




 本文介绍了一种独立于语言的个性化音乐推荐系统。该系统通过收集用户在社交网络上的帖子,使用基于语料库的情感分析方法计算用户当前的情绪强度,并结合用户个人资料信息的校正系数,为用户推荐合适的音乐。实验表明,该系统的准确性优于基于词典的情感分析方法。
本文介绍了一种独立于语言的个性化音乐推荐系统。该系统通过收集用户在社交网络上的帖子,使用基于语料库的情感分析方法计算用户当前的情绪强度,并结合用户个人资料信息的校正系数,为用户推荐合适的音乐。实验表明,该系统的准确性优于基于词典的情感分析方法。
独立于语言的个性化音乐推荐系统拉迪卡·N
计算机科学系研究生学者
工程专业
战国策工程学院
帕拉卡德,喀拉拉邦
赛亚姆·桑卡尔
计算机科学系助理教授
工程专业
战国策工程学院
帕拉卡德, 喀拉拉邦
电子邮件: syam.sankar8@gmail.com
摘要 — 社交媒体是用户展示的地方 他们自己并分享所有类型的信息、想法和 与世界的经验。近年来,情绪分析已经 被多家互联网服务探索推荐内容 根据人类的情感,通过社交网络。社交网络上的许多用户在写句子 多种语言。本文介绍与语言无关 音乐推荐系统中的情感分析。这个系统 根据当前的情绪向用户推荐音乐那个人的状态。其中当前情绪状态通过测量调整后的情绪强度来计算人 值,它是情绪强度值与 修正系数。此校正系数基于用户配置文件信息,并用于调整最终情绪强度值。
传统分类器是特定于语言的,需要很多 工作应用于不同的语言。建议的系统使用 语言的监督情绪分类方法 独立情绪强度计算。我们训练朴素湾 对我们的数据进行分类,并在2中的1000多个帖子上对其进行评估语言,英语和马拉雅拉姆语。
受监督的情绪具有校正因子的分类器可以提高性能拟议的语言独立音乐推荐系统。
关键词 — 社交网络,情绪分析,更正因素,建议
一、引言
互联网改变了我们的生活。如今很常见 让人们通过以下方式表达他们的情绪和意见 社交网络和微博。社交媒体使我们能够把世界掌握在我们手中。推特是最大的推特之一 互联网上的微博服务[8]。微博是 人们用来分享各种短信的短信 信息与世界。在推特上,这些微博是被称为“推
文”,其中超过4亿条被发布日。在这种情况下,关于情绪强度的研究有 开始出现。情感分析是一种自然语言技术 处理和文本分析,可应用于许多 推荐系统。了解情绪强度 一句话可以帮助更多地了解一个人表达自己对事件、产品或内容的看法。然而,它在推荐系统中的使用仍然是一个
挑战,因为人们用不同的方式表达自己的感受方式,这使得很难创建可靠的基于情绪分析的建议[2]。
在这里,情绪分析开始被探索
推荐特定歌曲的音乐推荐系统取决于人当前的情绪状态,因为歌曲完全与当下的情绪和感受有关这个人。人目前的情绪状态是通过收集用户在社交网络上的帖子来计算。
人们在一天中的某些时间使用社交网络了解他们的行为和习惯可能有助于几种应用[8],[9]。因此,记录很重要。
所有这些数据都在日志中。通过实现日志,可以为定制时期开发推荐系统的时间。例如,一个人通常阅读财经新闻周一和周四上午 8 点至上午 9 点,倾向于阅读周日娱乐新闻。
有大量的研究有待发现从文本数据中自动提取情绪的方法。最研究仅在一种语言的推文上进行。然而,Twitter是一个国际流行的社交网络服务和大部分推文都是多种语言的。
因此,仅分析一种语言的推文仅涵盖可用内容的一部分。 分类方法不限于只分析一种语言,就能收集很多东西来自多个推文的更多情绪信息语言。在本文中,我们研究了语言独立性情绪分类方法。我们训练分类器来标记推文的情绪极性,对于这个阶段需要原始用于训练分类器的该语言的推文。
我们在两个不同的推文上训练分类器语言:英语和马拉雅拉姆语。出于我们收集的目的以这两种语言发送的数千条人工注释的推文并假设任何一条推文只包含一种情绪一时间。要个性化此推荐系统,请正确使用因子,此校正因子完全取决于用户的个人资料信息。
本文对工作的贡献程度[1],它提出了个人语言独立音乐推荐使用基于语料库的情感分析的系统,具有 基于用户个人资料信息的校正系数。
