




 本文研究了如何利用大数据和K-means算法设计一个微博热点话题分析管理系统,通过信息采集、预处理和智能分析,实现舆情的高效分析和可视化,以支持突发事件舆情管理和决策制定。
本文研究了如何利用大数据和K-means算法设计一个微博热点话题分析管理系统,通过信息采集、预处理和智能分析,实现舆情的高效分析和可视化,以支持突发事件舆情管理和决策制定。
摘 要
随着计算机技术的发展,信息化建设在各领域内的应用,给人们的生活带来了很大的影响,转变了人们的思维模式和生活方式。信息化技术也在逐步影响着微博热点话题分析管理的方式。随着互联网的发展,网络信息正以惊人的速度增长,成为了有史以来最大的信息库。在面对如此海量的微博数据时,如何挖掘有价值的信息,尤其是把握民意的突发事件舆情是关键的问题,影响着社会的稳定。因此,对于民意的微博热点话题分析管理系统的研究具有重要的意义。
本文是对微博热点话题分析管理系统的设计研究,主要研究内容为:
- 通过分析系统的需求,设计总体方案,进行系统的设计实现,依照该思路进行了论文的展开,完成了民意突发事件舆情分析系统的架构设计,对于系统中的数据库以及业务流程进行了详细的介绍。
- 对系统进行设计与实现,实现的系统更主要包括了:信息采集模块、信息预处理模块、智能分析处理模块、微博热点话题分析模块。借助于spark平台在海量数据存储和数据挖掘方面的能力,设计一套微博热点话题分析管理系统。在数据采集模块,通过网络爬虫对于国民的微博数据进行采集。这些数据通过处理、去重之后,得到便于后续处理的数据。在数据预处理模块,利用TF-IDF算法进行特征向量空间的建立。