




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
《Hadoop+Spark+Hive 视频推荐系统》开题报告
一、选题背景与意义
(一)选题背景
随着互联网技术的飞速发展,视频内容呈现爆炸式增长。在线视频平台如爱奇艺、腾讯视频、B站等积累了海量的视频数据,涵盖了电影、电视剧、综艺、纪录片、短视频等多种类型。用户在面对如此丰富的视频资源时,往往难以快速找到自己感兴趣的内容,信息过载问题日益严重。同时,视频平台也面临着提高用户留存率、增加用户粘性和提升视频播放量的挑战。
大数据技术的兴起为解决视频推荐问题提供了新的思路和方法。Hadoop 作为一种分布式存储和计算框架,能够处理海量数据;Spark 以其内存计算和迭代计算能力,在数据处理速度上具有显著优势;Hive 则提供了类似 SQL 的查询语言,方便对数据进行管理和分析。将 Hadoop、Spark 和 Hive 应用于视频推荐系统,可以实现对海量视频数据的高效处理和分析,为用户提供个性化的视频推荐。
(二)选题意义
- 理论意义
本研究将大数据处理技术与视频推荐系统相结合,探索如何利用 Hadoop、Spark 和 Hive 优化视频推荐的准确性和效率。通过深入研究相关算法和技术,丰富和完善视频推荐系统的理论体系,为后续的研究提供参考和借鉴。 - 实践意义
对于视频平台而言,精准的视频推荐可以提高用户的满意度和忠诚度,增加用户的观看时长和付费意愿,从而提升平台的商业价值。对于用户来说,个性化推荐能够帮助他们快速发现感兴趣的视频,节省时间和精力,提高观看体验。
二、国内外研究现状
(一)国外研究现状
国外在视频推荐领域的研究起步较早,许多知名的科技公司和学术机构都开展了相关研究。例如,Netflix 通过举办推荐算法竞赛,吸引了全球众多研究者的参与,推动了视频推荐算法的发展。Google、YouTube 等平台也投入了大量资源进行视频推荐系统的研发,采用了协同过滤、内容推荐、深度学习等多种算法。在大数据处理方面,国外的研究者广泛使用 Hadoop、Spark 等技术来处理和分析海量视频数据,提高推荐系统的性能。
(二)国内研究现状
国内视频行业近年来发展迅速,各大视频平台也在积极探索和应用视频推荐技术。爱奇艺、腾讯视频等平台通过引入机器学习和深度学习算法,不断优化推荐效果。同时,国内的高校和科研机构也在视频推荐领域开展了一系列研究工作,取得了一定的成果。然而,与国外相比,国内在视频推荐系统的理论研究和实际应用方面仍存在一定的差距,特别是在大数据处理技术的应用上还有待进一步提高。
