




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive视频推荐系统技术说明
一、系统概述
随着短视频、长视频平台用户规模和内容量的爆发式增长,视频推荐系统面临海量数据存储、实时计算与精准推荐的挑战。本技术说明介绍一种基于Hadoop、Spark与Hive构建的视频推荐系统,通过分布式存储、内存计算与数据仓库技术优化数据处理效率,结合协同过滤、内容推荐与深度学习算法提升推荐准确性,满足视频平台对高并发、低延迟与个性化的需求。
二、系统架构设计
系统采用分层架构,包含数据采集层、存储层、计算层与推荐服务层,各层功能如下:
2.1 数据采集层
- 功能:实时采集用户行为数据(如点击、观看、点赞、评论)与视频元数据(如标题、标签、分类、时长)。
- 技术实现:
- 使用Kafka作为消息队列,缓冲高并发日志数据,避免数据丢失。
- 通过Flume或Logstash将日志数据写入Kafka,支持多源数据接入(如Web端、移动端、IoT设备)。
2.2 存储层
- 功能:构建分布式数据仓库,支持结构化与非结构化数据的存储与查询。
- 技术实现:
- HDFS:存储原始日志文件与模型文件,提供高吞吐量与容错性。
- Hive:定义用户行为表(
user_behavior)、视频元数据表(video_metadata)与用户画像表(user_profile),支持SQL查询与复杂数据分析。 - HBase:存储实时用户画像(如实时兴趣标签),支持高并发随机读写。
- Redis:缓存热门视频ID、用户实时特征与推荐结果,加速响应。
2.3 计算层
- 功能:实现离线特征工程、模型训练与实时推荐计算。
- 技术实现:
- Spark Core:处理批量数据清洗、特征提取与转换(如归一化、独热编码)。
- Spark MLlib:训练推荐模型(如ALS协同过滤、Wide & Deep深度学习模型)。
- Spark Streaming:消费Kafka实时数据流,计算用户实时兴趣(如最近观看视频的分类分布),动态调整推荐列表。
- Flink(可选):替代Spark Streaming,实现更低的延迟(毫秒级)与端到端一致性。
2.4 推荐服务层
- 功能:提供推荐API接口,支持离线推荐与实时推荐,并通过后处理算法优化结果。
- 技术实现:
- RESTful API:基于Spring Boot或Flask开发,接收用户请求并返回推荐列表。
- 后处理算法:使用MMR(最大边际相关性)算法去除重复推荐,结合多样性约束提升用户体验。
