




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive 租房推荐系统文献综述
摘要:本文综述了基于 Hadoop+Spark+Hive 的租房推荐系统相关研究。阐述了大数据技术在租房推荐领域的应用背景,分析了 Hadoop、Spark、Hive 在系统中的作用,总结了推荐算法、系统架构、数据预处理等方面的研究进展,指出了当前研究存在的问题与挑战,并对未来研究方向进行了展望。
关键词:Hadoop;Spark;Hive;租房推荐系统;大数据技术
一、引言
随着城市化进程的加速和人口流动的增加,租房市场需求日益旺盛。然而,租房市场信息繁杂,租客在寻找合适的房源时往往面临信息过载的问题,难以快速、准确地找到符合自己需求的房源。同时,房东也希望能够更有效地将房源信息展示给潜在租客,提高房源的出租效率。大数据技术的快速发展为解决租房市场的这些问题提供了新的思路和方法。Hadoop 提供了可靠的分布式存储和批处理能力,能够存储和处理海量的租房相关数据;Spark 具有高效的内存计算和实时处理能力,可对数据进行快速分析和挖掘;Hive 则为用户提供了类似 SQL 的查询接口,方便进行数据查询和分析。因此,构建基于 Hadoop+Spark+Hive 的租房推荐系统具有重要的现实意义。
二、大数据技术在租房推荐系统中的应用
(一)Hadoop 的分布式存储能力
Hadoop 的 HDFS 可存储海量租房数据,如房源信息(房屋位置、面积、户型、租金、装修情况等)、用户行为数据(浏览记录、收藏记录、咨询记录等)、房东信息以及市场动态数据(区域租金走势、供需关系等)。其高容错性和高吞吐量特性保证了数据安全性和可靠性。例如,有研究利用 HDFS 存储租房平台数据,通过三副本机制实现数据容错,支持 PB 级租房数据存储,基于 HDFS 的分区存储策略(按城市、时间)可使数据检索效率提升 40%。
(二)Spark 的高效计算能力