(三)研究现状总结
目前,视频推荐系统已经取得了一定的进展,但仍存在一些问题,如推荐准确性不高、实时性不足、可解释性差等。同时,随着视频数据的不断增长,如何高效地处理和分析这些数据,成为视频推荐系统面临的重要挑战。Hadoop、Spark 和 Hive 等大数据处理技术为解决这些问题提供了新的途径,但目前将这三者结合应用于视频推荐系统的研究还相对较少。
三、研究目标与内容
(一)研究目标
- 设计并实现一个基于 Hadoop、Spark 和 Hive 的视频推荐系统,能够高效处理和分析海量视频数据。
- 探索适合视频推荐的算法,并结合 Hadoop、Spark 和 Hive 技术进行优化,提高推荐的准确性和实时性。
- 开发可视化界面,展示视频推荐结果和系统的相关指标,方便用户和管理人员使用和监控。
(二)研究内容
- 系统架构设计
- 研究 Hadoop、Spark 和 Hive 的技术特点和优势,设计合理的系统架构,实现数据的采集、存储、处理和推荐功能。
- 确定各组件之间的数据交互方式和接口规范,确保系统的稳定性和可扩展性。
- 数据处理与分析
- 使用 Hadoop 分布式文件系统(HDFS)存储海量视频数据,包括视频元数据、用户行为数据等。
- 利用 Hive 构建数据仓库,对数据进行清洗、转换和预处理,为后续的推荐算法提供高质量的数据支持。
- 采用 Spark 进行数据处理和分析,提取视频的特征和用户的兴趣偏好,为推荐算法提供依据。
- 推荐算法研究与应用
- 研究协同过滤算法、内容推荐算法和混合推荐算法等常见视频推荐算法的原理和实现方法。
- 结合 Hadoop、Spark 和 Hive 技术,对这些算法进行优化和改进,提高推荐的准确性和效率。
- 实验对比不同推荐算法的性能,选择最适合本系统的推荐算法。
- 可视化界面开发
- 使用前端技术(如 HTML、CSS、JavaScript)和可视化库(如 ECharts、D3.js)开发可视化界面。
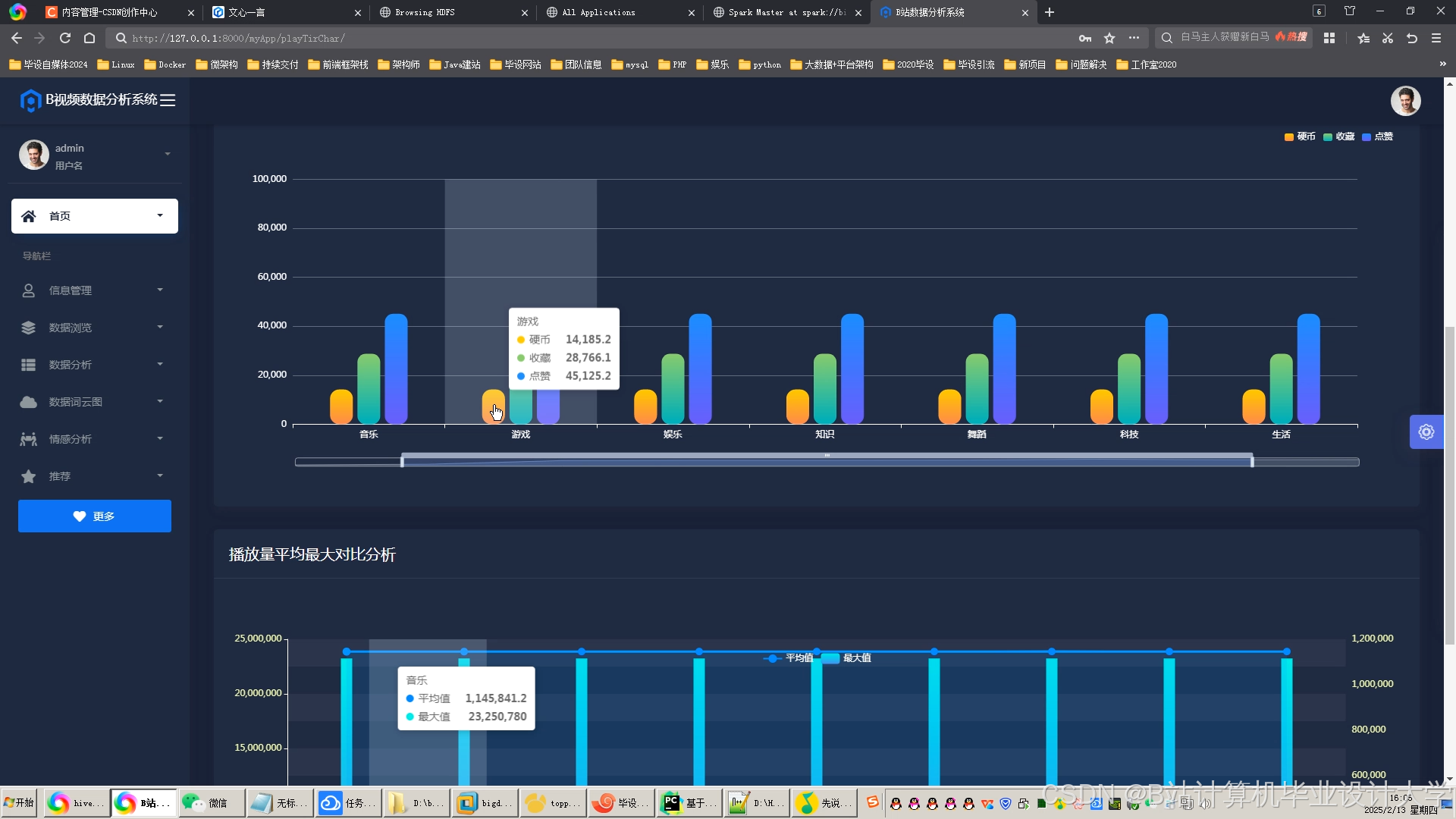
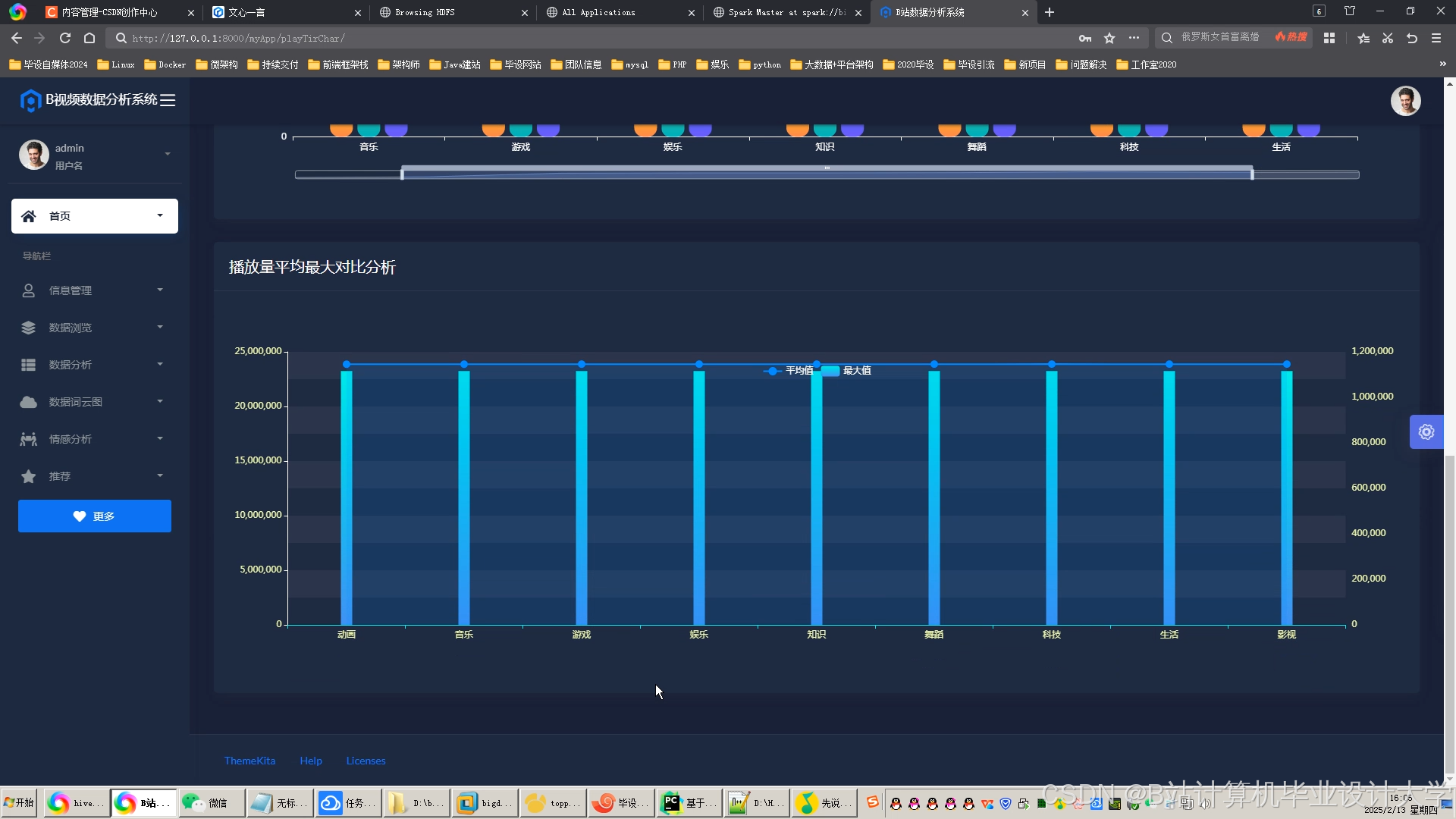
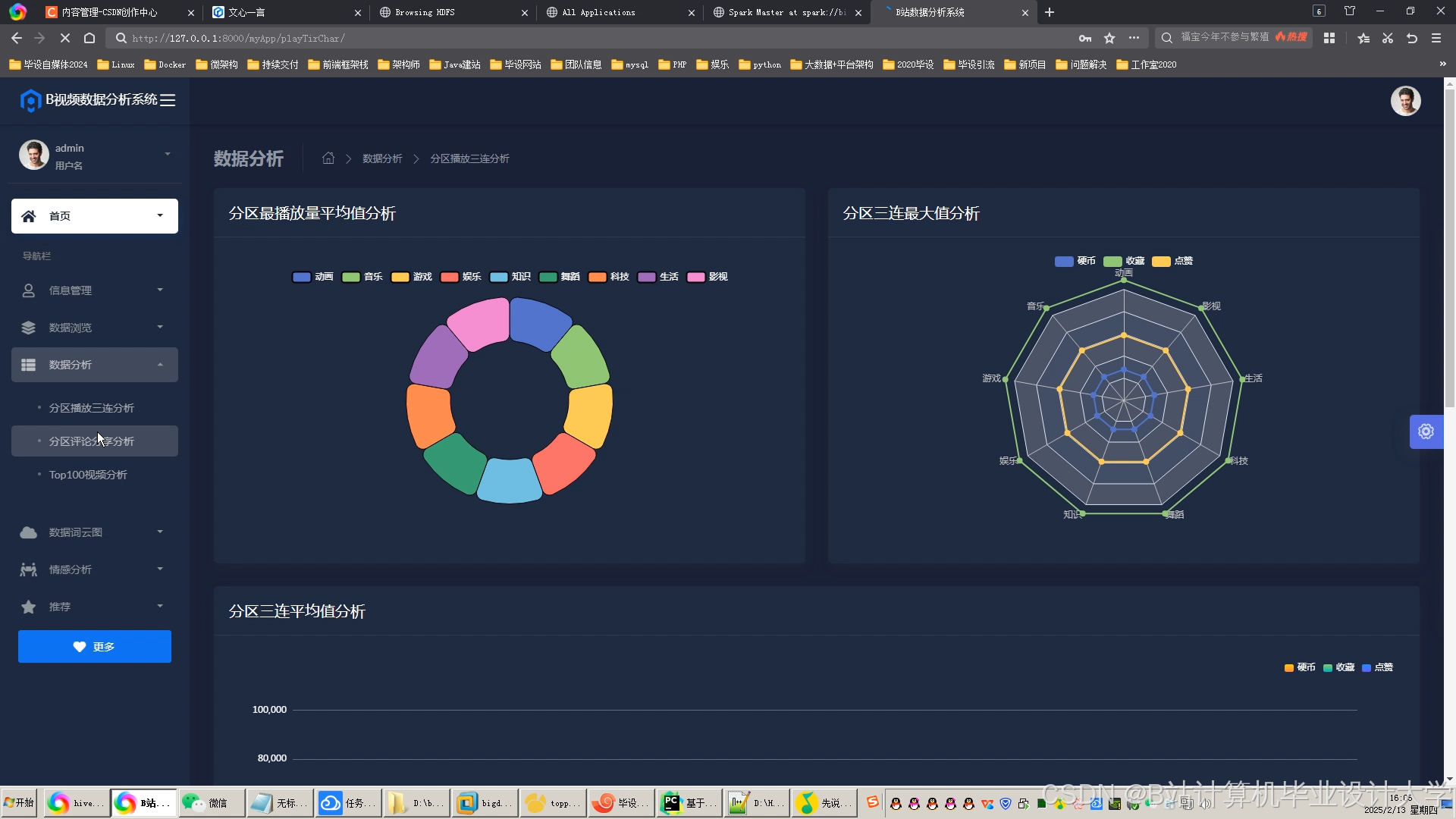
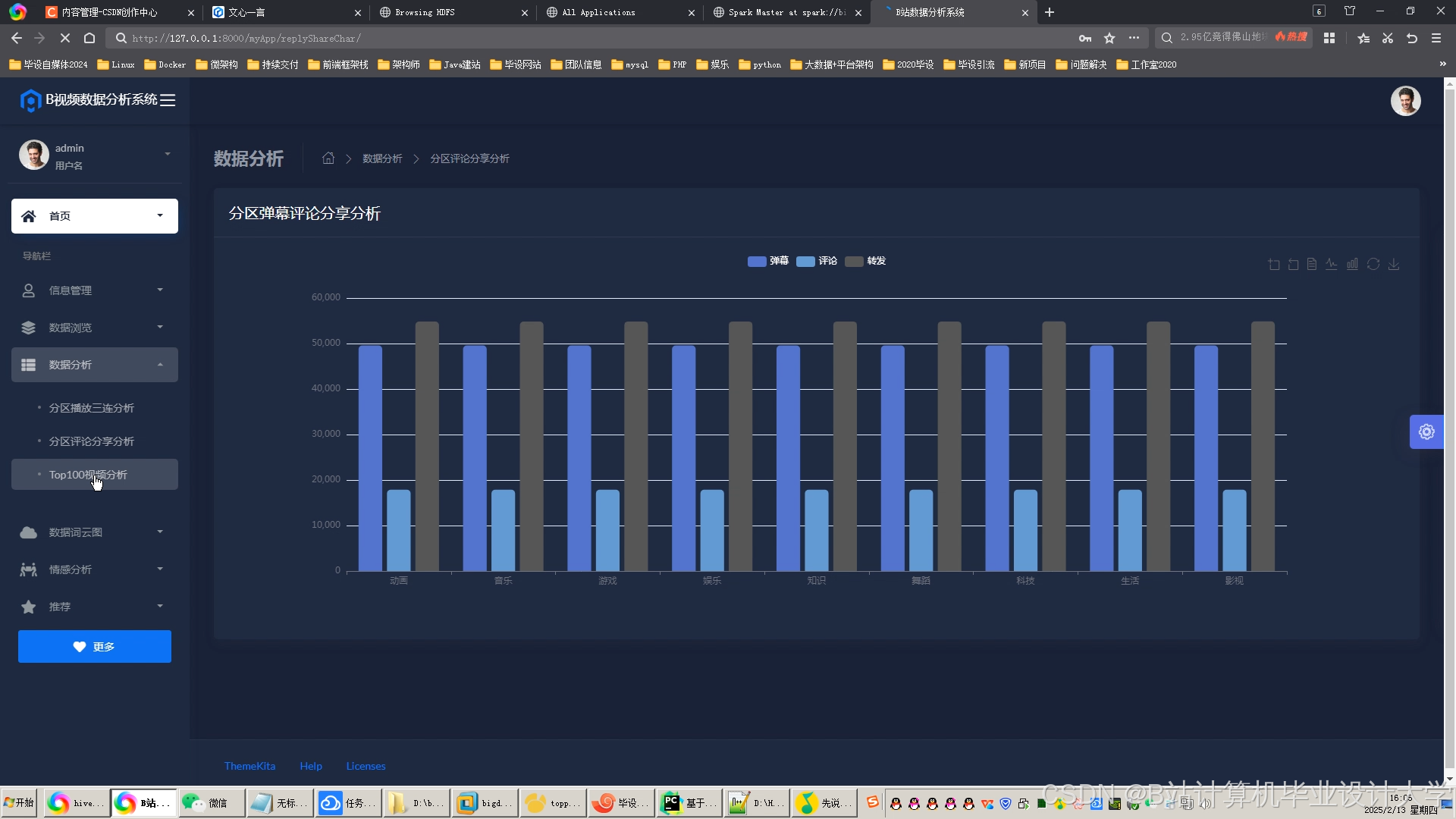
- 在界面上展示视频推荐结果、用户行为分析图表和系统的各项指标,如推荐准确率、用户满意度等。
- 实现用户与系统的交互功能,如用户反馈、搜索等。
四、研究方法与技术路线