二、相关作品
- 情绪分析
已经有大量的研究来寻找方法 自动从文本中提取情绪。情绪分析 可以使用三种方法执行,如图所示。 1、基于词典的方法使用词典,即使用机器学习和混合的基于语料库的方法 基于方法,它结合了这两种方法。 基于词典的情感分析技术[1]是 通过使用包含预标记的字典进行管理词汇。输入文本通过分词器。然后,遇到的每个新令牌都会匹配字典中的词典。如果存在正匹配,则总计文本的分数递增。否则分数为 递减或单词标记为负数。例如 情绪 (F) 表示句子的总情绪分数 F,使用以下公式1计算得出。
其中 dictionary.value 是在句子F中每个单词Wi的字典。但是这个 分类器是特定于语言的,需要大量工作才能 应用于其他语言。基于词典的情绪 分析还有其他限制:它在时间方面的性能 复杂性和准确性随着增长而急剧下降 单词字典的大小,即单词的数量。基于机器学习的情感分析[7]就是其中之一由于其适应性和 准确性。这种基于语料库的情感分析是一个有监督的 学习方法。它包括五个阶段:数据收集,预处理、训练数据、分类、绘制结果。在数据收集阶段,要分析的所需数据是 从博客、社交网络等各种来源抓取(Twitter,MySpace等)取决于区域 应用 [11]。然后在第二个预处理阶段 收集的数据经过清理并准备好将其输入分类。训练数据是手工标记的数据集合采用最常用的众包方法制备。 这些数据是用于学习目的的分类器的燃料。分类阶段是其中最重要的阶段 技术。根据应用要求部署 SVM 或朴素贝叶斯进行分析。在最后阶段 根据表示类型绘制结果 选择。这种技术的主要优点是语言 独立且时间复杂度较低。 朴素贝叶斯分类器 [10] 是一个简单的概率 基于贝叶斯定理的分类器 要素之间的独立性假设。给定一个类 变量和因特征向量通过,贝叶斯定理陈述了以下关系:
图1 执行情绪的不同方法分析
- 推荐系统
有三种推荐系统模型[2],基于内容的推荐系统,协作式推荐系统和基于混合的推荐型。基于内容的方法[7]适用于项目描述与用户描述之间的关联 配置文件,根据用户的 偏好。基于内容的系统检查属性推荐项目,其中项目的相似性由以下因素确定 测量其属性的相似性。 基于协作的方法[6]分析用户行为和偏好,并探索类似的人与人之间的偏好。协同过滤系统通过以评级的形式收集用户反馈来工作给定域中的项。然后利用评级的相似性多个用户的行为决定了如何推荐 一个项目。混合方法结合了这两种方法。在服务器上分配推荐系统 包含具有用户首选项或历史记录的数据库。这 使用服务器分配的优点是它们不会 数据使用户设备的内存过载,因为客户端应用程序的复杂性较低。有数据客户端和服务器之间的传输流,但当前的数据网络不像以前那样受到限制。在推荐系统中,情绪 开始探索分析以建议更多更新 内容并基于人的情绪和感受。
特定领域的推荐系统,例如多媒体需要根据人的 当前的情绪,情绪和感觉,因为这个人选择特定的电影或歌曲取决于他们当前的心情和 感觉。 任何推荐系统中的用户反馈 [12],[14]是需要考虑的重要工具。研究专注于数字电视或音乐推荐根据用户反馈的建议更有效。用户通常不喜欢编写手动反馈。因此它使用自动技术收集用户很重要反馈。用户的个人资料是另一个重要因素必须包含在推荐系统中,由调查问卷或评级。有许多研究指出,用户配置文件详细信息会影响情绪指标,即情绪强度可能因用户个人资料而异信息。此推荐系统计算情绪从真实社交网络中提取的句子强度为反对从特定的受信任者中提取句子网络。基于词典的情绪分析与更正因子[1]精确到最终情绪强度值,其中校正系数是根据用户配置文件计算的信息。但这种方法是特定于语言的,因为此情感分析技术基于单词字典。所提议的系统通过使用基于语言独立语料库的情感分析校正因子,这将提高性能现有推荐模型。
三、方法论
本节介绍