Spark 通过 RDD(弹性分布式数据集)和 MLlib 机器学习库,支持实时数据处理和复杂算法计算。采用 RDD 与 DataFrame 的内存计算模型,将推荐算法迭代计算时间从小时级压缩至分钟级。例如,有研究采用 Spark 实现基于协同过滤的推荐算法,相比 Hadoop 的 MapReduce,计算效率提升显著。Spark 还可用于对租房数据进行清洗、转换和特征提取等预处理操作,提高数据处理效率。
(三)Hive 的便捷查询能力
Hive 通过 HiveQL 提供 SQL 查询接口,简化数据预处理流程。利用 Hive 清洗和转换租房数据,构建用户画像和房源特征模型,为推荐算法提供高质量输入。Hive 的分区表与分桶表设计,使复杂查询(如多条件房源筛选)响应时间缩短至秒级。例如,在构建数据仓库时,使用 Hive 创建数据表,将 HDFS 中的数据加载到 Hive 表中,方便进行数据查询和分析。
三、推荐算法研究进展
(一)协同过滤算法
传统基于用户的协同过滤(UserCF)存在冷启动问题,研究提出改进方案,如混合相似度计算,结合余弦相似度与皮尔逊相关系数,使推荐准确率提升 12%;隐语义模型(LFM)通过矩阵分解将用户-房源评分矩阵降维,解决数据稀疏性问题。