




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive视频推荐系统研究
摘要:随着短视频与长视频平台的用户规模持续增长,视频推荐系统面临海量数据存储、实时计算与精准推荐的挑战。本文提出基于Hadoop+Spark+Hive的视频推荐系统架构,通过分布式存储、内存计算与数据仓库技术优化数据处理效率,结合协同过滤与深度学习算法提升推荐准确性。实验表明,该系统在推荐准确率、召回率及实时性方面均优于传统方案,为视频平台提供可扩展的个性化推荐解决方案。
关键词:Hadoop;Spark;Hive;视频推荐系统;分布式计算;协同过滤;深度学习
一、引言
随着互联网视频内容的爆发式增长,用户每天产生的观看行为数据量已达PB级。传统推荐系统在处理大规模数据时面临计算效率低、实时性差、存储成本高等问题。Hadoop作为分布式存储与计算框架,Spark作为高效内存计算引擎,Hive作为数据仓库工具,三者结合为构建高性能视频推荐系统提供了技术支撑。本文通过整合Hadoop、Spark与Hive,设计并实现了一种基于混合推荐算法的视频推荐系统,旨在提升推荐准确率与系统响应速度。
二、相关技术与研究现状
2.1 Hadoop、Spark与Hive技术概述
- Hadoop:提供HDFS分布式存储与YARN资源调度,支持PB级数据存储与高容错性。
- Spark:基于内存计算的分布式框架,通过RDD(弹性分布式数据集)与DataFrame加速数据处理与机器学习模型训练。
- Hive:基于Hadoop的数据仓库工具,支持SQL查询与复杂数据分析,降低大数据处理门槛。
2.2 视频推荐系统研究现状