建议语言独立音乐推荐基于最终情绪强度值的系统。系统介绍架构如图 2 所示。推荐系统具有用户的个人资料包含用户配置文件参数的数据库,例如年龄,性别,教育水平,基于音乐偏好他/她的情绪状态和社交网络用户名第一次使用此系统的人。最初系统捕获一个人在社交上发布的每句话网络,其中时间和日期记录在日志中,并且发送到数据库。
图2 基于情绪强度指标的系统
图3 收集用户配置文件信息
然后对收集的用户执行朴素贝叶分类数据,以查找发布的句子的情绪强度用户。然后通过添加校正系数,此修正系数是使用在第一阶段收集的个人资料信息,例如年龄,教育水平和性别。最后,系统选择音乐根据最终的情绪强度并将其发送到用户应用程序。
A. 数据库
1)用户数据库:此推荐系统有两个 数据库类型:用户配置文件数据库包含用户的 音乐偏好,以及个人资料参数作为年龄、性别、教育水平和用户的社交网络用户名。通过设计用户收集的这些配置文件信息如图3所示的界面。
3.从图中提取的初始特征。帮助了解一个人的哪些特征会影响 最终情绪值。这些信息用于计算校正系数。
2)音乐数据库:从音乐中提取的多首歌曲门户,按情绪和情绪强度分类音乐专家[5]。这些歌曲存储为文件流在 MPEG-1 第 3 层音频编码方案中称为 MP3 中用于推荐系统的数据库。
图4 用于对歌曲进行分类的情绪
此推荐系统中使用的音乐类别 基于快乐、悲伤、愤怒和平静的情绪 图例.
4. 这些记录包含歌曲的名称、风格、歌手,情绪强度和情绪存储在 数据库。大多数歌曲的最大容量为3.0 MB 大小和平均长度在 2 到 3 分钟的范围内。
A. 校正系数存储在用户配置文件数据库中的信息用于计算校正因子[1]。此校正因子将调整初始情绪值,如图 5 所示。 句子 F 的最终情绪强度值为 由下面的等式 2 给出。此值是从主观测试结果,代表情绪强度 评估员给出的价值。
其中FSM(F)代表最终情绪强度,SM(F) 表示初始情绪强度,C 表示规模 不断。答1;A2,...,表示是与 年龄范围,如果其中一个等于一个,则其他是 零。答1;:::an 是每个年龄段的权重因素。这里 考虑四个范围 G1 和 G2 是与 性别,如果其中一个等于 1,另一个为零,MF是性别的权重因子,男人或女人,分别,e1 和 e2 是与教育水平(是否受过高等教育),GenG是教育水平的权重因
素,是否受过高等教育,分别。
图6 与用户配置文件信息相关权重因素
图 6表示每个参数的权重在评估中考虑。该图显示,性别和年龄参数是情绪中影响最大的因素强度指标。请注意,此音乐推荐系统需要提取简单的用户特征,随着年龄,用户的性别、教育水平。应用程序没有 需要提取复杂的用户特征,如每月 收入,宗教和种族,因为这些特征没有 影响情绪分析。因此,该研究没有 违反任何隐私规则,可以在任何国家/地区应用。 C. 独立于语言的情感分析 该系统使用推特作为在线社交网络平台 和用于情感分类的朴素海湾分类器。然后 使用重新训练的扩展修改分类器 分类器,用于对发布在 唽。现在情绪分类器变成了语言 独立。最后系统向 用户根据他/她当前的情绪状态。 四、结果分析 在本节中,我们进行了一系列实验 评估我们音乐推荐的表现 基于用户情绪的系统模型。我们爬了近 20 特定用户的实时推文。推文被收集 来自推特用户的时间线。对于我们的实验,我们使用了 超过 800M 条推文的训练数据集,包含 我们的评估数据集的 2 种语言可执行基于语料库情绪分析。 基于词典的情感分析是一种语言 依赖方法,仅考虑一个推文语言。它是一种基于字典的方法。在这里,我们的系统 考虑与语言无关的情感分析 修正系数。校正系数取决于 用户的个人信息。
A. 与语言无关 执行一系列测试,每组包含 20 条推文 两种不同的语言,如英语和马拉雅拉姆语。 第一组包含十条英语和十条马拉雅拉姆语推文, 第二组包含 9 条英语和 11 条马拉雅姆语推文,同样,最后一个评估集包含零英语推文和二十条马来拉姆语推文 仅基于词典的情感分析方法考虑数据集中的英语推文并过滤掉推文其他语言。因此结果不准确,因为它仅涵盖部分可用内容。当我们使用语料库时基于情感分析方法,考虑所有可用内容。因此,与词典相比,它的准确性很高基于方法。最后添加一个校正因子用于计算增强情绪值的初始值。