(一)研究方法
- 文献研究法:查阅国内外相关文献,了解视频推荐系统和大数据处理技术的研究现状和发展趋势,为系统的设计和实现提供理论支持。
- 实验研究法:通过实验对比不同推荐算法和参数设置下的系统性能,分析系统的优势和不足,不断优化系统。
- 系统开发法:采用分层架构设计,使用 Hadoop、Spark、Hive 等技术进行系统开发,实现视频推荐系统的各项功能。
(二)技术路线
- 数据采集与存储
- 使用爬虫技术或平台提供的 API 接口采集视频数据和用户行为数据。
- 将采集到的数据存储到 HDFS 中,并使用 Hive 创建相应的表进行管理。
- 数据处理与分析
- 使用 Spark 对存储在 Hive 中的数据进行清洗、转换和特征提取。
- 构建用户 - 视频评分矩阵(或兴趣模型)和视频特征向量,为推荐算法提供输入。
- 推荐算法实现
- 在 Spark 中实现协同过滤算法、内容推荐算法和混合推荐算法。
- 对算法进行参数调优,提高推荐的准确性和实时性。
- 可视化界面开发
- 使用前端框架(如 Vue.js、React)构建可视化界面的基本结构。
- 调用后端 API 获取推荐结果和系统指标数据,使用可视化库进行展示。
- 系统测试与优化
- 对系统进行功能测试、性能测试和用户体验测试,发现并解决系统中存在的问题。
- 根据测试结果对系统进行优化,提高系统的稳定性和性能。
五、预期成果与创新点
(一)预期成果
- 完成基于 Hadoop、Spark 和 Hive 的视频推荐系统的设计与实现,包括系统架构设计、数据处理模块、推荐算法模块和可视化界面模块。
- 通过实验验证系统的推荐效果,展示系统在推荐准确性、实时性和可扩展性等方面的优势。
- 撰写相关学术论文,发表在国内外相关学术期刊或会议上。
(二)创新点
- 将 Hadoop、Spark 和 Hive 三种大数据处理技术有机结合,应用于视频推荐系统,充分发挥它们在分布式存储、计算和分析方面的优势,提高系统的处理能力和推荐效率。
- 提出一种基于混合推荐算法的视频推荐方法,结合协同过滤和内容推荐算法的优点,并利用 Spark 进行优化,提高推荐的准确性和多样性。
- 开发可视化界面,直观展示视频推荐结果和系统的相关指标,方便用户和管理人员使用和监控,提高系统的可用性和用户体验。
六、研究计划与进度安排
(一)第 1 - 2 个月:文献调研与需求分析
- 查阅国内外相关文献,了解视频推荐系统和大数据处理技术的研究现状和发展趋势。
- 与视频平台的相关人员进行沟通,了解他们的需求和痛点,确定系统的功能和性能指标。