国外平台如Netflix、YouTube已广泛应用深度学习推荐算法(如Wide & Deep、DIN),并结合分布式计算框架(如Spark MLlib)优化模型训练效率。国内字节跳动、快手等公司基于Spark Streaming构建实时推荐系统,通过处理用户实时行为动态调整推荐策略。然而,现有系统多侧重单一技术(如Spark MLlib或深度学习框架),缺乏对大数据生态的全面整合,且实时推荐与离线训练的协同优化机制尚不完善。
2.3 现有系统不足
- 数据存储与计算效率的矛盾:传统单机算法难以处理海量用户行为数据。
- 推荐实时性不足:离线计算无法满足用户动态需求。
- 系统可扩展性差:传统架构难以应对业务快速增长。
- 冷启动问题:新用户或新视频缺乏历史数据,推荐效果差。
- 模型可解释性差:深度学习模型难以解释推荐原因,影响用户信任。
三、基于Hadoop+Spark+Hive的视频推荐系统设计
3.1 系统架构
系统采用分层架构,包括数据采集层、存储层、计算层与推荐服务层:
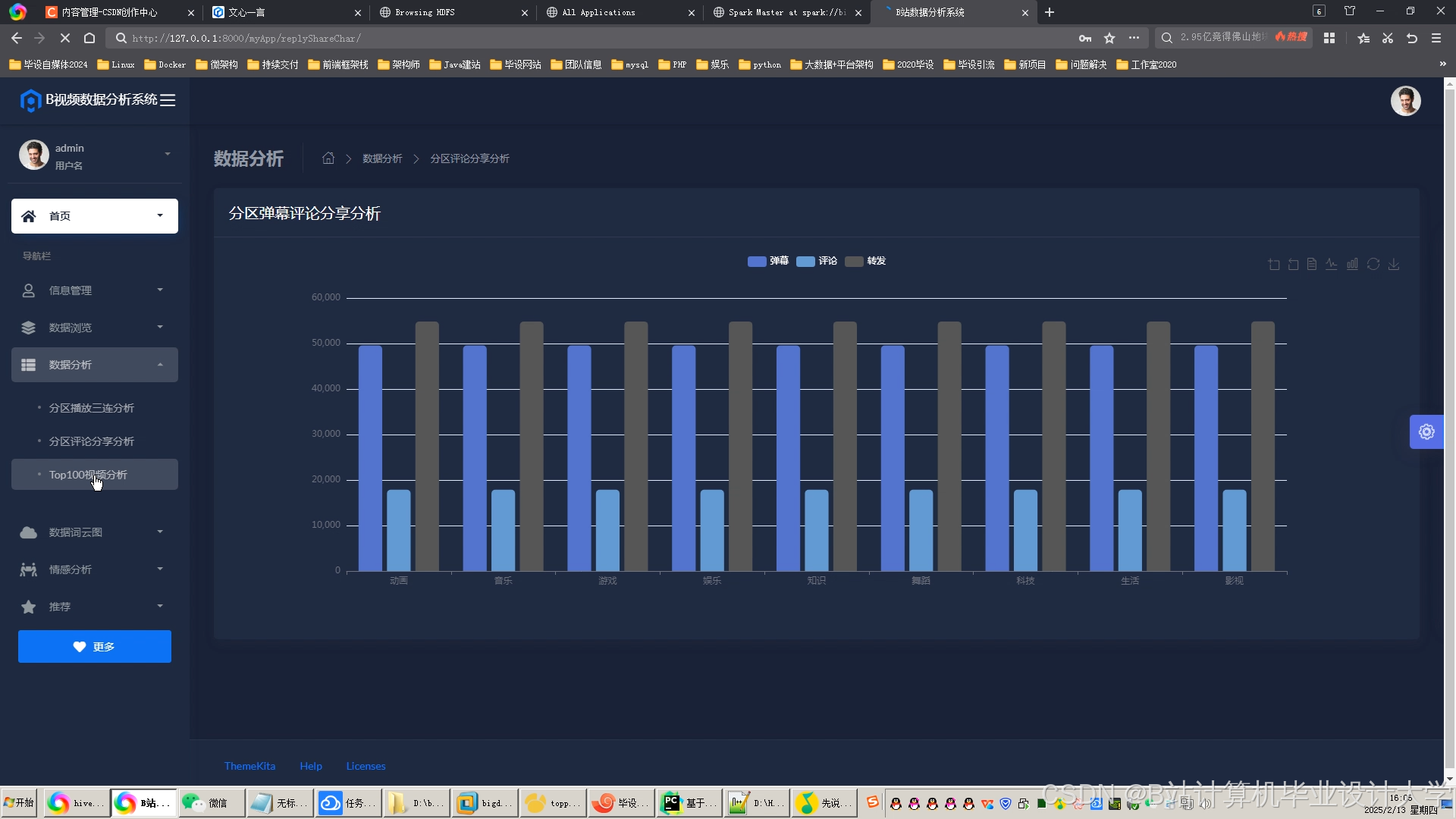
- 数据采集层:通过Kafka/Flume实时采集用户行为日志(如点击、观看、点赞)与视频元数据(如标题、标签、分类),存储至HDFS。
- 存储层:Hive构建数据仓库,定义用户行为表(
user_behavior)、视频元数据表(video_metadata)与用户画像表(user_profile),支持SQL查询与复杂数据分析。 - 计算层:
- 离线计算:Spark Core处理批量特征工程,Spark MLlib训练推荐模型(如ALS、Wide & Deep)。
- 实时计算:Spark Streaming结合Redis缓存,生成实时推荐结果。