图7 基于词典与语料库的情感分析
B. 准确性
进行了一系列测试,以证明准确性 所提出的系统优于现有系统。哪里 Test1 包含 20 条负面推文,Test2 包含 19 条负面推文和 1 条正面推文,Test3 包含 18 条负面推文和 2 条正面推文等。图7显示,基于语料库的准确性情感分析优于基于词典的情绪分析。上行显示基于语料库的准确性情绪分析和下线显示准确性基于词典的方法。情绪强度值的范围从 -3 到 +3。 例如,考虑从推特中提取的 5 条推文 用户的时间线,如表1所示这里有三条负面推文和两条正面推文,因此,人的预期情绪是消极的。但当我们使用基于词典的情感分析方法时,结果如图 8 所示。所以结果是积极的。这心情会很高兴,这是一个不正确的结果。但是当我们使用基于语料库的情感分析时价值变得消极,情绪会悲伤,这被显示出来在图 9 中。校正因子的值取决于用户个人资料信息,如年龄、性别、教育水平的用户。最终情绪强度值根据到校正因子的值。
图8基于词典的情感分析结果
图9 基于语料库的情绪分析结果
五、结论和今后的工作
在本文中,我们提出了一种独立于语言的音乐 基于用户情绪提取的推荐系统 来自推特等社交网络。情绪强度 推文的价值是使用独立于语言的计算的 基于语料库的情绪分析与校正因子。此校正因子将使推荐者个性化系统,因为此校正因子是从用户评估的个人资料信息。这种语言独立的情感使用校正因子进行分析可提高性能的音乐推荐系统。
参考文献
[1] Renata L. Rosa, Demostenes Z. Rodriguez, and Grace Bressan, ”Music Recommendation System Based on User’s Sentiments Extracted from Social Networks”, IEEE Transactions on Consumer Electronics, volume. 61, pp. 1189-1204, 2015.
[2] G. Adomavicius and A. Tuzhilin, “Towards the next generation of recommender systems: a survey of the state of- the-art and possible Tweets I do not like this car Feeling happy with my best friends I need to apologize my parents I think I am so unlucky I love this day 2017 International Conference on Intelligent Computing and Control (I2C2) extensions”, IEEE Transaction on Data and Knowledge Engineering, pp. 734-749, 2005.
[3] G. Linden, B. Smith, and J. York, “Amazon.com recommendations: Item to-item collaborative filtering”. Internet Computing, pp. 76-80, 2003.
[4] Renata Lopes Rosa, emostenes Zegarra Rodriguez, ”SentiMeter-Br: a New Social Web Analysis Metric to Discover Consumers Sentiment”, IEEE 17th International Symposium on Consumer Electronics (ISCE) ,pp. 153-154, 2013.