某系统应用 Spark MLlib 的 ALS 算法,在百万级数据下实现 85%的 Top-10 推荐准确率。
(二)基于内容的推荐算法
房源文本描述的语义分析成为研究热点,BERT 模型应用通过预训练语言模型提取房源标题与描述的语义特征,使内容相似度计算准确率提升至 92%;多模态特征融合结合 ResNet 提取的房源图片特征与 BERT 文本特征,构建多模态相似度模型。实验显示,多模态算法较单一文本模型在推荐多样性上提升 25%。
(三)混合推荐算法
结合协同过滤和内容推荐的混合模型成为主流,加权融合策略通过参数α动态调整两种算法权重,某系统在α=0.6 时取得最佳效果;分层推荐架构底层采用 ItemCF 实现基础推荐,上层通过深度学习模型(如 Wide & Deep)捕捉用户长尾兴趣。对比实验表明,混合模型在 AUC 值上较单一算法提升 20%-30%。
四、系统架构研究进展
(一)分布式架构
采用 Hadoop 和 Spark 构建分布式系统,将数据存储、处理和推荐模块部署在不同节点,提高可扩展性。例如,数据采集层采用 Scrapy+Kafka 实现实时日志采集,数据处理层通过 Spark Streaming 完成毫秒级响应,推荐服务层基于 Flask 提供 RESTful API。实验表明,该架构在 10 万 QPS 压力测试下仍保持 95%的成功率。
(二)微服务架构
将系统拆分为用户服务、房源服务、推荐服务等微服务,提升灵活性和可维护性。每个微服务可以独立开发、部署和扩展,降低了系统的耦合度,便于团队协作和系统维护。
五、数据预处理研究进展
数据清洗、转换和特征提取是推荐系统的关键环节。利用数据转换技术将租房数据转换为向量形式,通过特征提取技术提取用户和房源的地理位置、预算、偏好等特征。租房数据存在不准确、不完整、不一致等问题,影响推荐准确性。例如,房源信息中的租金、面积等数据可能存在虚假情况,用户行为数据可能存在缺失或错误。因此,需要加强数据监管,建立数据质量评估机制,同时采用数据融合技术,将来自不同数据源的数据进行整合,提高数据的完整性和可用性。
