




毕业技术方向调查表
姓名: 李昌福
|
课题方向 |
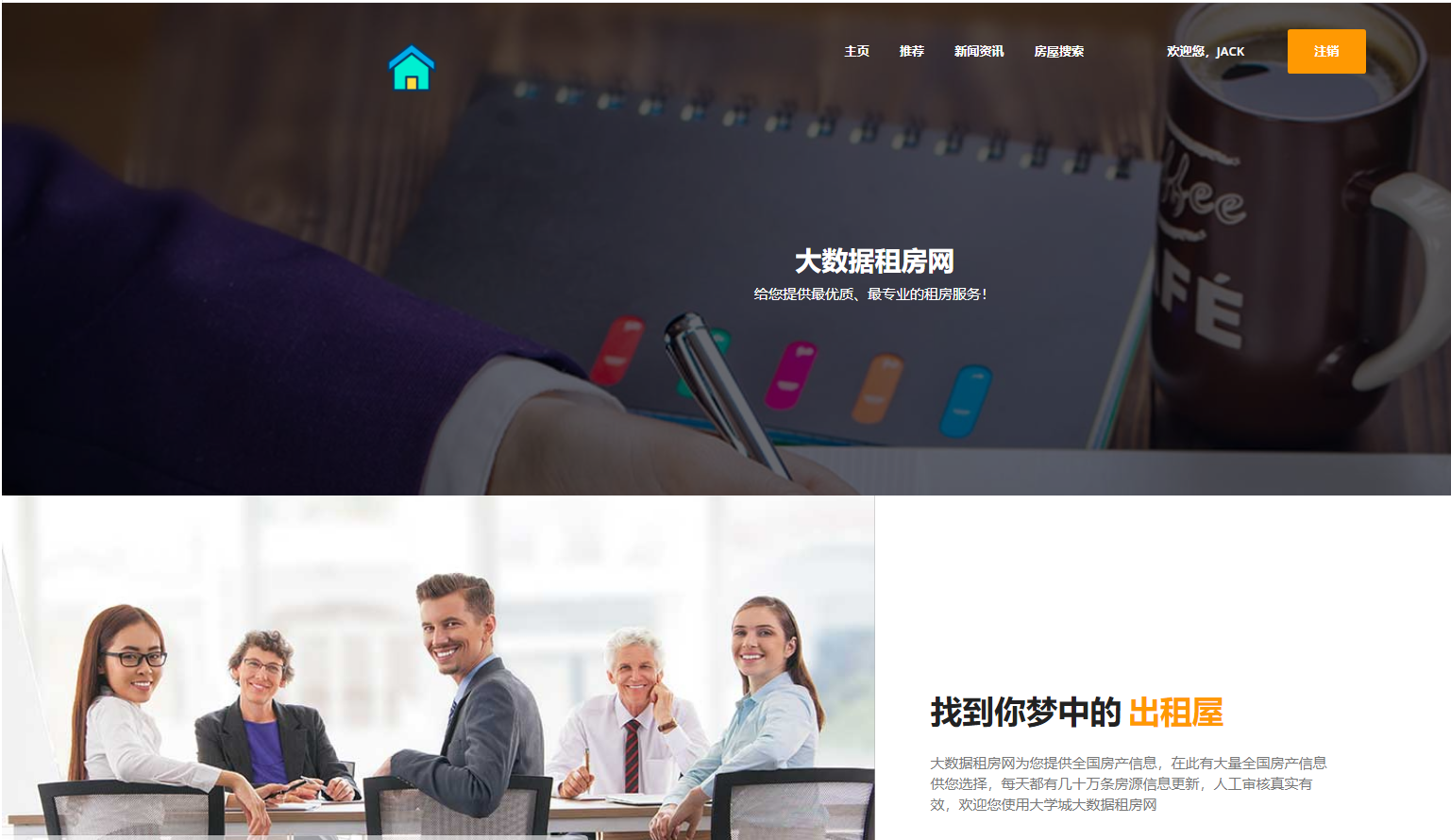
房无忧房屋租赁平台 | ||||||
|
开发语言: |
Java |
前端框架: |
VUE |
数据库: |
MySQL | ||
|
服务器端 框架: |
SpringCloud |
其他技术: |
Hadoop、HDFS | ||||
|
方向意义 |
结合四年在校所学专业知识,针对如今人们对住房需求提升的问题,进行调研和分析,并利用Java、VUE、SpringCloud等技术开发XX房屋租赁平台,解决人们找房难、出租难的问题,并提供数据分析结果便于用户对房源及租期进行合理的规划。 | ||||||
|
预设 业务逻辑 |
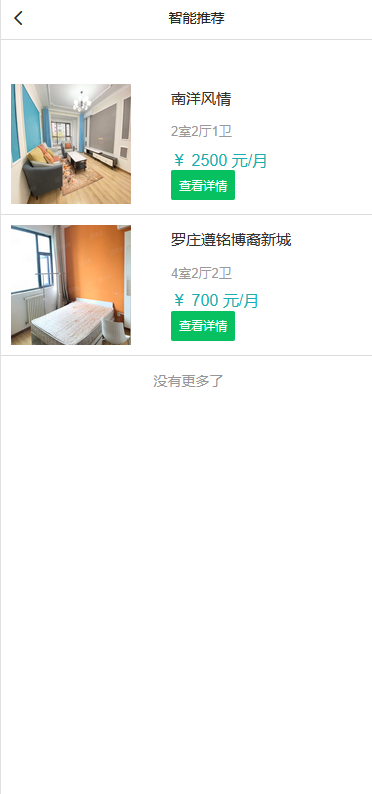
模块一:租客用户模块 功能点1:用户注册和登录 功能点2:查看在租房屋的具体房源信息(时间,所在位置,大小等) 功能点3:向房东提出看房请求 功能点4:对已租房屋向房东发起退租请求 功能点5:查看租房历史,并可对其进行增删改查 模块二:房东用户模块 功能点1:用户注册和登录 