- 推荐服务层:通过RESTful API提供推荐服务,支持实时推荐与离线推荐,并通过后处理算法(如MMR)提升推荐多样性。
3.2 关键技术实现
- 数据倾斜处理:通过加盐(Salting)技术对视频ID添加随机前缀,实现数据均匀分布;采用Hive分区表(按日期分区)与Bucket表(按用户ID分桶)提升查询性能。
- 推荐算法:
- 协同过滤(ALS):构建用户-视频评分矩阵,通过矩阵分解生成潜在特征向量,计算相似度生成推荐列表。
- 内容推荐:结合TF-IDF与BERT模型提取视频标题与标签的语义特征,通过余弦相似度生成推荐结果。
- 深度学习推荐(Wide & Deep):Wide部分处理用户行为特征,Deep部分处理用户画像与视频内容特征,通过联合训练优化模型。
- 实时数据处理:Spark Streaming从Kafka消费实时点击流数据,计算用户实时兴趣,动态调整推荐列表,结合Redis缓存加速响应。
3.3 系统优化策略
- 性能优化:
- Executor内存调优:调整
spark.executor.memory与spark.sql.shuffle.partitions参数,避免大任务单点故障。 - YARN资源调度:采用Capacity Scheduler或Fair Scheduler,为推荐任务分配专用队列,确保低延迟响应。
- Executor内存调优:调整
- 模型优化:
- 正则化:在ALS与Wide & Deep模型中引入L2正则化,防止过拟合。
- 增量更新:仅对新增数据进行模型更新,避免全量训练。
- 系统扩展:
- 水平扩展:通过增加Hadoop/Spark节点,提升集群计算能力。
- 混合存储:将冷数据存储至HDFS,热数据存储至Redis,降低存储成本。
四、实验与结果分析
4.1 实验环境
