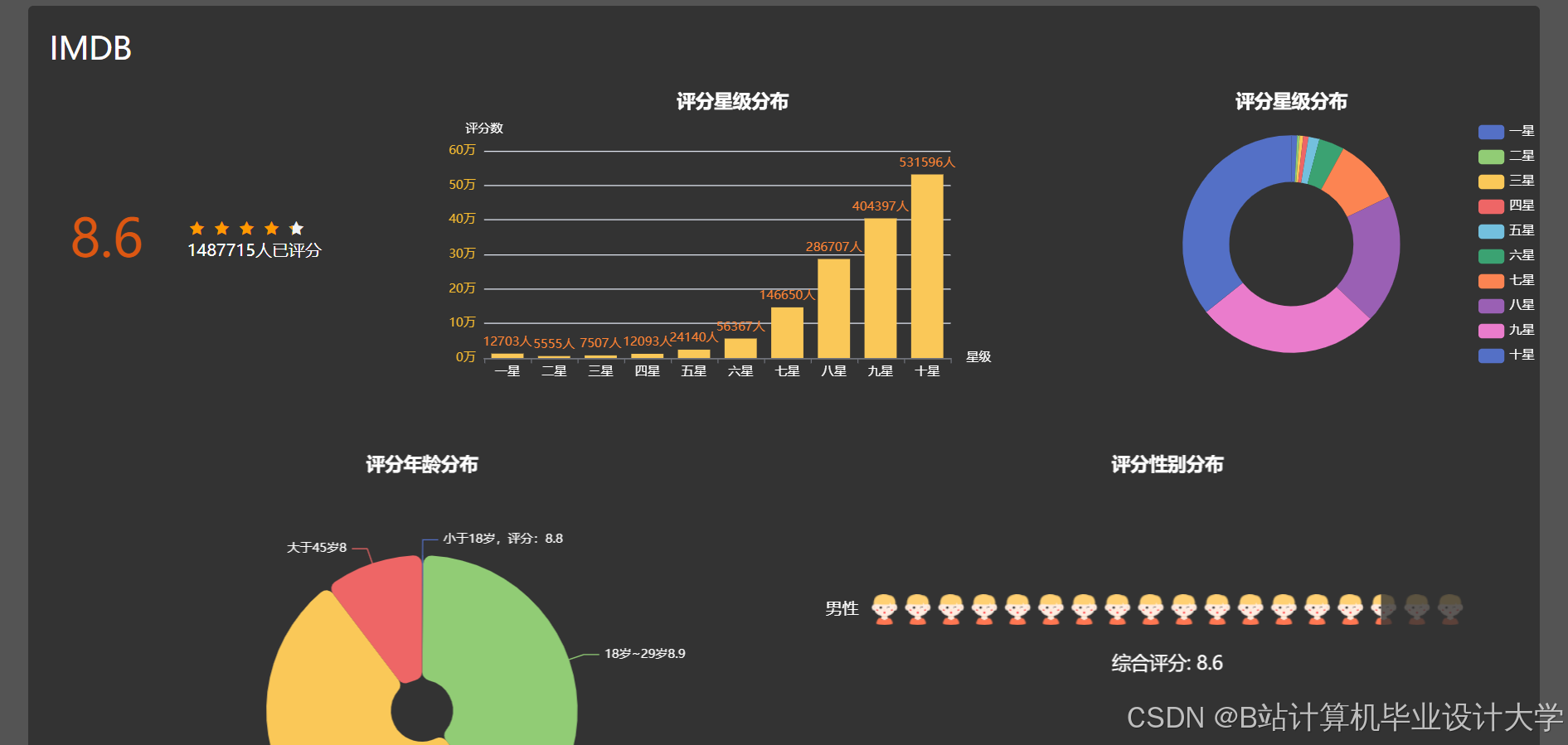
运行截图


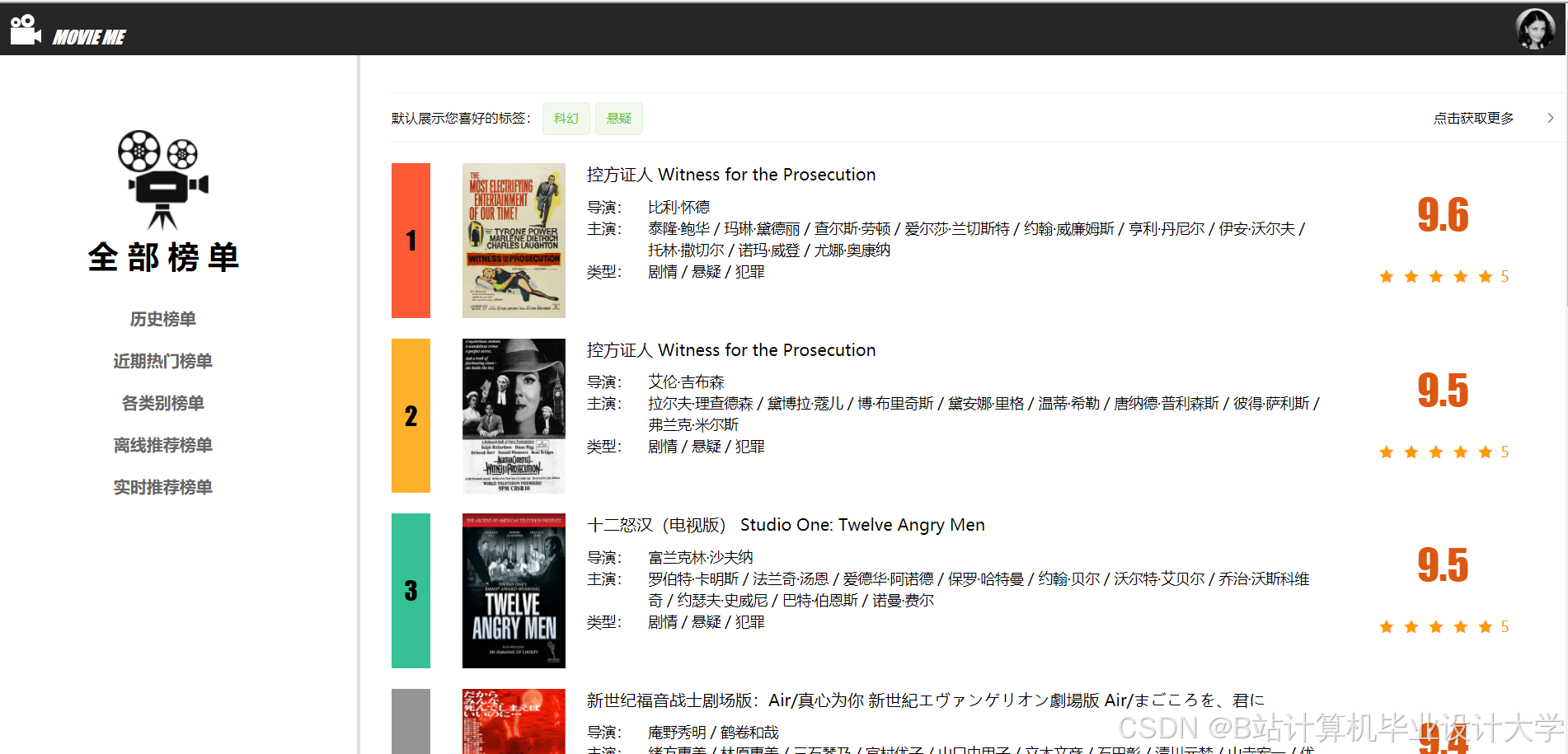