功能点2:发布房源具体信息(包括图片、文字、视频等) 功能点3:查阅看房请求(所对应的租客信息、时间、请求的房源) 功能点4:管理看房请求(可对其接受或拒绝)和退租请求 模块三:管理员模块 功能点1:管理员注册和登录 功能点2:查看平台租客、房东权限和信息,并可对其进行管理 功能点3:查看平台的房源内容,并有权限对其进行增删改查 功能点4:发布平台公告,返回公告已确认信息 模块四:报障模块 功能点1:租客发现故障,进行报障申请 功能点2:房东查看对应租客未处理的故障 功能点3:房东收到报障申请,开始处理已报故障 功能点4:发布故障处理流程和处理结果反馈 模块五:数据导出及分析模块 功能点1:将用户数据导出为MR平台数据文件 功能点2:允许用户基于HDFS分布式平台进行数据管理 功能点3:允许用户基于Hadoop集群进行数据处理 功能点4:处理数据,得出看房请求的最大值,请求量与时间的关系 功能点5:处理并分析租客年龄信息,对比各年龄人群租房的偏好 功能点6:输出数据成为数据库文件,供数据展示平台使用 | ||||||
|
技术或业务逻辑特色 | |||||||
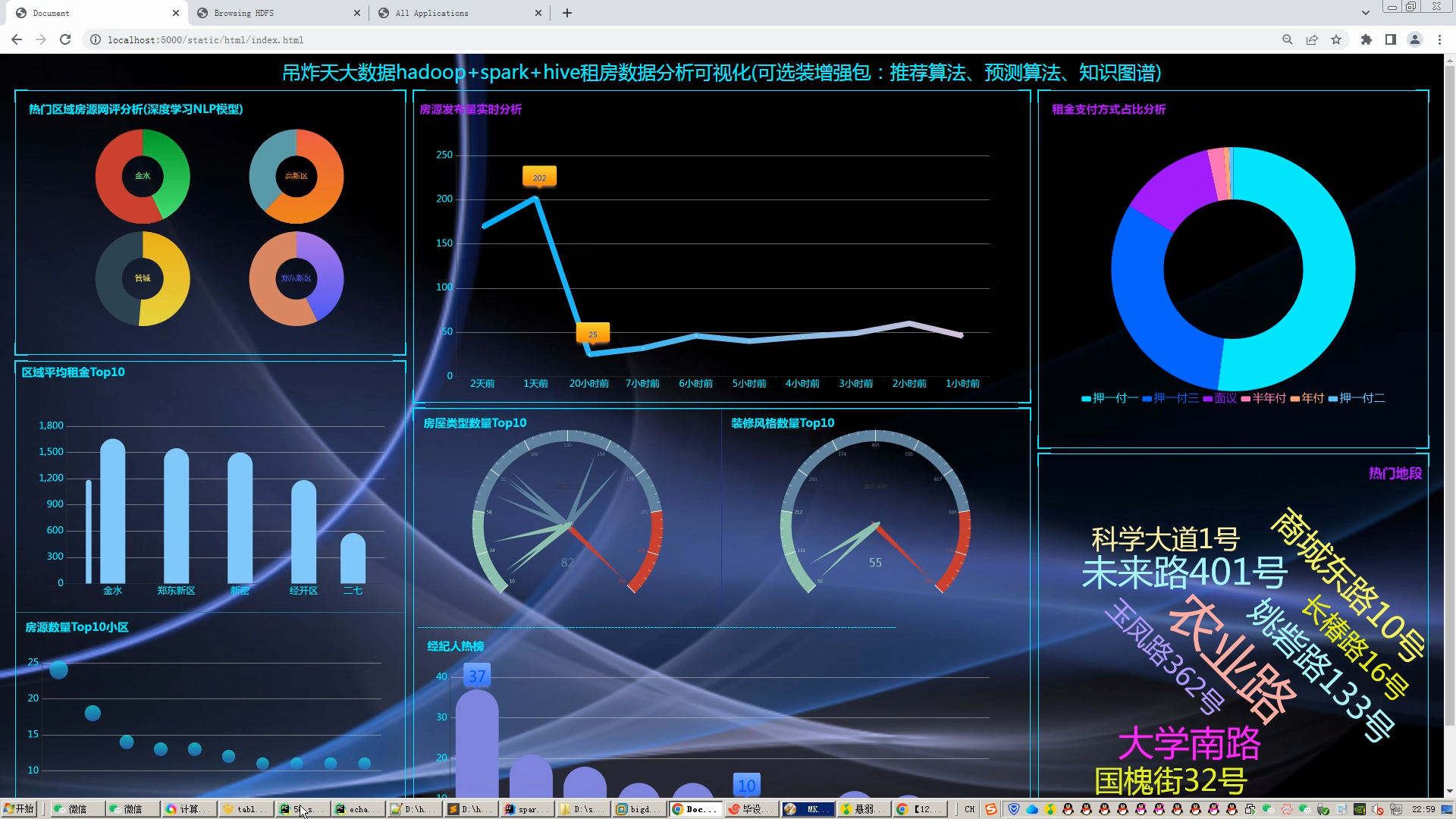
