




1.爬虫,用python爬取游戏网站的各种游戏数据存储到mysql(游戏信息; 区,服,阵营; 游戏商品,与游戏对应)
这三类都要爬取到对应的表
游戏接口说明:XXXXXX
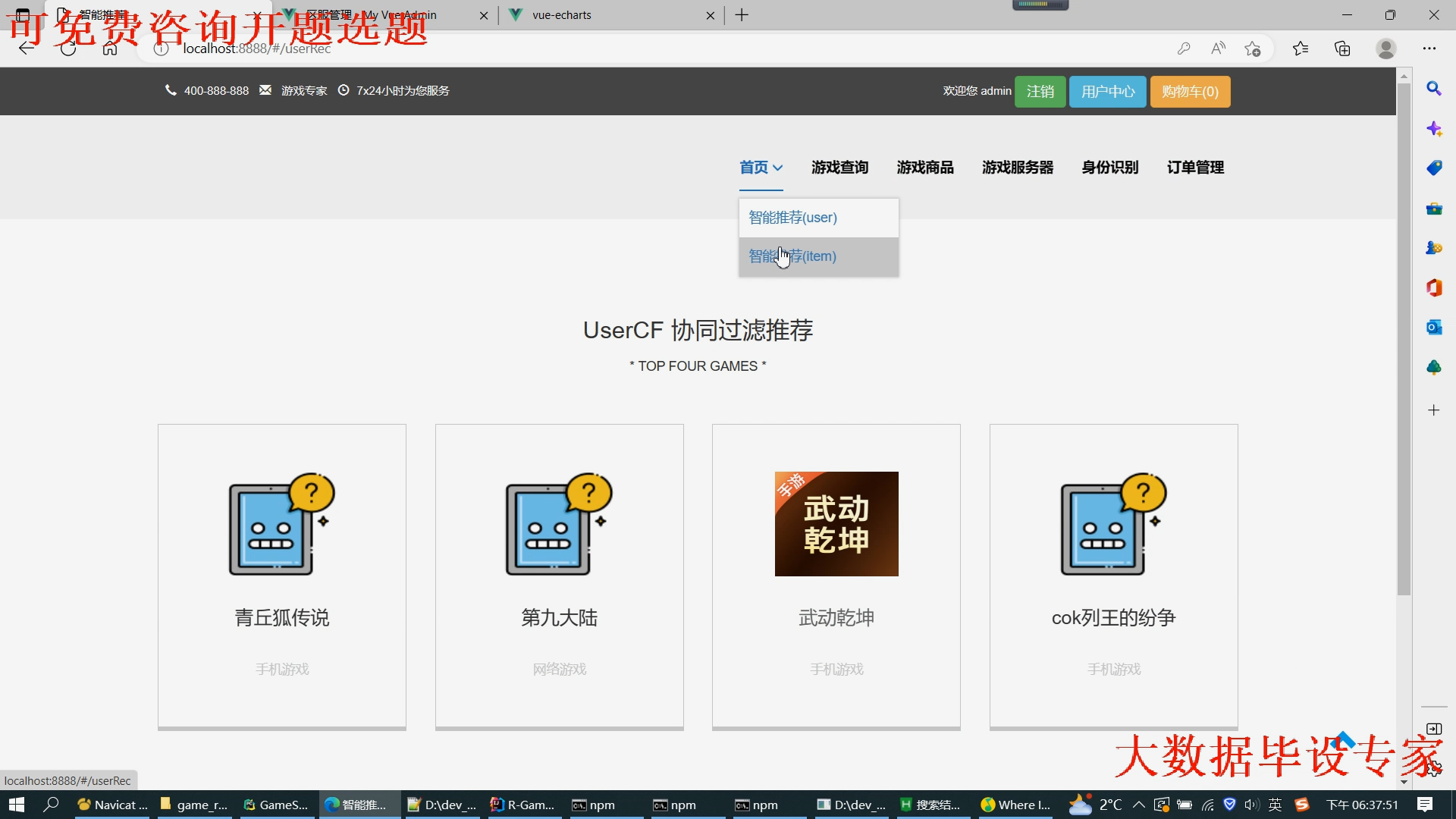
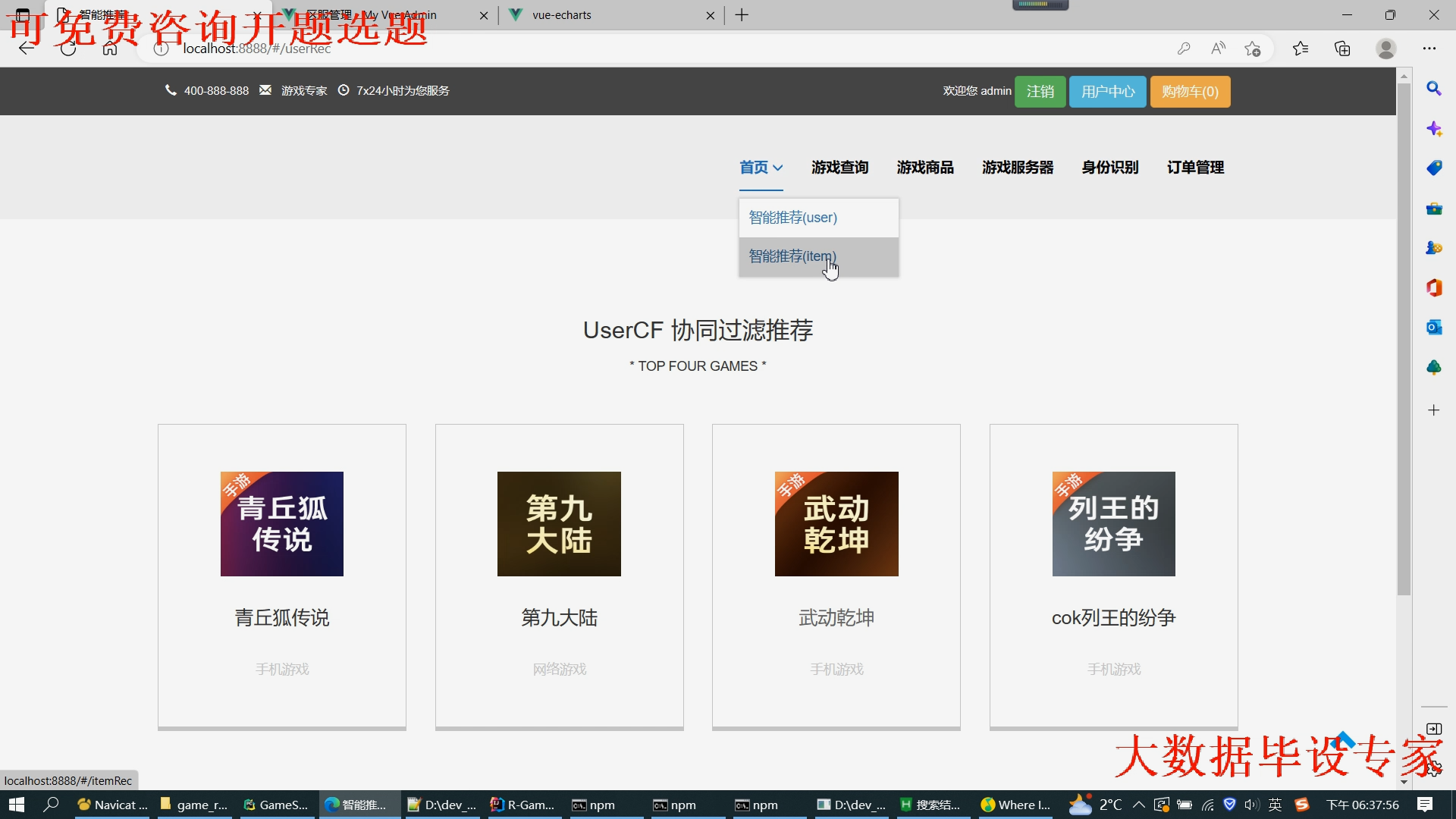
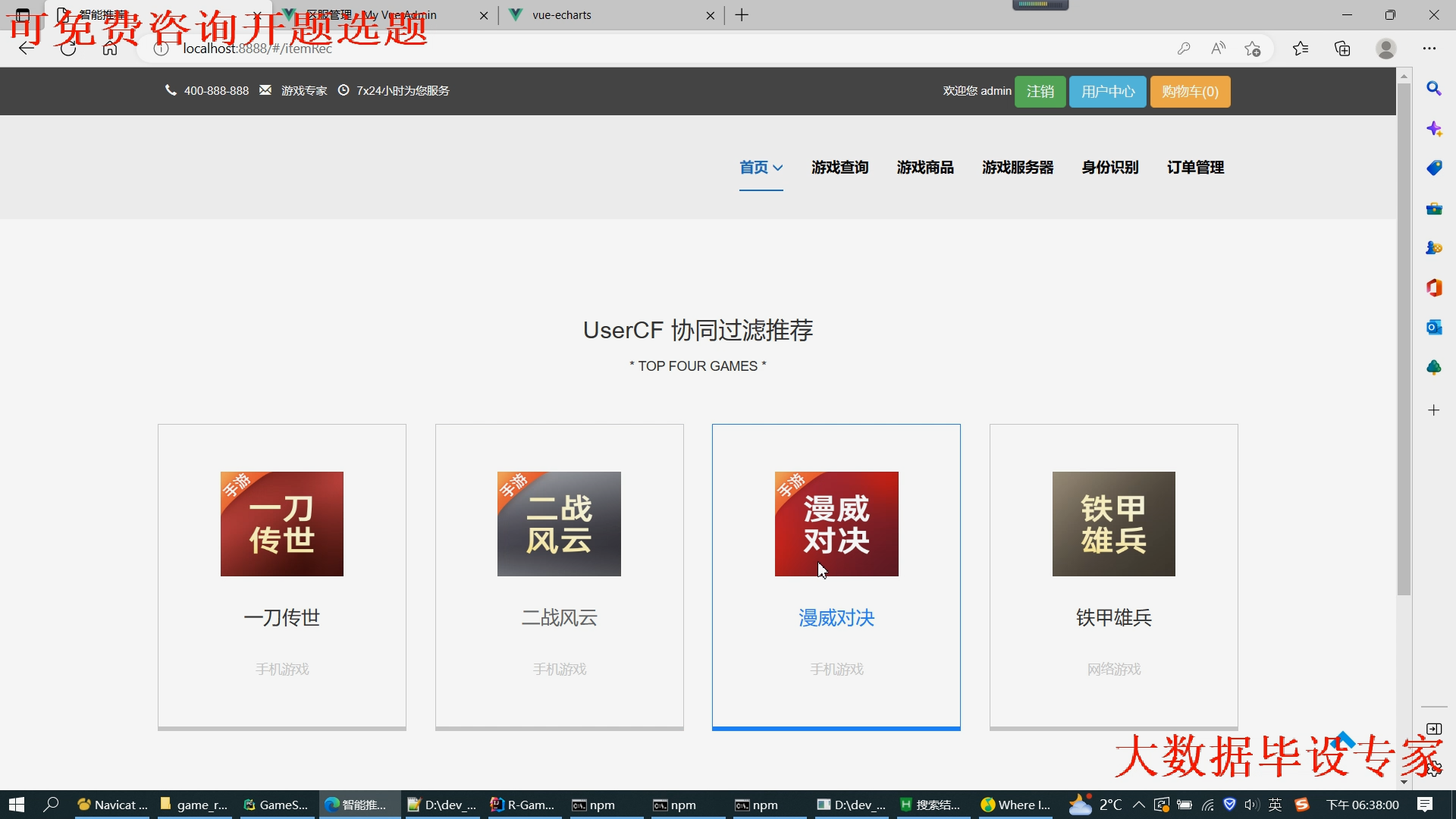
2.门户系统:提供三种推荐算法推荐游戏(同时点击游戏详情可以去浏览这个游戏配套的商品);
可以各种条件搜索游戏商品(游戏金额、游戏名称、等等);
可以下单购买游戏对应的游戏商品(支付宝沙箱支付);
查看订单;