(二)第 3 - 4 个月:系统架构设计与技术选型
- 设计基于 Hadoop、Spark 和 Hive 的视频推荐系统架构,确定各组件的功能和交互方式。
- 选择合适的技术和工具,如开发语言、数据库、可视化库等。
(三)第 5 - 7 个月:数据处理与分析模块开发
- 搭建 Hadoop 和 Spark 集群环境,配置相关参数。
- 使用 Hive 构建数据仓库,对采集到的视频数据和用户行为数据进行清洗、转换和预处理。
- 利用 Spark 进行数据分析和特征提取,构建用户 - 视频评分矩阵和视频特征向量。
(四)第 8 - 10 个月:推荐算法模块开发
- 研究协同过滤算法、内容推荐算法和混合推荐算法的原理和实现方法。
- 在 Spark 中实现这些算法,并进行参数调优。
- 实验对比不同推荐算法的性能,选择最适合本系统的推荐算法。
(五)第 11 - 12 个月:可视化界面开发与系统测试
- 使用前端技术开发可视化界面,展示视频推荐结果和系统的相关指标。
- 对系统进行功能测试、性能测试和用户体验测试,发现并解决系统中存在的问题。
- 根据测试结果对系统进行优化,撰写系统使用说明书和测试报告。
(六)第 13 - 14 个月:论文撰写与答辩准备
- 撰写学术论文,总结研究成果和创新点。
- 准备毕业答辩材料,进行答辩演练。
七、参考文献
[此处列出在开题报告中引用的相关文献,按照学术规范进行排版,例如:]
[1] 项亮. 推荐系统实践[M]. 人民邮电出版社, 2012.
[2] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107 - 113.
[3] Zaharia M, Chowdhury M, Franklin M J, et al. Spark: cluster computing with working sets[C]//Proceedings of the 2nd USENIX conference on Hot topics in cloud computing. 2010: 10 - 10.
[4] Thusoo A, Sarma J S, Jain N, et al. Hive: a warehousing solution over a map-reduce framework[J]. Proceedings of the VLDB Endowment, 2009, 2(2): 1626 - 1629.
[5] 李航. 统计学习方法[M]. 清华大学出版社, 2012.