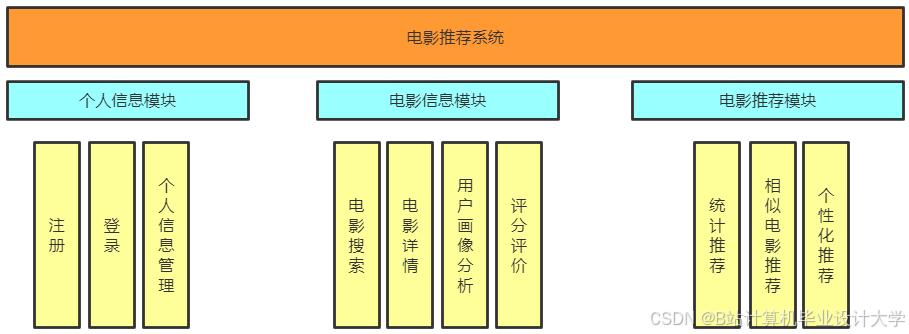
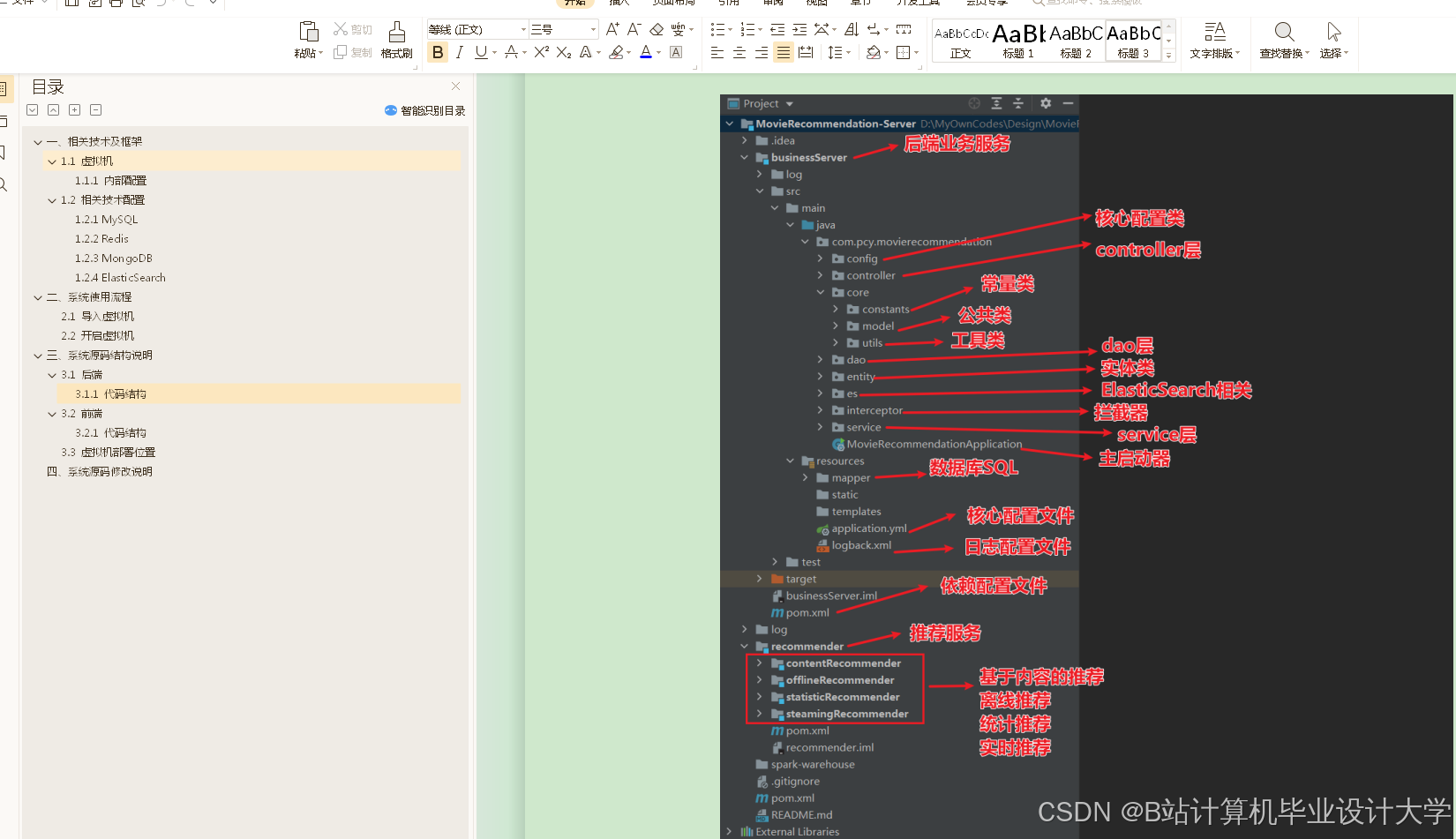
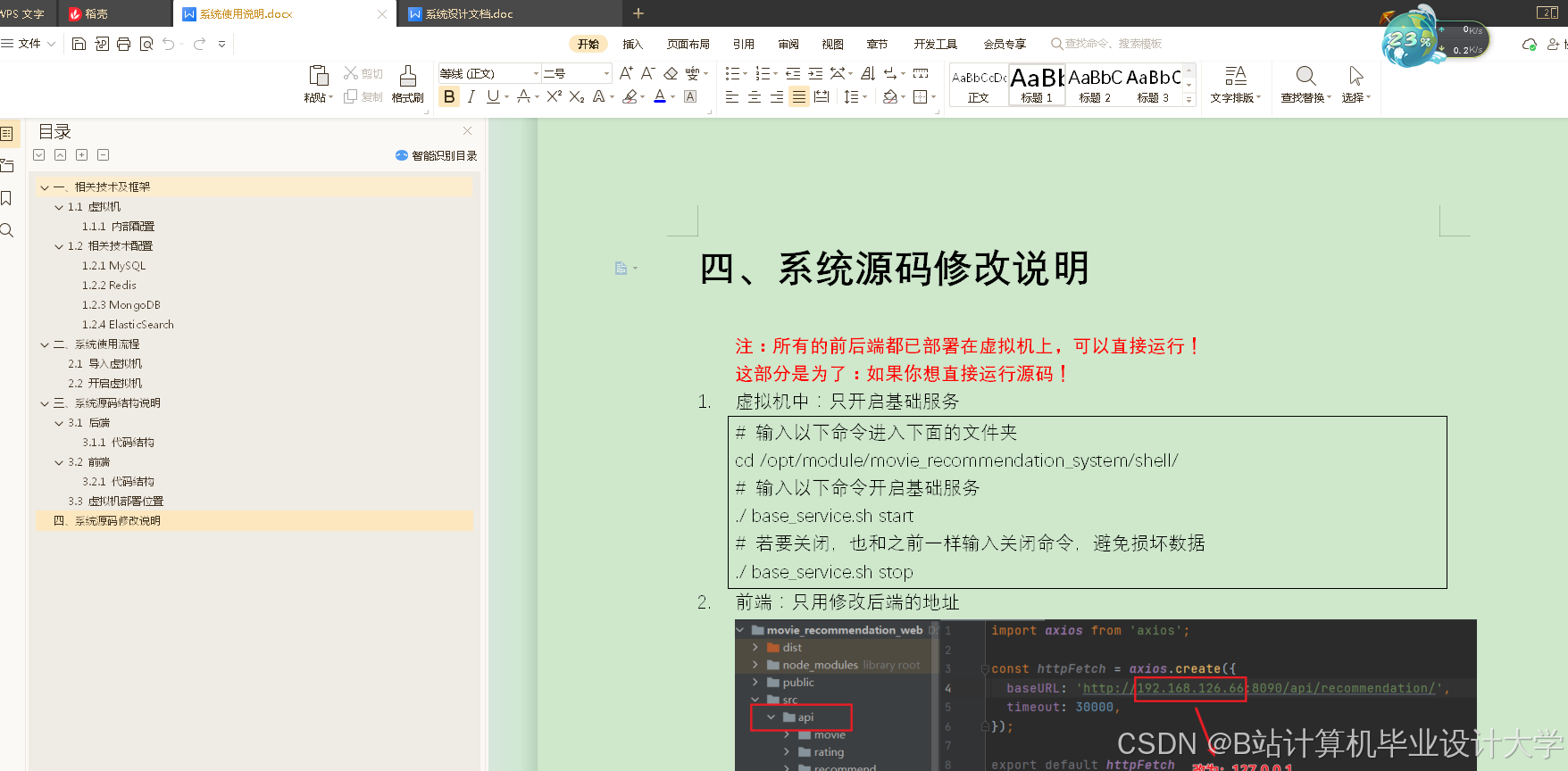
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