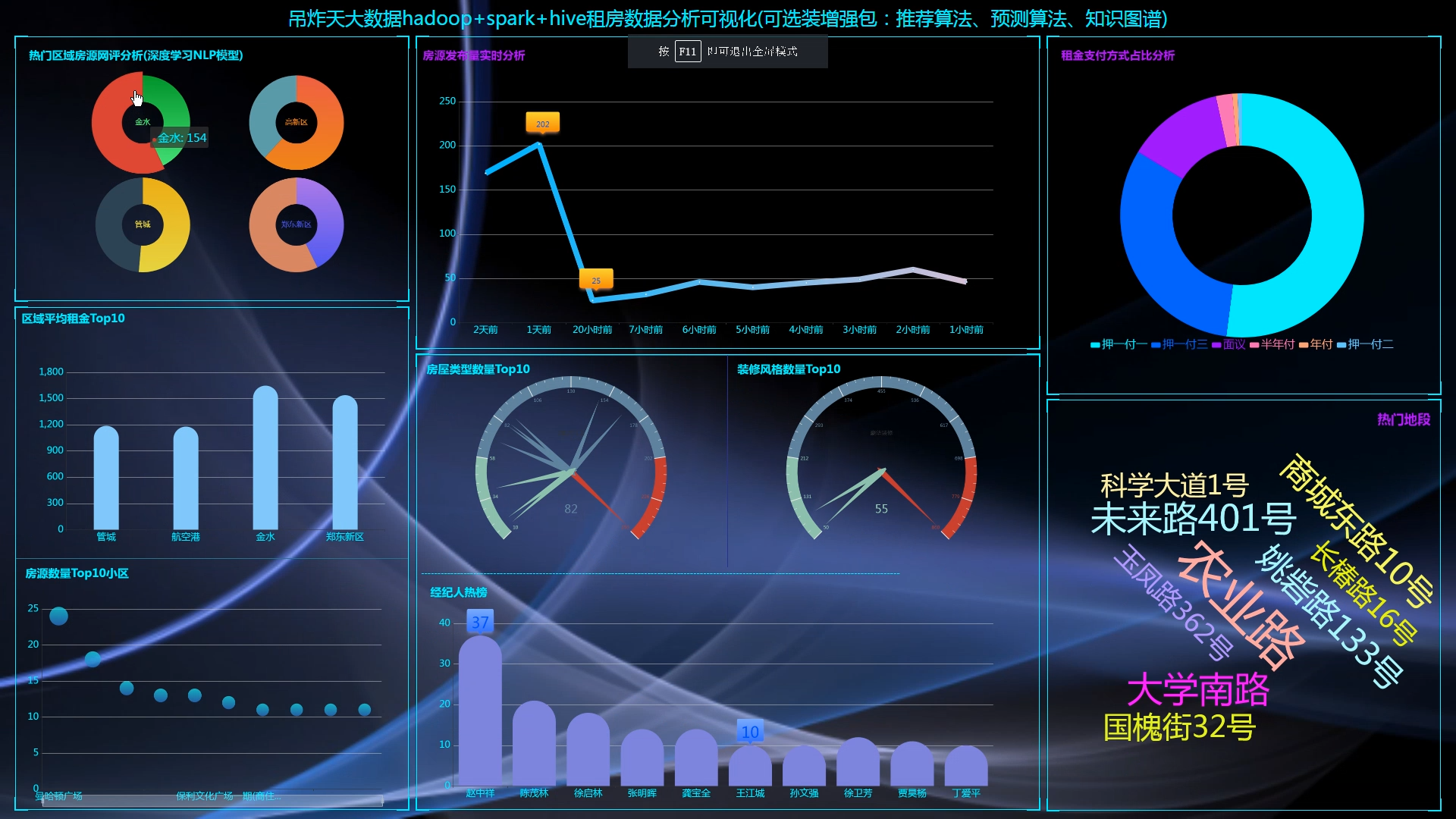
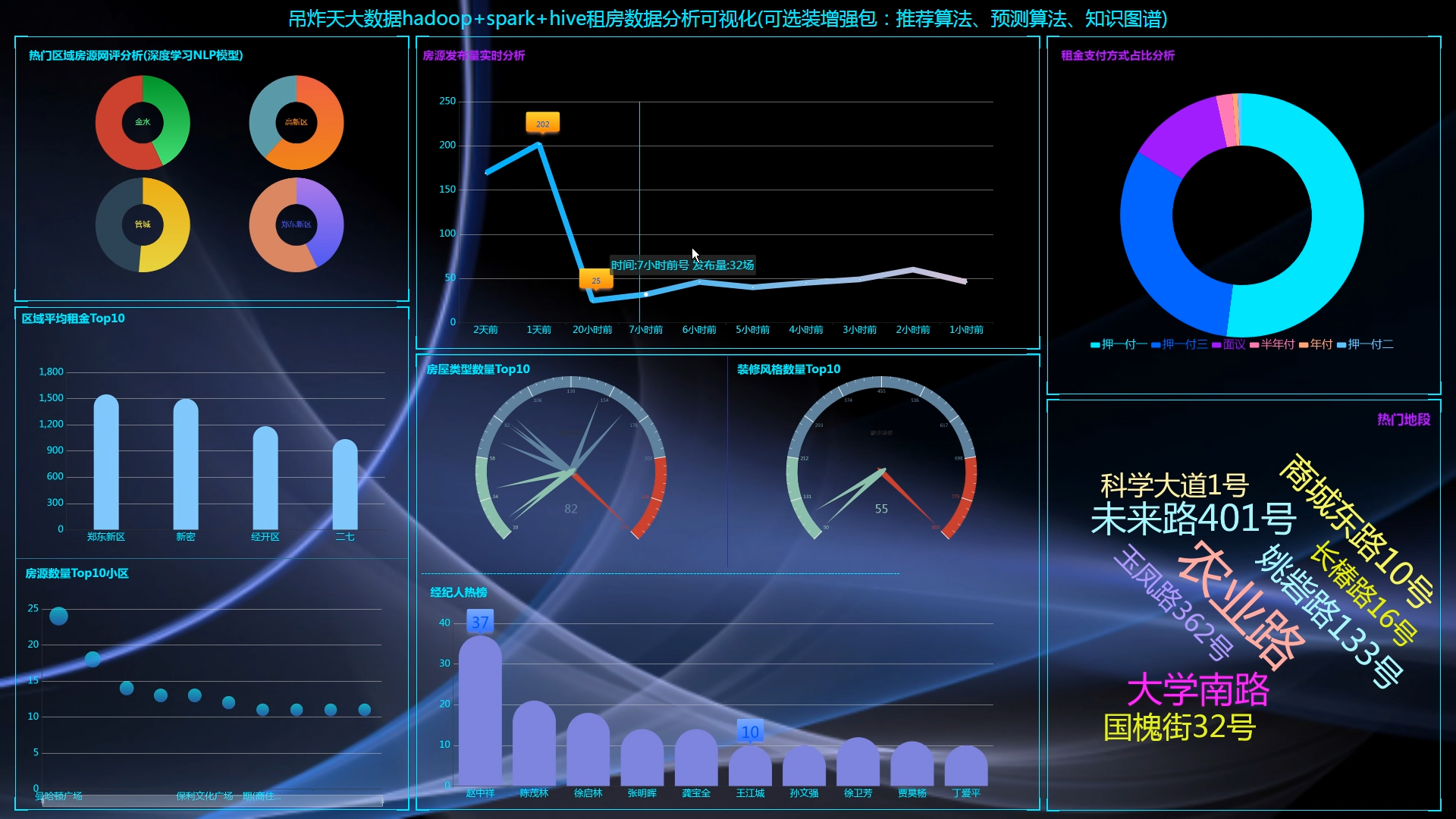
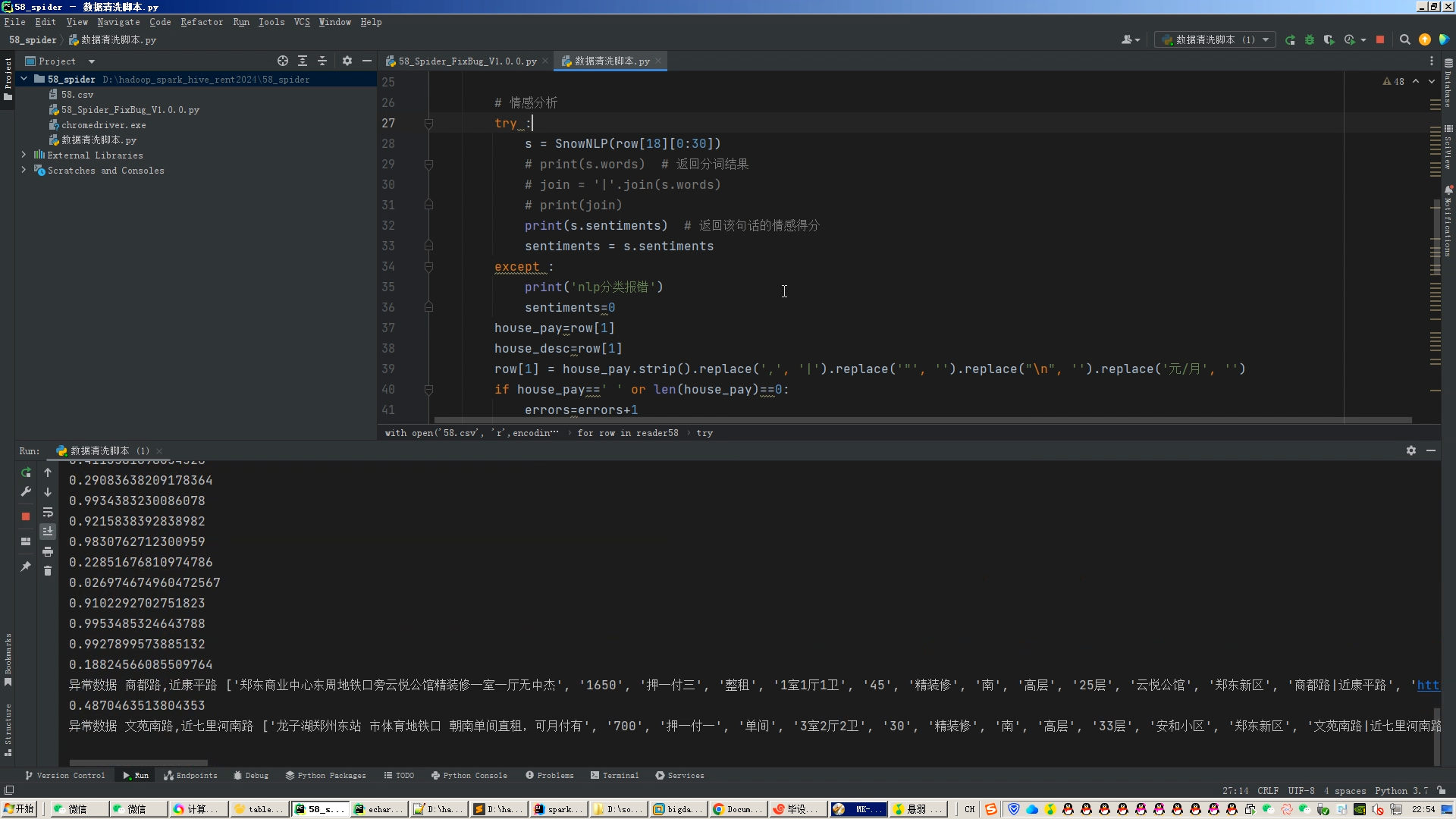
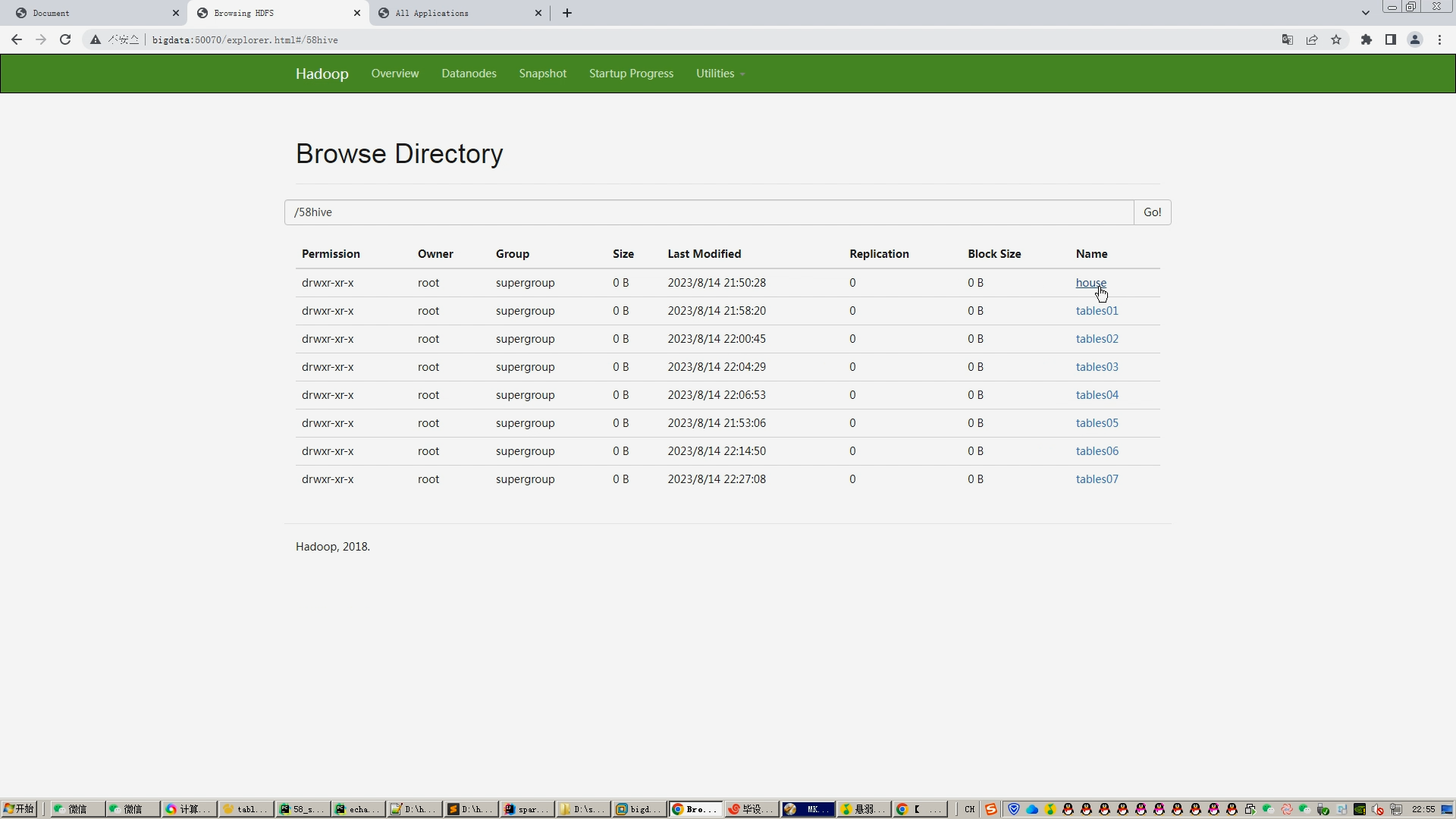
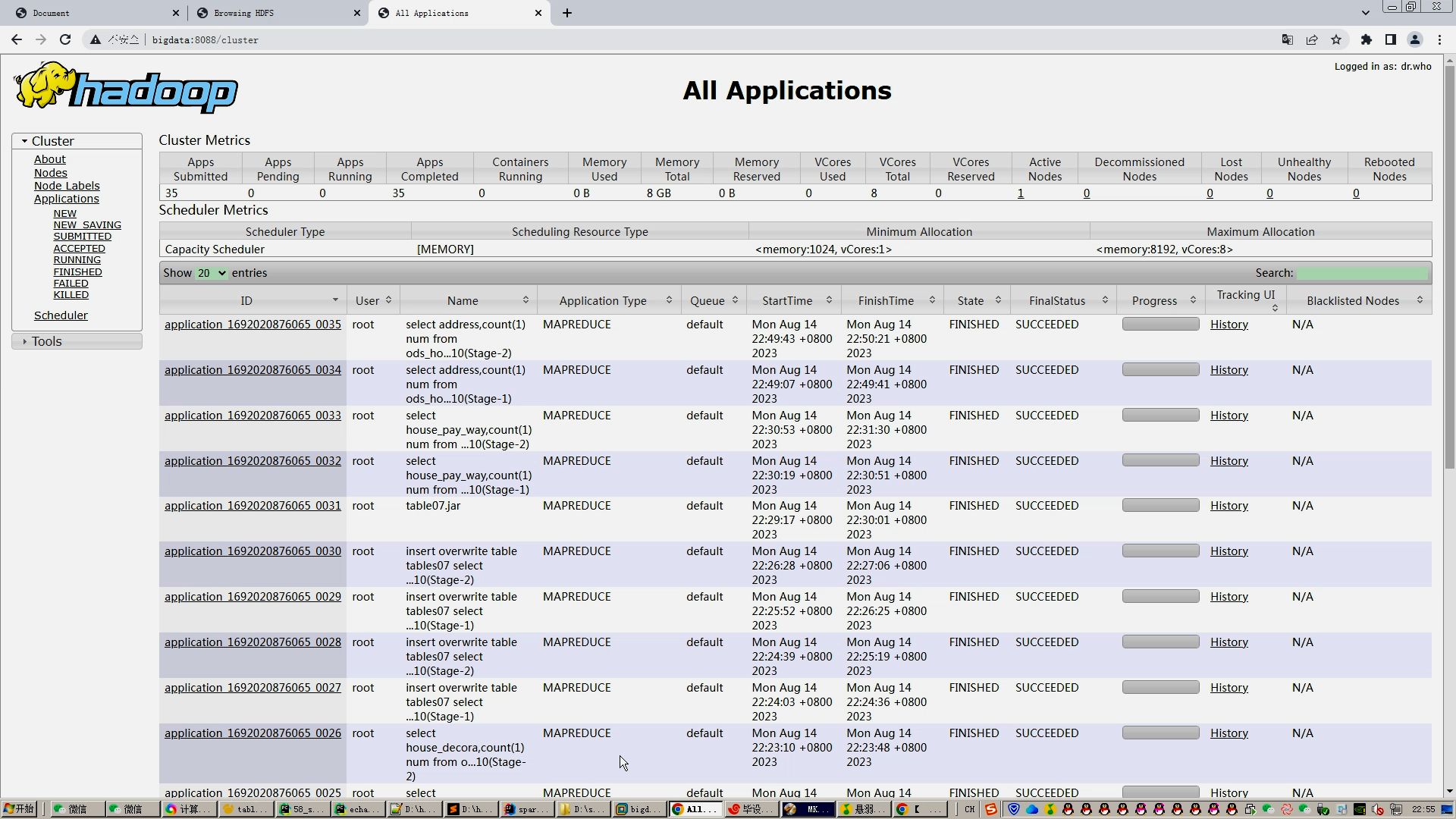
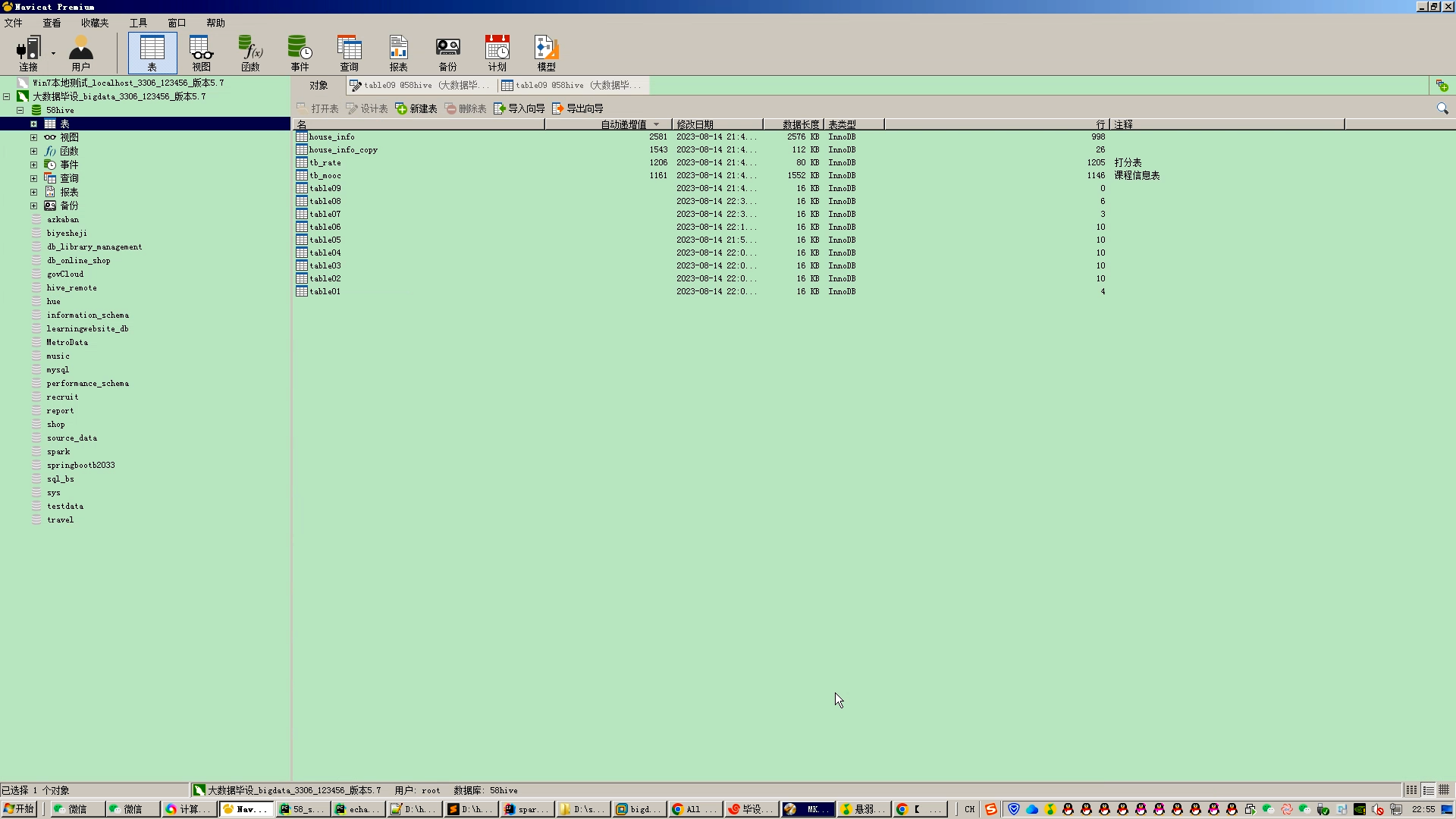
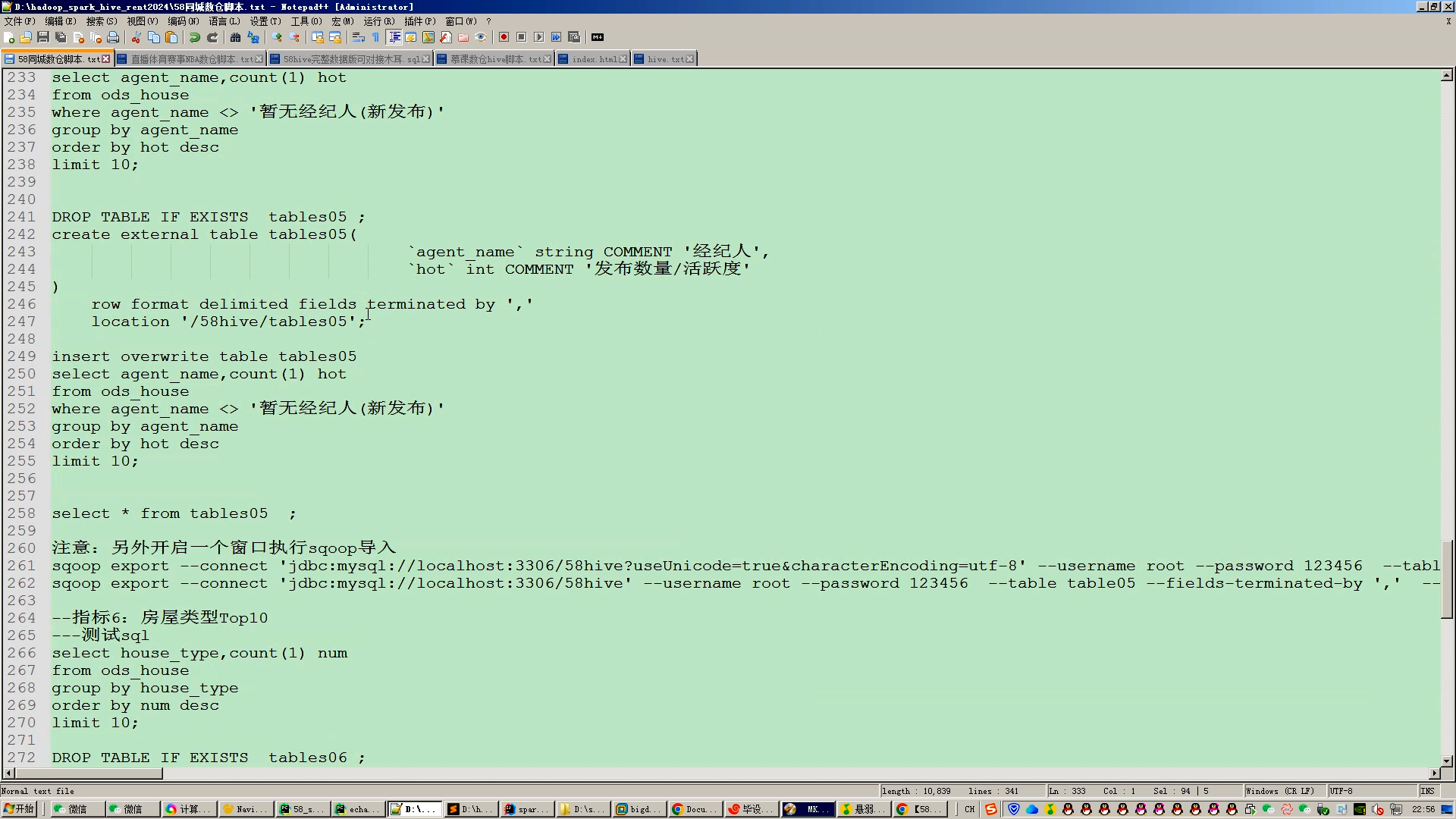
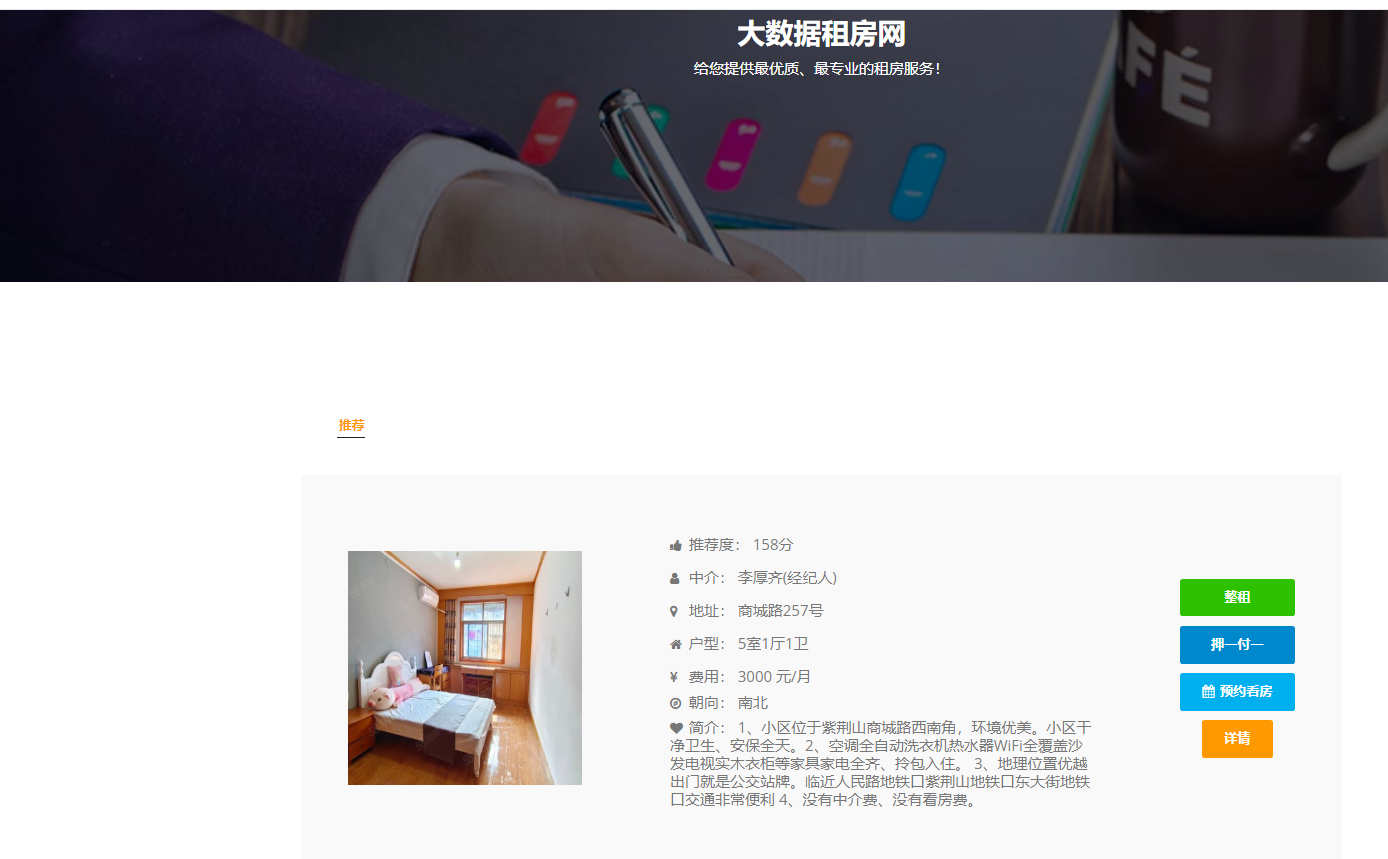
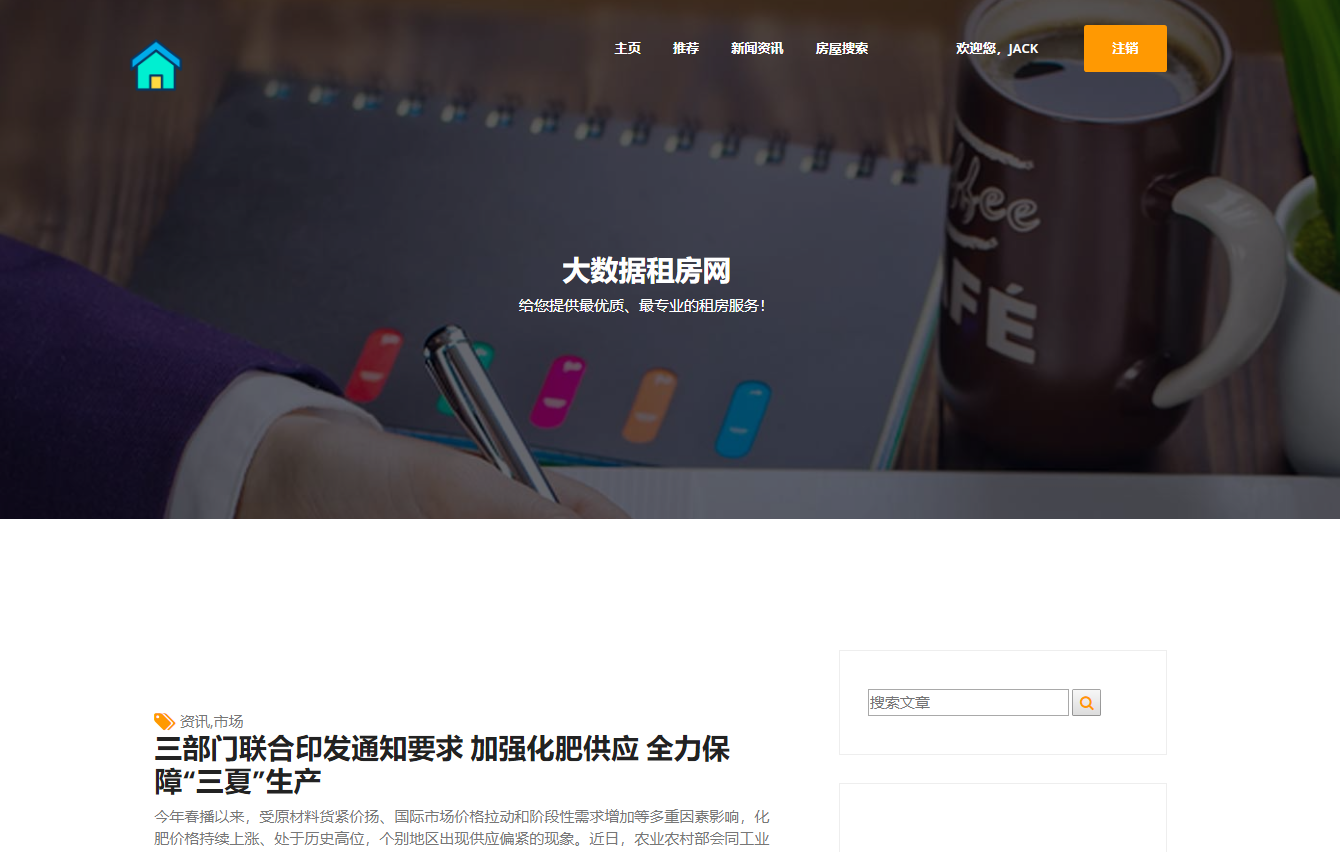
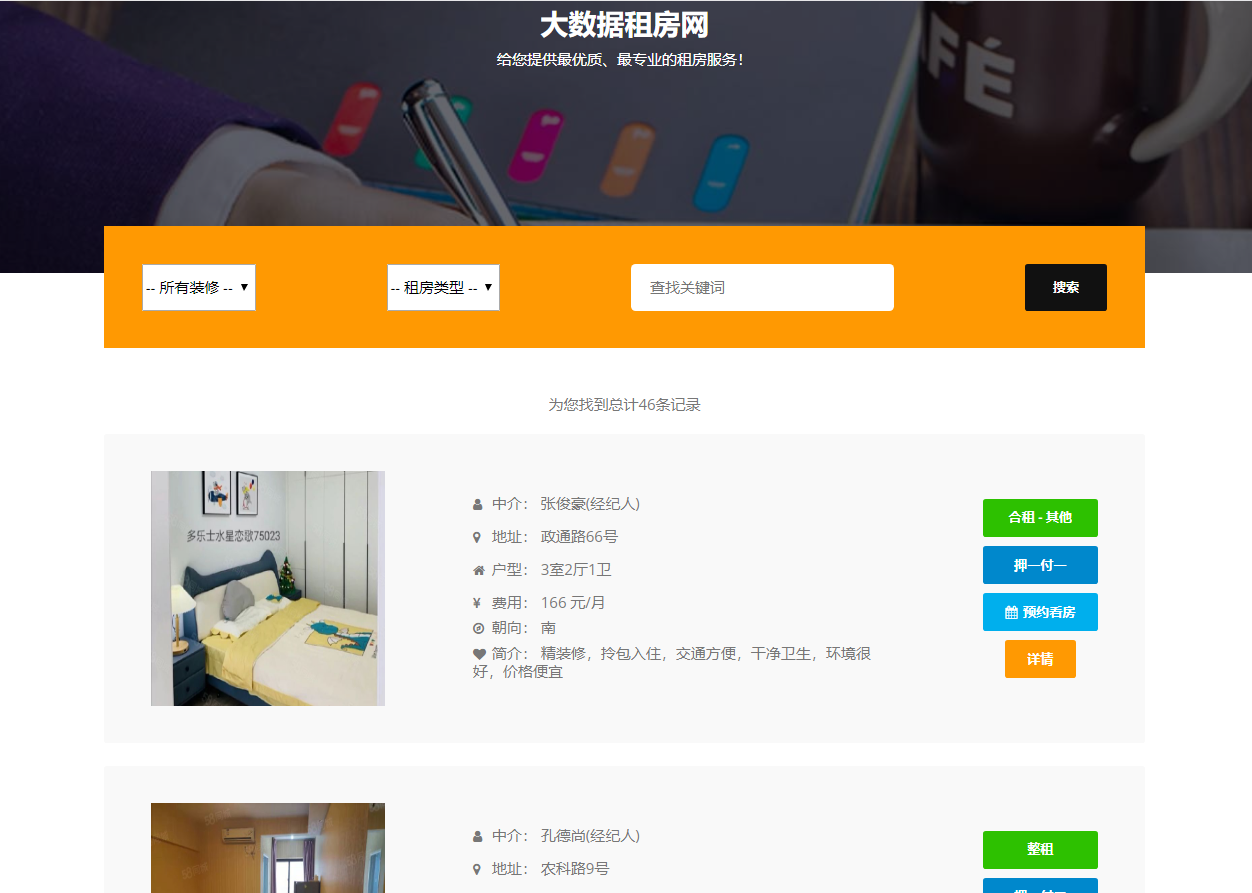
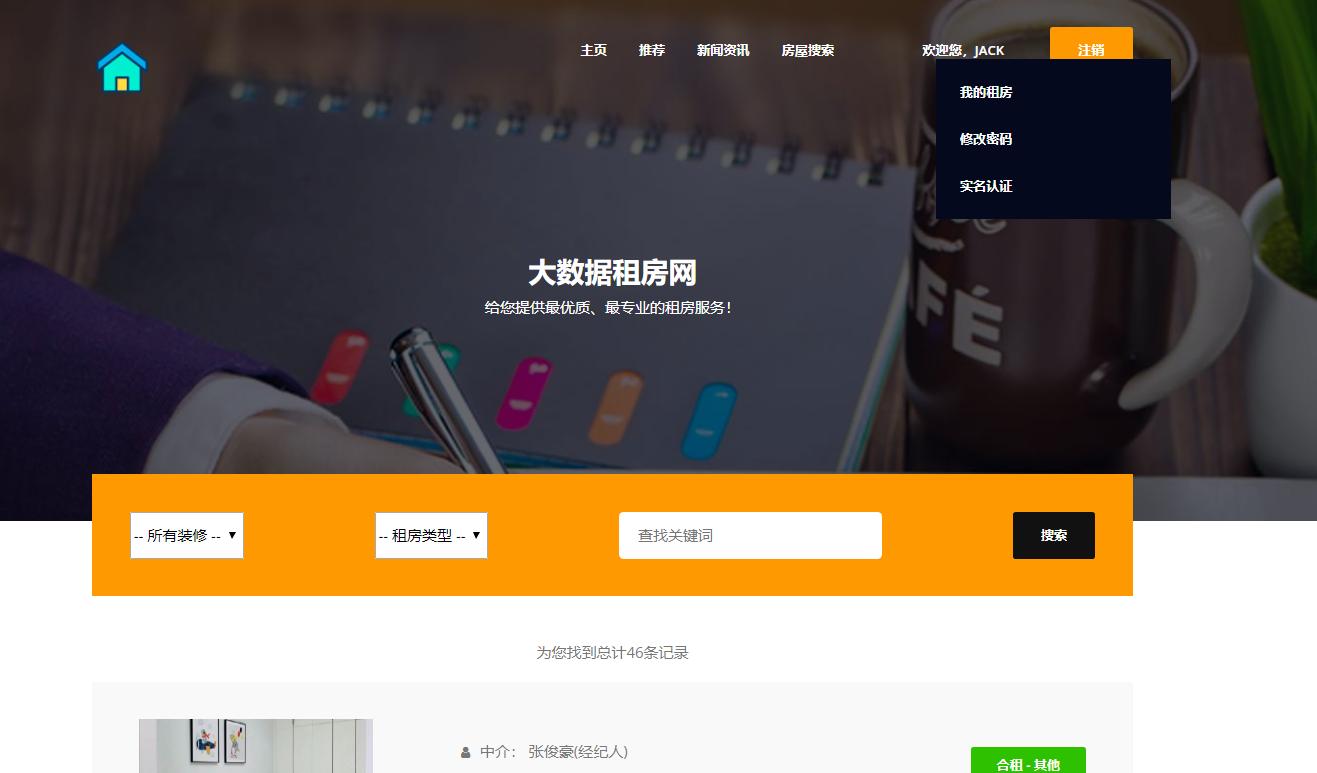
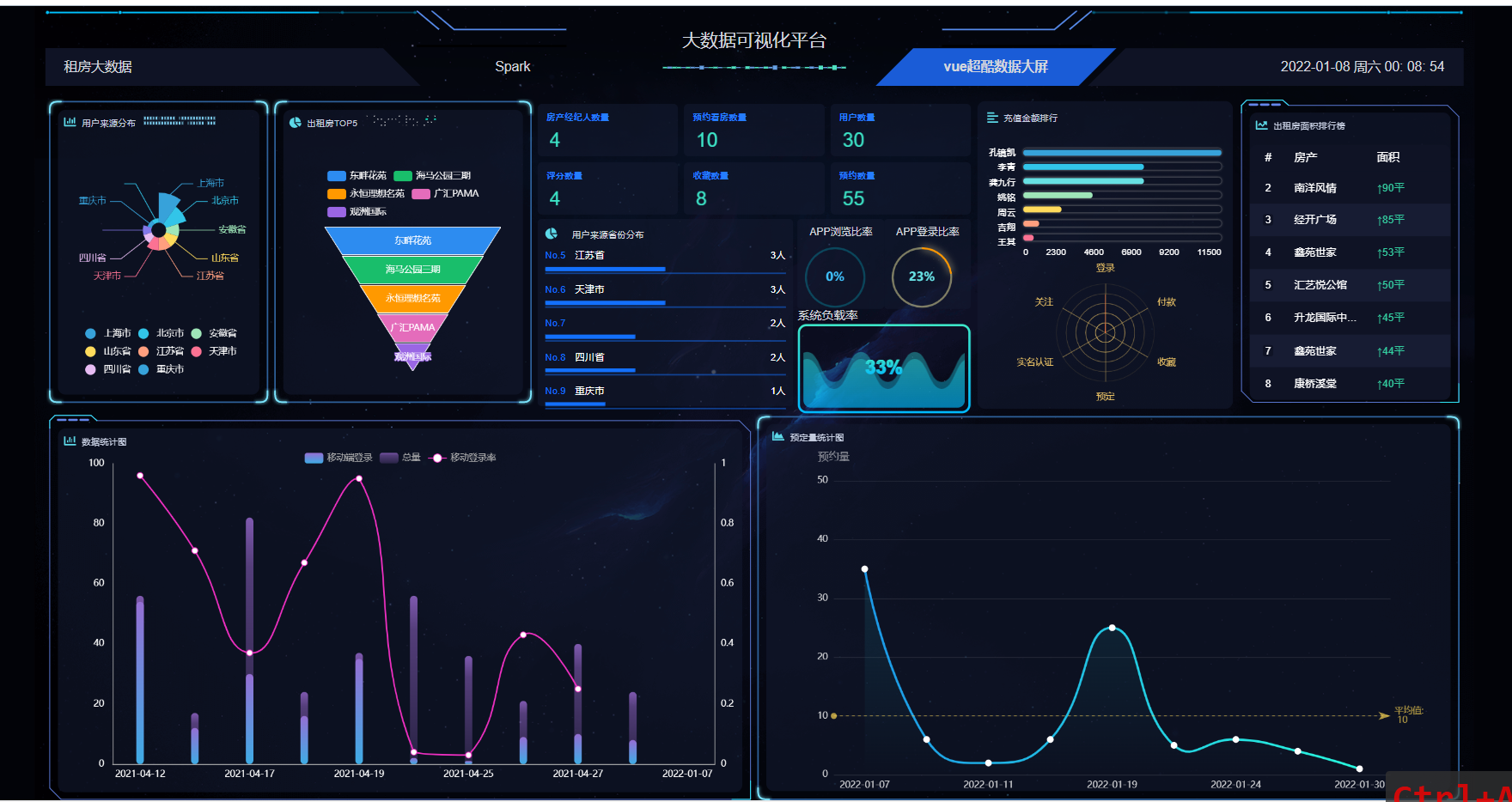
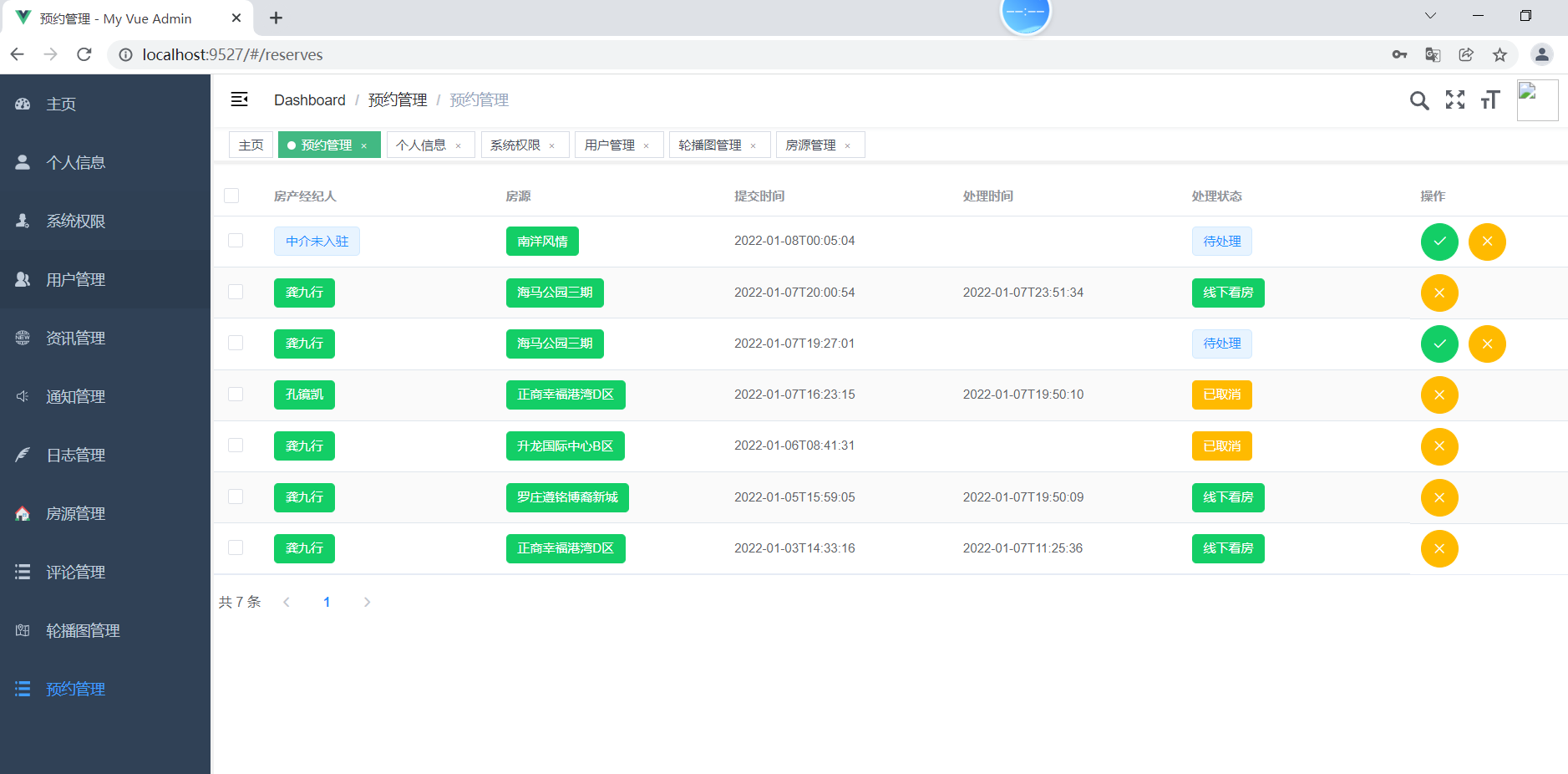