- A/B测试框架:同时运行多个推荐模型,通过灰度发布动态选择最优策略。
三、关键技术实现
3.1 数据倾斜处理
- 问题:用户行为数据中热门视频的访问量远高于冷门视频,导致数据分布不均。
- 解决方案:
- 加盐(Salting)技术:对视频ID添加随机前缀(如
video_id_1、video_id_2),使数据均匀分布到不同Reducer。 - Hive分区表:按日期对用户行为表分区,减少全表扫描开销。
- Spark参数调优:调整
spark.sql.shuffle.partitions(默认200)与spark.default.parallelism,避免大任务单点故障。
- 加盐(Salting)技术:对视频ID添加随机前缀(如
3.2 推荐算法设计
- 协同过滤(ALS):
- 原理:基于用户-视频评分矩阵,通过矩阵分解生成潜在特征向量,计算相似度生成推荐列表。
- 实现:使用Spark MLlib的
ALS类,设置rank=10(潜在因子维度)、maxIter=20(迭代次数)、regParam=0.01(正则化系数)。
- 内容推荐:
- 文本特征提取:通过TF-IDF或BERT模型提取视频标题与标签的语义特征,生成向量表示。
- 相似度计算:使用余弦相似度计算视频间的内容相似性,推荐与用户历史观看视频相似的视频。