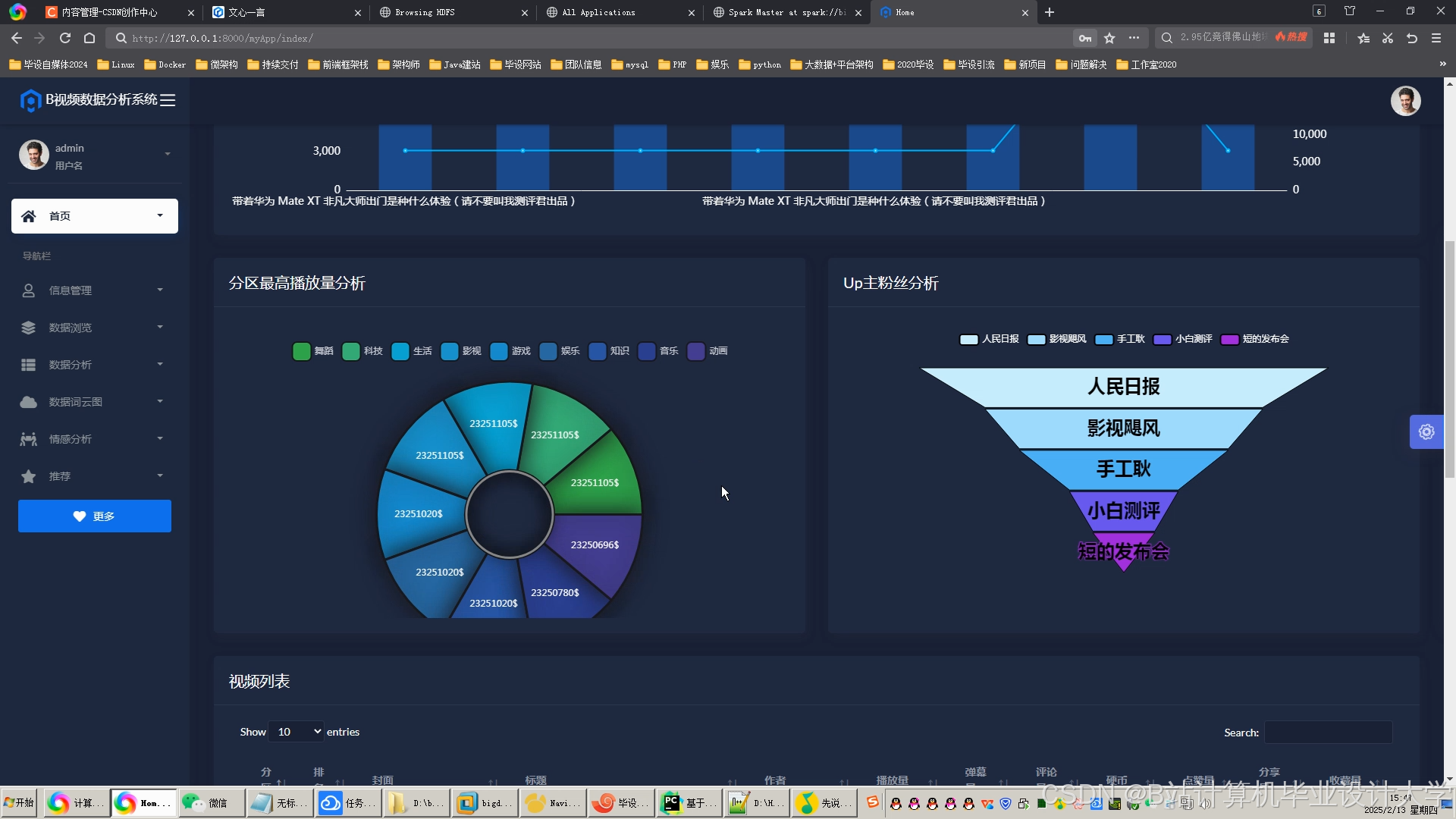
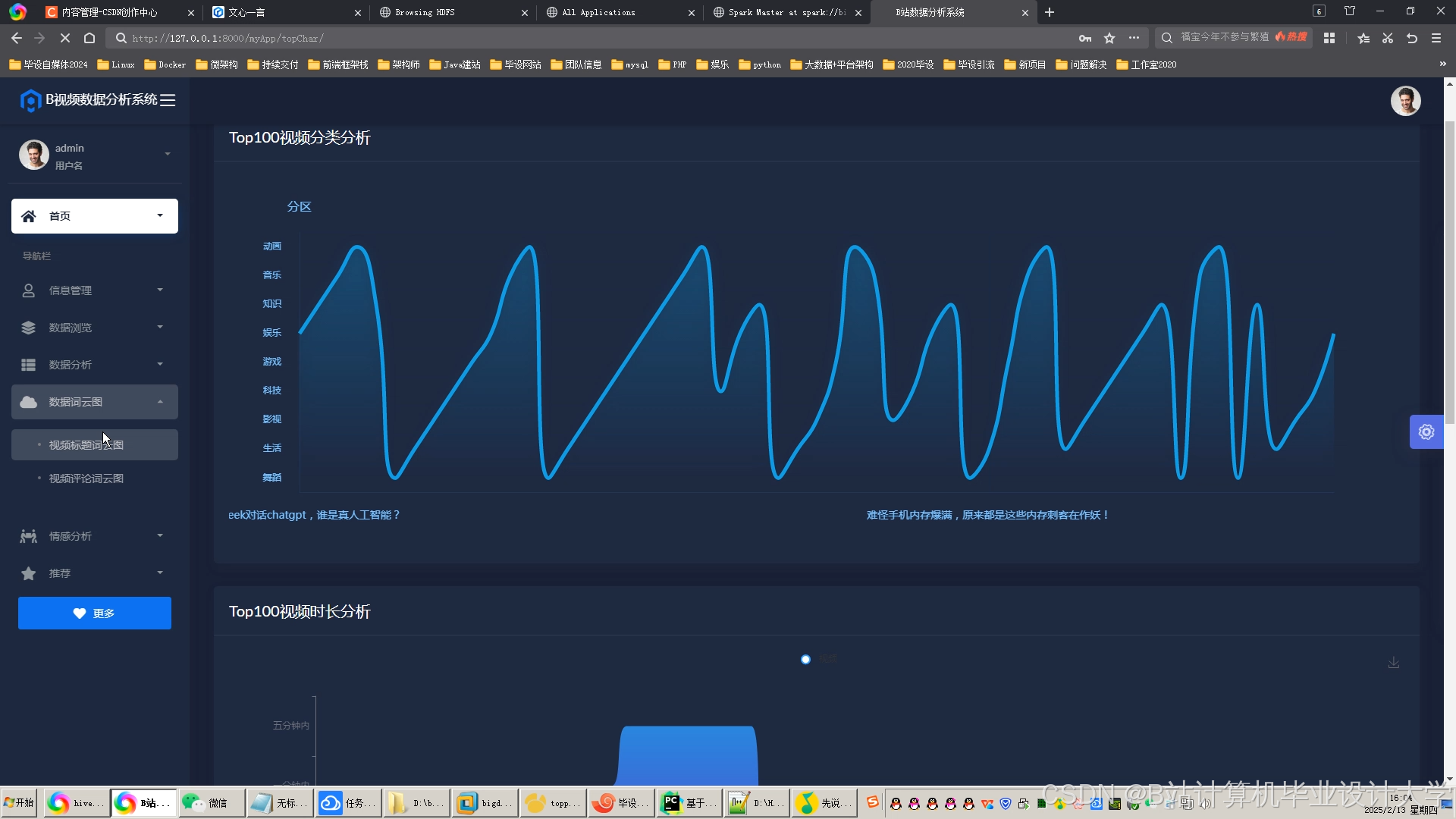