对于采集的原始数据进行分析与处理,对于访问公网的数据消除网页噪音数据,依据分词技术,对于访问的内容进行分解,产生摘要信息,然后进行归类。智能分析模块,对于内容倾向性的分析,其核心就是文本的聚类,聚类的结果也直接决定了微博热点话题分析管理系统分析的结果。微博热点话题分析模块,是依据分类的大小,对于文章的点击量以及评论数等信息计算文章的热度,进行将热点的话题选择出来,依据时间段中的热点度增量的变化,进行突发事件舆情趋势的分析。
- 从平台的问答互动中采集正文信息,然后对信息进行预处理、语义处理、内容识别,获得有价值的信息,呈现可视化分析结果,为及时发现热点、把握突发事件舆情趋势、应对突发事件舆情危机提供自动化、系统化、科学化的信息支持。
关键词:大数据;微博热点话题分析管理;数据挖掘;K-means
1 绪论
1.1 研究目的及意义
1.1.1 研究目的
提升舆情分析的效率和精度:通过可视化建模,可以将大量的舆情数据以直观的方式呈现出来,便于分析和理解。这不仅可以提高舆情分析的效率,还能提升分析的精度,更好地把握舆情的真实情况和演变趋势。
发现舆情传播规律和关键因素:通过可视化建模,可以发现舆情传播的规律和关键因素,如传播路径、影响力较大的节点、舆论场中的热点话题等。这有助于深入了解舆情传播的内在机制,为制定有效的应对策略提供依据。
评估舆情引导效果和预测未来走势:通过可视化建模,可以对舆情引导的效果进行评估,如传播范围、用户反馈、态度变化等。同时,可以对未来的舆情走势进行预测,为决策者制定长远规划和政策提供支持。
优化媒体内容生产和用户运营策略:通过可视化建模,可以深入了解用户对媒体内容的偏好和需求,从而优化内容生产和用户运营策略。例如,根据用户的兴趣和行为特征,制定个性化的内容推荐和营销策略,提高用户黏性和活跃度。