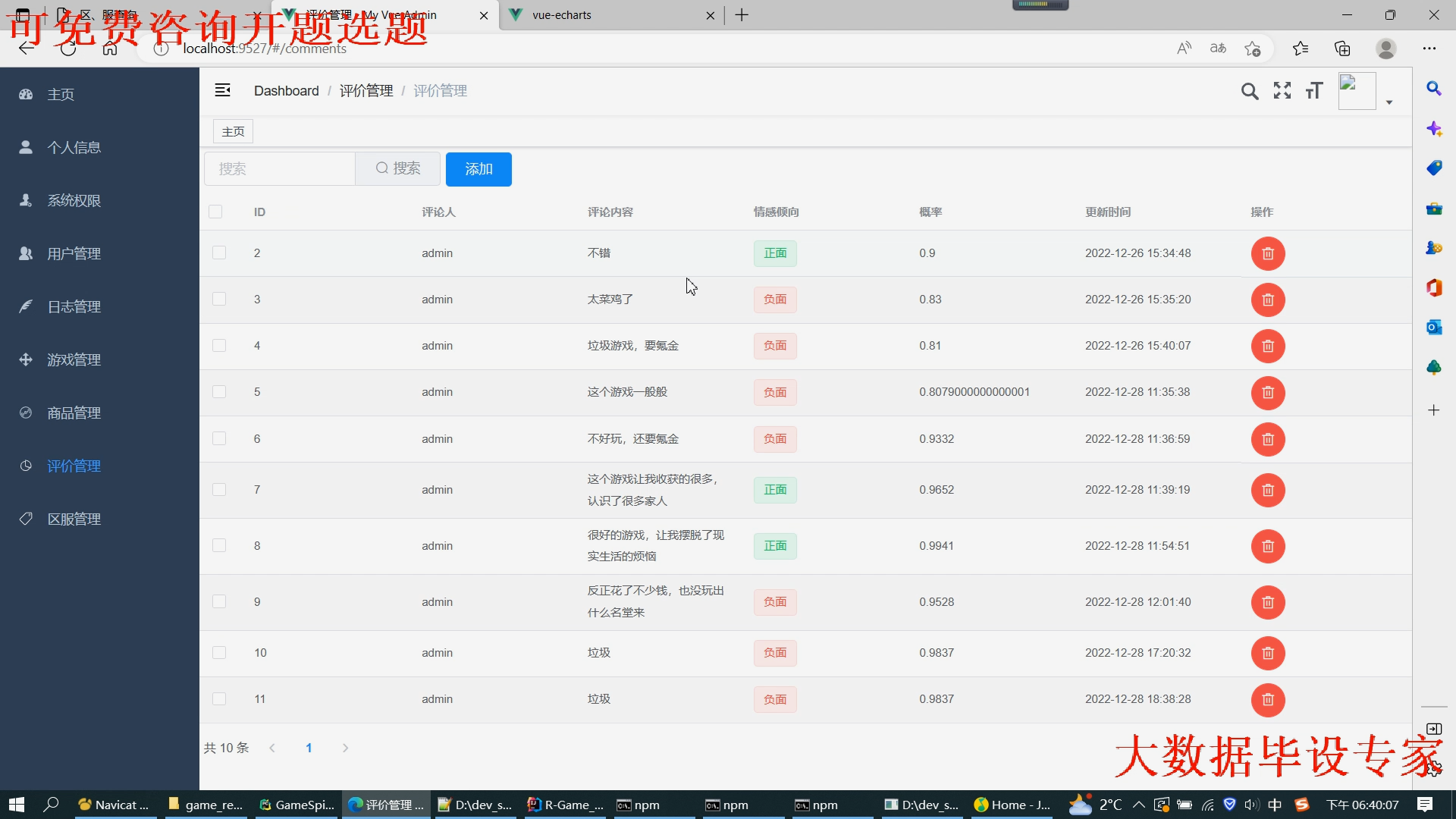
评论可以lstm情感分析;
查看游戏详情可关联到评论;
论坛模块发布者发布时可以关联到对应的游戏发起讨论,
评论均可以情感分析并且显示到门户页面给其他用户看到
(包含情感分数、情感倾向等各种彰显机器学习的维度数据)
短信注册
识别身份证
3.后台系统:前台各种模块的增删查改
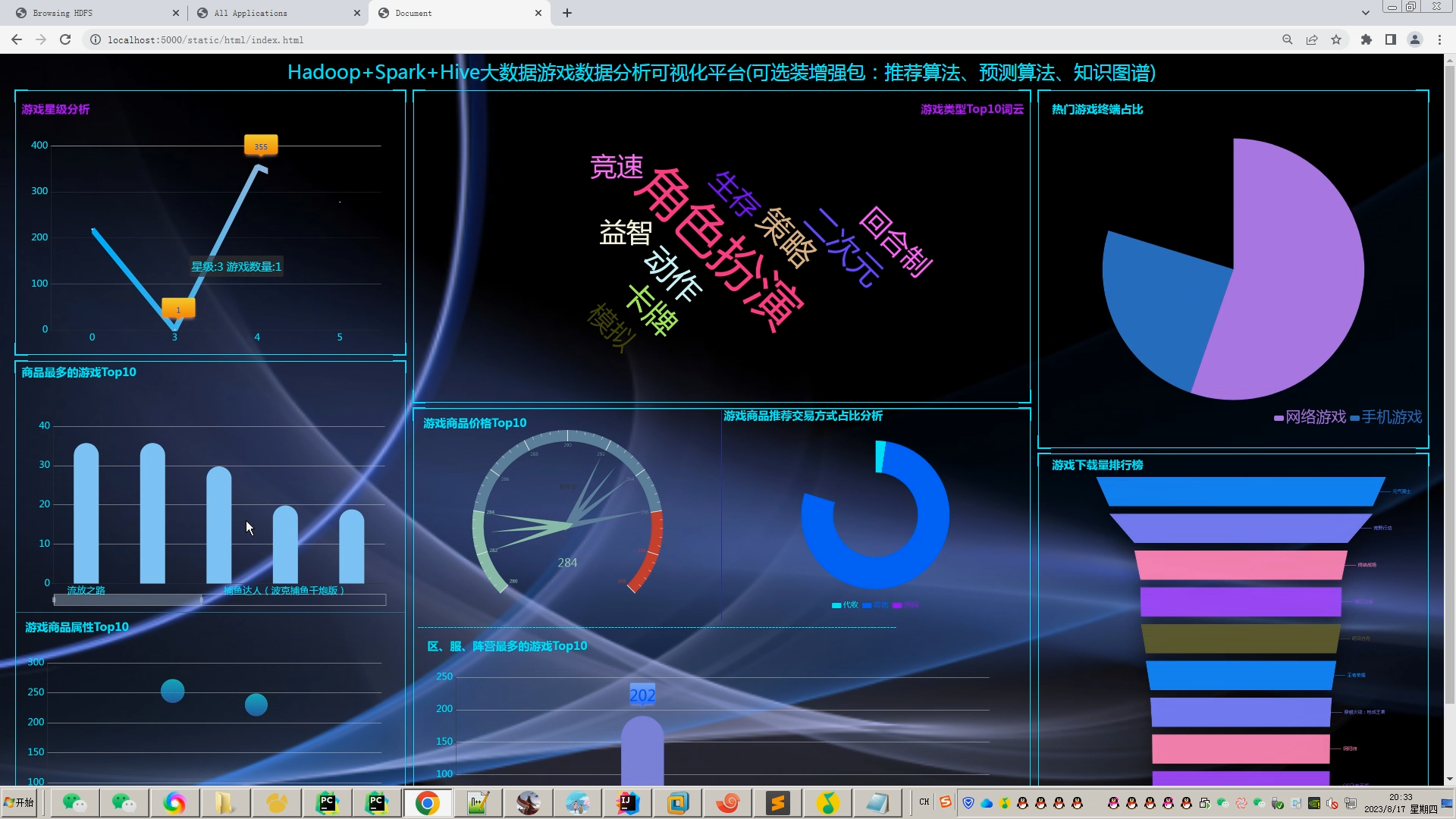
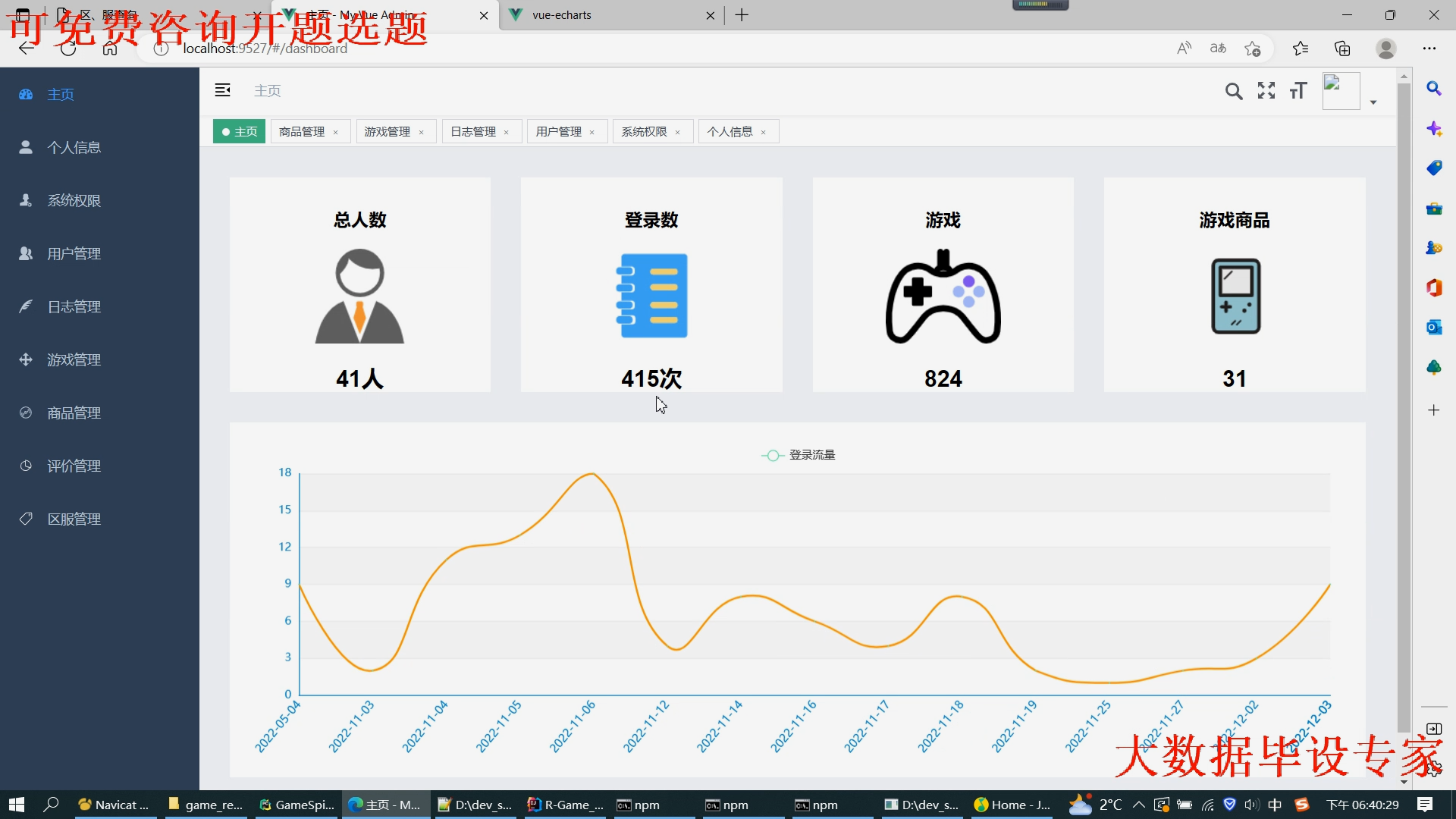
4.Spark大屏,使用最新的UI,数据尽量符合游戏相关的业务(带评论的情感词云)
框架:python+spark+springboot+vue
门户系统最好更新下UI好看点