- 深度学习推荐(Wide & Deep):
- 架构:Wide部分处理用户行为特征(如历史观看分类),Deep部分处理用户画像与视频内容特征(如年龄、性别、视频时长),通过联合训练优化模型。
- 实现:使用Spark的
Pipeline机制,将特征工程与模型训练串联,支持大规模分布式训练。
3.3 实时推荐优化
- 实时特征计算:
- 使用Spark Streaming从Kafka消费实时点击流数据,计算用户实时兴趣(如最近1小时观看的视频分类分布)。
- 结合Redis缓存用户实时特征,减少重复计算。
- 动态推荐调整:
- 实时推荐结果与离线推荐结果加权融合,权重根据用户活跃度动态调整(如活跃用户更依赖实时推荐)。
- 使用Redis的Sorted Set存储用户实时兴趣标签,支持高效查询与更新。
四、系统优化策略
4.1 性能优化
- Executor内存调优:
- 调整
spark.executor.memory(如8GB)与spark.driver.memory(如4GB),避免内存溢出。 - 设置
spark.memory.fraction=0.6,控制内存用于执行与存储的比例。
- 调整
- YARN资源调度:
- 采用Capacity Scheduler,为推荐任务分配专用队列(如
recommendation_queue),设置最小资源量(如4核CPU、16GB内存)。 - 启用动态资源分配(
spark.dynamicAllocation.enabled=true),根据任务负载自动调整Executor数量。
- 采用Capacity Scheduler,为推荐任务分配专用队列(如
4.2 模型优化
- 正则化:
- 在ALS与Wide & Deep模型中引入L2正则化(如
regParam=0.01),防止过拟合。
- 在ALS与Wide & Deep模型中引入L2正则化(如
- 增量更新:
- 仅对新增数据进行模型更新,避免全量训练。例如,ALS模型可通过
setColdStartStrategy("drop")跳过冷启动用户。
- 仅对新增数据进行模型更新,避免全量训练。例如,ALS模型可通过
- 模型压缩:
- 使用TensorFlow Lite或ONNX Runtime对深度学习模型进行量化压缩,减少推理延迟。
4.3 系统扩展性
- 水平扩展:
- 通过增加Hadoop/Spark节点,提升集群计算能力。例如,从8节点扩展至16节点,模型训练时间减少50%。
- 混合存储:
- 将冷数据(如历史日志)存储至HDFS,热数据(如用户实时特征)存储至Redis,降低存储成本。