促进跨学科交流和合作:舆情可视化建模涉及到计算机科学、信息管理、新闻传播等多个学科领域。通过研究,可以促进跨学科的交流和合作,推动相关学科的发展和创新。
总之,微博舆情可视化建模方法研究目的在于提升舆情分析的效率和精度,发现舆情传播规律和关键因素,评估舆情引导效果和预测未来走势,优化媒体内容生产和用户运营策略,促进跨学科交流和合作等方面。
1.1.2 研究意义
提升舆情分析的效率和精度:舆情信息可视化可以直观地呈现大量数据,有助于用户快速理解和分析舆情数据,提高舆情分析的效率和精度。
发现舆情传播规律和关键因素:通过可视化建模,可以清晰地观察到舆情传播的路径、影响力较大的节点和热点话题,有助于深入了解舆情传播的内在机制,发现舆情传播的规律和关键因素。
评估舆情引导效果和预测未来走势:通过可视化建模,可以全面评估舆情引导的效果,如传播范围、用户反馈和态度变化等。同时,通过对未来舆情走势的预测,可以为决策者制定长远规划和政策提供支持。
优化媒体内容生产和用户运营策略:通过可视化建模,深入了解用户对媒体内容的偏好和需求,从而优化内容生产和用户运营策略,提高用户黏性和活跃度。
促进跨学科交流和合作:舆情可视化建模涉及到多个学科领域,如计算机科学、信息管理、新闻传播等。通过研究,可以促进跨学科的交流和合作,推动相关学科的发展和创新。
辅助决策制定:对于企业和政府机构来说,舆情信息可视化可以帮助他们更好地理解公众的观点和情绪,从而做出更明智的决策。
提升公共话语权的公平性:在公共话语权的争夺中,舆情信息可视化可以帮助公众更全面地了解各种观点和立场,提升公共话语权的公平性。