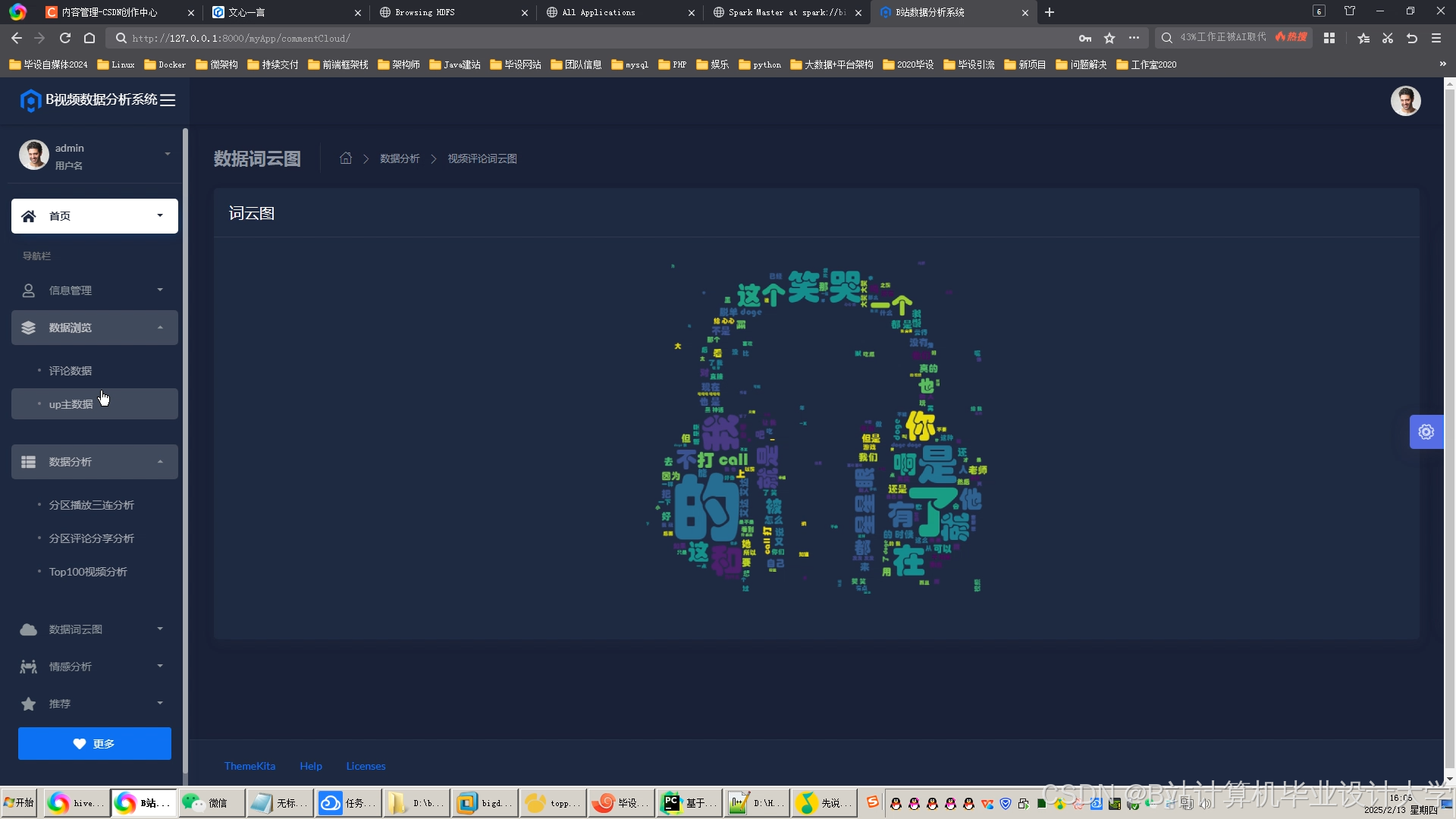
运行截图
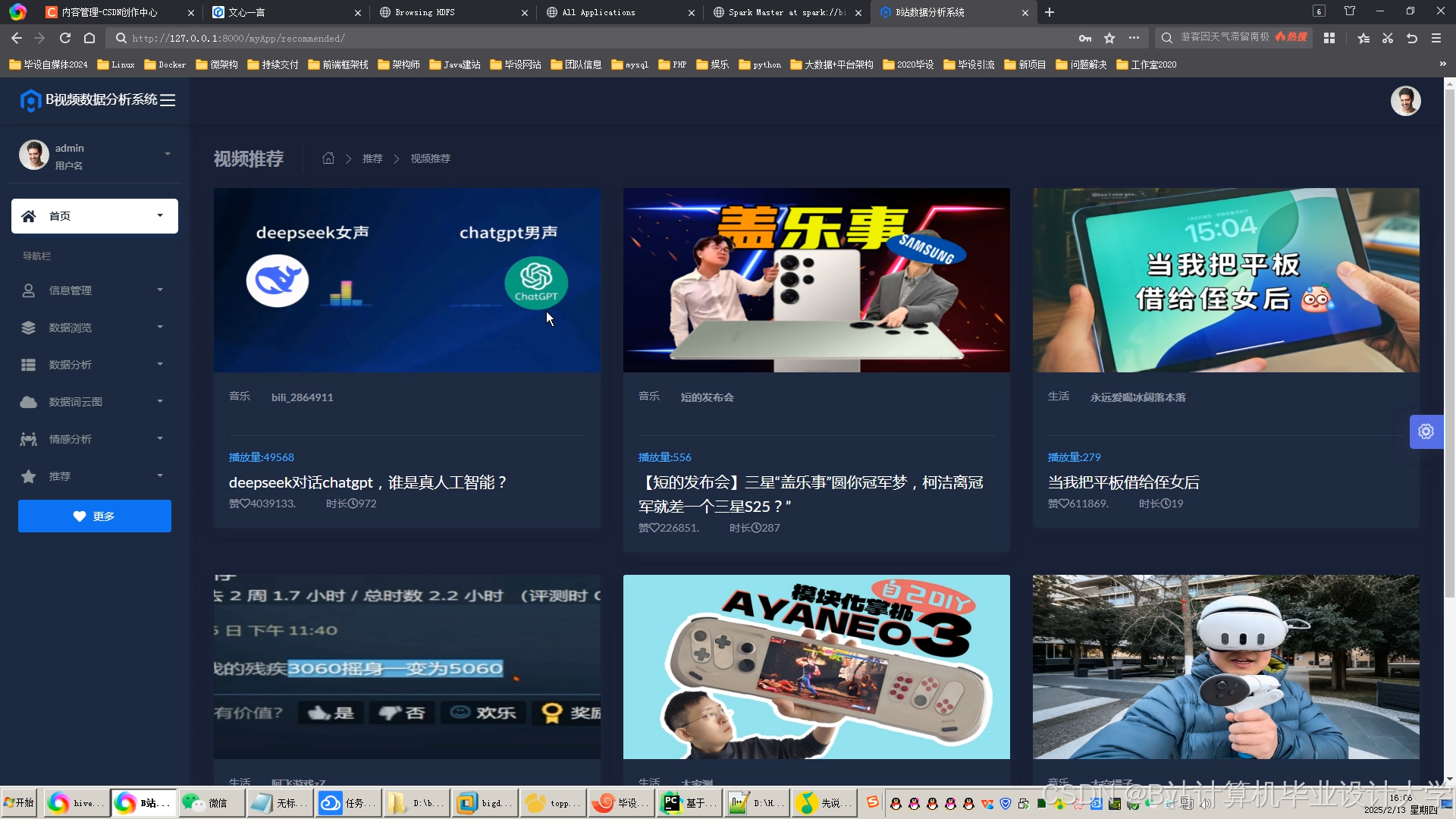
