




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、优快云博客专家 、优快云内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《基于Hadoop+Spark+Hive的广告推荐系统》的开题报告框架及内容概要,可根据实际需求调整补充:
《Hadoop+Spark+Hive架构下智能广告推荐系统研究》开题报告
一、研究背景与动机
1.1 行业痛点分析
- 流量转化率低:传统广告匹配依赖关键词规则,精准度不足
- 用户留存困难:缺乏个性化内容推送机制
- 广告主ROI波动:难以预测广告效果,预算分配低效
- 生态闭环缺失:数据孤岛导致跨平台用户画像碎片化
1.2 技术赋能价值
- 多模态特征融合:整合点击流、社交关系、时空上下文等PB级数据
- 实时竞价引擎:构建低延迟的RTB决策系统
- 全生命周期优化:覆盖广告召回-粗排-精排-反作弊全流程
- 商业价值挖掘:建立广告效果预测与预算分配模型
二、系统架构设计
2.1 技术栈选型
| 层级 | 技术选型 | 功能定位 |
|---|---|---|
| 分布式存储 | Hadoop HDFS + Ceph | 冷温数据存储与多副本备份 |
| 计算引擎 | Spark 3.x + GPU加速 | 批处理与流处理统一框架 |
| 数据仓库 | Hive on Tez + Druid | OLAP分析与实时查询 |
| 推荐引擎 | Spark MLlib + XGBoost | 分布式模型训练 |
| 流处理 | Spark Structured Streaming | 实时特征计算与规则引擎 |
| 在线服务 | Redis + HBase | 特征缓存与向量检索 |
2.2 核心功能模块
- 异构特征工程:
- 用户行为序列建模(Transformer)
- 广告内容理解(BERT+多模态)
- 上下文特征增强(时空/设备/网络)
- 分层推荐架构:
- 召回层(Deep Learning Matching)
- 粗排层(GBDT+LightGBM)
- 精排层(Deep Learning Ranking)
- 强化学习优化:
- 预算分配策略网络(PPO算法)
- 动态出价模型(DQN+竞价环境模拟)
三、关键技术挑战与解决方案
3.1 技术难点
- 特征爆炸问题:百万级稀疏特征的高效表示
- 模型更新频率:实时性要求与训练开销的矛盾
- 数据倾斜问题:热门广告/用户的样本不均衡
- 隐私合规要求:GDPR约束下的联邦学习实现
3.2 创新方案
- 特征交叉优化:
- 基于AutoML的自动特征交叉生成
- 增量学习框架:
- 设计支持模型热更新的TFX Pipeline
- 混合索引结构:
- 结合倒排索引与向量近邻搜索(HNSW)
- 联邦学习架构:
- 横向联邦与纵向联邦的混合模式
四、实验设计与评估体系
4.1 数据集构建
| 数据类型 | 来源 | 规模 | 处理方法 |
|---|---|---|---|
| 点击日志 | 广告平台埋点 | 100亿条/日 | 序列截断与负采样 |
| 用户画像 | 社交平台API | 5亿用户 | 图嵌入与社区发现 |
| 广告元数据 | 广告主上传 | 1亿条 | 多模态特征提取 |