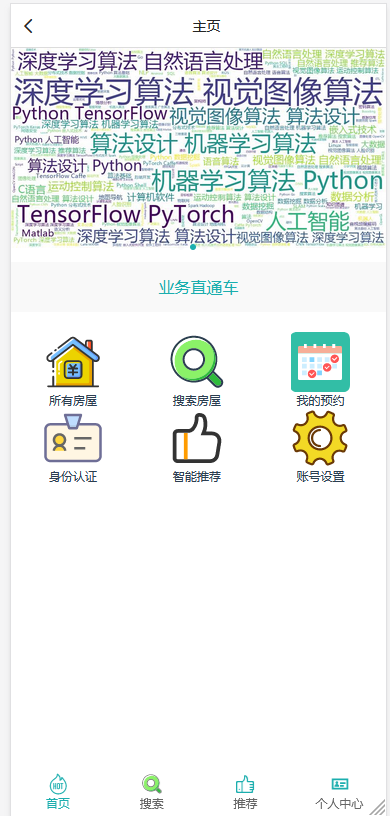
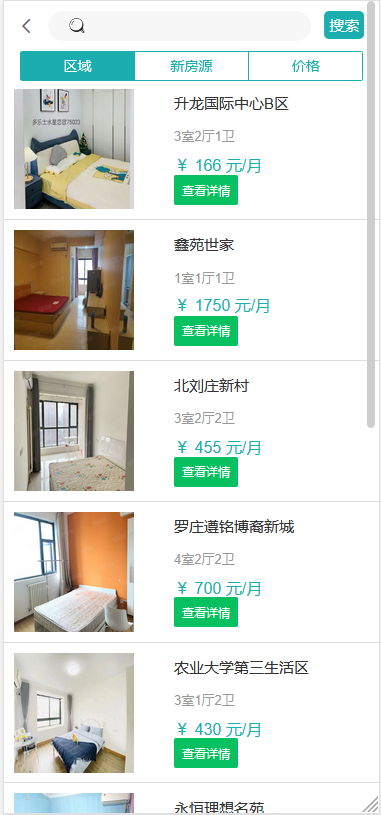
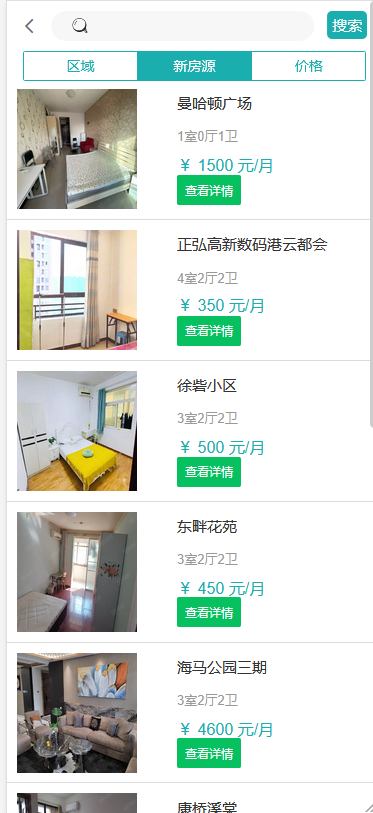
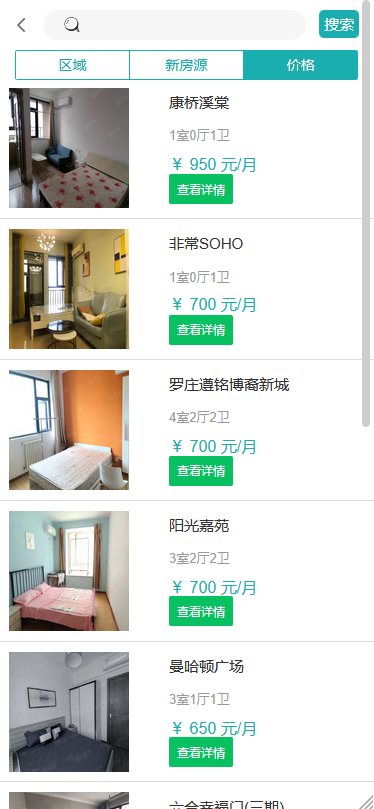
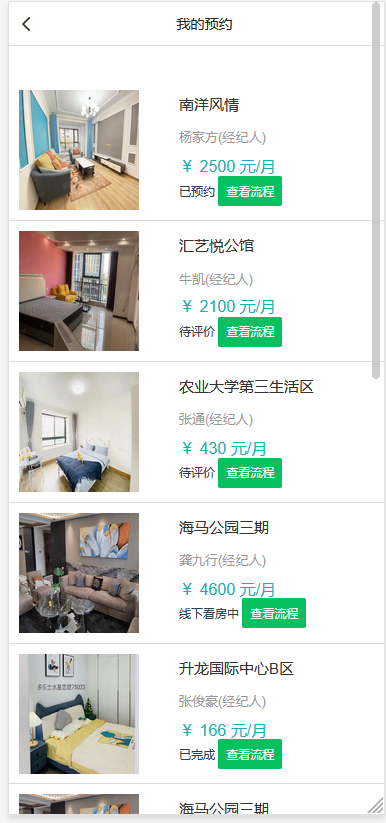

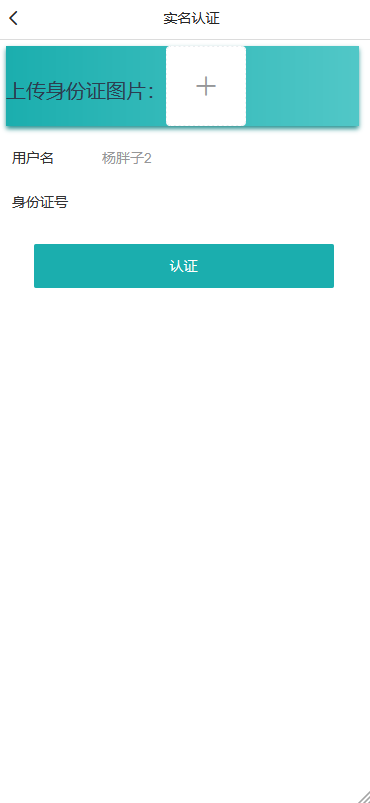
核心算法代码分享如下:
import csv
from snownlp import SnowNLP
#如果有英文逗号就复制下面的代码修改
#都是在弥补没对moc.py的111行前后的nickname字段进行处理!代码已经优化
with open('58.csv', 'r',encoding='utf-8') as file58 :
reader58 = csv.reader(file58)
errors = 0
for row in reader58:
#租房表正常是按照,分割出21个字段,如果多了一个逗号,分割的字段指定大于21,识别为异常行直接舍弃
address=row[12]
