




申报人: 职称:
|
题目名称:基于大数据的美食推荐系统的设计与实现 | |||||
|
课 题 性 质 |
课 题 来 源 | ||||
|
是否联系实际 |
是 |
自选课题 | |||
|
毕业设计(论文)和 毕业实习主要场所 |
校外 |
毕业设计(论文) 周数 |
24 | ||
|
课题主要研究内容及预期达到的目标: 本课题旨在通过设计一种基于大数据技术的美食推荐系统帮助解决本地美食的推广与智能推荐问题。预期用户可以通过网站首页进行美食搜索、个性化美食推荐、支付宝下单、美食点评等功能。管理员能够登录后台管理系统进行美食管理、美食知识图谱查看、评价管理等数据维护。Python爬虫可以采集美团约1W条本地美食数据。用户可以直观观看可视化统计大屏。 | |||||
|
课题研究的工作基础或实验条件: 工作基础:使用Python爬虫采集美团APP本地美食数据作为基础数据集 开发环境:IDEA、navicat_for_mysql、jdk1.8、maven、mysql、nodejs | |||||
|
课题所涉及的知识: 注意:可以写开发所用的框架、开发所用的语言、开发所用的数据库以及使用到的其他专业知识(如推荐系统、深度学习)等。 样例:前端开发框架采用Vue.js和ElementUI,后端开发框架采用SpringBoot,数据库采用MySQL,前端开发语言主要采用HTML、JavaScript,后端开发语言主要采用Java,使用神经网络混合推荐算法进行个性化美食推荐。 | |||||
