




 本文描述了一个基于Hadoop和Hive的知网文献推荐系统开发过程,涉及数据采集、推荐算法研究(内容过滤和协同过滤)、系统设计与实现,以及系统评估和优化。重点在于实现实时、个性化的文献推荐,以提高学术研究效率和促进学术发展。
本文描述了一个基于Hadoop和Hive的知网文献推荐系统开发过程,涉及数据采集、推荐算法研究(内容过滤和协同过滤)、系统设计与实现,以及系统评估和优化。重点在于实现实时、个性化的文献推荐,以提高学术研究效率和促进学术发展。
核心算法代码如下:
## 启动hadoop
cd /data/hadoop/sbin
start-all.sh
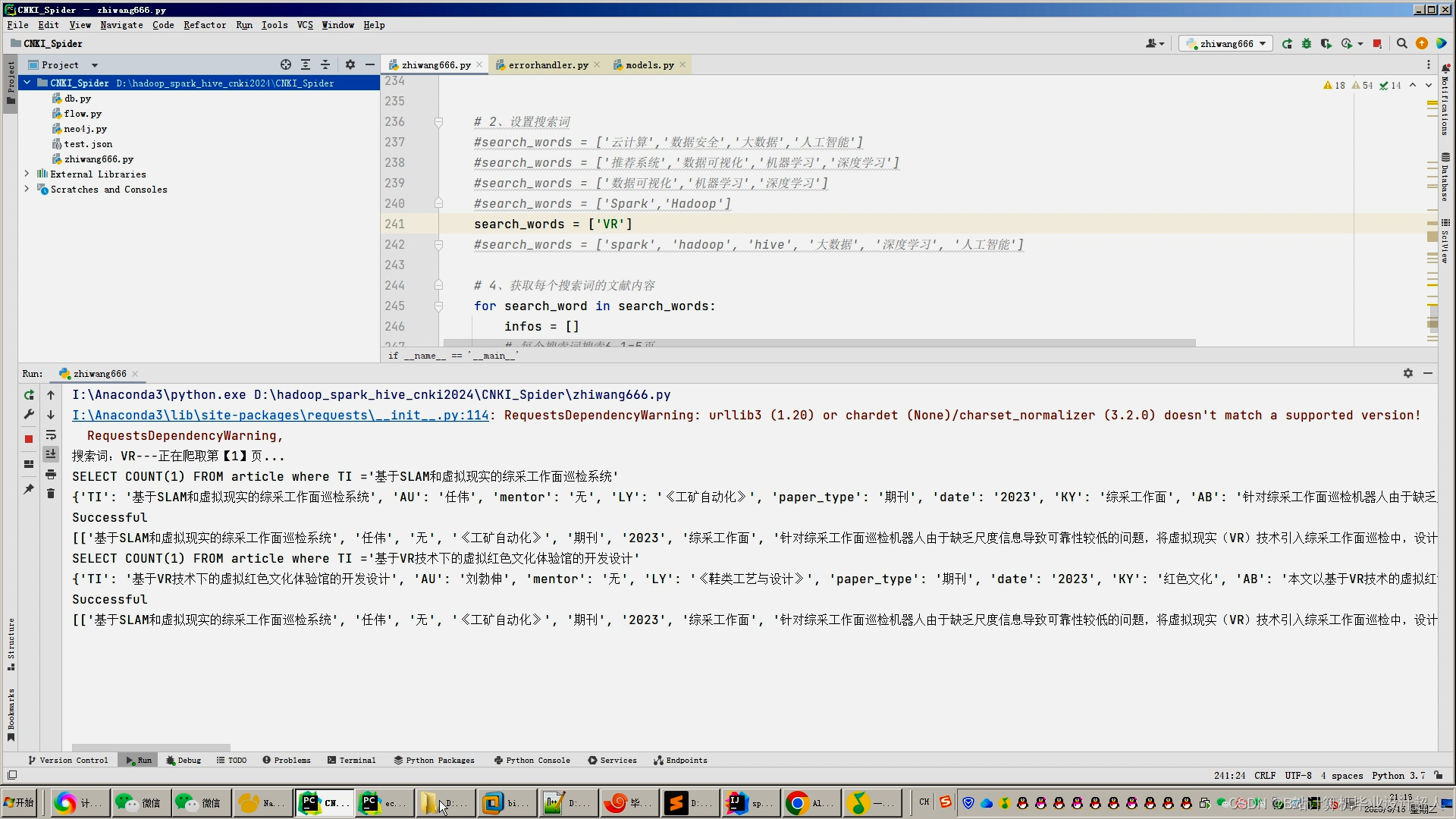
反复爬取的时候如果数据库中已经存在了就不会继续入库mysql和CSV文件 懂吧 我做了容错处理和重复处理
## 启动hive
cd /data/hive
nohup hive --service metastore &
nohup hive --service hiveserver2 &
============hive+hadoop离线计算命令无脑复制
--hive 建库