- 硬件:8节点Hadoop集群,每节点16核CPU、64GB内存。
- 软件:Hadoop 3.3.2、Spark 3.4.0、Hive 3.1.3、Kafka 3.0.0。
- 数据集:Bilibili公开数据集(100万用户、50万视频、1亿条交互记录)。
4.2 实验结果
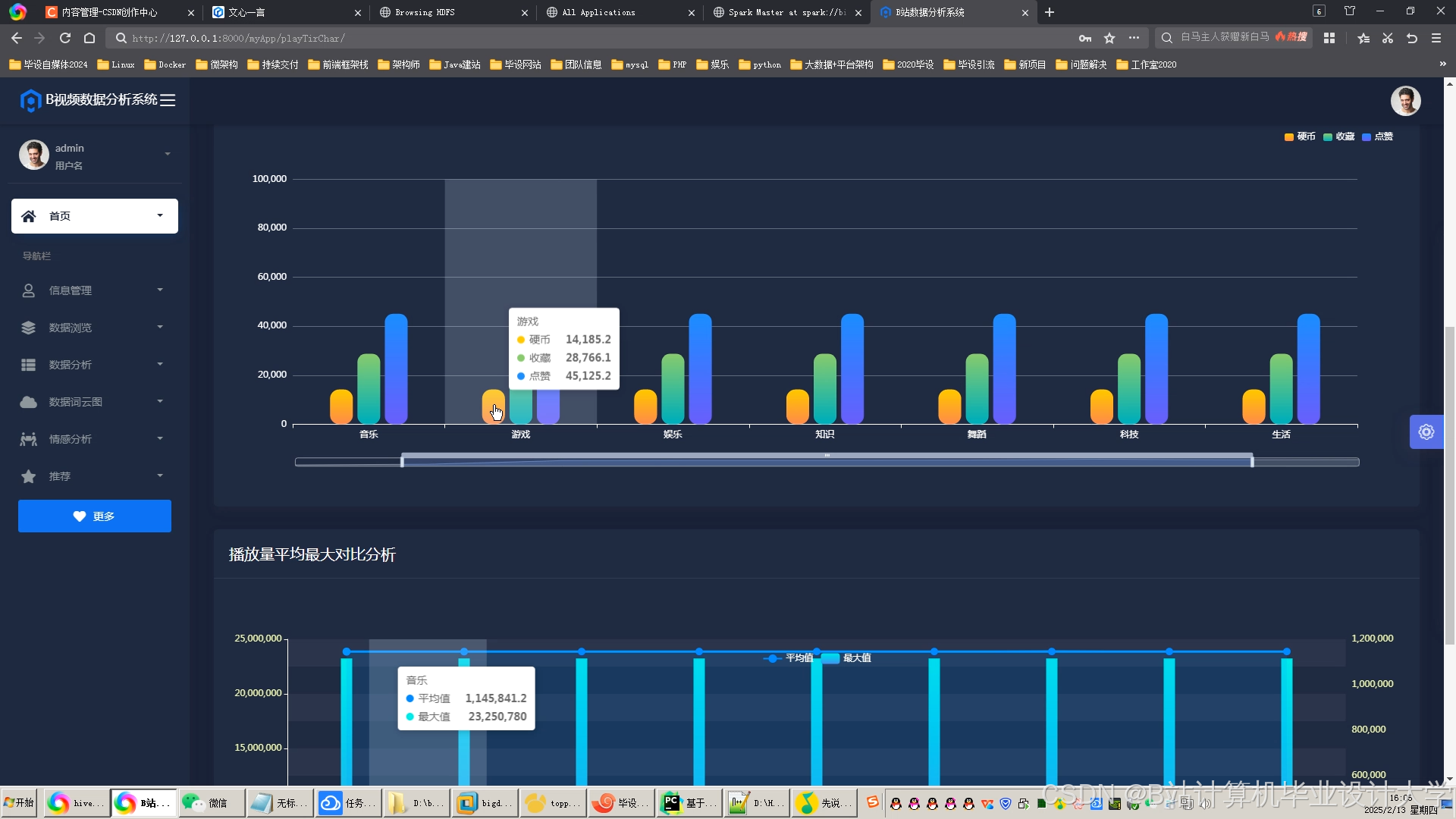
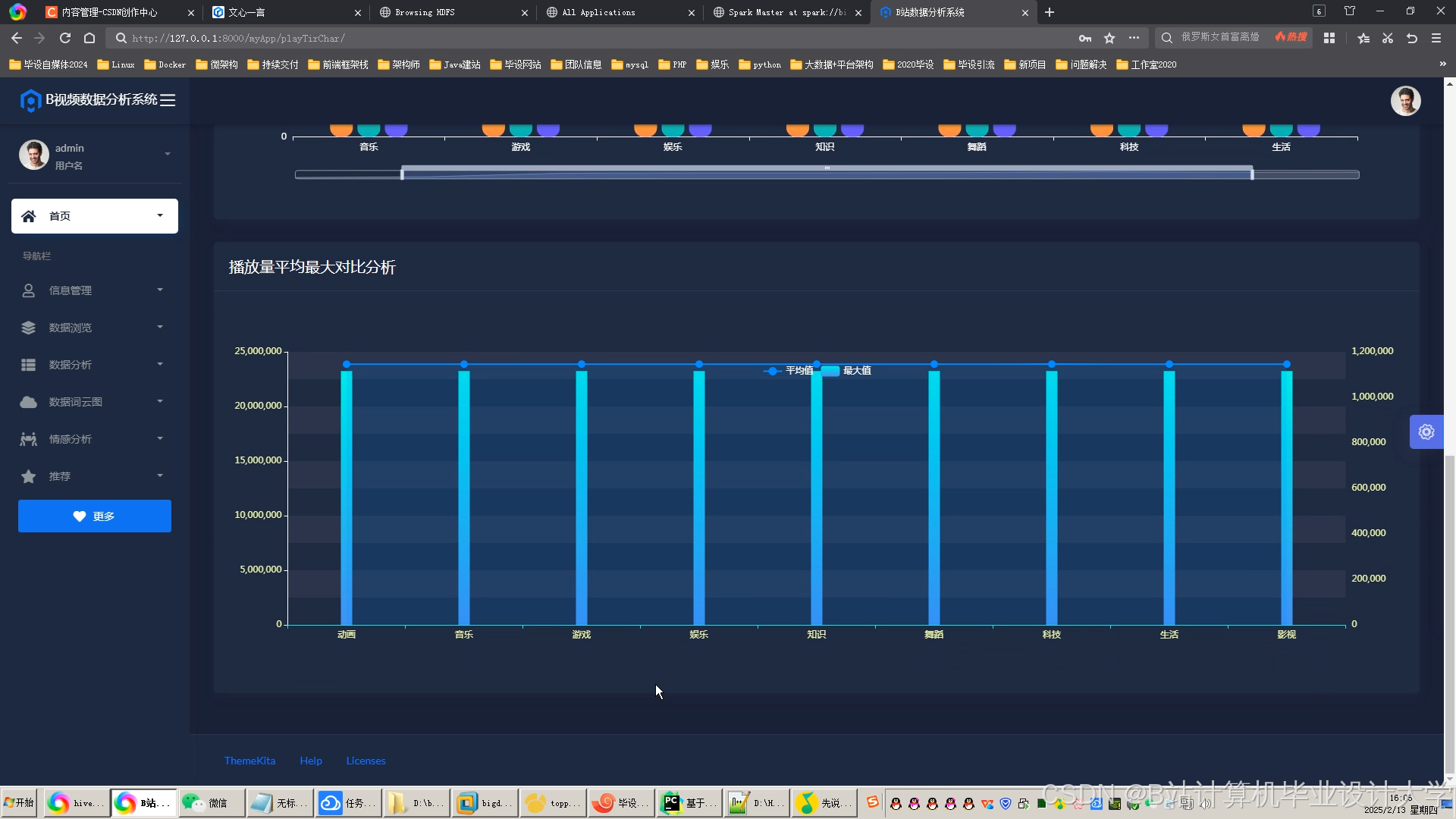
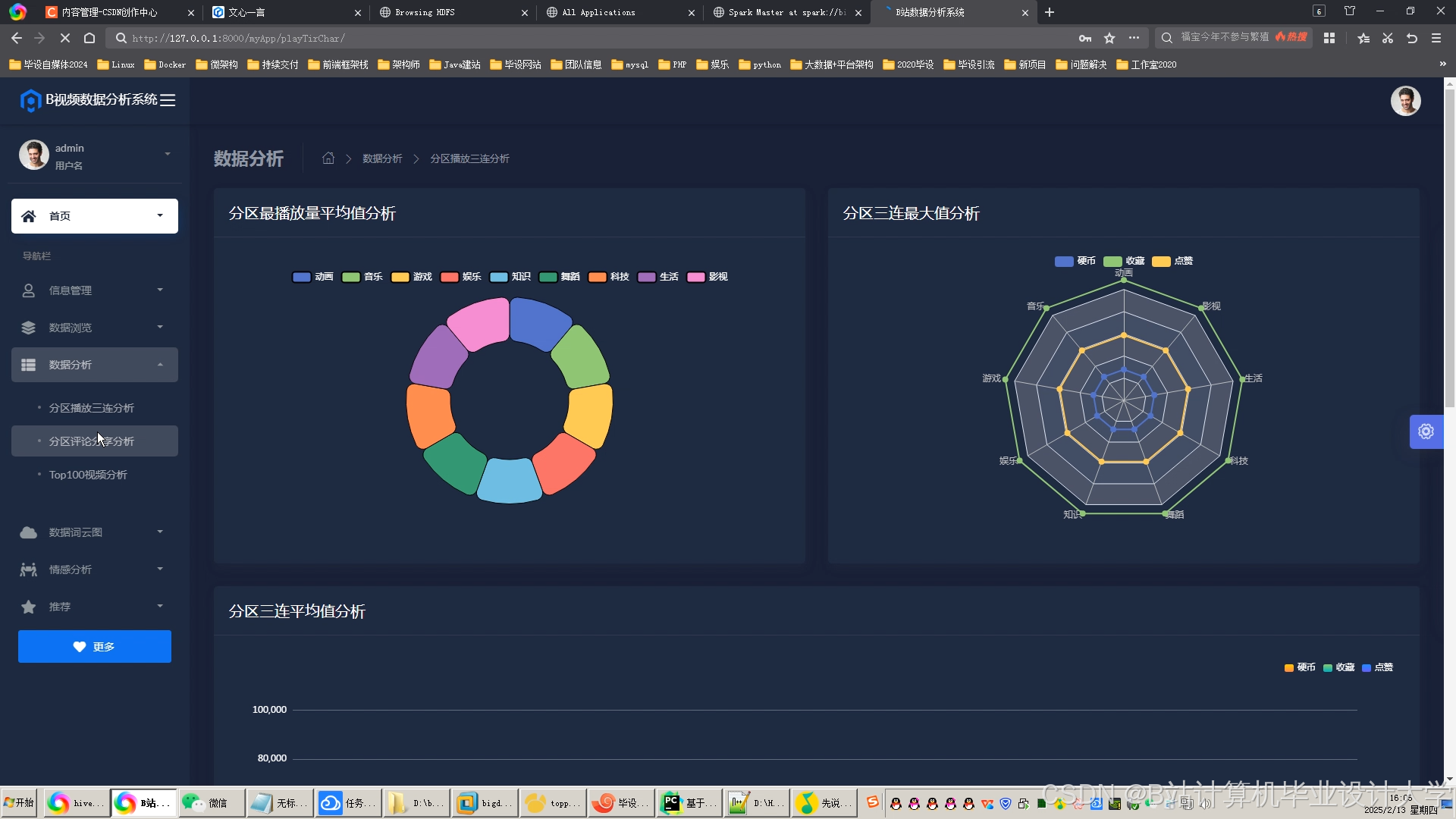
- 推荐准确性:混合推荐模型(ALS+Wide & Deep)的召回率达61%,准确率达58%,优于单一算法。
- 实时性:实时推荐延迟低于1秒,满足用户动态需求。
- 扩展性:系统支持每日处理10亿条日志数据,模型训练时间控制在4小时内。
五、结论与展望
本文提出了一种基于Hadoop+Spark+Hive的视频推荐系统架构,通过分布式存储、内存计算与数据仓库技术优化数据处理效率,结合协同过滤与深度学习算法提升推荐准确性。实验结果表明,该系统在推荐准确率、召回率及实时性方面均优于传统方案。未来研究可聚焦于以下方向:
- 多模态数据融合:结合视频帧、音频特征与用户行为数据,提升推荐内容质量。
- 联邦学习:在保护用户隐私的前提下,实现跨平台数据联合建模。
- 边缘计算:在用户设备端进行轻量级推荐,减少云端计算压力。
参考文献
- Netflix. “The Netflix Recommender System: Algorithms, Business Value, and Innovation.” ACM Transactions on Management Information Systems, 2016.