|
专业核心组意见: 专业核心组组长签字: 年 月 日 |
学院审批意见: 教学院长签字: 年 月 日 | ||||
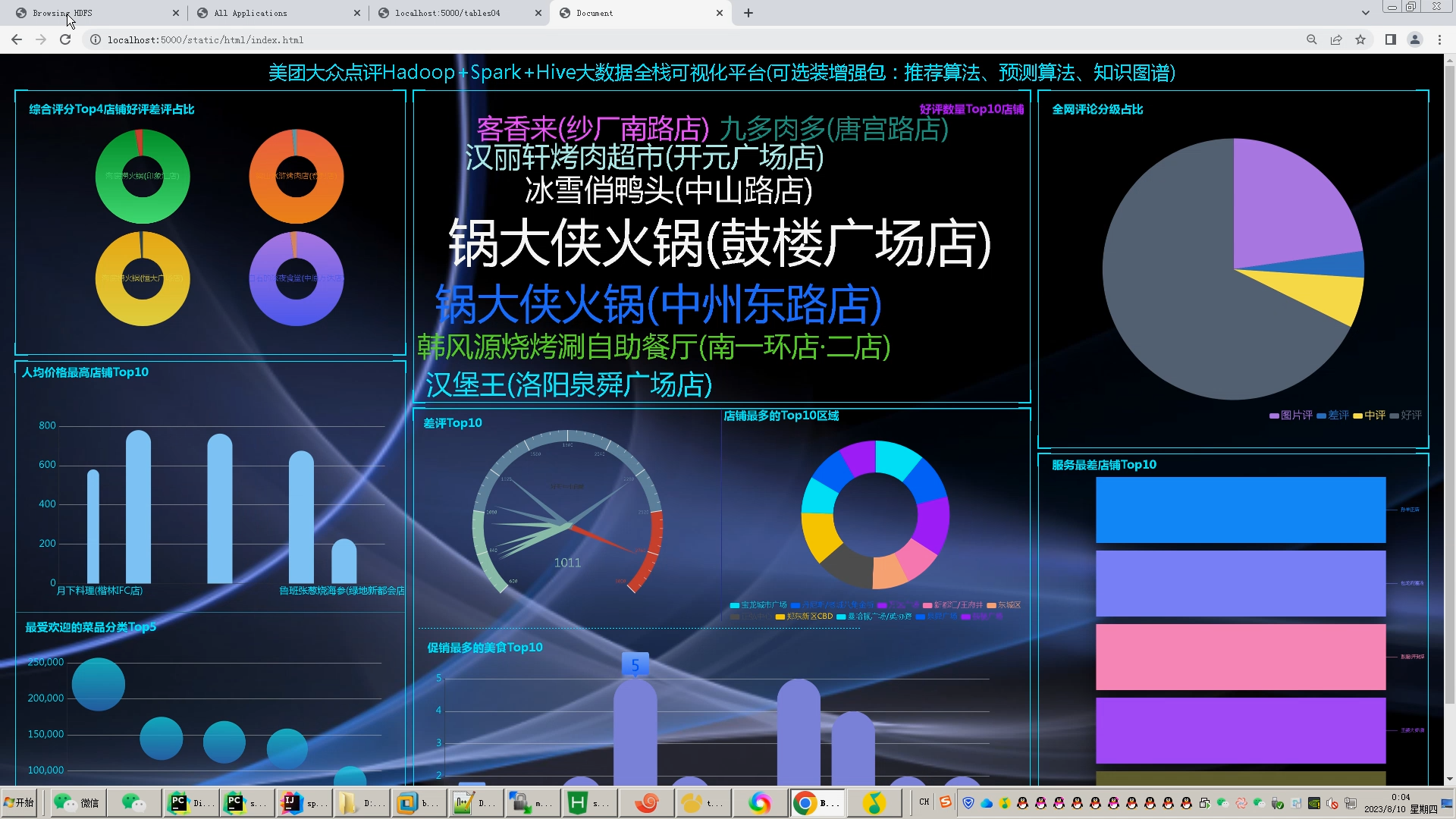


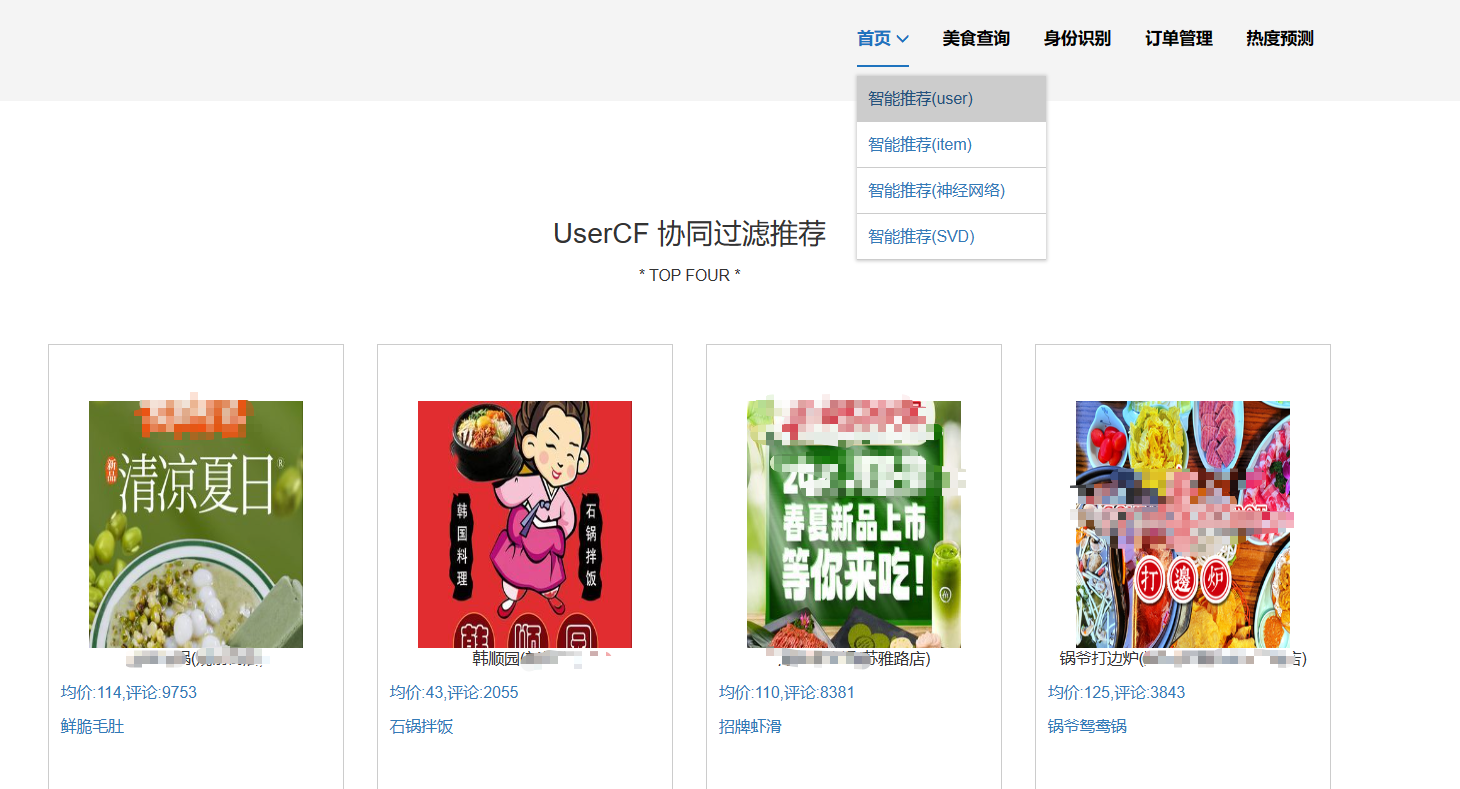
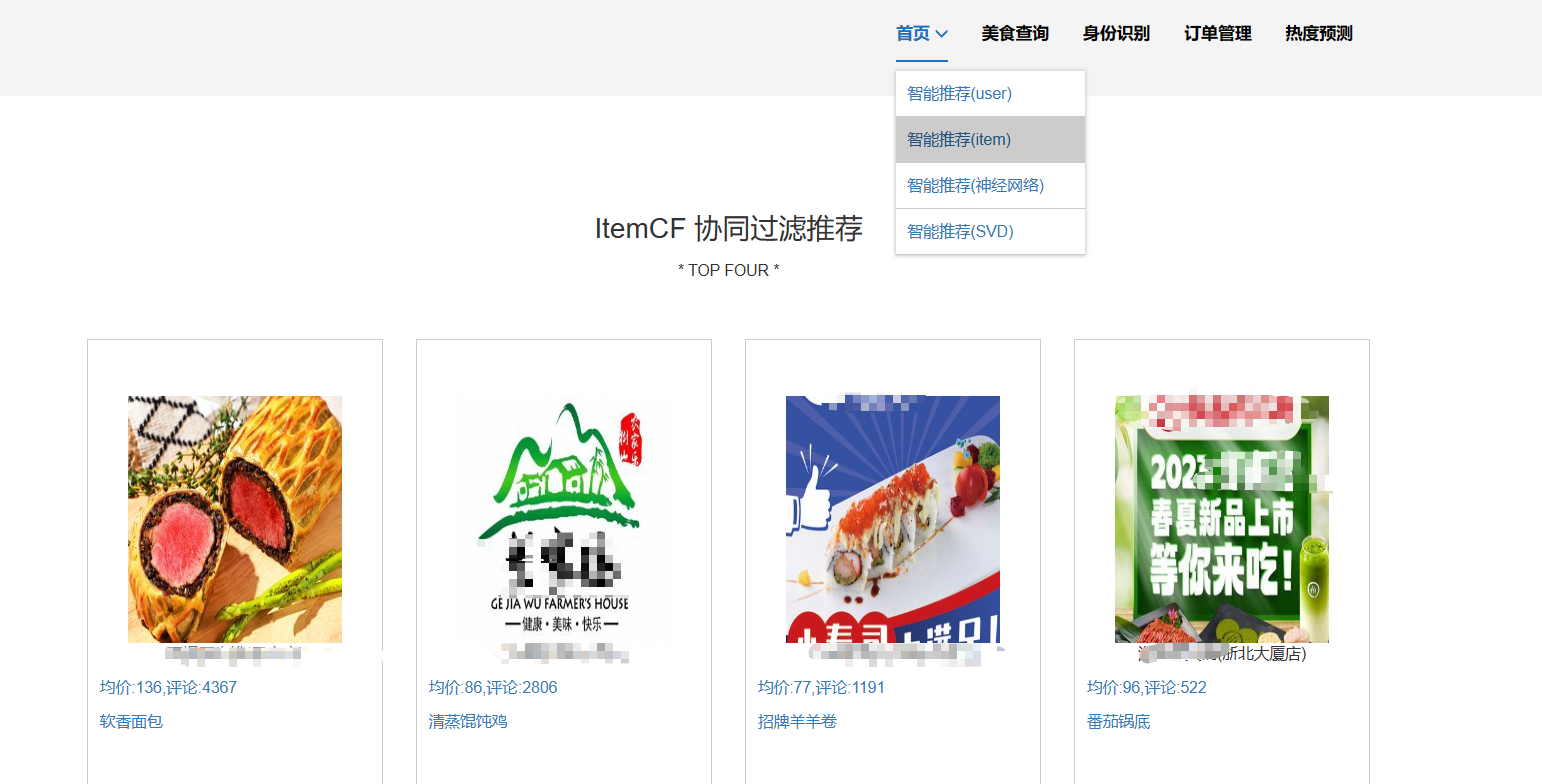
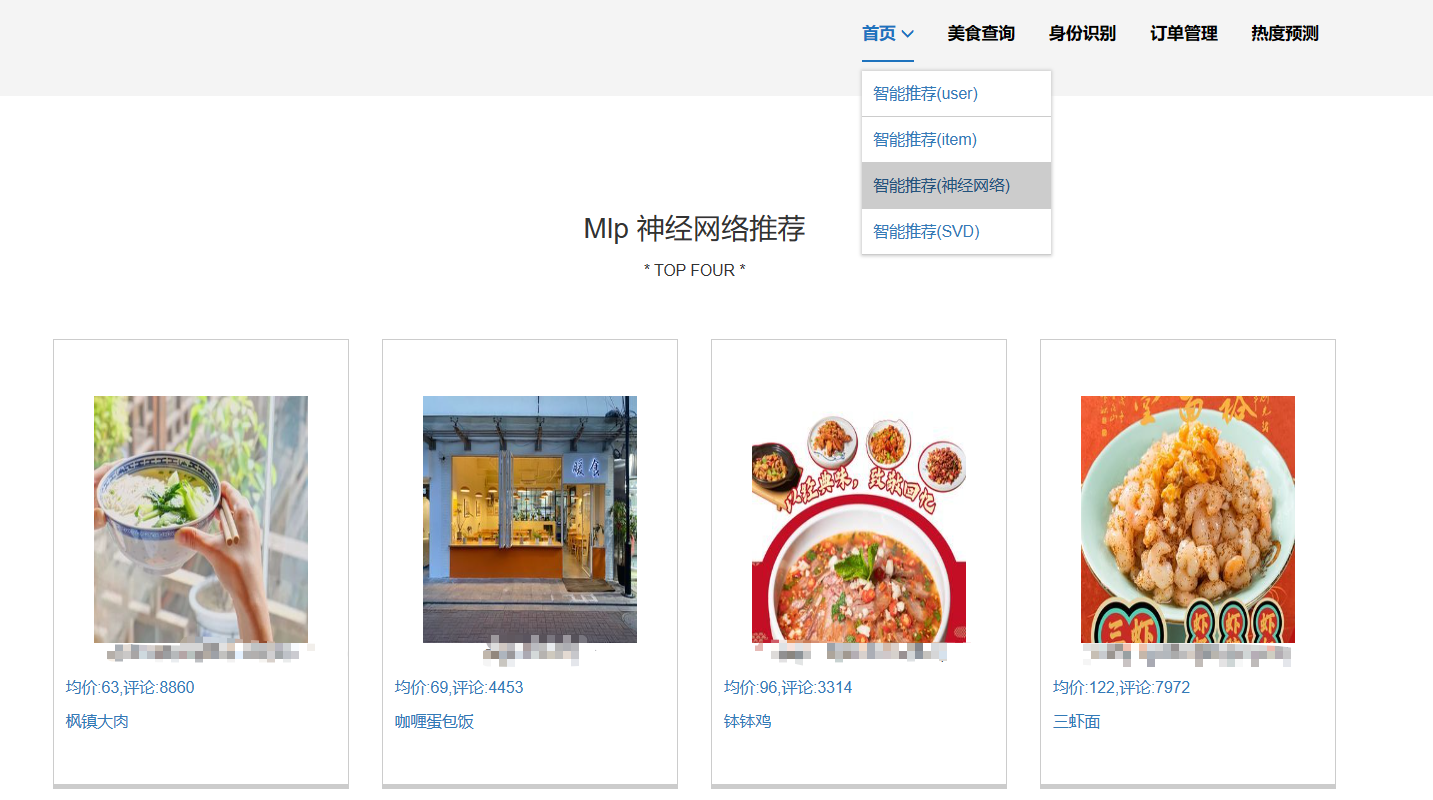
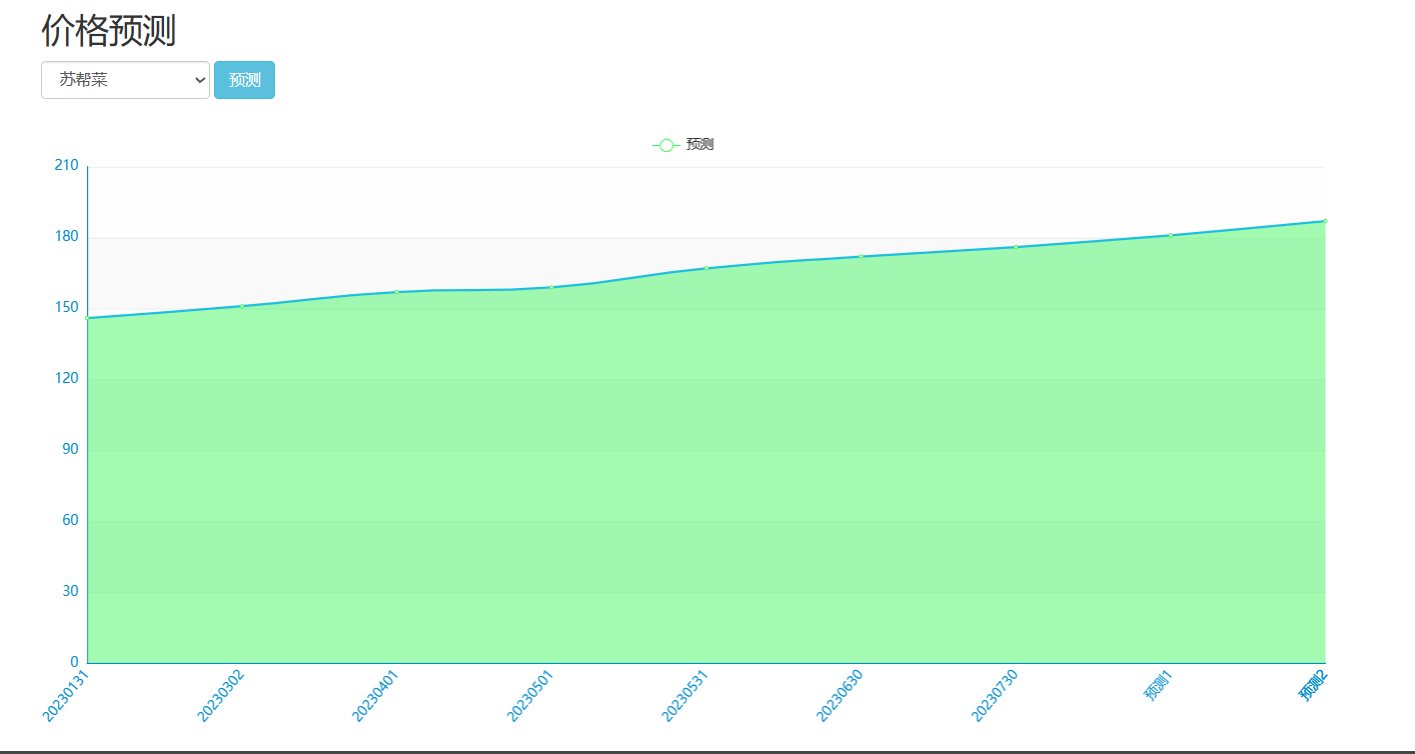

核心算法代码分享如下:
package com.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.junit.Test
import java.util.Properties
class MeituanSpark {
val spark = SparkSession.builder()
.master("local[6]")
.appName("美团Spark实时计算")
.getOrCreate()
val schema = StructType(
List(