因此,微博舆情可视化建模方法的研究意义重大,不仅可以提升舆情分析的效率和精度,发现舆情传播规律和关键因素,还可以评估舆情引导效果和预测未来走势,优化媒体内容生产和用户运营策略,促进跨学科交流和合作等。
1.2 国内外研究现状
网络舆情是指在互联网环境下针对各种社会问题,多数网民区中所持有的意见和态度。早在上世纪70年代左右,美国著名传媒学者赫伯特·席勒在《大众传播与美利坚帝国》一书中提出“文化帝国主义”这一新颖词汇[1],认为美国利用新型媒体作为媒介来推进其实现文化扩张的行为,是美国政治、军事及外交的多方面综合产物。军事服从于政治,而部队战略又服从于国家政略[2]。自上世纪互联网产生并逐渐发展出社交功能后,西方各国政府也开始注意到互联网舆情在社会层面的作用,并相继开展相关方面研究。其中,美国政府作为社交媒体领域的发源地,一直坐拥着专业技术优势以及世界范围的媒体话语权,长期以来一直专注于挖掘社交媒体对国内社会结构稳定、对外国进行文化及价值观输出过程中所能发挥的作用。如美国著名民调型智库皮尤研究中心(Pew Research Center)便开设有互联网及社会舆情研究项目,实时对美国国内社交媒体舆情实施监测。而美国政府在积极推动全球互联网领域技术革新与信息媒体垄断的同时,也开始指导美国军队建设其网络科技战略威慑能力,强化网络舆情分析能力,发挥网络舆论斗争功能[3]。