house_desc=row[18]
agent_name=row[15]
house_area=row[5]
row[18]=house_desc.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('\r', '')
row[12]=address.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('\r', '')
row[5] = house_area.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('平', '')
house_decora=row[6]
toward=row[7]
floor=row[8]
floor_height=row[9]
row[6] = house_decora.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('\r', '')
row[7] = toward.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('\r', '')
row[8] = floor.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('\r', '')
row[9] = floor_height.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('\r', '')
# 情感分析
try :
s = SnowNLP(row[18][0:30])
# print(s.words) # 返回分词结果
# join = '|'.join(s.words)
# print(join)
print(s.sentiments) # 返回该句话的情感得分
sentiments = s.sentiments
except :
print('nlp分类报错')
sentiments=0
house_pay=row[1]
house_desc=row[1]
row[1] = house_pay.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('元/月', '')
if house_pay==' ' or len(house_pay)==0:
errors=errors+1
print('租金异常',house_pay)
continue
if ',' in address or '"' in address :
print('异常数据',address,row)
row[12]=address.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('','')
errors=errors+1
if floor_height==' ' and len(floor)>0:
print('floor_height空值处理',row)
row[9]=floor.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('层', '')
errors = errors + 1
elif floor_height==' ' and len(floor)==0 :
errors = errors + 1
continue
else :
row[9] = floor_height.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('', '').replace('层', '')
if agent_name==' ':
print('agent_name空值处理',row)
row[15]='暂无经纪人(新发布)'
errors = errors + 1
else :
row[15] = agent_name.strip().replace(',', '|').replace('"', '').replace("\n", '').replace('', '').replace('(经纪人)', '')
row.append(sentiments)
rent_file = open("rent.csv", mode="a+", newline='', encoding="utf-8")
rent_writer = csv.writer(rent_file)
rent_writer.writerow(row)
rent_file.close()
print('处理非法行数:',errors)


















 8434
8434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