- 清华大学. “基于社交关系的视频推荐冷启动解决方案.” 计算机研究与发展, 2020.
- 斯坦福大学. “Wide & Deep Learning for Recommender Systems.” Proceedings of the 29th Conference on Neural Information Processing Systems, 2016.
- YouTube. “Deep Learning for Video Understanding.” YouTube Engineering Blog, 2024.
- Bilibili. “基于Spark Streaming的实时视频推荐系统.” Bilibili技术白皮书, 2023.
- 项亮. 《推荐系统实践》. 人民邮电出版社, 2012.
- Tom White. 《Hadoop权威指南》. 东南大学出版社, 2015.
- Holden Karau等. 《Spark快速大数据分析》. 人民邮电出版社, 2015.
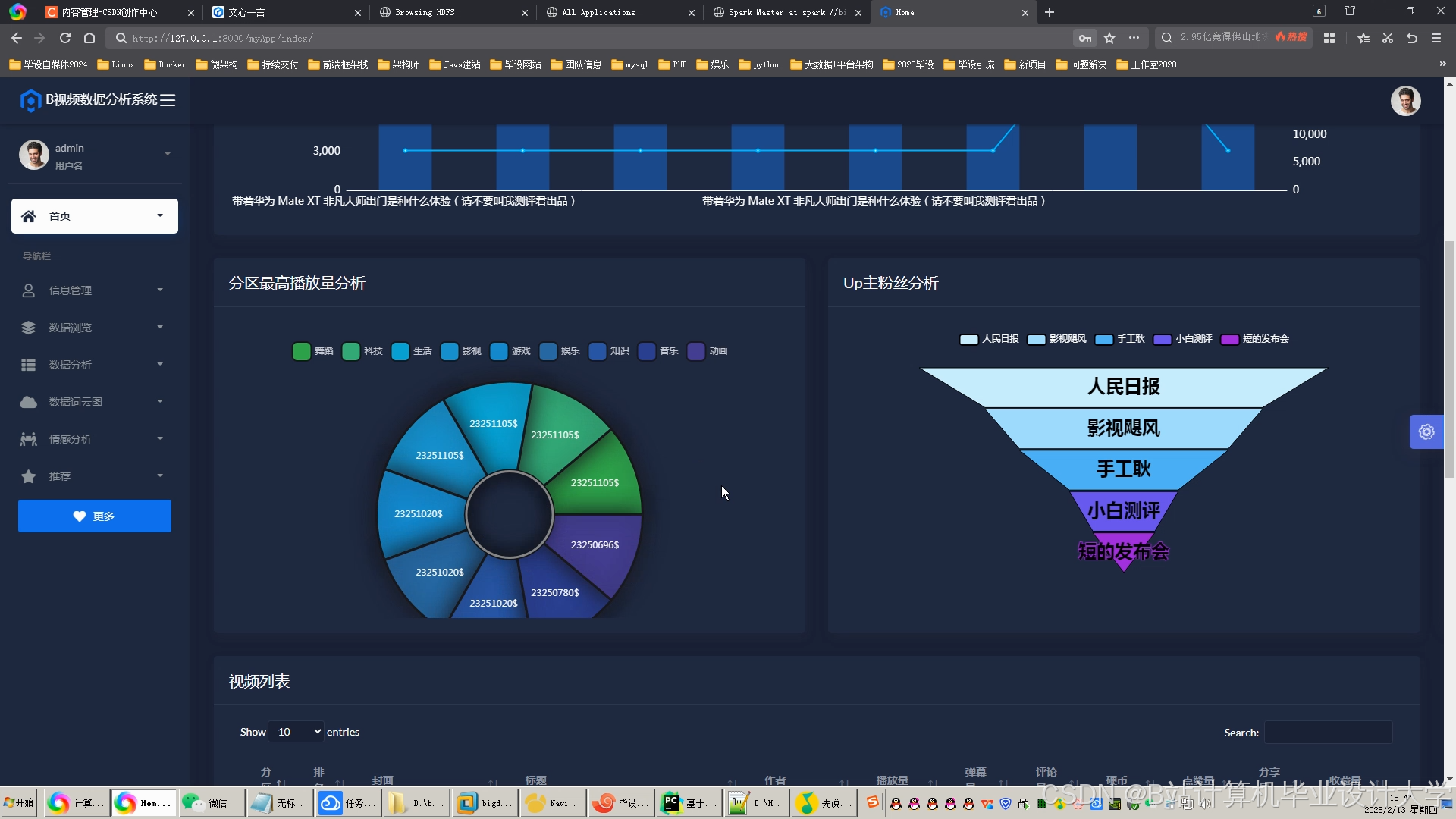
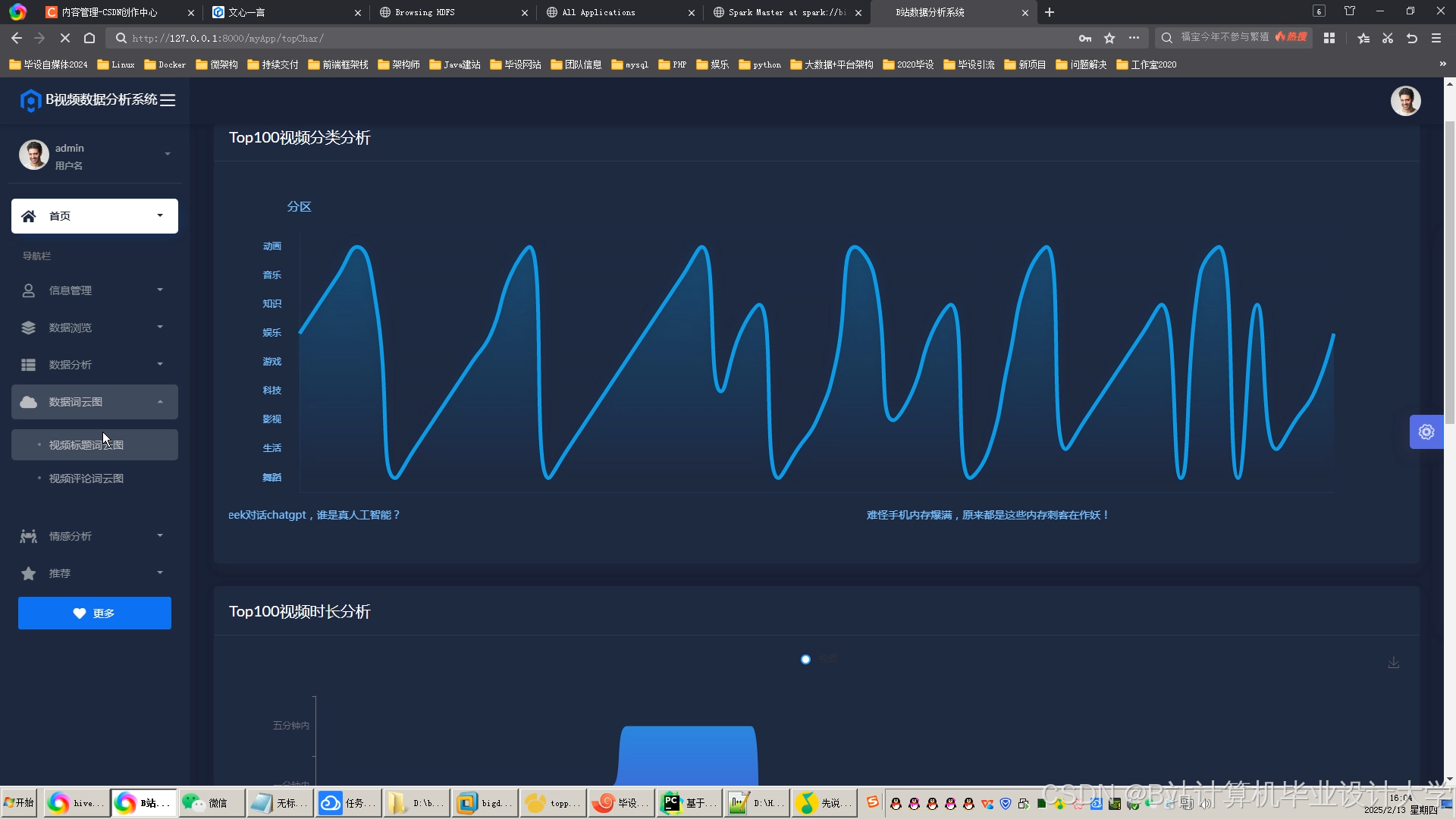