而随着互联网在国内影响力日益增大,中国政府及各级党政机关、公司企业机构和国内专项学术机构都越发重视互联网舆情的监控、分析和引导,互联网业俨然成为了党和政府新时代治国理政的重要平台。根据中国互联网络信息中心发布的第45次《中国互联网络发展状况统计报告》,截至2020年3月份,中国网民数量已经超过了9亿[4]。但互联网的低门槛和开放性一定程度上成为公众谣言滋生的地盘。在此环境下,人民日报所属分析机构自2006年起就开始探索网络舆情研究,并于2008年正式创建人民网舆情监测室[5]。在此之中有具备传播学、经济学、公共管理学、社会学、数理统计学等专业背景的舆情分析研究人员50多名,在人民日报社、人民网的上级领导和中国社科院、北京大学、清华大学等单位的专业技术学者的指引下,我国目前已初步形成了一套较完善的网络舆情监测理论体系、工作方法、作业流程和应用技术[6],可以对网络版传统媒体、新闻网页评论回复、各大社交网络平台等网络舆情的主要载体进行全天候监测,并进行专业的数据统计和情况分析,形成监测分析研究成果。而2010年成立于湖南长沙的蚁坊软件公司,通过于国防科技大学计算机学院等多加互联网领域研究机构实施合作,研发出了名为鹰眼速读网的全网舆情监测系统[7],用户对象主要为国家各级政府,其监测范围包括各大社交网络软件及平台,各大新闻网站以及网络社区等。此外,公司旗下自主研发的大数据服务云——Antfact[8],可全天侯对全网舆情信息进行不间断自动收集处理,能够实行全网监测、方便快速阅读并进行综合分析与高效率剪辑,为用户提供网络舆情的实时预警能力,把握舆情发展态势,为使用者的下一步决策提供足够的数据基础[10]。
1.3 主要工作
本课题基本思路是研究通过网络爬虫技术,对微博平台海量突发事件舆情信息实时进行爬取,并将之筛选归类于突发事件舆情信息数据库,利用情感分析技术对其中特定敏感关联词汇进行检索及监测,实现对平台的突发事件舆情监测与分析。目的是为了协助有关网络部门评估突发事件舆情发展态势并进行正确引导。