推荐算法都用java去调用python机器学习脚本

核心算法代码分享如下:
def get_good():
url = 'XXXXXXXXXXX'
for game in get_games():
game_id = game[1]
print(game_id)
params = {
'parentId': game_id,
}
data = p.urlencode(params)
url = url + data
response = requests.get(url)
json_data = json.loads(response.text)
print(json_data)
if json_data['StatusData']['ResultData'] is None:
continue
goods = json_data['StatusData']['ResultData']['GameGoodsType']
# print(goods)
for good in goods:
print(good)
sql2 = "select count(1) from tb_game_good where gid = '%s'" % good['Id']
cursor = db.cursor()
cursor.execute(sql2)
count = cursor.fetchone()
if count[0] > 0:
print('已存在')
else:
sql3 = "insert into tb_game_good(gid, gameid, name, isall, customlink" \
",isenabled, recommendways, supportransactionmode, update_time,price) " \
"values ('%s', '%s', '%s', %d, '%s', %d, %d, '%s', '%s', %f) " %\
(good['Id'], game_id, good['Name'], good['IsAll'],
good['CustomLink'], good['IsEnabled'], good['RecommendWays'], good['SupportTransactionMode'],
datetime.date.today().strftime("%Y%m%d"), random.randint(50,300) )
cursor = db.cursor()
cursor.execute(sql3)
db.commit()
if __name__ == '__main__':
# 要爬取游戏,先清空游戏表
# truncate table tb_game;
get_game()
# 爬取游戏对应的区、服或者阵营
# get_district()
# 爬虫游戏对应的商品
# get_good()



















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