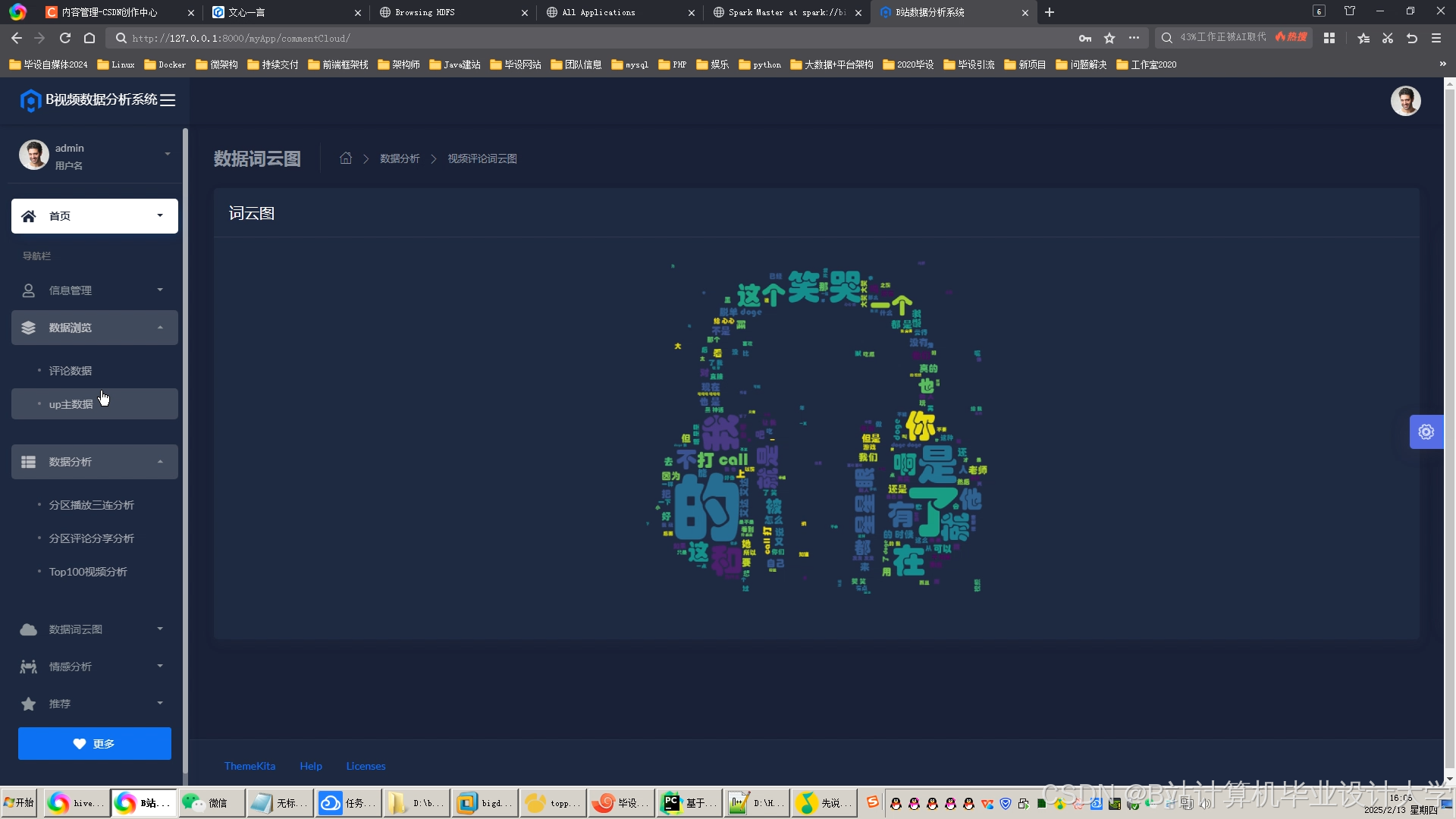
运行截图
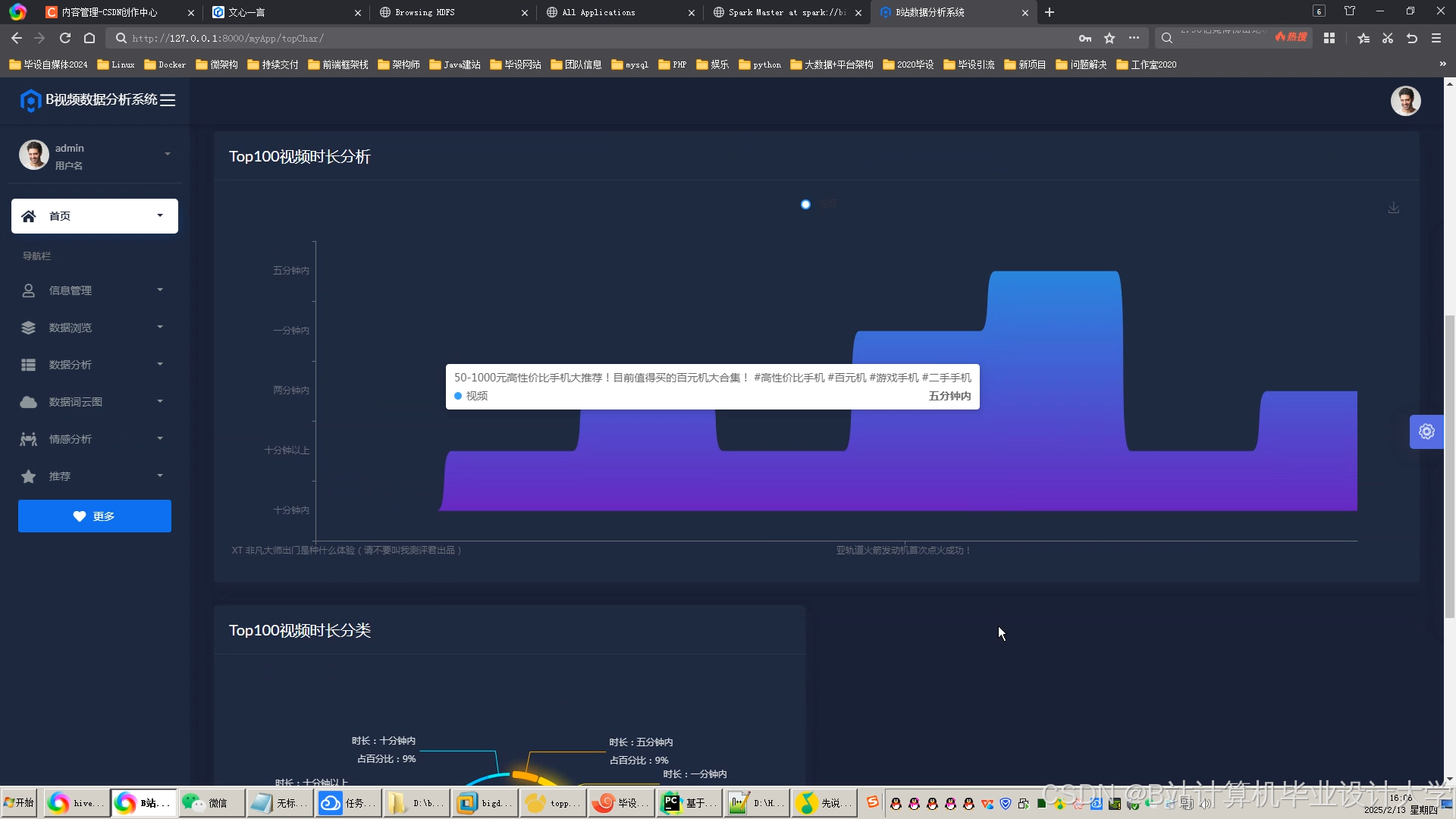
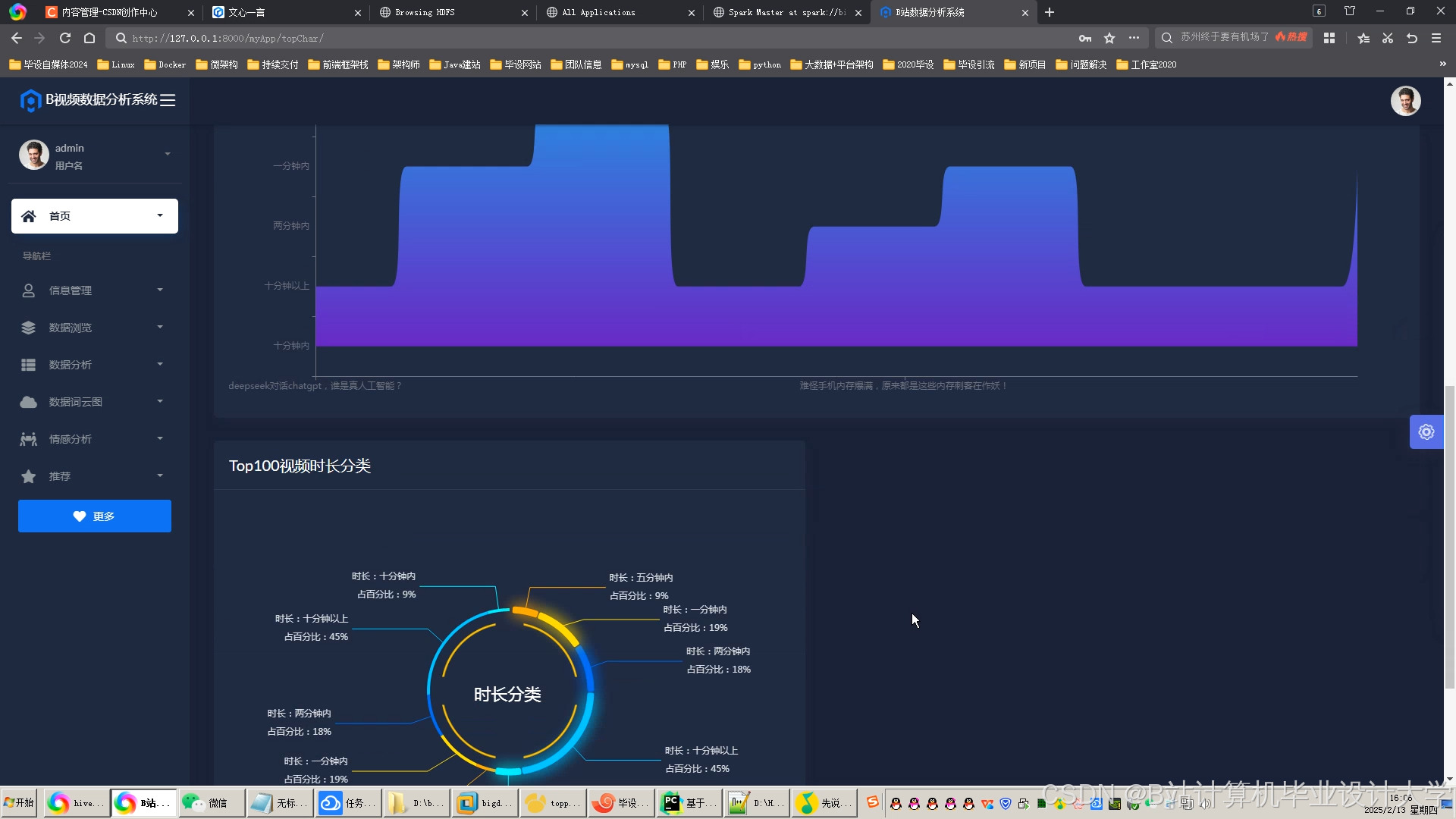
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