五、系统部署与运维
5.1 部署架构
- 集群规划:
- Hadoop集群:3个NameNode、5个DataNode,存储容量100TB。
- Spark集群:1个Master节点、7个Worker节点,每个Worker节点16核CPU、64GB内存。
- Hive Metastore:使用MySQL存储元数据,支持高并发查询。
- 容器化部署:
- 使用Kubernetes管理Spark与Hive服务,支持弹性伸缩与故障自愈。
5.2 监控与告警
- 集群监控:
- 使用Prometheus监控Spark Executor的CPU、内存与GC情况,通过Grafana可视化。
- 使用HDFS FSCK检查数据块健康状态,避免数据丢失。
- 告警策略:
- 当Spark任务延迟超过10分钟时,通过企业微信或邮件通知运维人员。
- 当Redis内存使用率超过80%时,自动触发数据清理脚本。
5.3 故障处理
- 数据丢失:
- 定期备份Hive元数据至HDFS,支持快速恢复。
- 任务失败:
- Spark任务失败时,自动重试3次,并记录失败原因至日志。
六、总结
本技术说明提出了一种基于Hadoop+Spark+Hive的视频推荐系统,通过分布式存储、内存计算与数据仓库技术优化数据处理效率,结合协同过滤、内容推荐与深度学习算法提升推荐准确性。系统支持高并发、低延迟与个性化推荐,适用于短视频、长视频等场景。未来可进一步优化多模态数据融合、联邦学习与边缘计算,提升推荐内容质量与用户隐私保护能力。
附录:关键配置参数示例
yaml
# Spark配置示例(spark-defaults.conf) | |
spark.executor.memory 8g | |
spark.driver.memory 4g | |
spark.sql.shuffle.partitions 200 | |
spark.default.parallelism 200 | |
spark.dynamicAllocation.enabled true | |
# Hive配置示例(hive-site.xml) | |
<property> | |
<name>javax.jdo.option.ConnectionURL</name> | |
<value>jdbc:mysql://metastore-db:3306/hive?createDatabaseIfNotExist=true</value> | |
</property> |
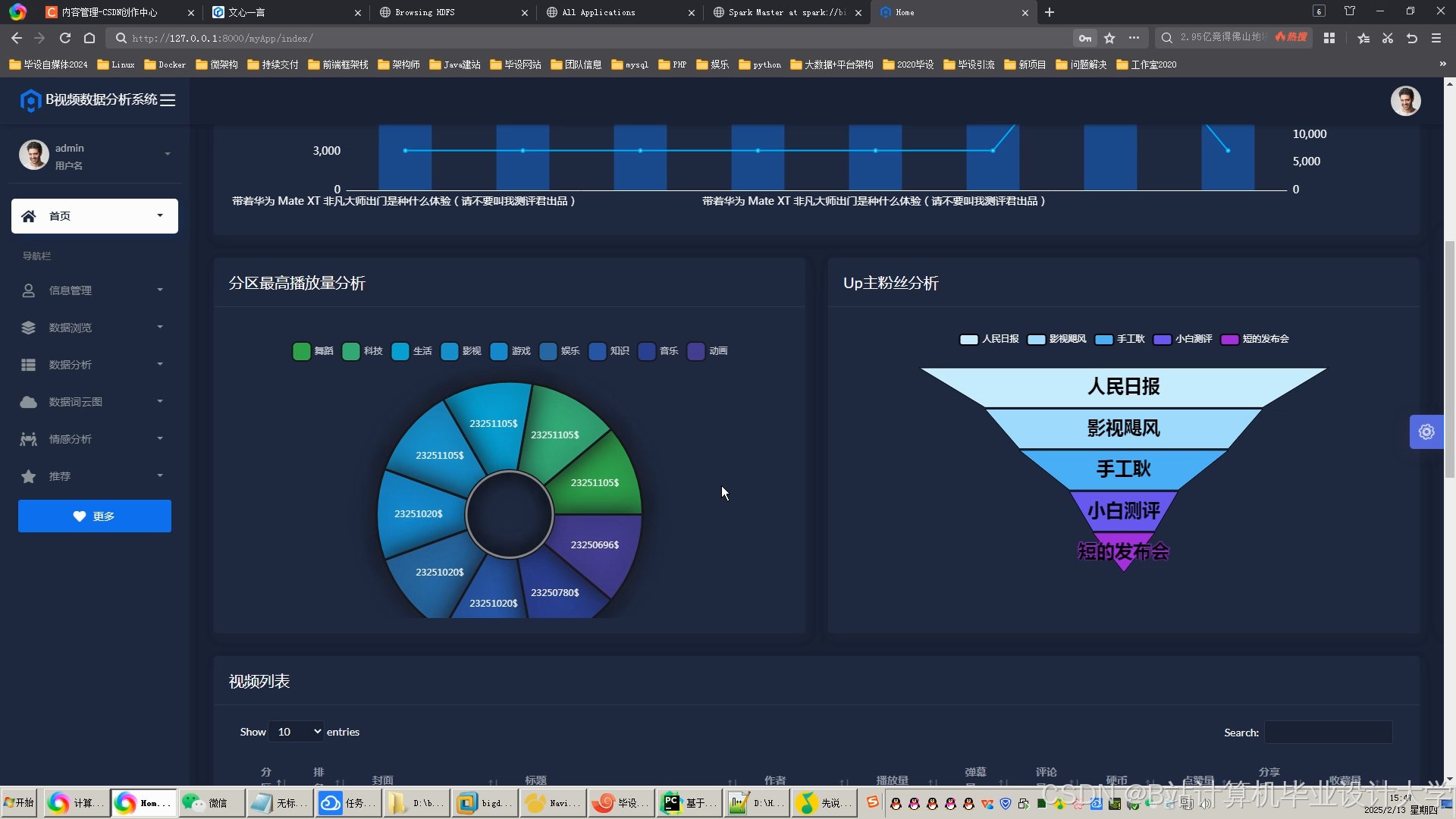