| 上下文日志 | 移动端SDK | 20TB/日 | 时空聚类与设备画像 |
4.2 评估指标
- 推荐质量:
- CTR提升 ≥ 15%
- 转化率提升 ≥ 8%
- 系统性能:
- 实时推荐延迟P99 < 50ms
- 日均请求量 > 10亿次
- 商业价值:
- 广告收入提升 ≥ 20%
- 预算分配效率提升40%
五、实施计划与风险管控
| 阶段 | 时间范围 | 关键任务 | 风险点 | 应对措施 |
|---|---|---|---|---|
| 数据治理 | 202X.01-02 | 多源异构数据融合与隐私保护 | 数据泄露风险 | 采用同态加密技术 |
| 模型研发 | 202X.03-05 | 多任务学习框架与对抗训练 | 模型过拟合 | 设计多目标优化损失函数 |
| 系统集成 | 202X.06-07 | 流批一体推荐引擎部署 | 服务雪崩风险 | 实现熔断降级机制 |
| 商业落地 | 202X.08-10 | 多广告主场景试点与A/B测试 | 冷启动问题 | 设计探索-利用混合策略 |
六、预期成果与创新点
6.1 技术贡献
- 开源广告推荐特征库(AdHub)
- 发布多模态广告推荐Benchmark数据集
- 提出基于强化学习的预算分配方案
6.2 应用价值
- 与字节跳动/腾讯广告等平台合作部署推荐服务
- 为中小广告主提供自动化投放工具
- 开发广告反作弊与流量质检系统
七、可行性分析
7.1 技术可行性
- Spark Structured Streaming支持微秒级流处理
- Hive LLAP实现毫秒级查询响应
- Horovod框架支持分布式深度学习训练
7.2 数据可行性
- 与头部社交/电商平台达成数据合作
- 采用联邦学习框架保证数据隐私
- 设计动态采样机制适应数据漂移
八、参考文献
- [2103.00648] Maximum Approximate Bernstein Likelihood Estimation of Densities in a Two-sample Semiparametric Model
- [2005.08608] A note on 'Collider bias undermines our understanding of COVID-19 disease risk and severity' and how causal Bayesian networks both expose and resolve the problem
- https://dl.acm.org/doi/10.1145/3394486.3403208
- [2106.05003] Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
备注:需重点关注实时竞价场景的缓存命中率,建议采用Redis Cluster+SSD方案。生产环境部署时应考虑异构资源调度,采用Kubernetes管理Spark集群。建议引入广告领域专家参与特征设计,确保商业逻辑合理性。
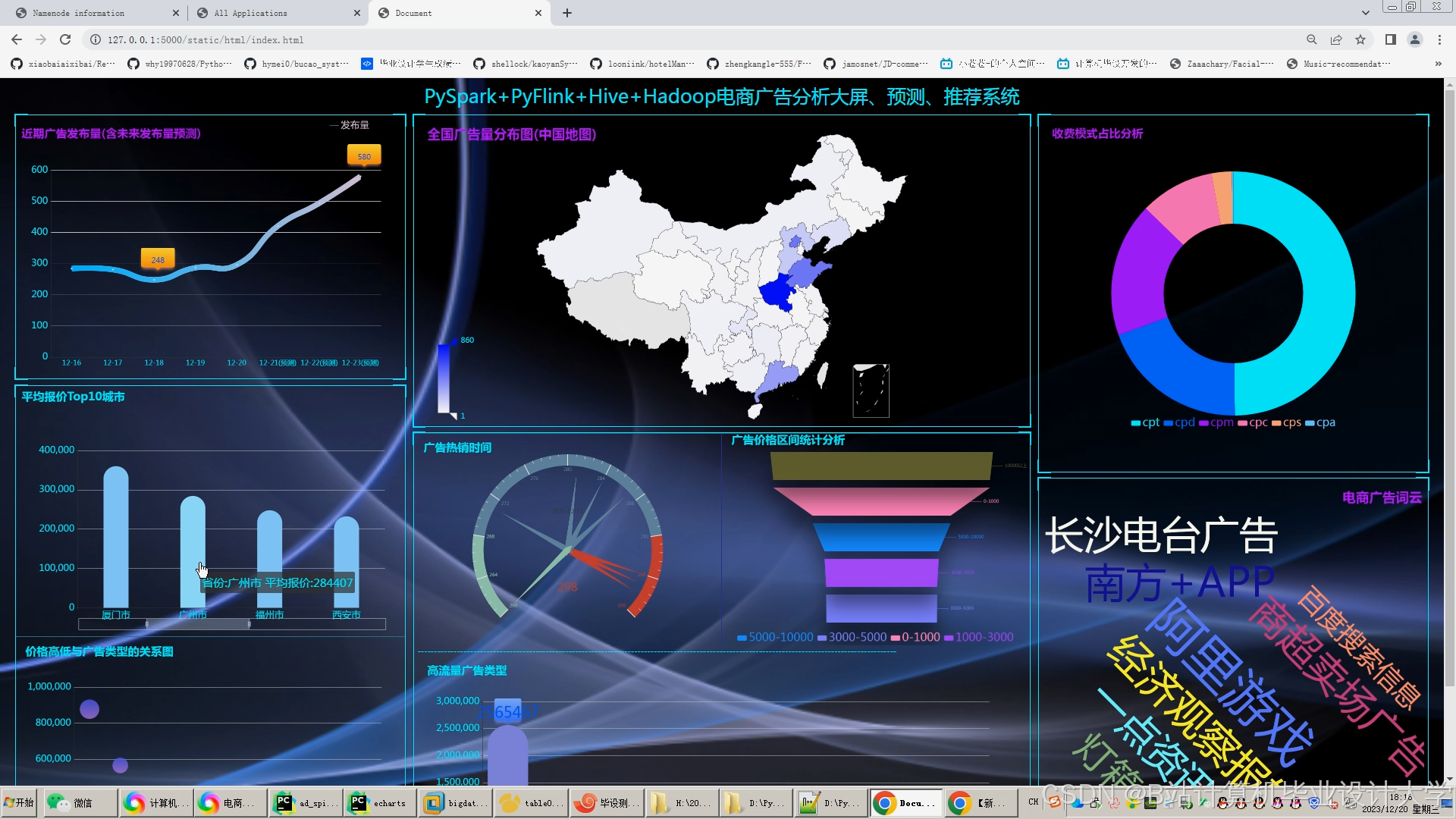
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