本论文的主要工作包含以下几个方面:
(1)收集整理国民在微博上的社交数据,为国民的微博热点话题分析管理做准备;
(2)建立微博数据正文信息采集、分析、处理模型,利用建立的知识库知识,推理分析解决平台对系统的特定要求,选择确定最优算法和实现路径;
(3)采用spark作为技术平台,设计并实现友好的人机界面,处理平台信息,得到分析结果。

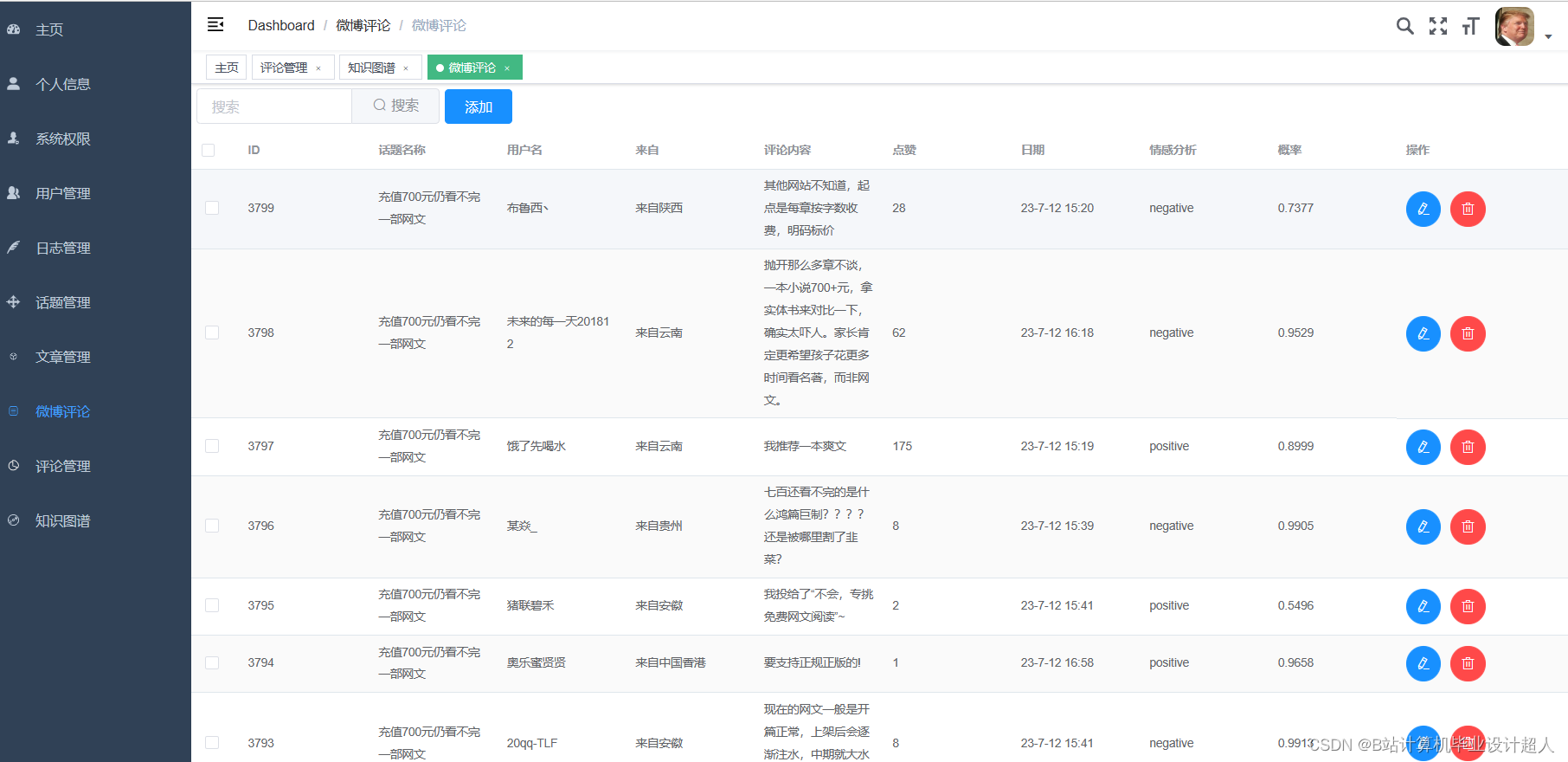
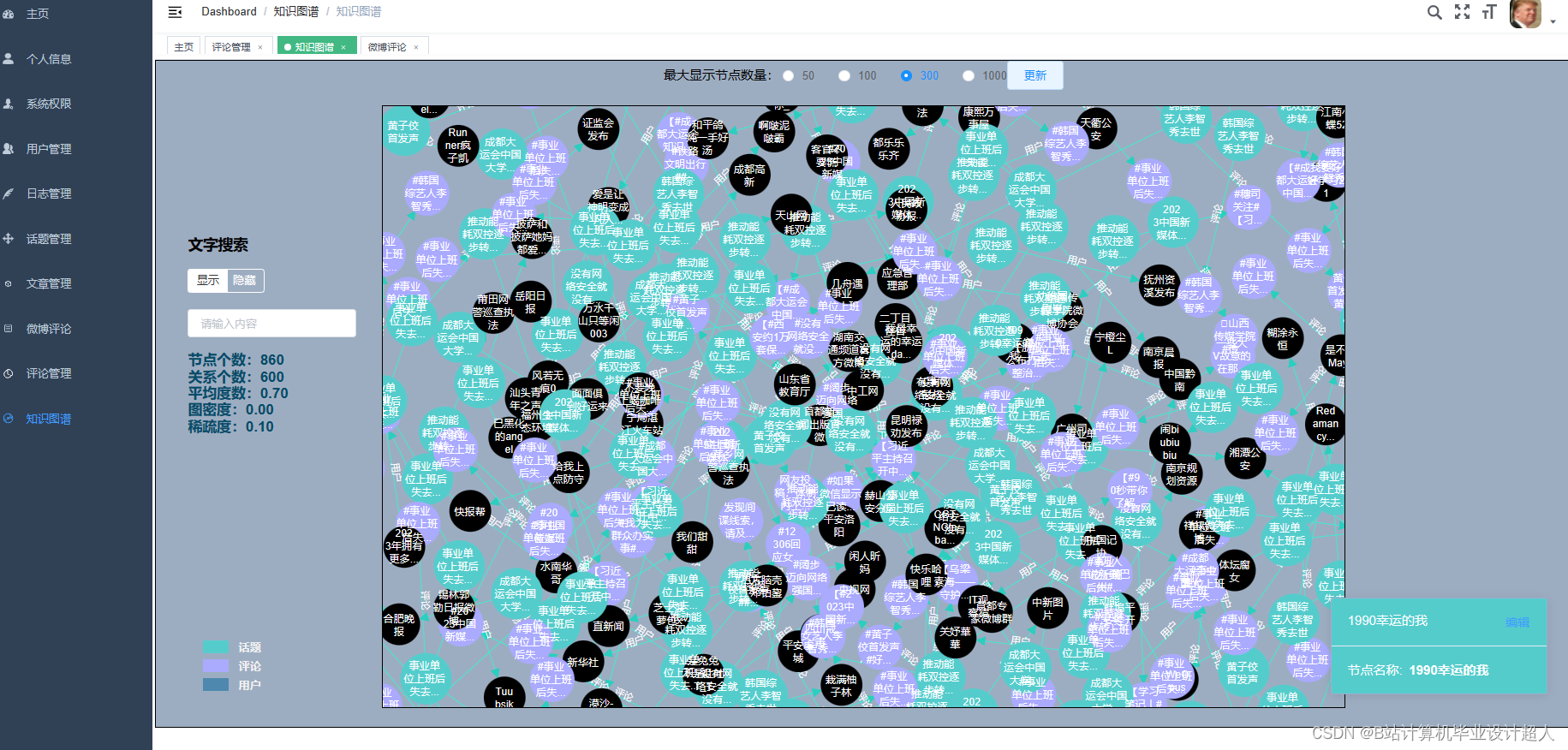
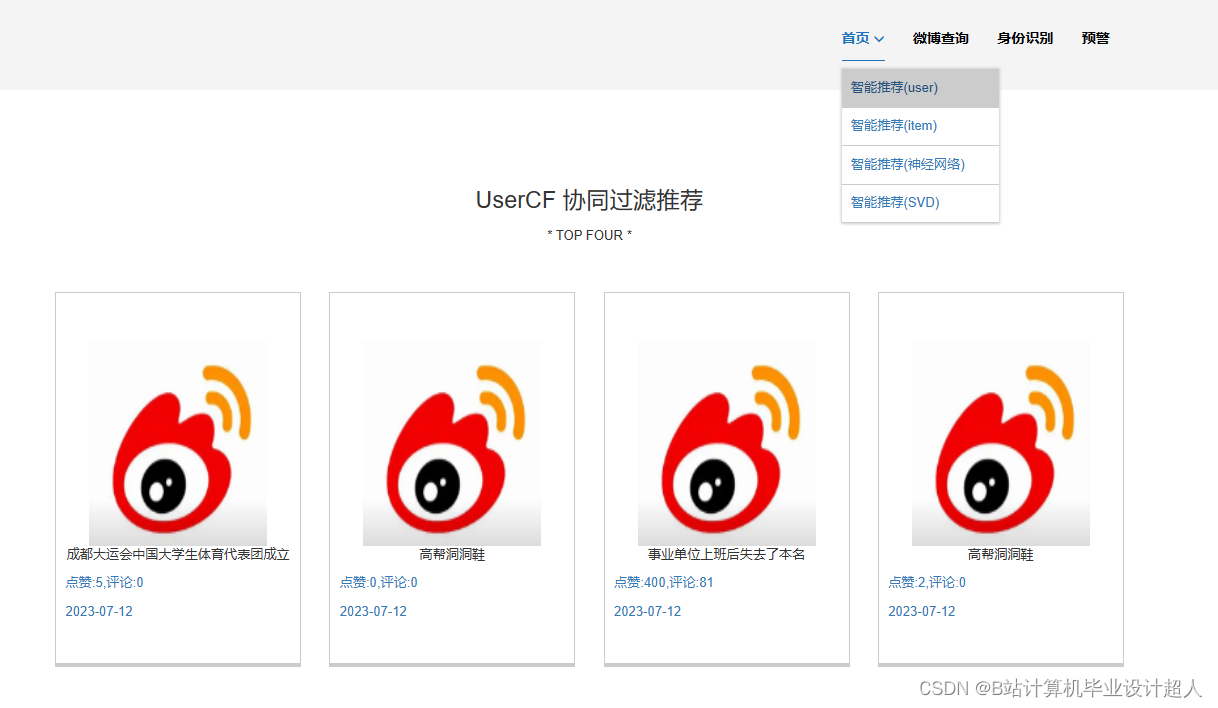
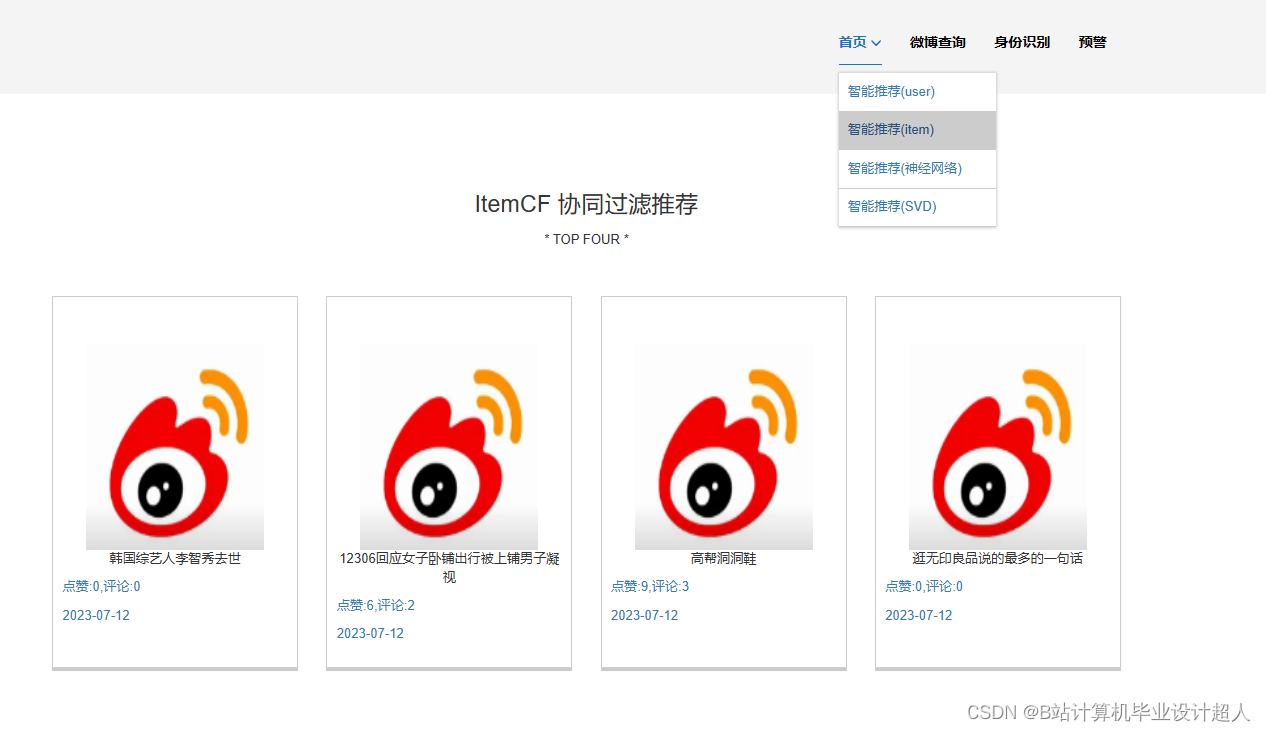
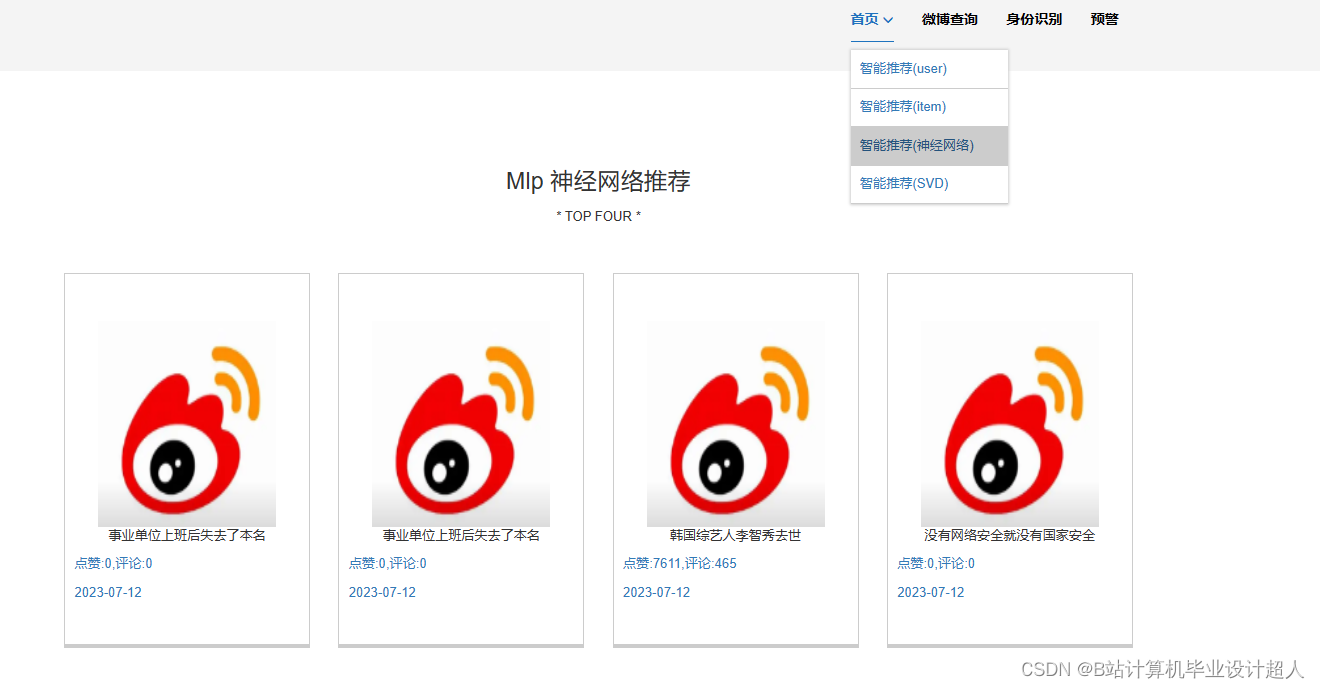
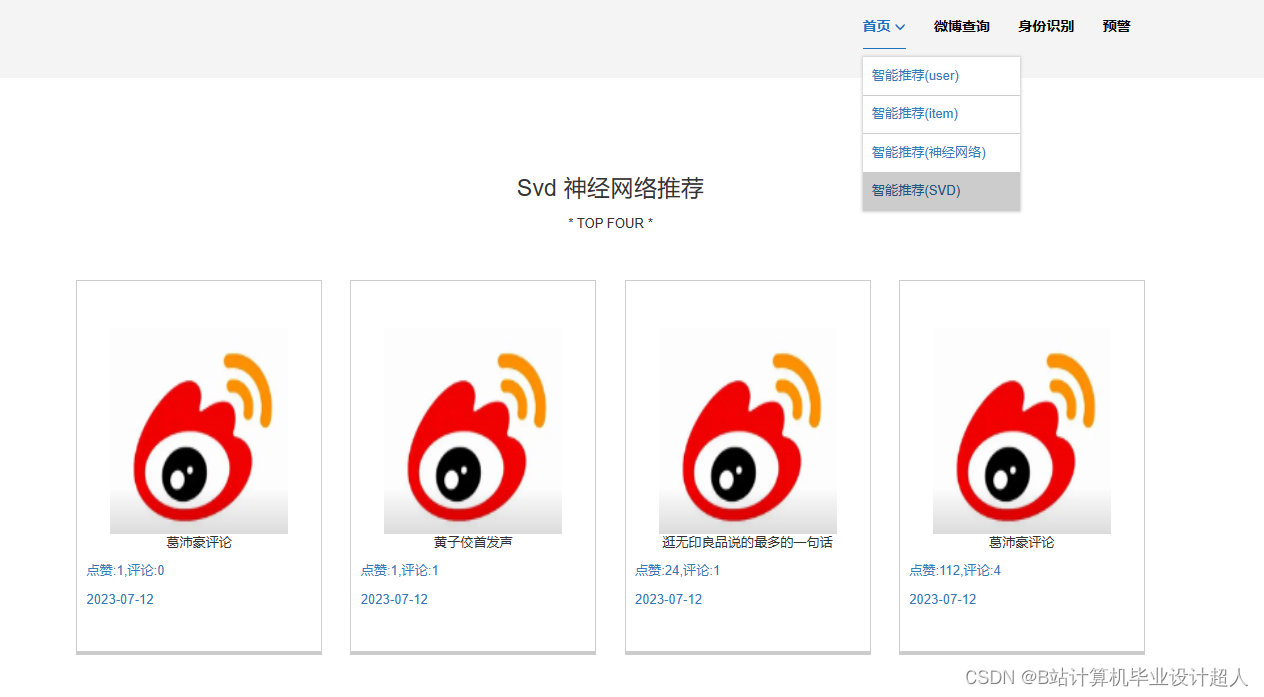
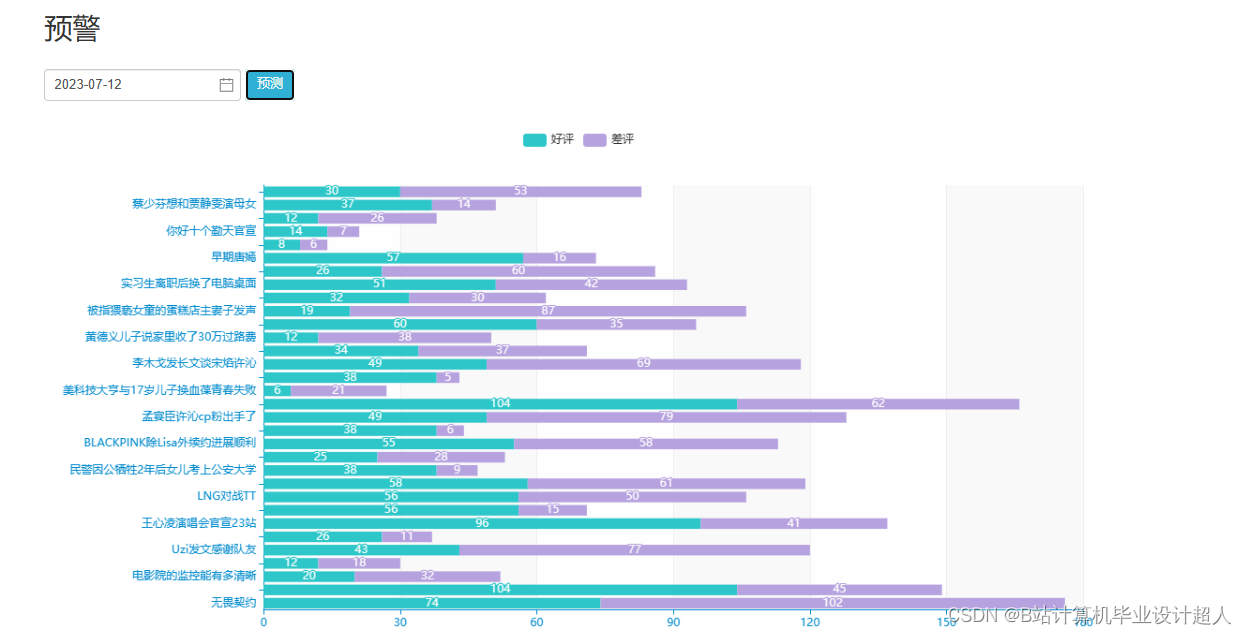
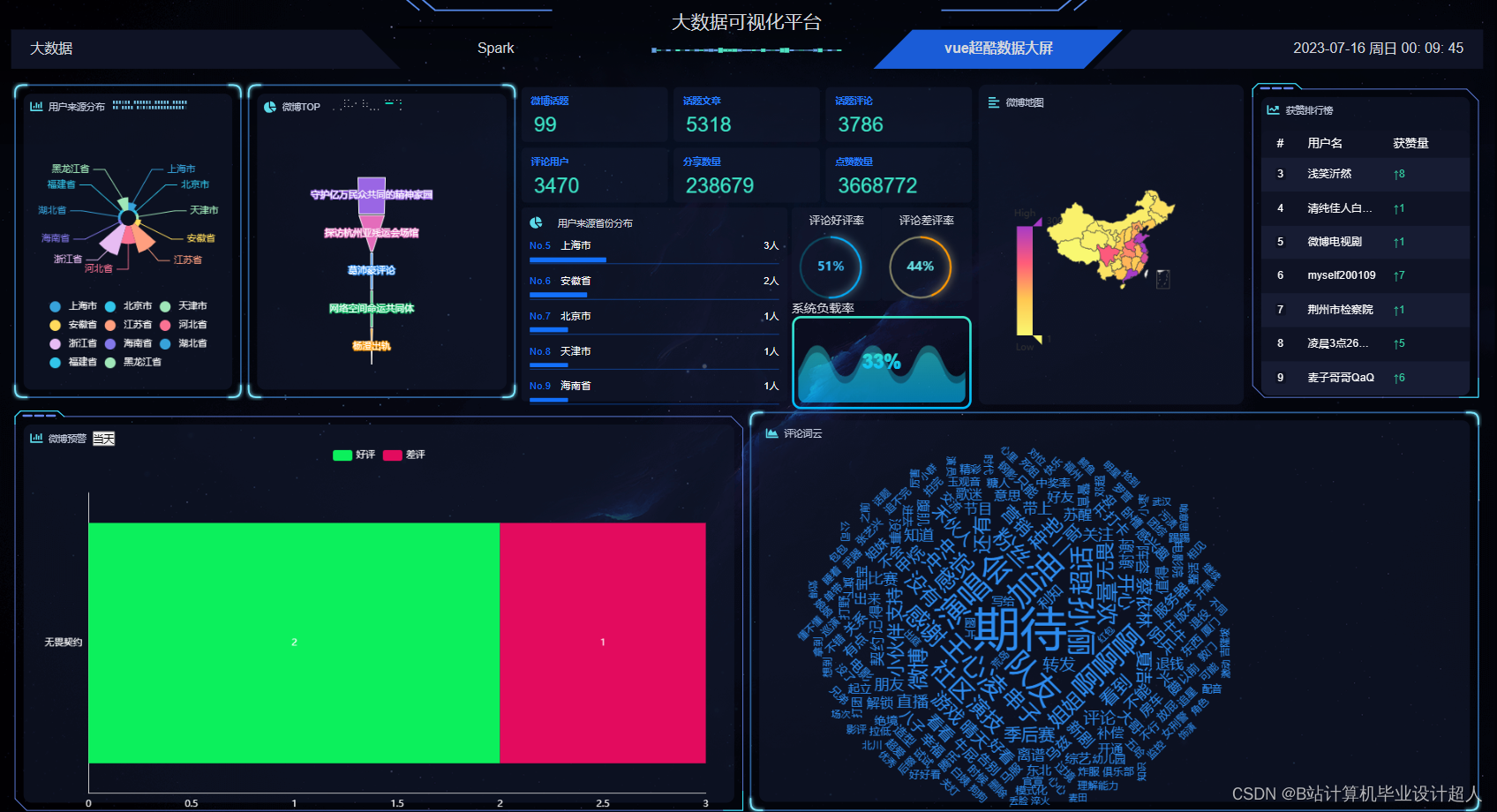
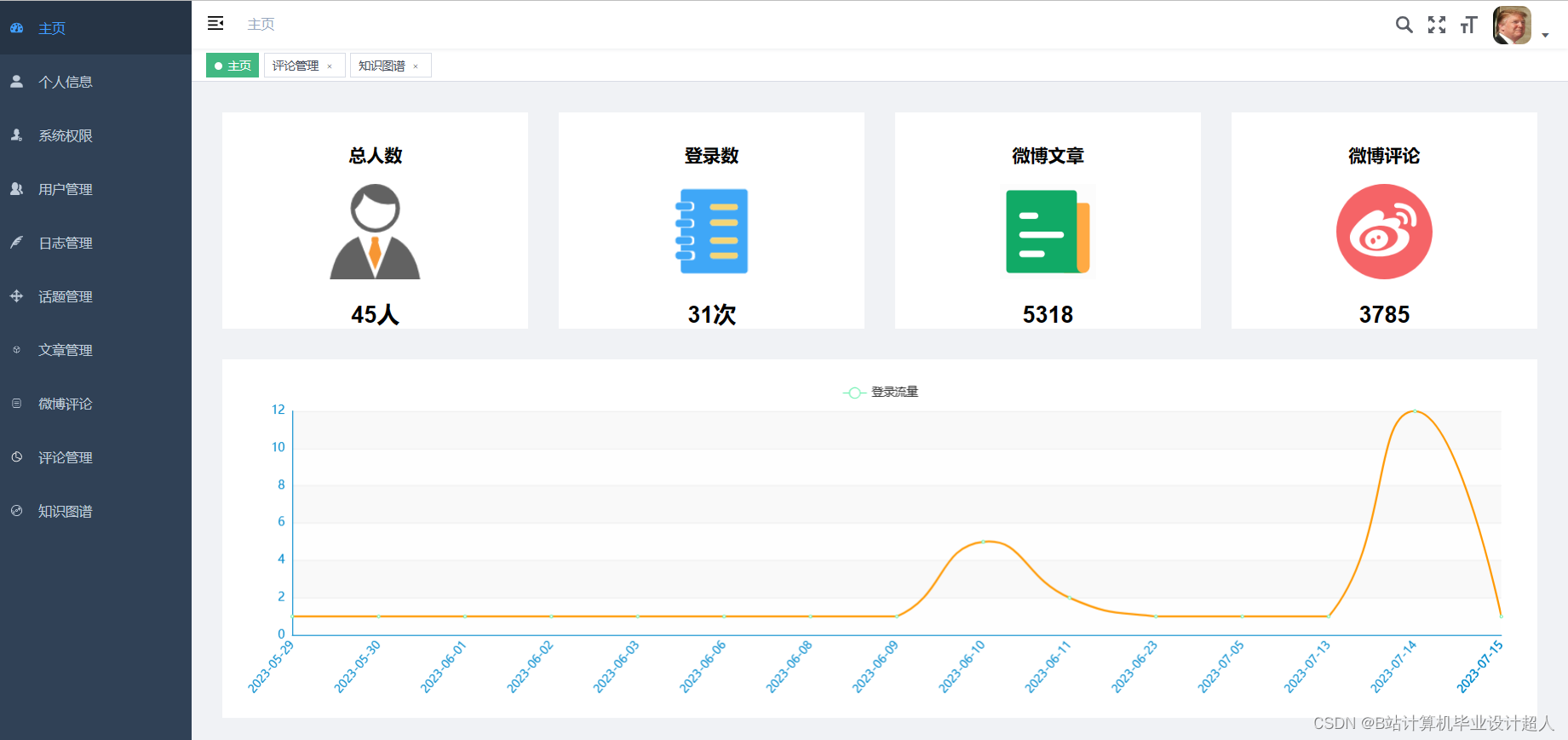
核心算法代码分享如下:
package com.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.junit.Test
import java.util.Properties