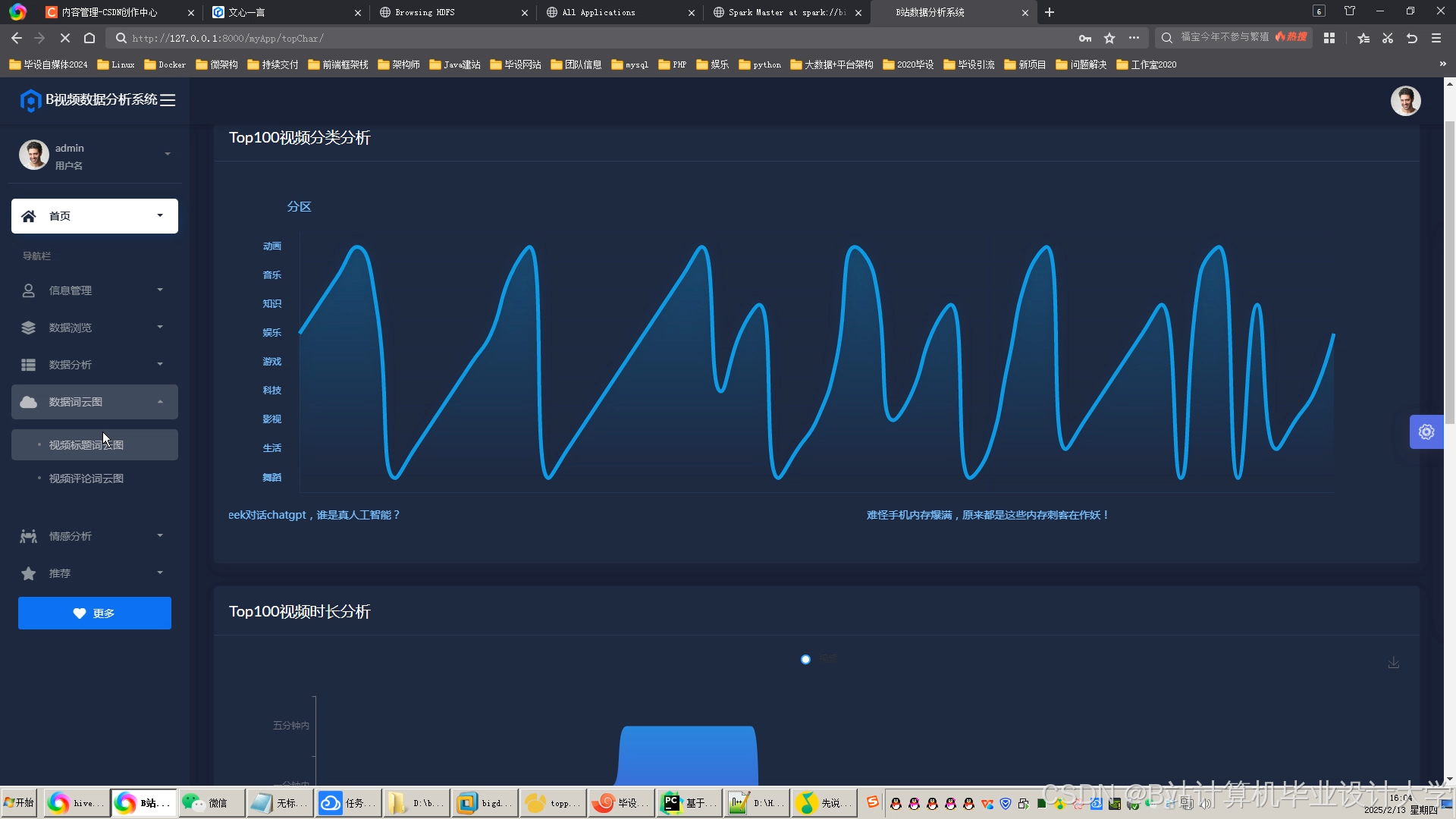
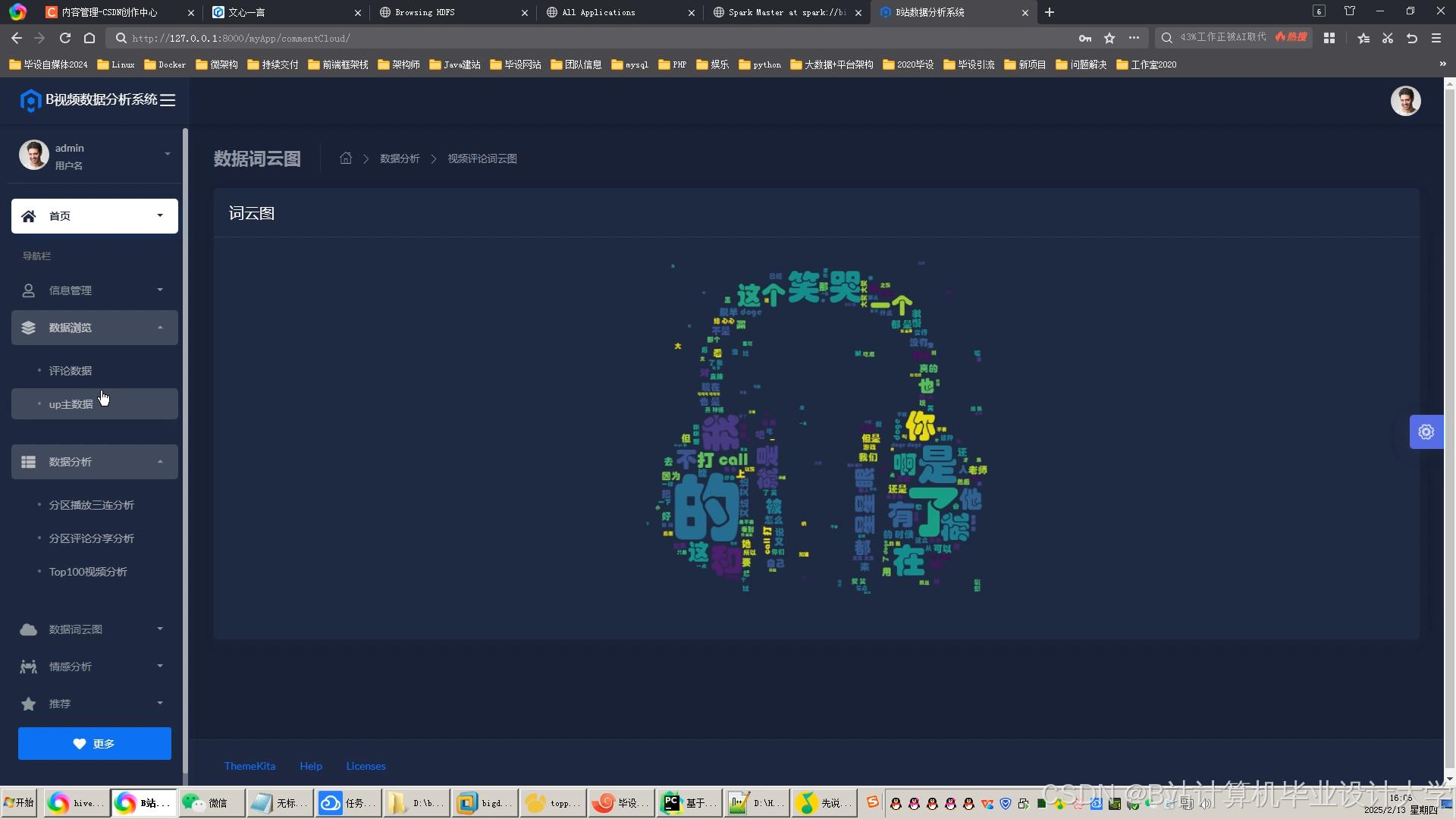
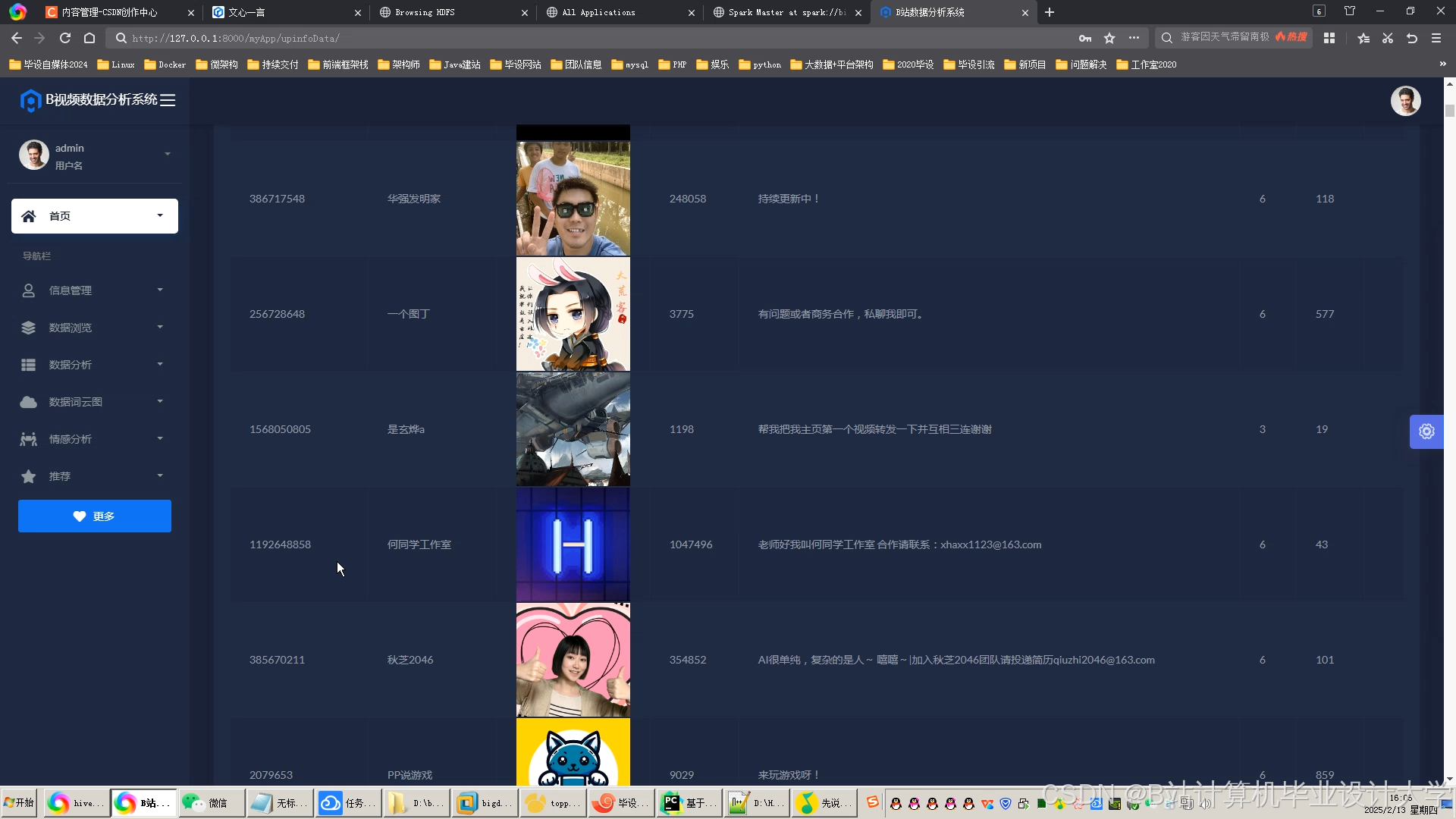
运行截图
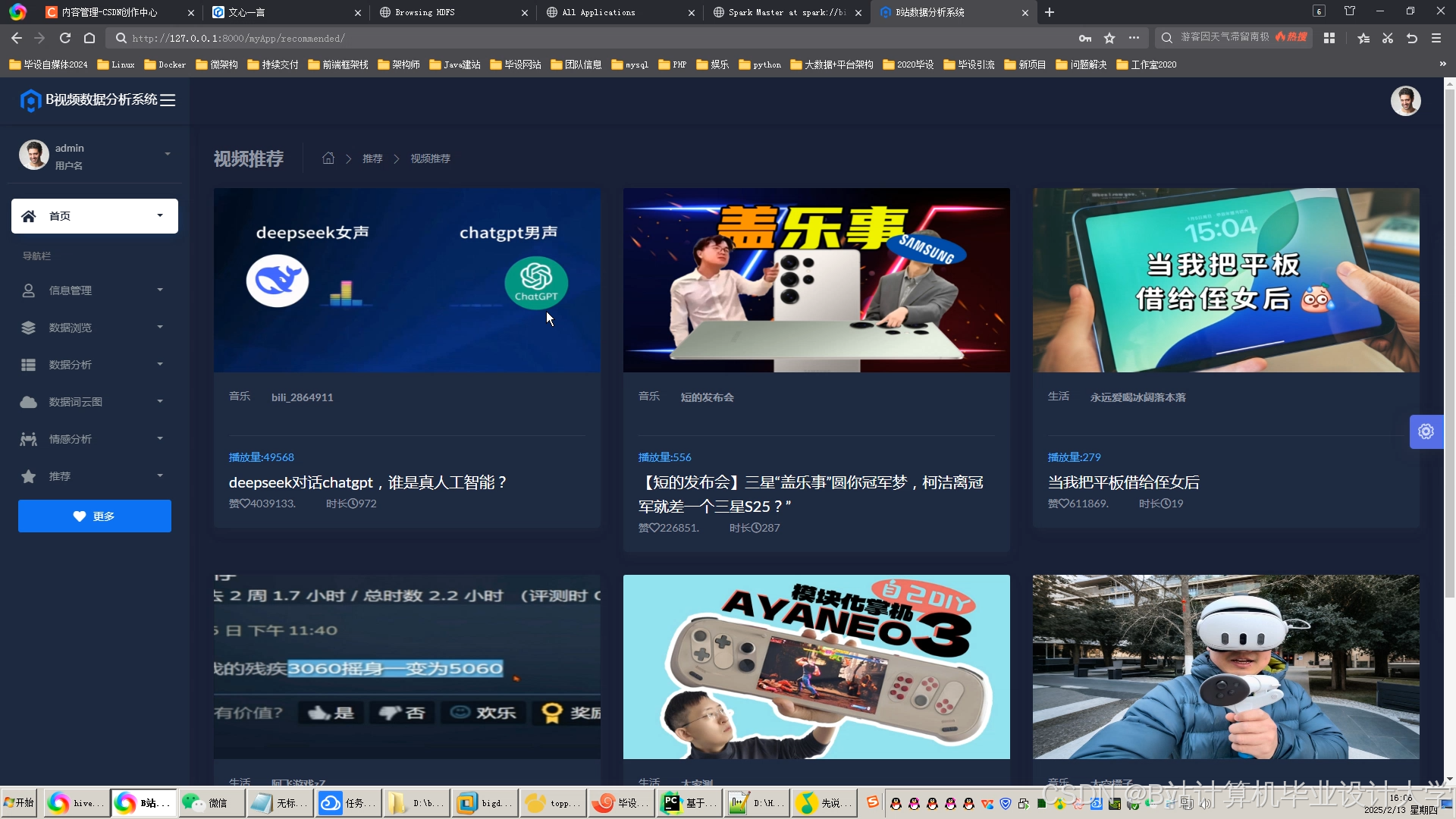
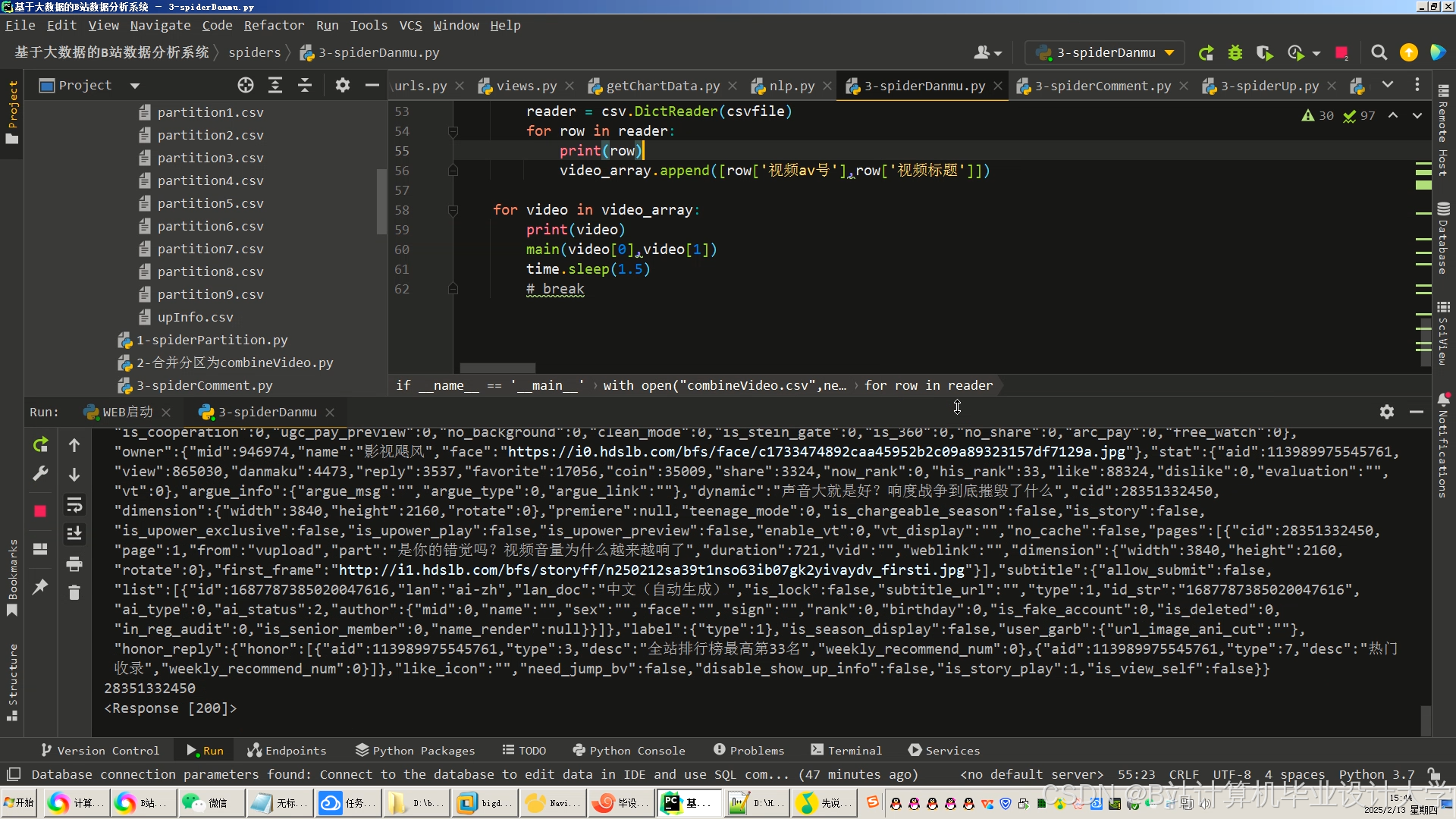
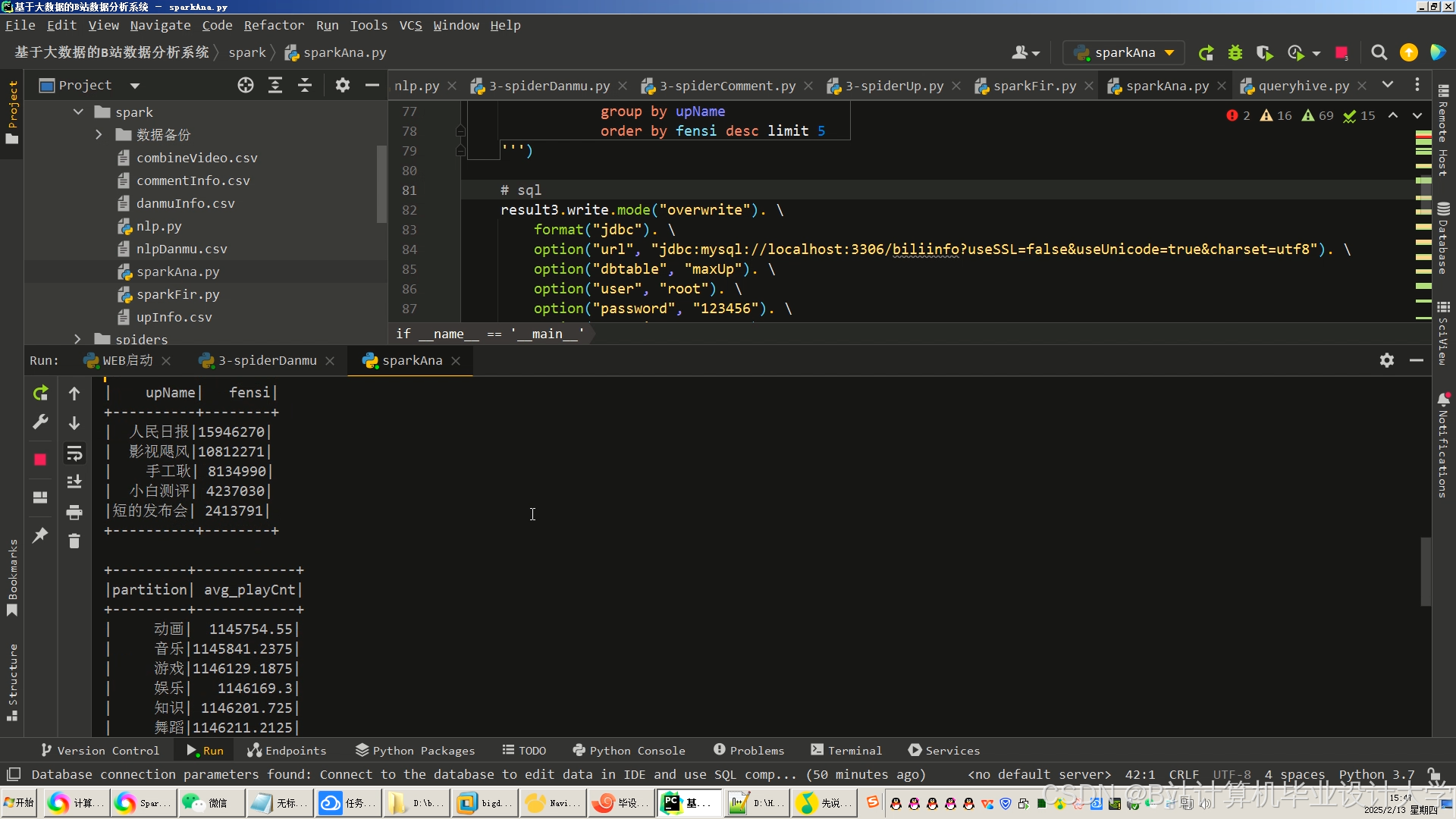
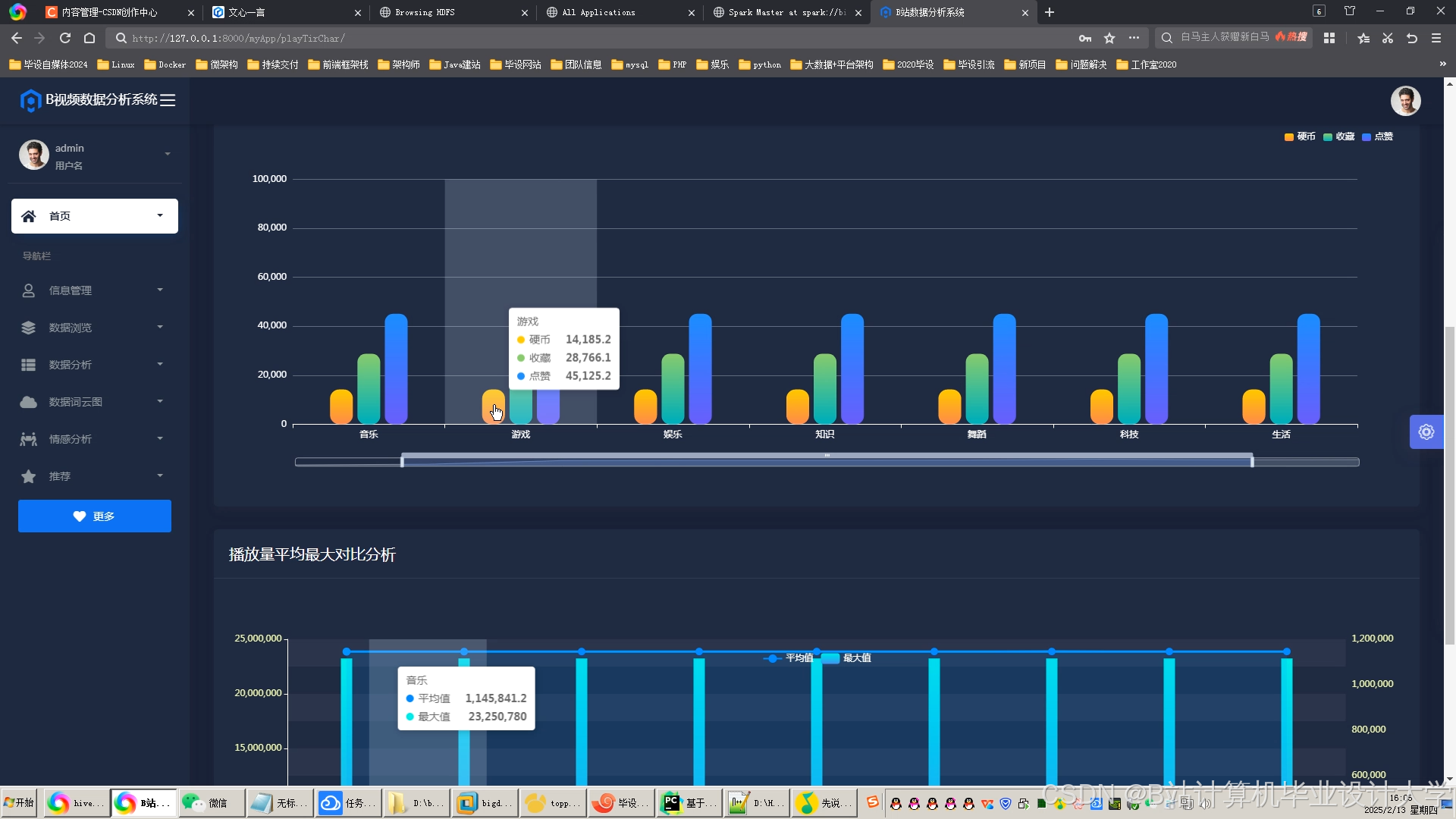
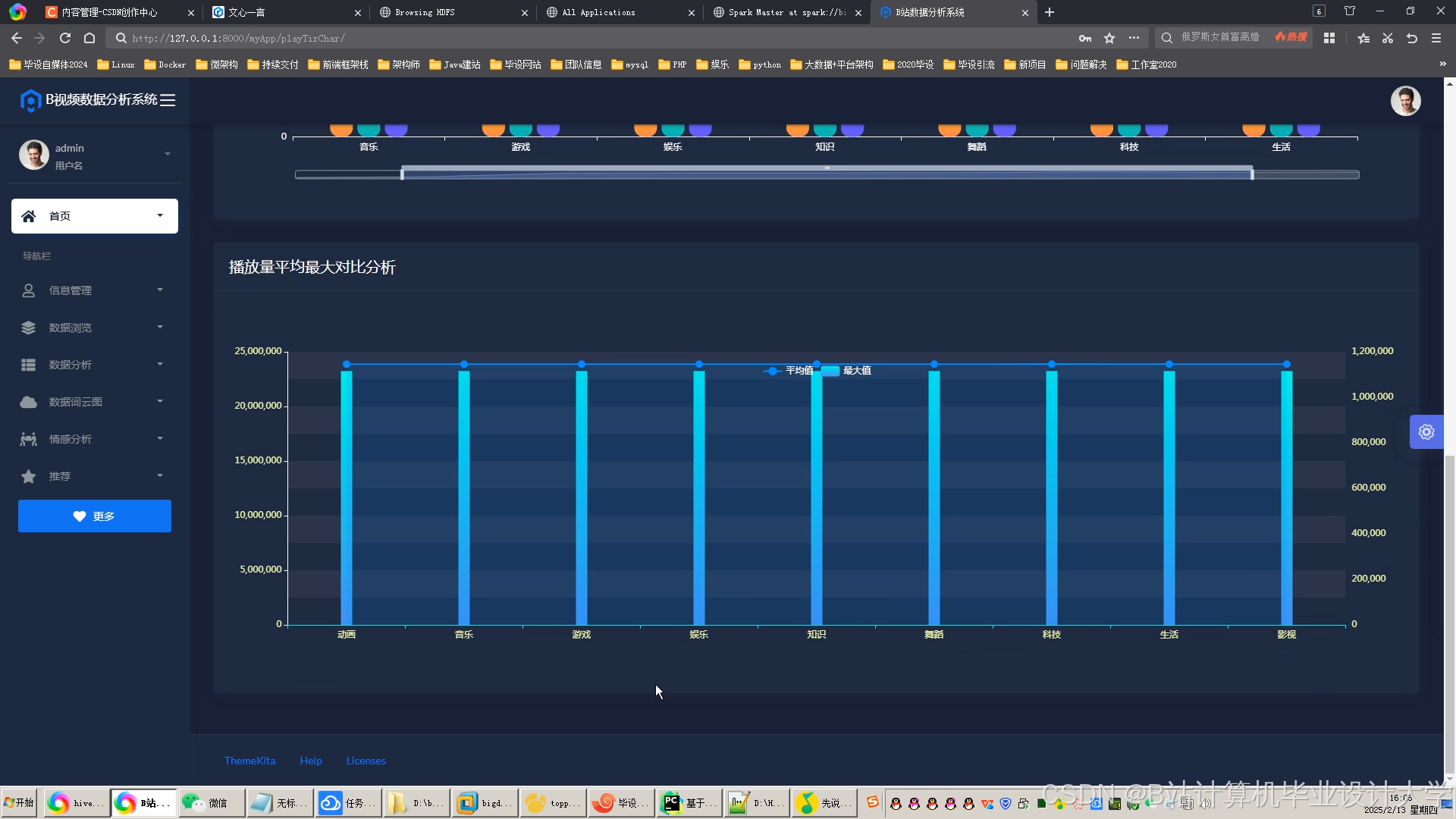
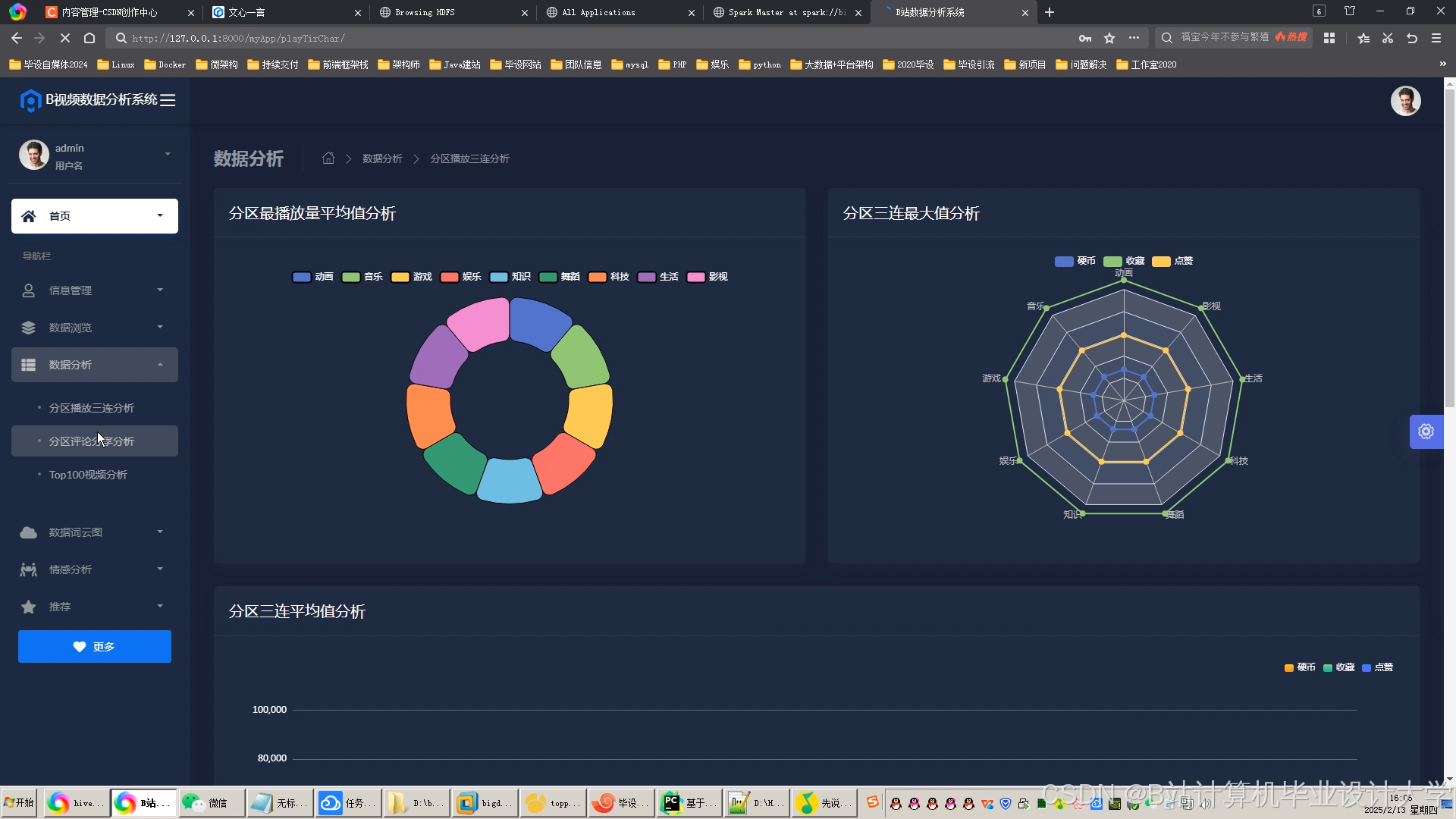
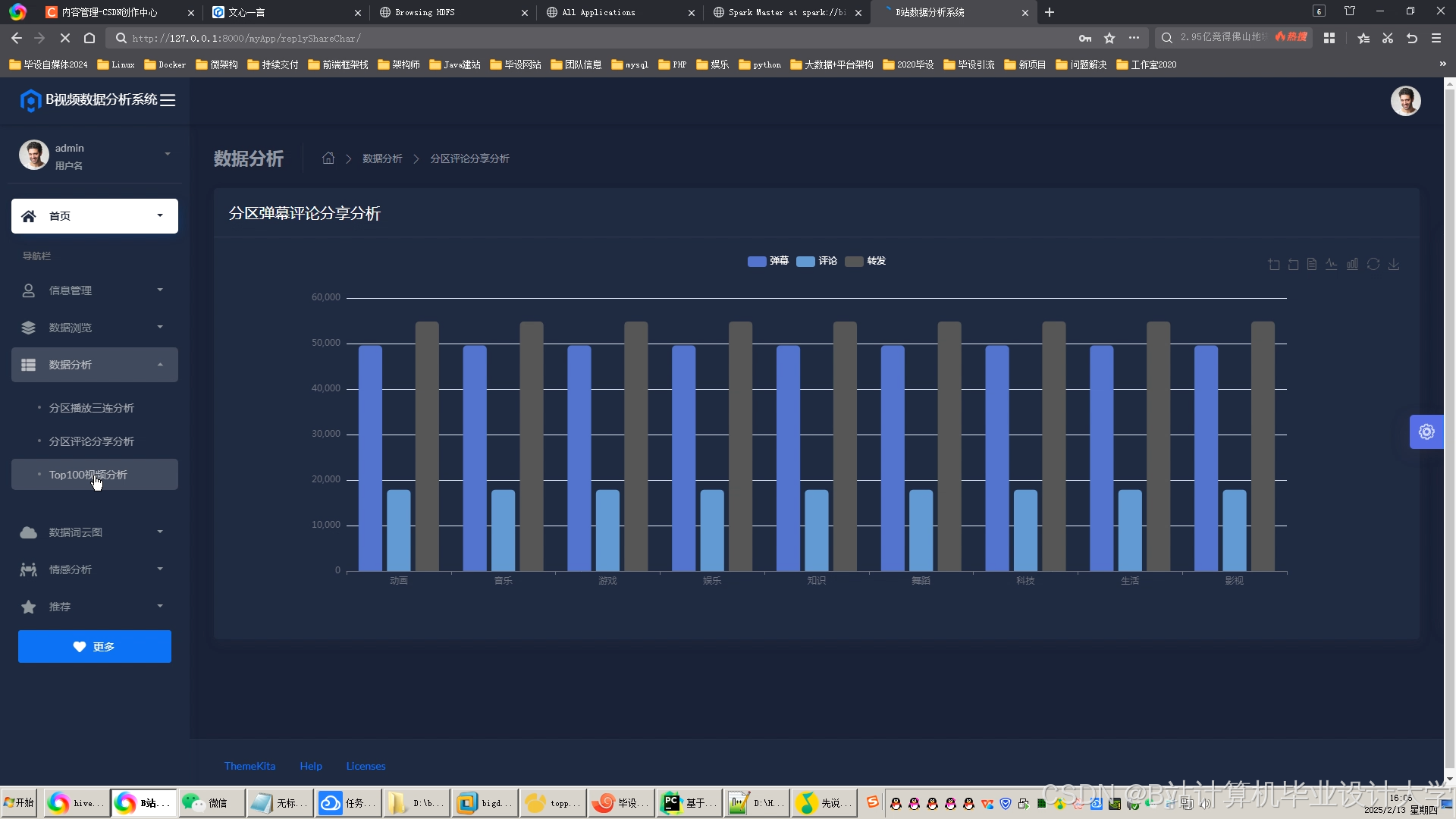
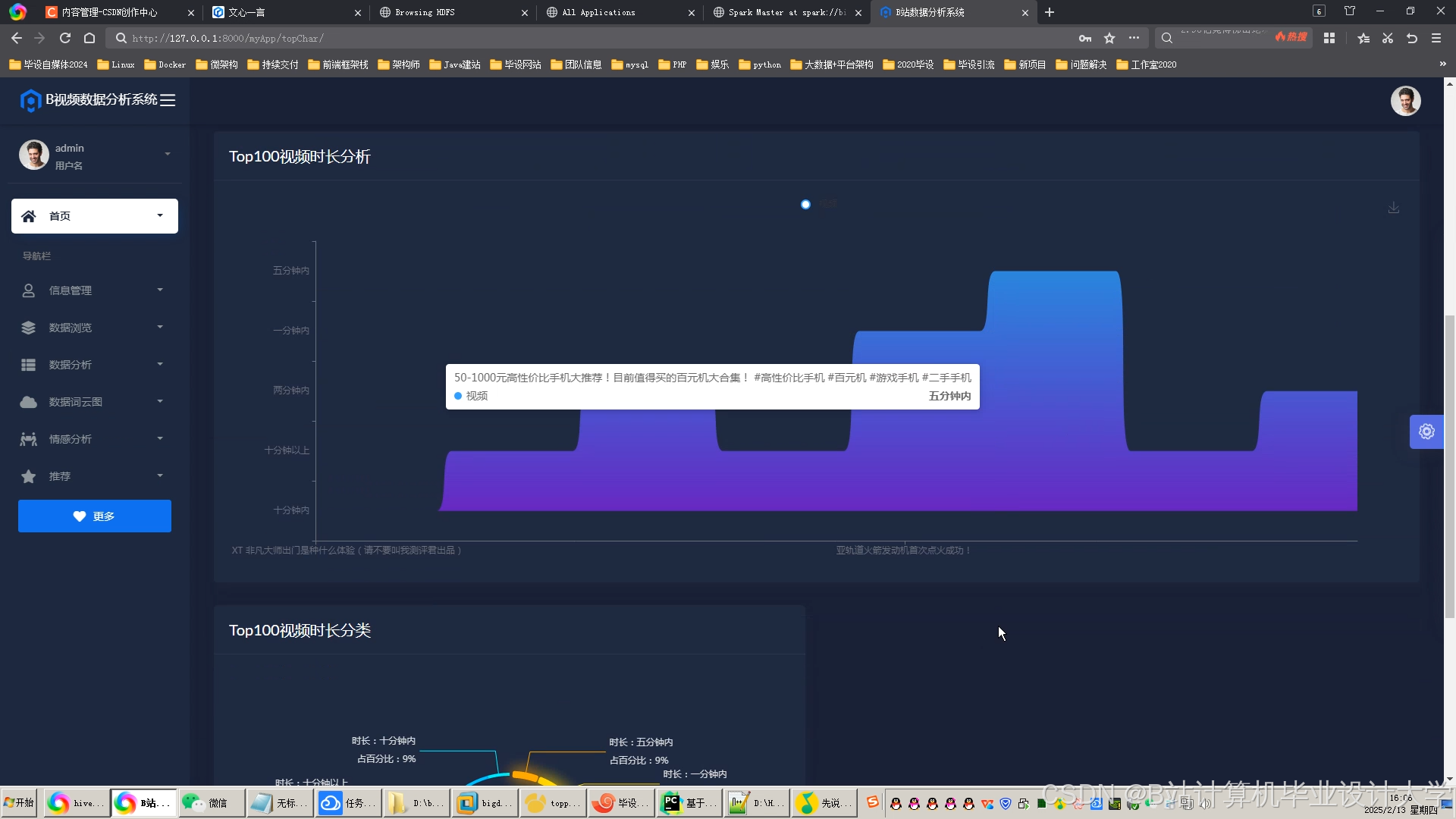
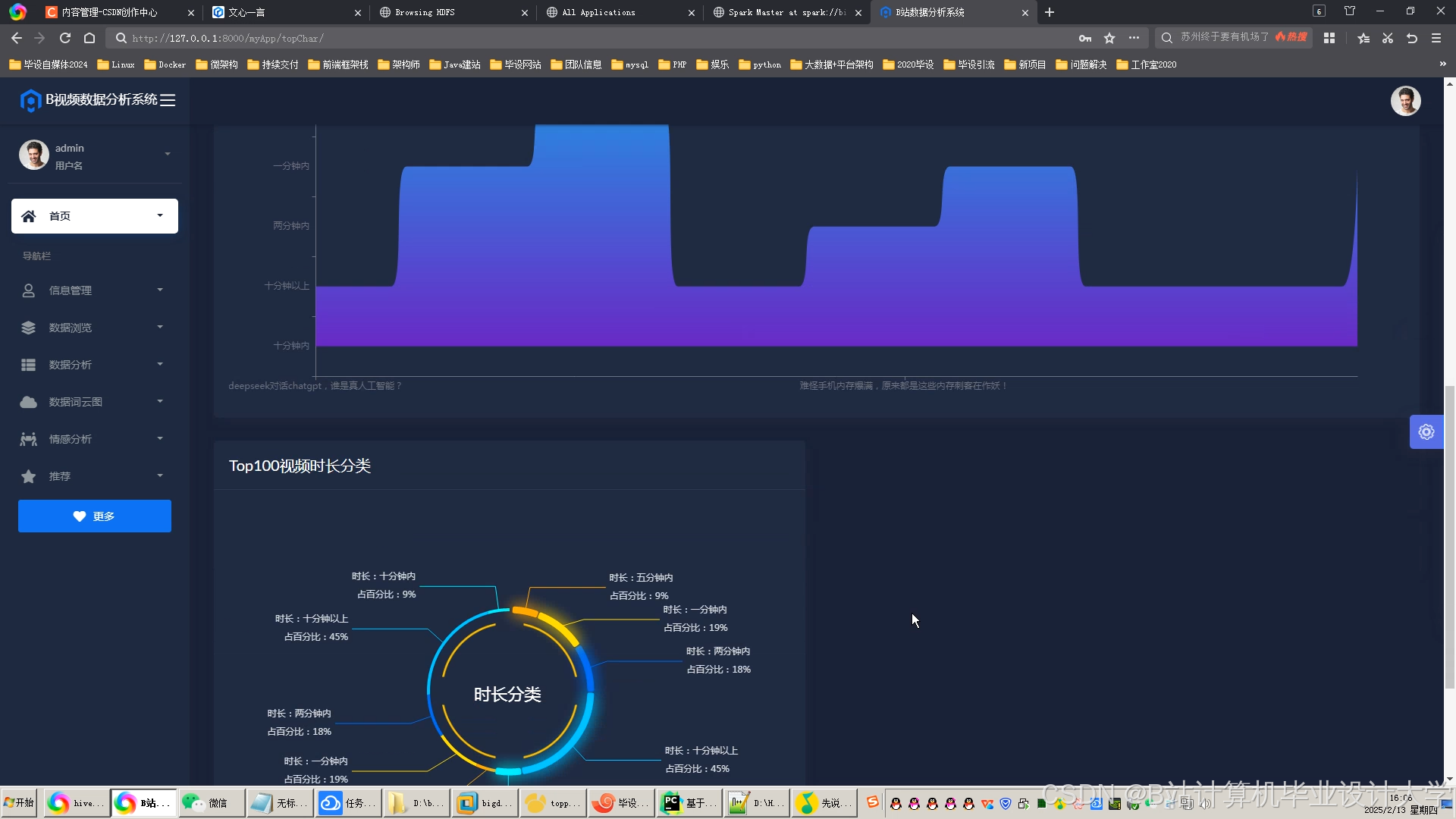
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