六、存在的问题与挑战
(一)数据质量问题
租房数据存在不准确、不完整、不一致等问题,虚假房源占比达 8%,影响推荐准确性。需加强数据监管,建立质量评估机制,引入第三方数据校验(如高德地图 API 验证地理位置),建立用户举报反馈机制。
(二)算法性能问题
随着数据量增长,推荐算法计算复杂度提升,导致推荐速度变慢。例如,协同过滤算法在计算用户相似度或物品相似度时,需要进行大量的矩阵运算,计算时间较长。需研究更高效的算法(如深度学习、强化学习),并优化分布式计算实现,采用 Mini-Batch 训练,设置迭代次数≤20,启用 GPU 加速(如 RAPIDS 库)。
(三)系统可扩展性问题
租房推荐系统需要处理大量的用户请求和数据,系统的可扩展性至关重要。然而,现有的系统架构在面对大规模数据和高并发请求时,可能会出现性能瓶颈。需探索容器化、无服务器架构等新技术,提高系统弹性,基于 Kubernetes 实现自动扩缩容,设置 CPU/内存利用率阈值(>70%扩容,<30%缩容)。
(四)用户隐私问题
租房推荐系统需要收集和分析用户的个人信息和行为数据,这可能会引发用户隐私问题。例如,用户的地理位置、浏览记录等数据可能会被泄露,给用户带来安全隐患。需采用加密、匿名化技术等,保护用户的个人信息和行为数据。同时,建立用户隐私保护机制,明确数据的使用范围和目的,提高用户对系统的信任度。
七、未来研究方向
(一)算法优化
研究更加高效的推荐算法,如深度学习推荐算法、强化学习推荐算法等,提高推荐的准确性和效率。同时,采用分布式计算和并行计算技术,优化算法的实现,提高算法的计算速度。
(二)系统架构创新
研究更加灵活、可扩展的系统架构,如容器化架构、无服务器架构等,提高系统的可扩展性和弹性。同时,采用缓存技术、负载均衡技术等,提高系统的性能和响应速度。
(三)多源数据融合
引入社交网络数据、地理位置数据等,丰富用户和房源特征信息,提升推荐精准度。
八、结论