class WeiboSpark2024 {
val spark = SparkSession.builder()
.master("local[6]")
.appName("微博大数据Spark分析2024")
.getOrCreate()
val ods_weibo_schema = StructType(
List(
StructField("title", StringType),
StructField("hot", IntegerType),
StructField("create_time", StringType),
StructField("auname",StringType),
StructField("acmt", StringType),
StructField("shares", IntegerType),
StructField("comments",IntegerType),
StructField("alikes", IntegerType),
StructField("cuname", StringType),
StructField("ccmt", StringType),
StructField("clikes", IntegerType),
StructField("level", StringType),
StructField("addr", StringType),
StructField("label", StringType),
StructField("probs", FloatType),
StructField("ctime", StringType)
)
)
val ods_weibo_df = spark.read.option("header", "false").schema(ods_weibo_schema).csv("hdfs://bigdata:9000/weibo2024/weibo/weibo.csv")
@Test
def init(): Unit = {
ods_weibo_df.show()
}
//指标6 新浪微博日活实时分析
@Test
def tables06(): Unit = {
ods_weibo_df.createOrReplaceTempView("ods_weibo")
val df2 = spark.sql(
"""
select create_time,count(distinct cuname) num
from ods_weibo
group by create_time
order by create_time desc
limit 10
""")
df2
// .show(50)
.coalesce(1)
.write
.mode("overwrite")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.jdbc(
"jdbc:mysql://bigdata:3306/hive_weibo?useSSL=false",
"tables06",
new Properties()
)
}
}


















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