[5] M. Jiang et al, “Social contextual recommendation”, Proceeding of 21st ACM International Conference Information Knowledge Management, pp. 45- 54, 2012.
[6] Xiaojiang Lei,Xueming Qian,Guoshuai Zho, “Rating prediction Based on Social Sentiment from Textual Reviews”, IEEE Transaction on multimedia , pp. 652-659, September 2016.
[7] Nadia Felix F. Da silva, Luiz F S. Coletta, Eduardo , “ A Survey and Comparative Study of Tweet Sentiment Analysis via Semi-Supervised Learning”, ACM Computing Surveys (CSUR), Volume 49 Issue 1, pp. 266- 277, July 2016.
[8] F. A. Nielsen, “A new ANEW: evaluation of a word list for sentiment analysis in microblogs”, in proceedings on Workshop on Making Sense of Microposts:Big Things come in small Packages.pp. 93-98, May, 2011.
[9] Q. Ye, R. Law, and B. Gu, “ The impact of online user reviews on hotel room sales”. International journel of Hospitality management. Vol 28, pp. 180-182, July 2009.
[10] R. Feldman ,” Techniques and applications for sentiment analysis”. ACM Communications, vol 56, pp. 82-89, April 2013.
[11] Nadia Felix F. Da silva, Luiz F S. Coletta, Eduardo,” A Survey and Comparative Study of Tweet Sentiment Analysis via Semi-Supervised Learning. ACM Computing Surveys,(CSUR)Volume 49 pp. 272-287, July 2016.
[12] W. Zhang, G. Ding, L. Chen, C. Li, and C. Zhang ,” Generating virtual ratings from Chinese reviews to augment online recommendations”, ACM Transaction Intellectual Systems and Technologies 26(11), pp.2774-2788, January 2013.
[13] G. Paltoglou, and M. Thelwall, “Twitter, MySpace, Digg. unsupervised sentiment analysis in social media”. ACM Transaction on Intellectual Systems and Technologies. Vol 3, pp.1-19, September 2012.
[14] S. E. Shepstone, Z.-H Tan, and S.H Jensen, “Audio-based age and gender identification to enhance the recommendation of TV content”. IEEE Transaction on Consumer ElectronicsVol 59, pp. 721-729, August, 2013.
[15] A. C. Lampe, N. Ellison, and C. Steinfield, “ A familiar Face(book): profile elements as signals in an online social network”. in proceedings of Conference on Human Factors in Computing Systems, pp. 435-444, May, 2007.
[16] R. Cai, C. Zhang, C. Wang, L. Zhang, and W.-Y. Ma , “MusicSense: contextual music recommendation using emotional allocation modelling”, in Proc. International Conference on Multimedia, Augsburg, Germany pp. 553- 556, May, 2007.
[17] A.C.M. Fong, B. Zhou, S.C. Hui, G.Y. Hong, and T. A. Do, “Web content recommender system based on consumer behavior modelling”, IEEE Trans. Consumer Electronics, vol. 57, no. 2, pp. 962-969, May, 2011.