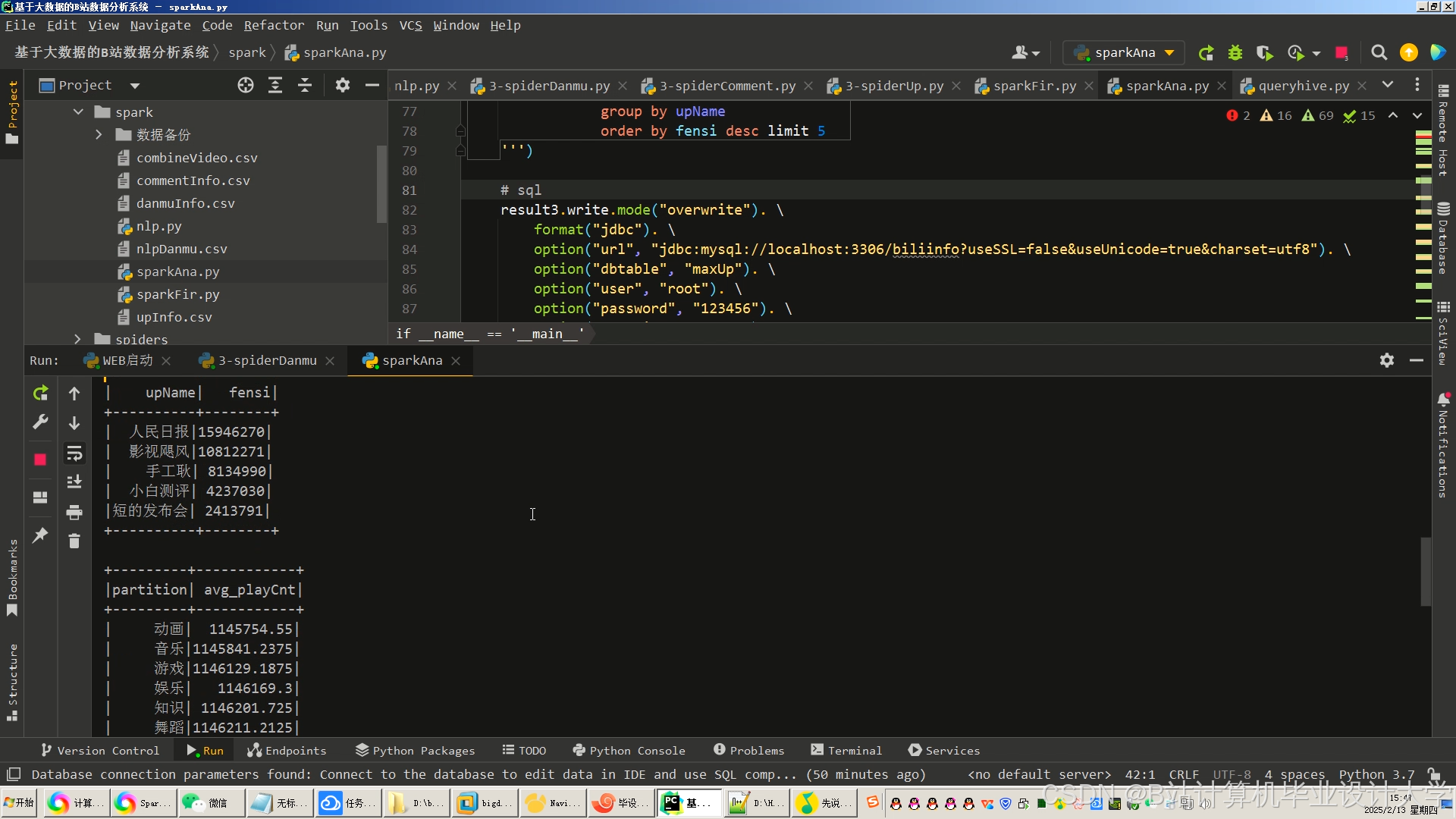
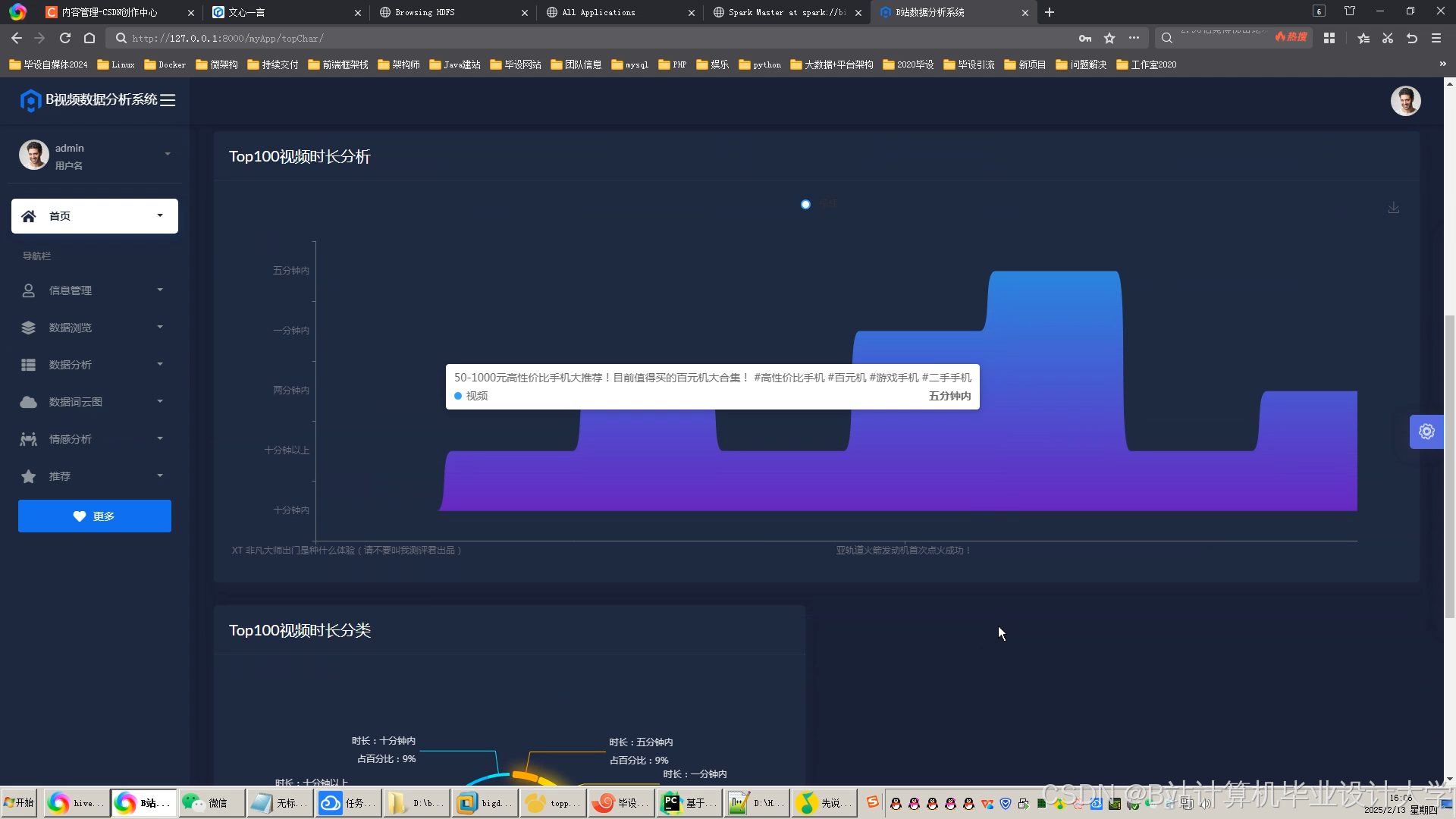