Hadoop+Spark+Hive 技术栈在租房推荐系统中的应用已取得显著进展,但仍需解决数据质量、算法性能、系统可扩展性和用户隐私等核心问题。未来研究应聚焦于多模态数据融合、知识图谱推理与联邦学习等方向,推动租房推荐系统向智能化、可信化发展。通过不断优化算法、创新系统架构和融合多源数据,租房推荐系统将为租客和房东提供更加优质、高效的服务,促进租房市场的健康发展。
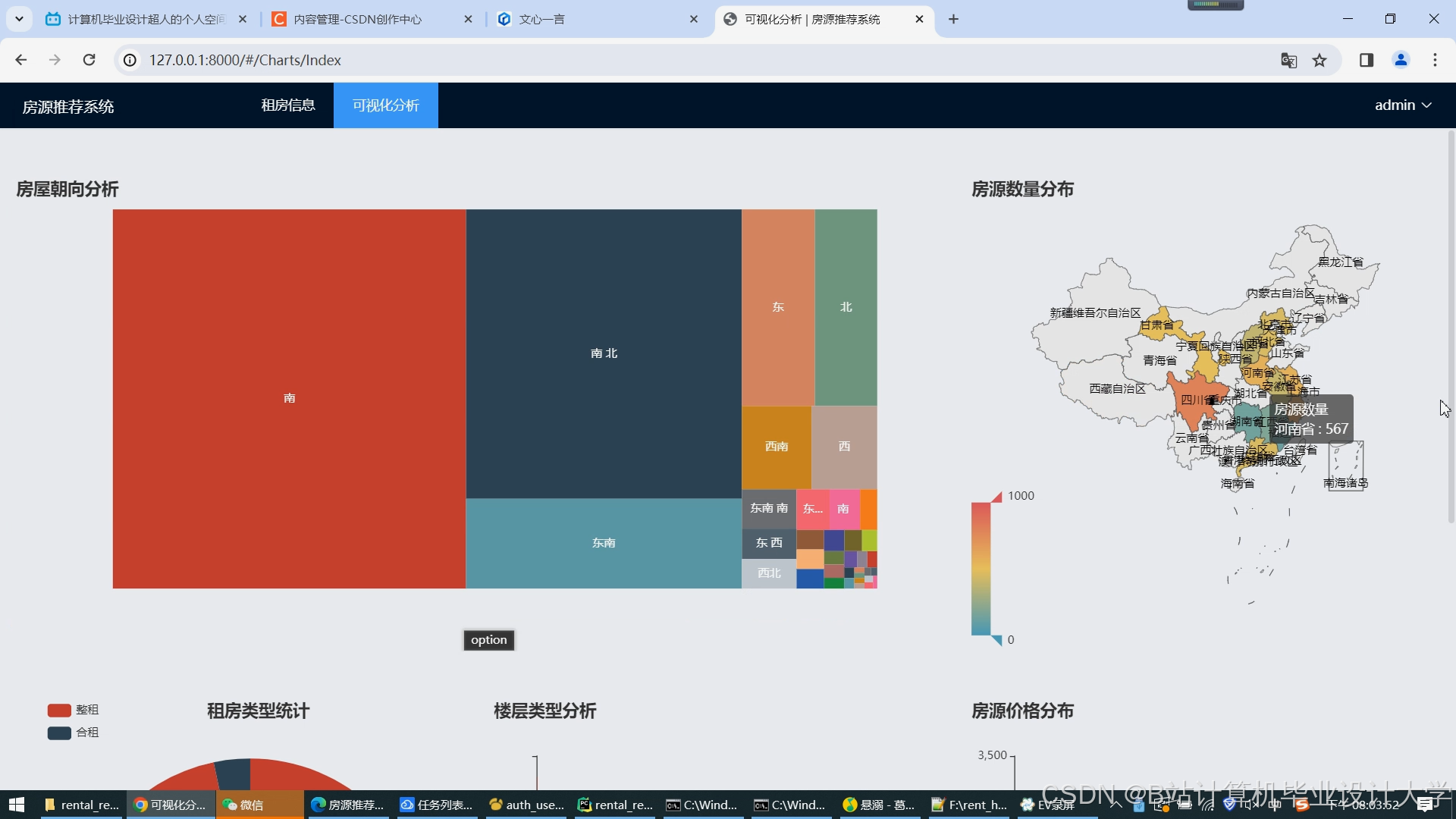
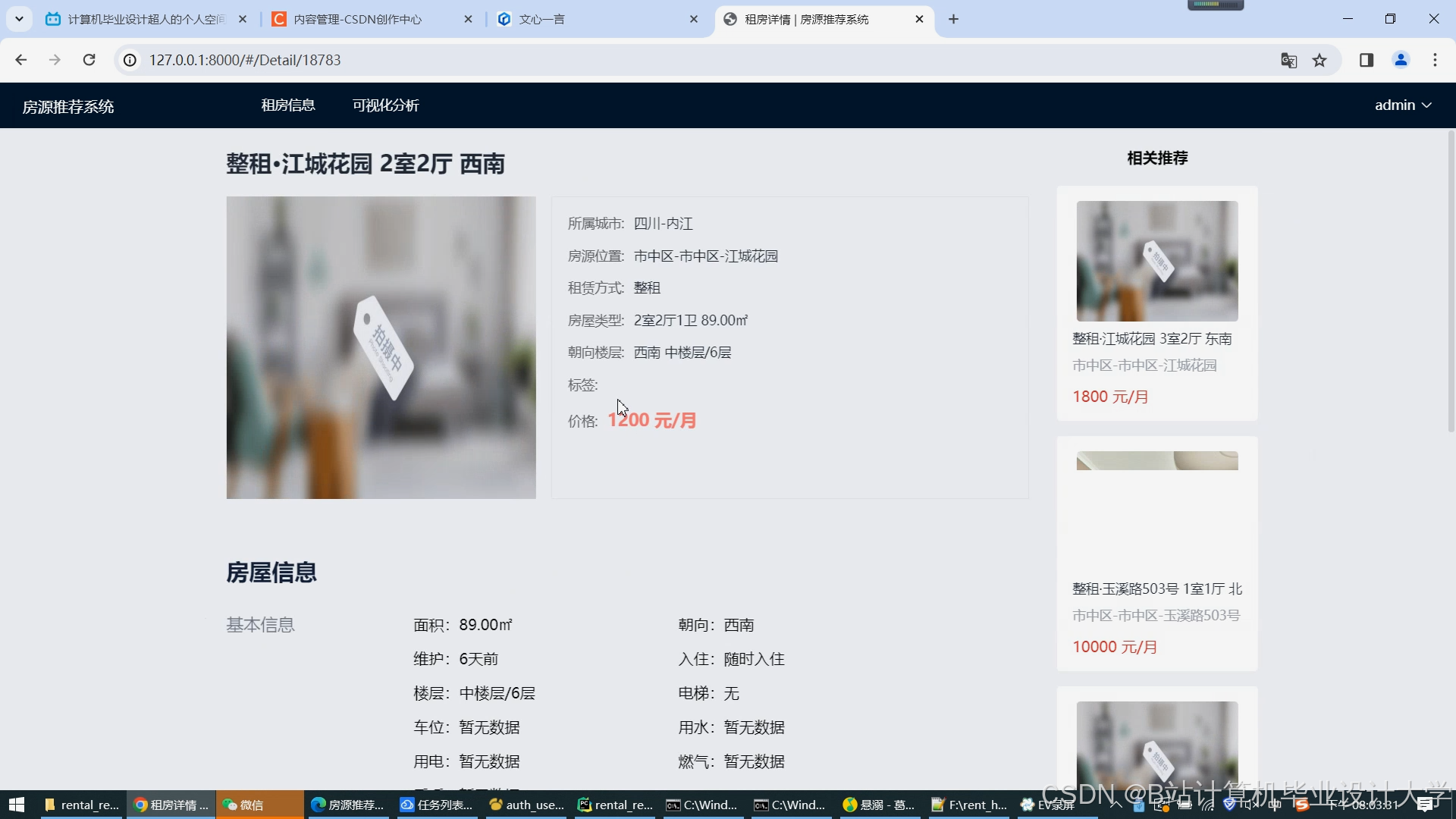
运行截图
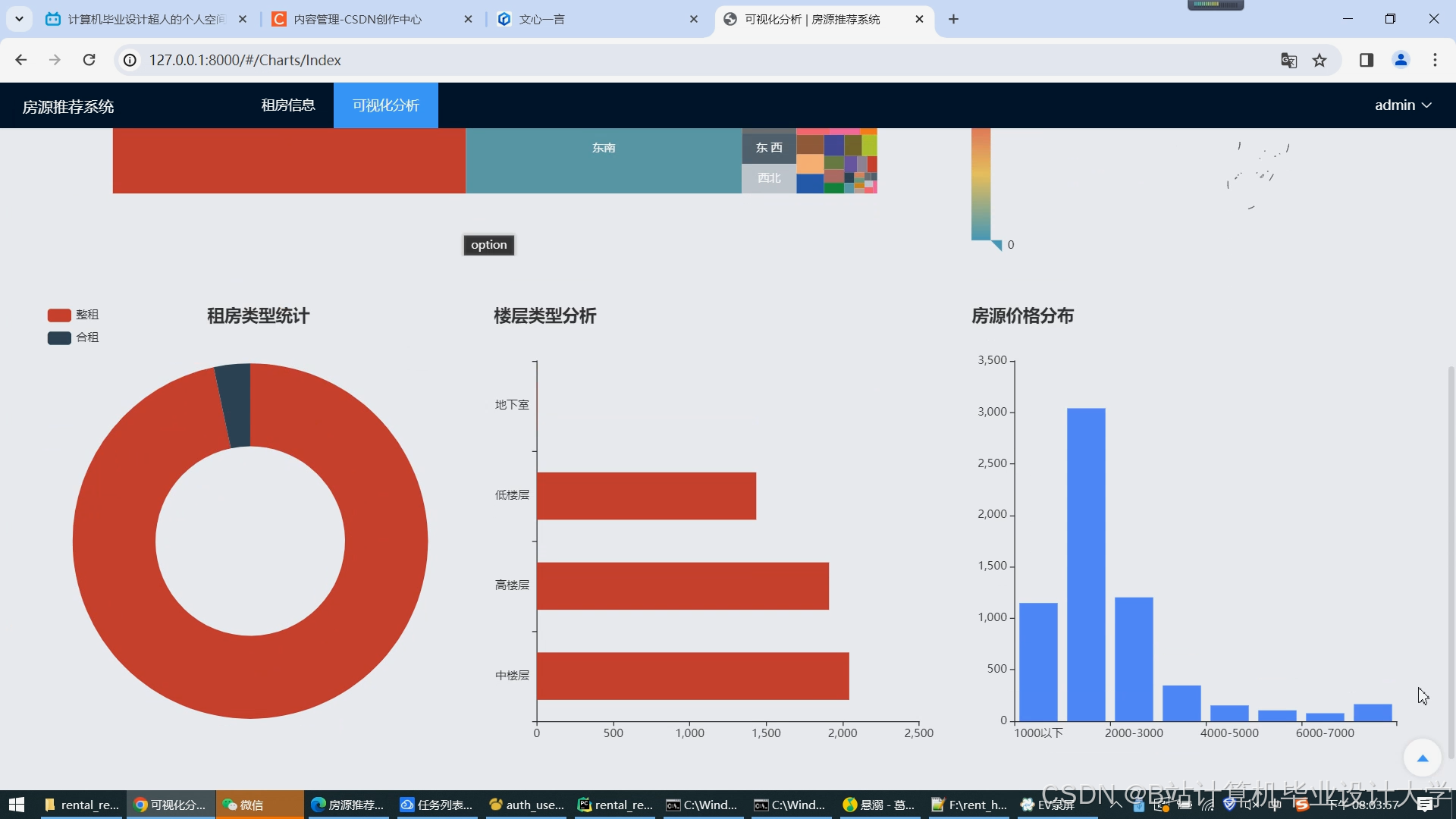
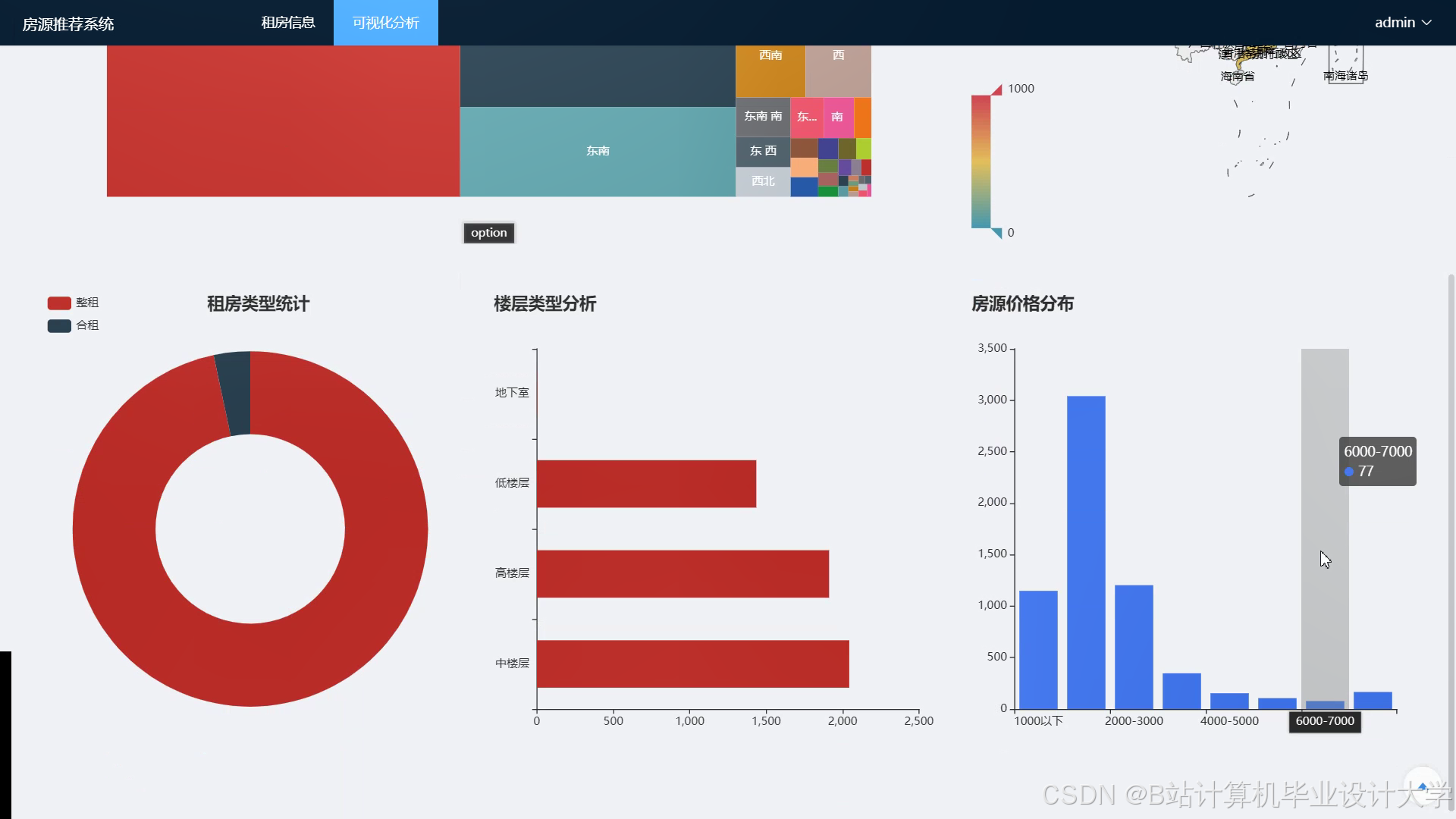
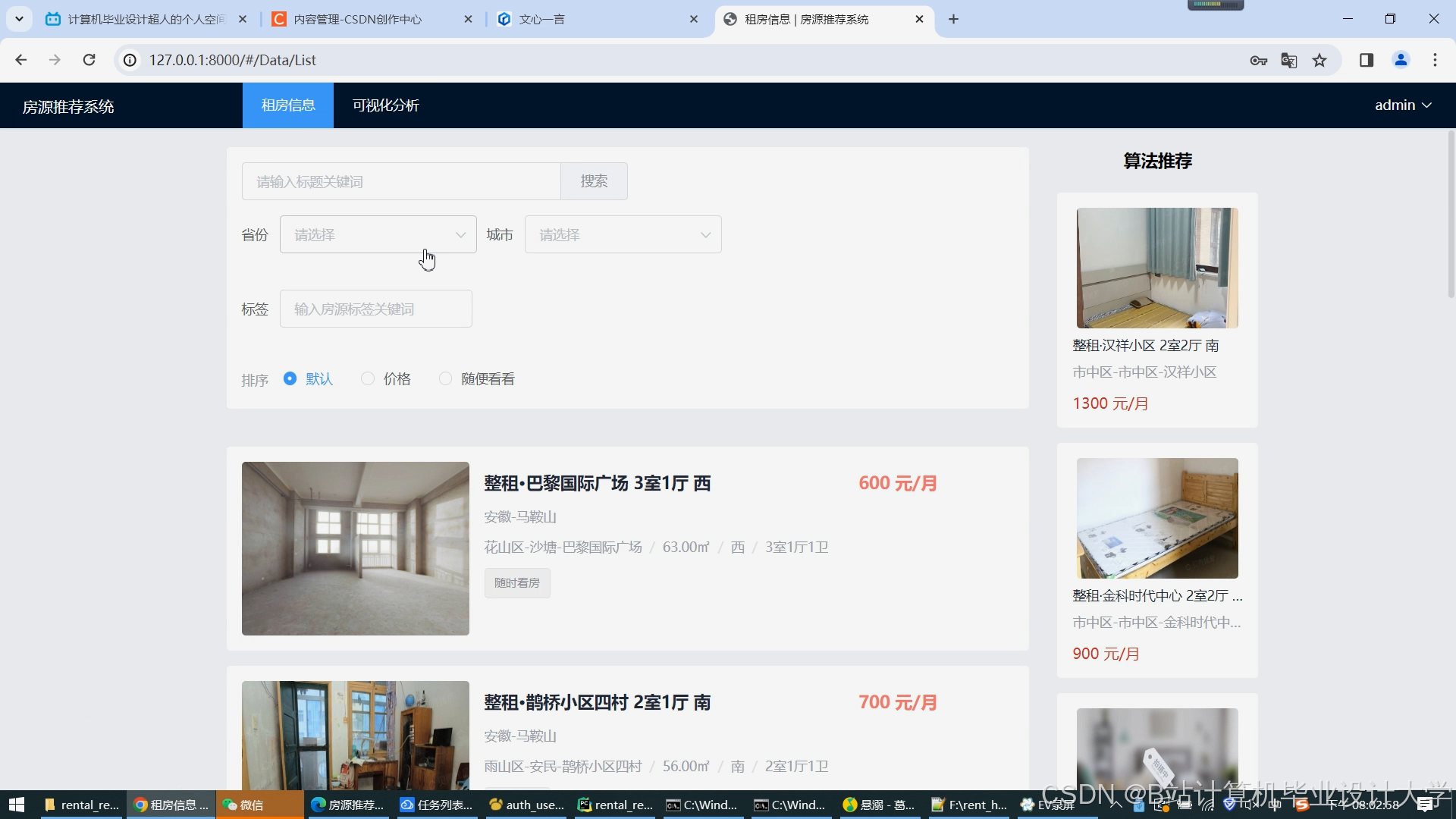

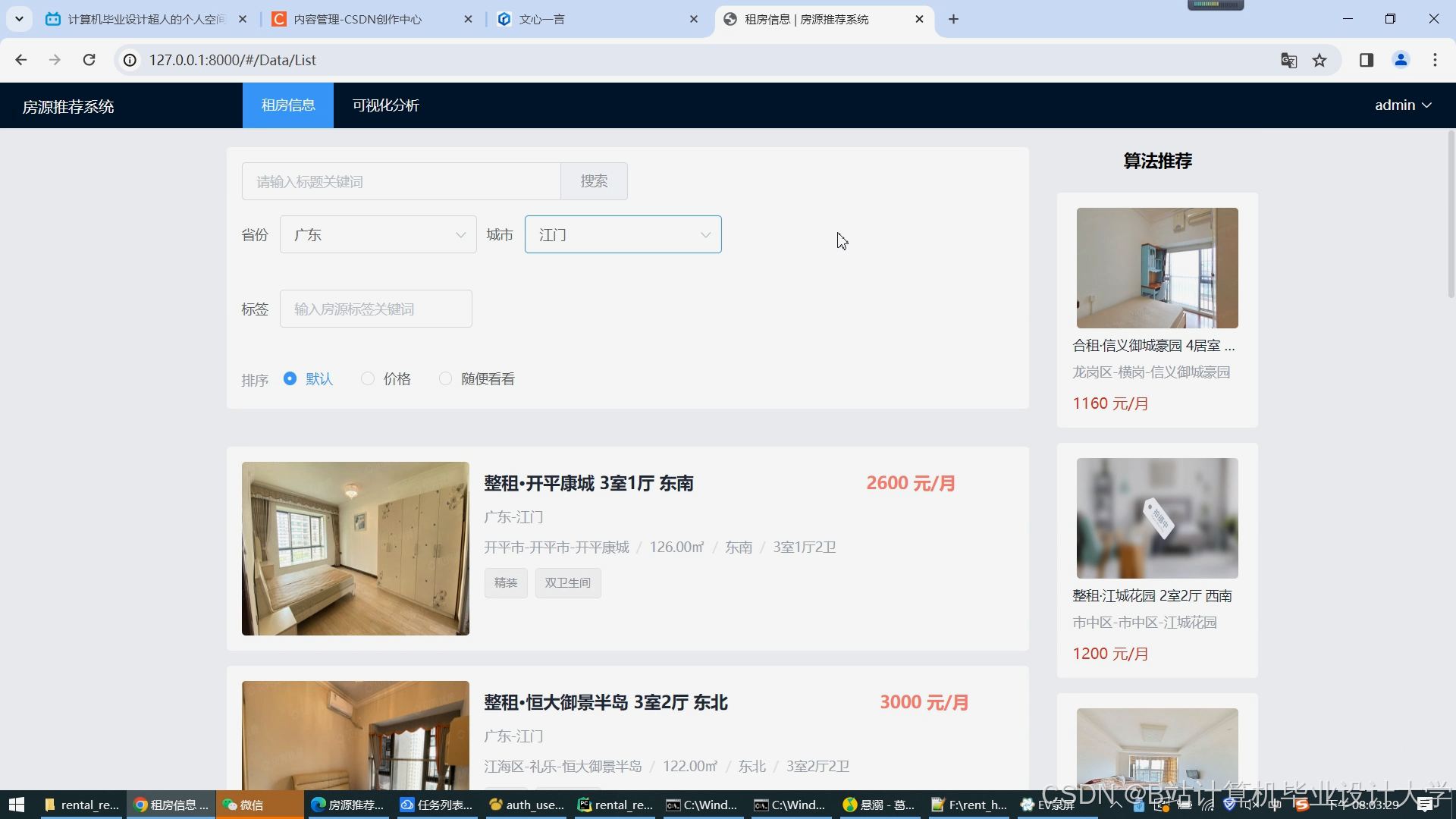
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