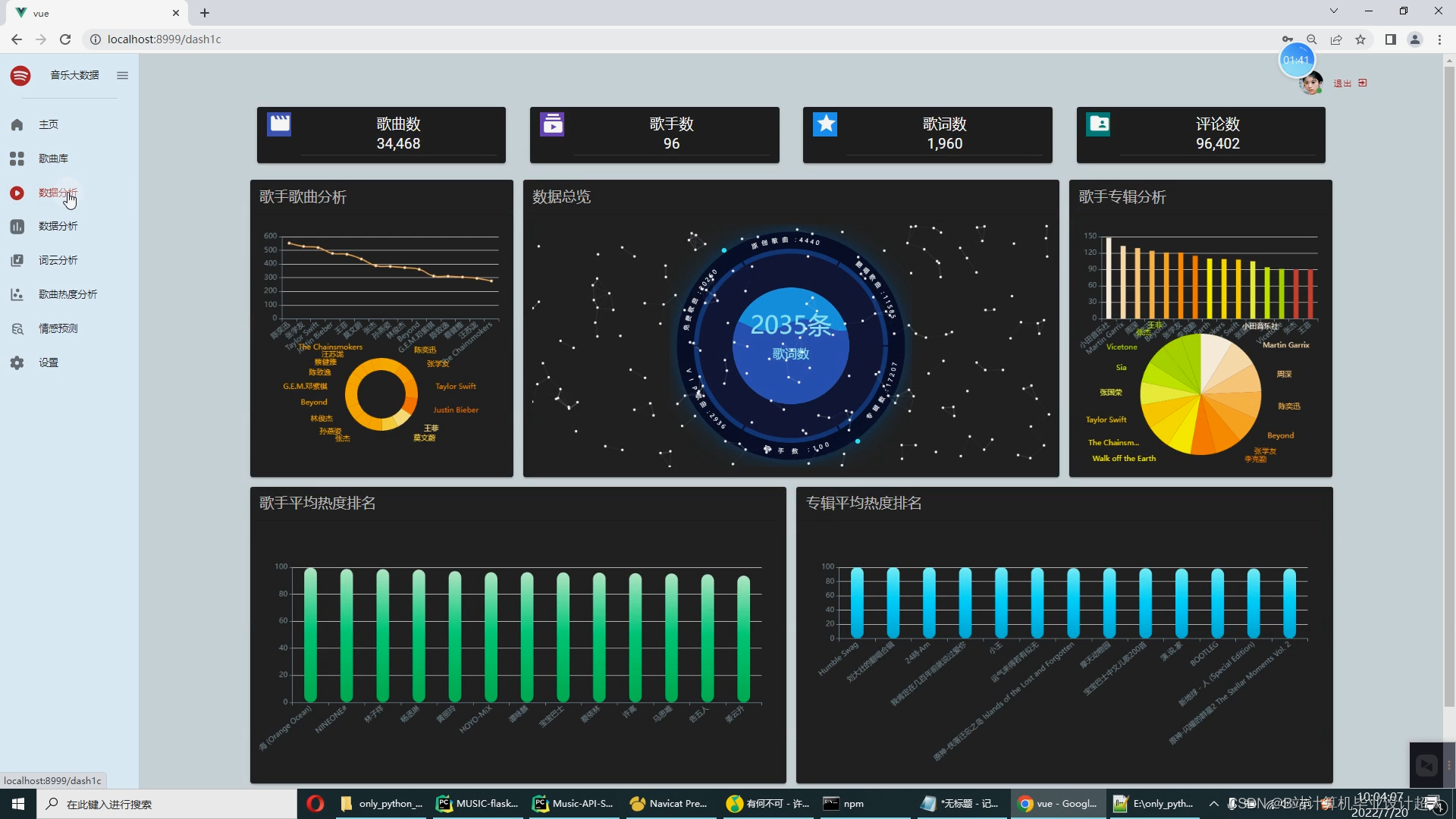
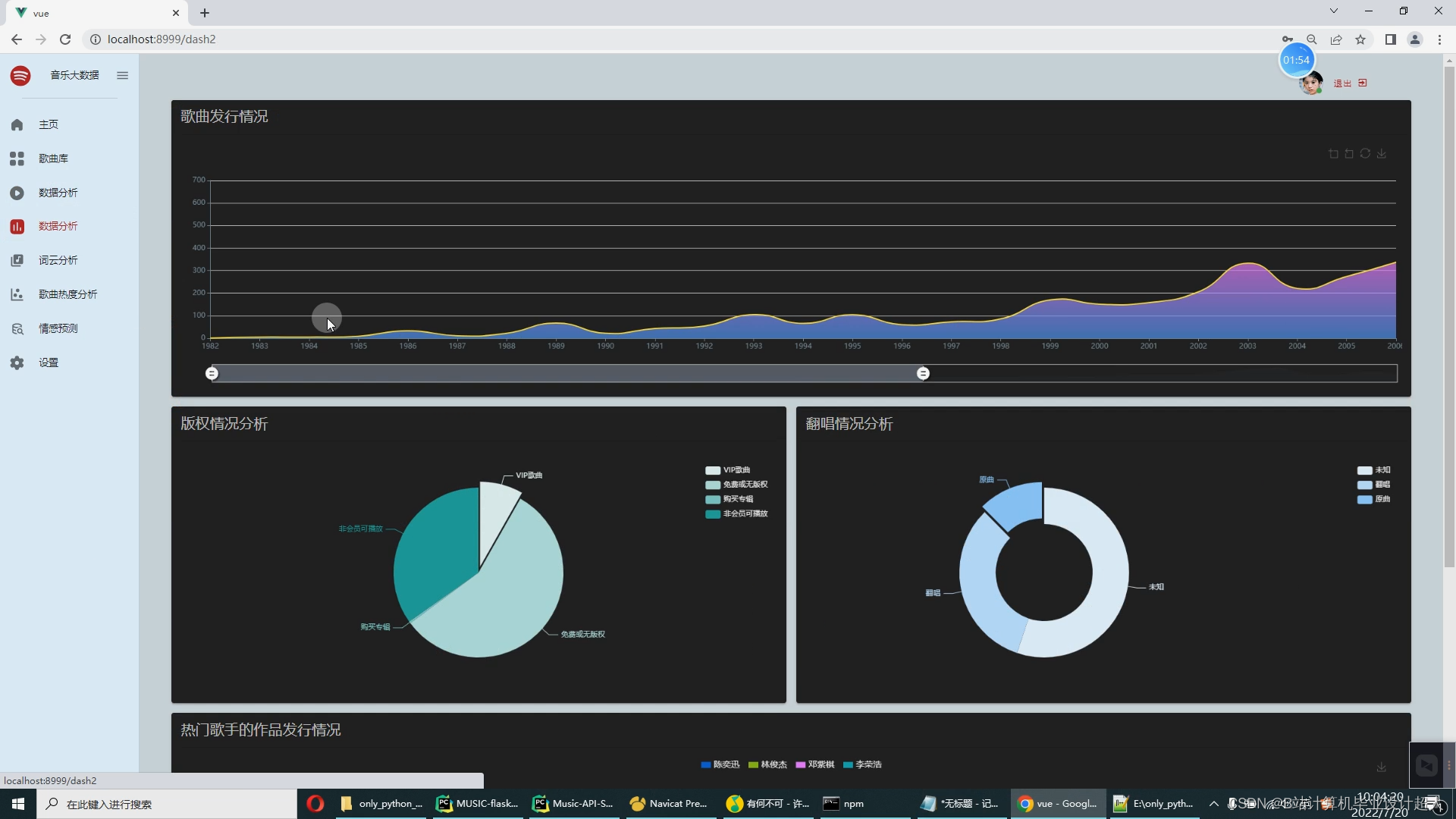
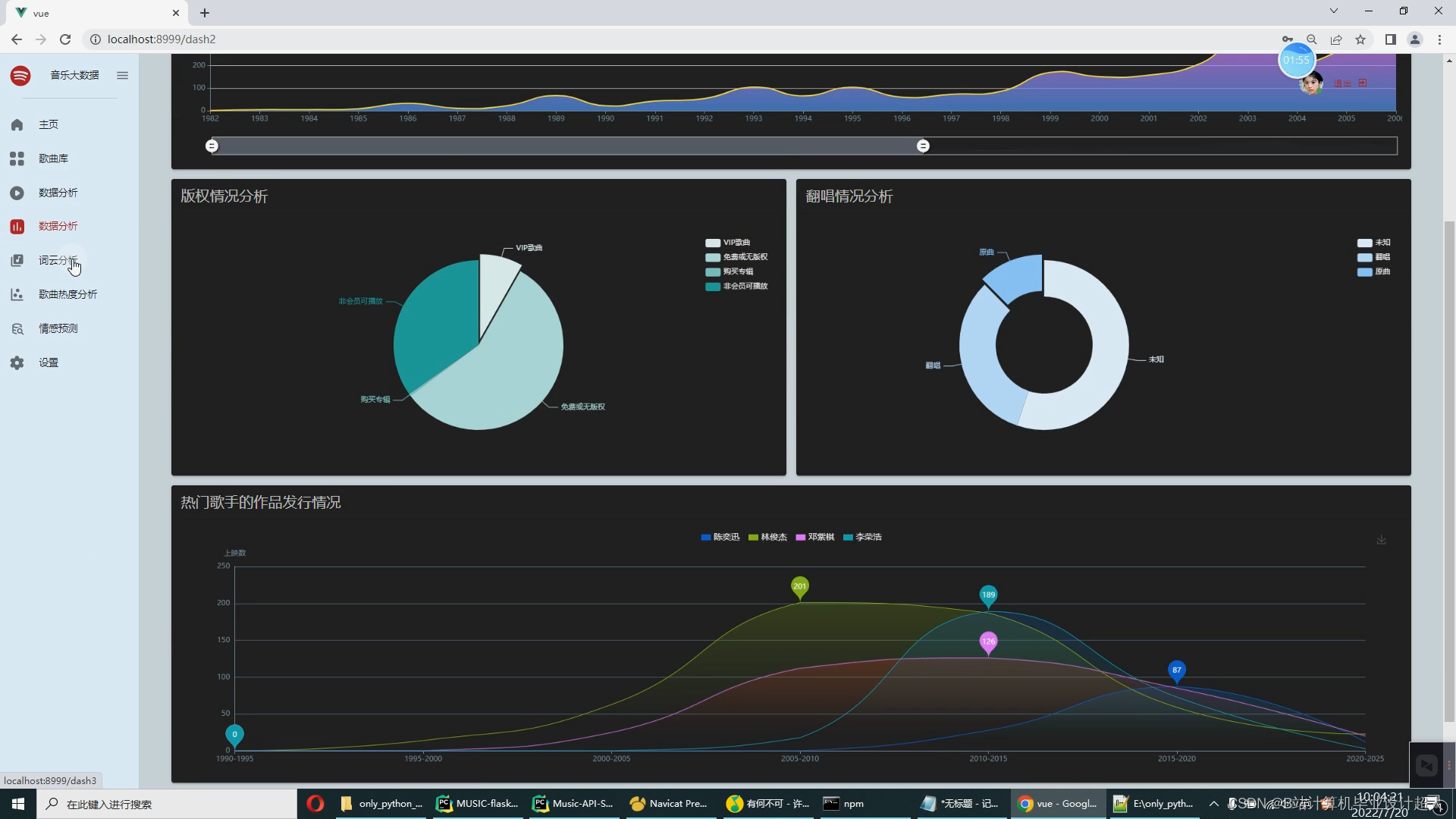

核心算法代码分享如下:
import csv
import random
import pymysql
from snownlp import SnowNLP
connect = pymysql.connect(host="localhost",port=3306, user="root",
password="123456", database="hive_music2024")
cur = connect.cursor()
cur.execute('''SELECT * FROM tb_artist''')
rv = cur.fetchall()
lines=0
errors=0
for result in rv:
id=result[0]
artistId=result[1]
artistName=result[2]
alias=result[3]
pic=result[4]
musicSize=result[5]
albumSize=result[6]
status=result[7]
#处理空值
#alia
#artistName
if len(alias) ==0 or alias=='' or alias == None:
alias='暂无'
errors=errors+1
#print(id,artistId,artistName,alias,pic,musicSize,albumSize,status)
if len(artistName) ==0 or artistName=='' or artistName == None:
artistName='暂无'
errors = errors + 1
#处理特殊字符
#alia artistName
alias = alias.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r','').replace( '\t', '')
artistName = artistName.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r','').replace( '\t', '')
#写入CSV
artists_file = open("artists.csv", mode="a+", newline='', encoding="utf-8")
artists_writer = csv.writer(artists_file)
print('歌手数据清洗转入CSV',id, artistId, artistName, alias, pic, musicSize, albumSize, status)
artists_writer.writerow(
[id, artistId, artistName, alias, pic, musicSize, albumSize, status] )
artists_file.close()
lines=lines+1
print('歌手-处理行数',lines)
print('歌手-处理错误数据项',errors)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