StructField("shop_id", StringType),
StructField("shop_name", StringType),
StructField("total_score", FloatType),
StructField("goods",IntegerType),
StructField("mids", IntegerType),
StructField("bads", IntegerType),
StructField("imgs",IntegerType),
StructField("price", IntegerType),
StructField("reviewCount", IntegerType),
StructField("taste_score", FloatType),
StructField("env_score", FloatType),
StructField("serv_score", FloatType),
StructField("tese_tuan", StringType),
StructField("tese_cu", StringType)
)
)
//val df = spark.read.option("header", "true").schema(schema).csv("G://sparksqlnk02//dataset//lvyou.csv")
val df = spark.read.option("header", "true").schema(schema).csv("hdfs://192.168.227.166:9000/ods_shop_detail/shop_detail2023.csv")
//val df = spark.read.option("header", "true").schema(schema).
val df1 = df.na.drop()
@Test
def init(): Unit = {
df.show()
}
@Test
def head(): Unit = {
df1.show()
}
// ----剩余指标8 指标9走Spark实时计算
//
// ---服务得分最差的十个店铺
@Test
def tables08(): Unit = {
df.createOrReplaceTempView("ods_shop_detail")
val df2 = spark.sql(
"""
select shop_name,serv_score
from ods_shop_detail
order by serv_score asc
limit 10
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2408_meituan?useSSL=false",
"table08",
new Properties()
)
}
// ----剩余指标8 指标9走Spark实时计算
// ---好评、差评、中评、图片评论占比扇形图
@Test
def tables09(): Unit = {
df.createOrReplaceTempView("ods_shop_detail")
val df2 = spark.sql(
"""
select '好评' name,sum(goods) from ods_shop_detail
union
select '中评' name,sum(mids) from ods_shop_detail
union
select '差评' name,sum(bads) from ods_shop_detail
union
select '图片评' name,sum(imgs) from ods_shop_detail
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/2408_meituan?useSSL=false",
"table09",
new Properties()
)
}
}


















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