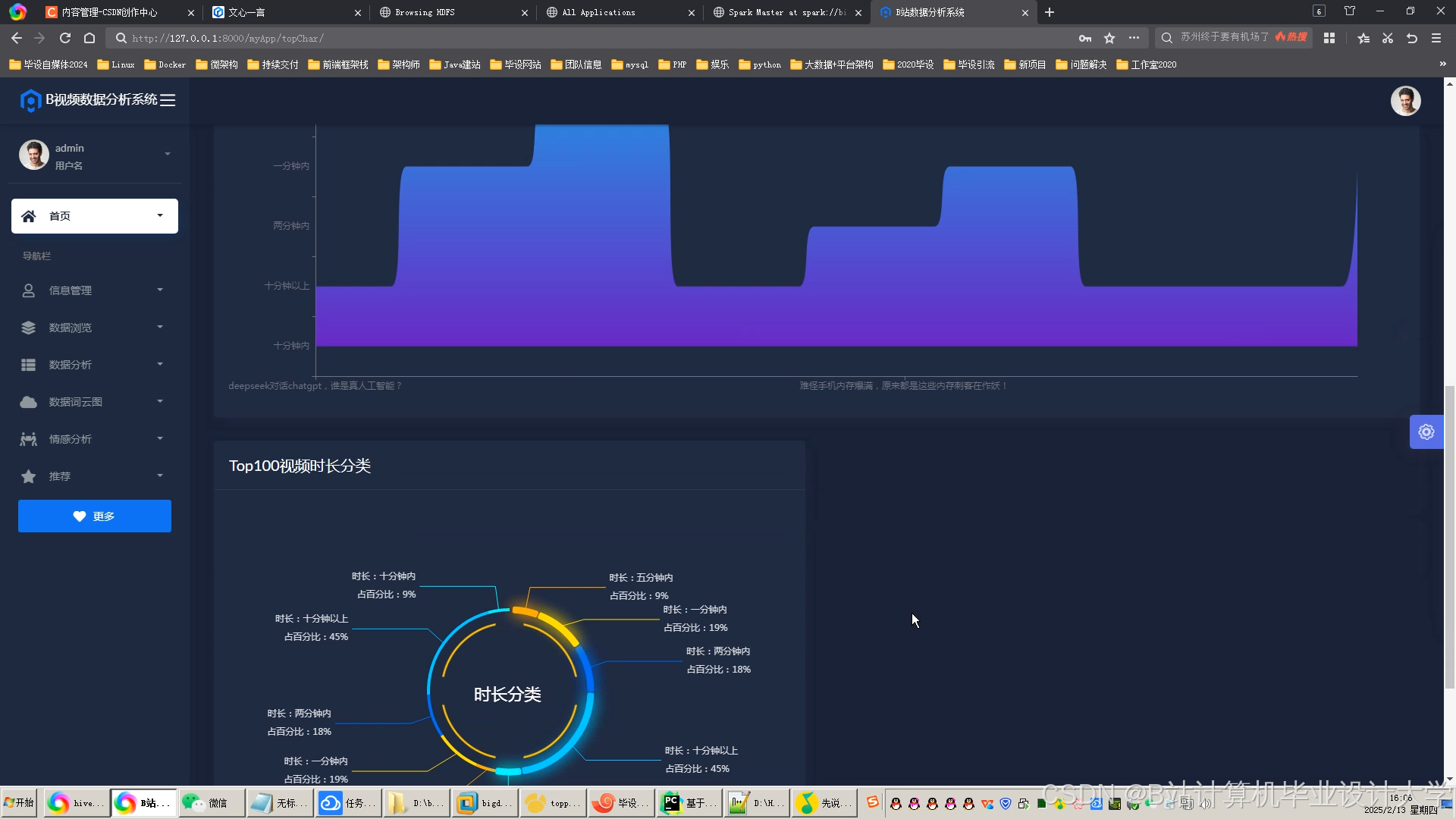
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