DROP DATABASE IF NOT EXISTS cnki2024;
CREATE DATABASE IF NOT EXISTS cnki2024;
use cnki2024;
show tables;
--hdfs创建文件夹、上传CSV(linux上上传CSV到/cnki2024然后再执行以下命令 -f表示覆盖)
hadoop dfs -mkdir -p /cnki2024/cnki_base
hadoop dfs -mkdir -p /cnki2024/cnki_kw
hadoop dfs -put -f /data/cnki2024/cnki_base.csv /cnki2024/cnki_base
hadoop dfs -put -f /data/cnki2024/cnki_kw.csv /cnki2024/cnki_kw
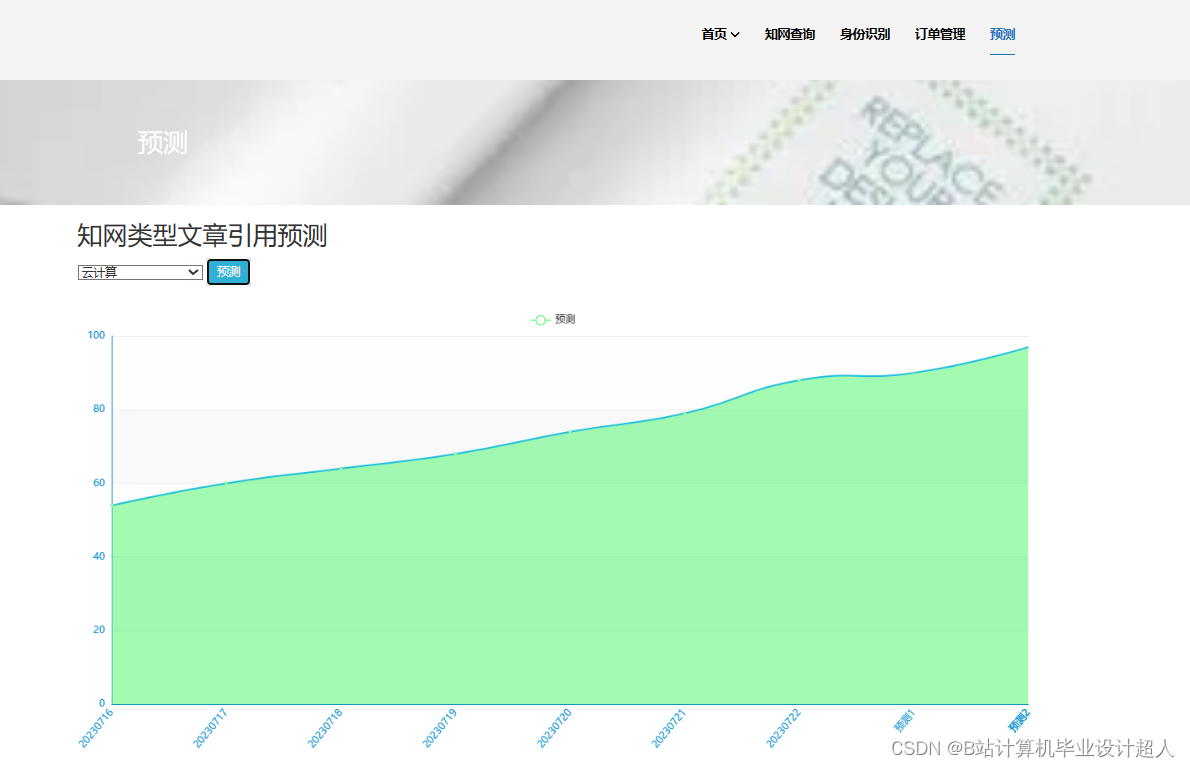
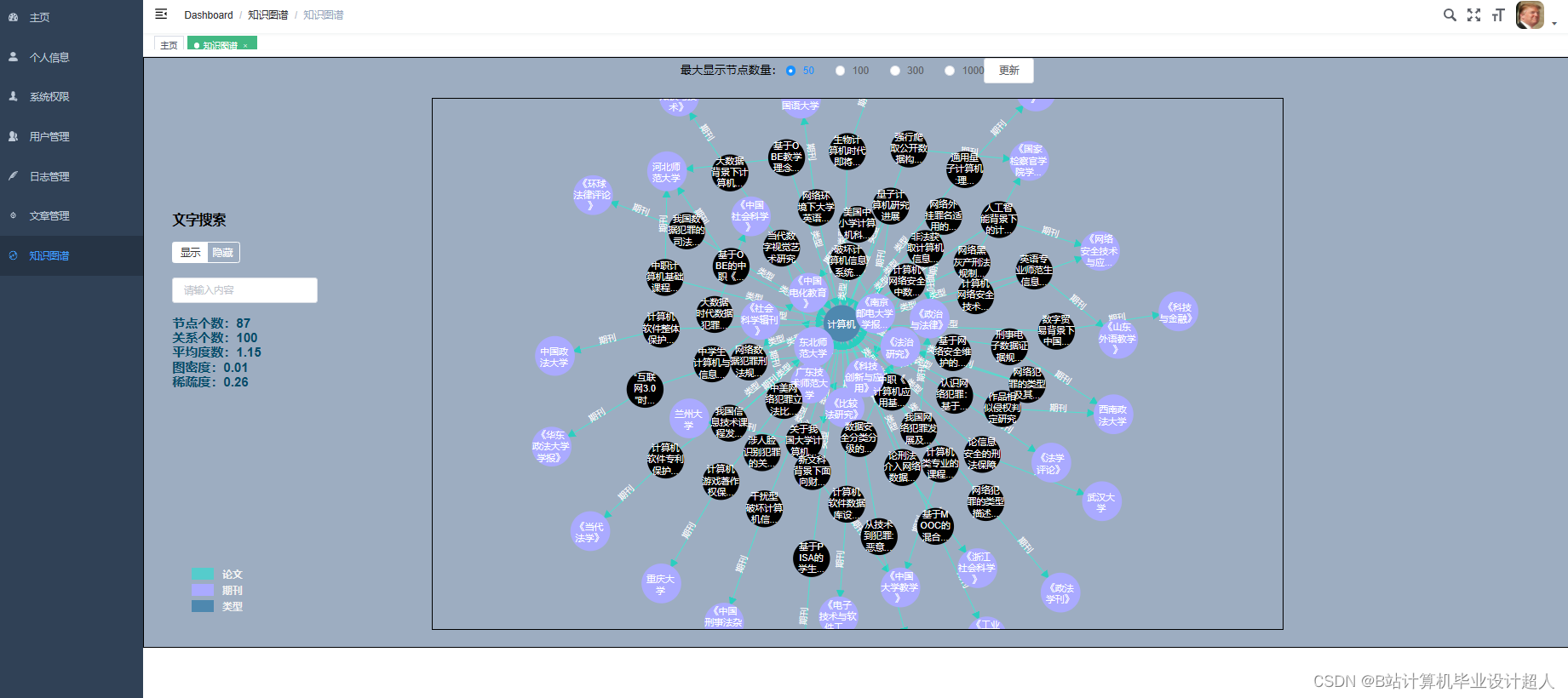
开题报告
一、选题背景与意义
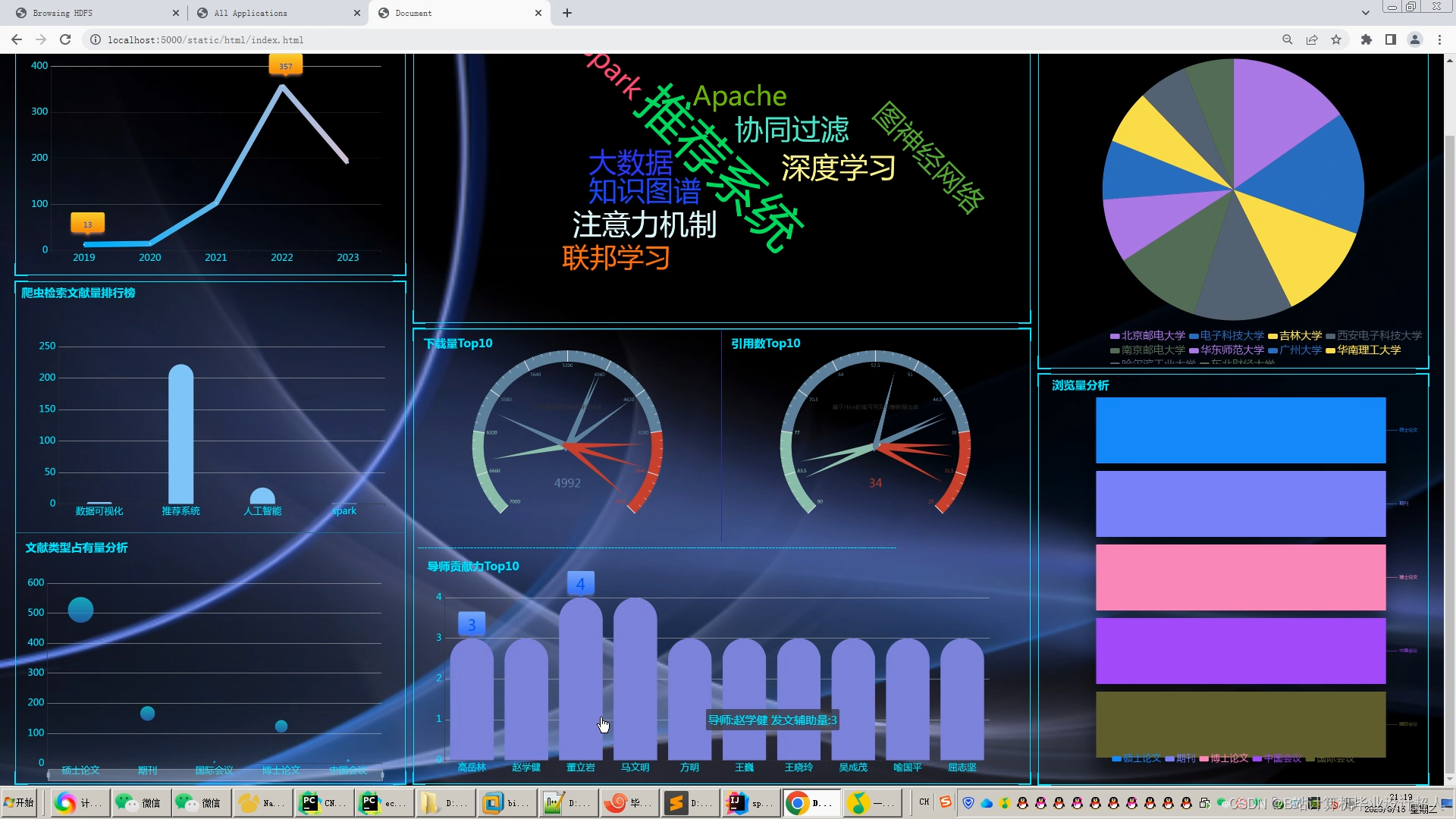
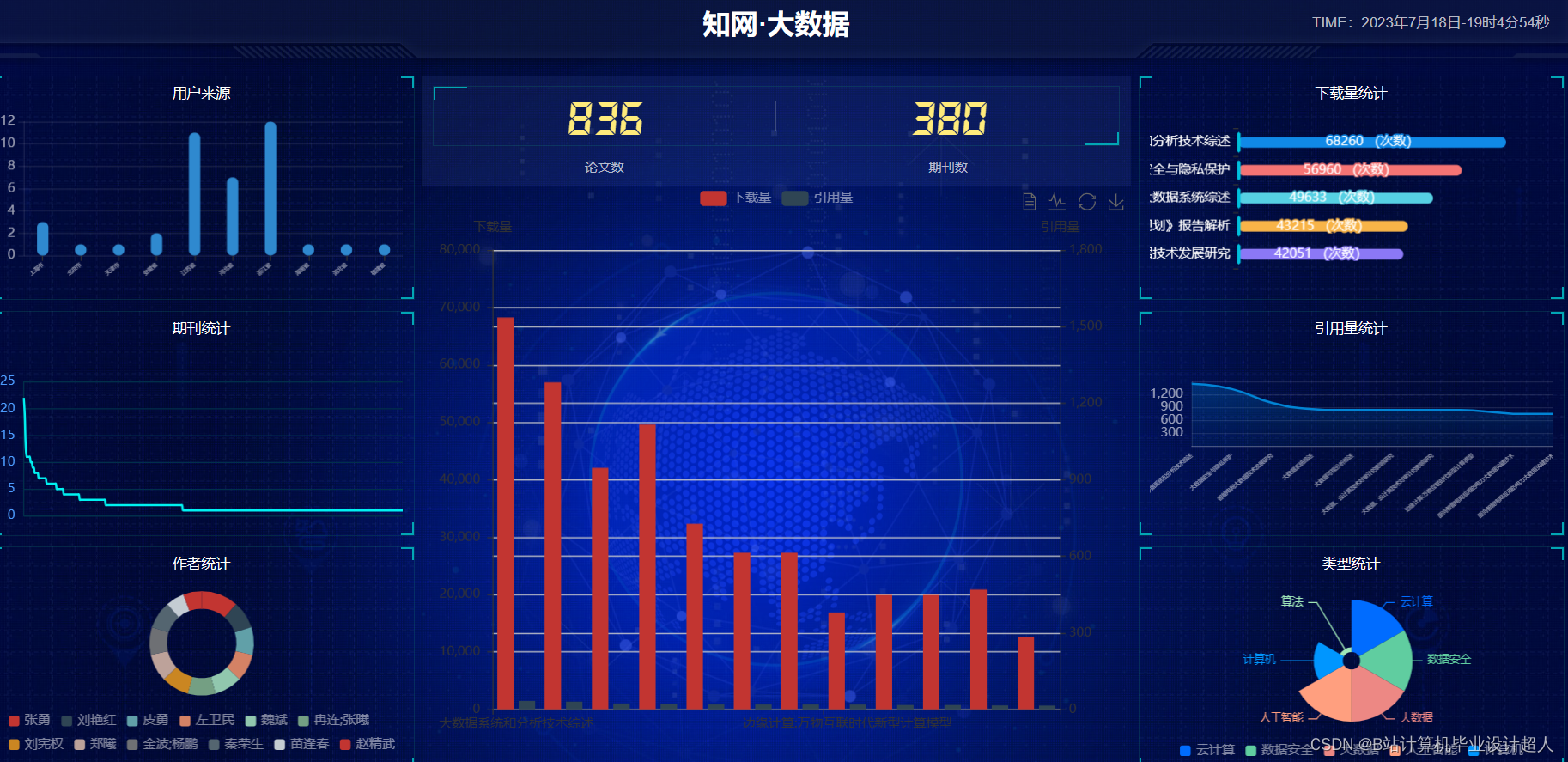
知网文献推荐系统是基于学术文献数据库的推荐系统,旨在帮助用户发现与其研究领域相关的高质量文献资源,提高学术研究效率和质量。随着科技发展和学术信息爆炸式增长,研究者往往面临着海量文献的挑选和筛选困难,因此建立一个智能、个性化的文献推荐系统对于提高学术工作者的信息获取效率至关重要。
二、研究目标与内容
-
研究目标:建立一套基于知网文献数据库的文献推荐系统,实现个性化、高效的文献推荐服务,满足用户需求。
-
研究内容:
- 构建文献数据集:从知网等学术文献数据库中采集、整理文献数据。
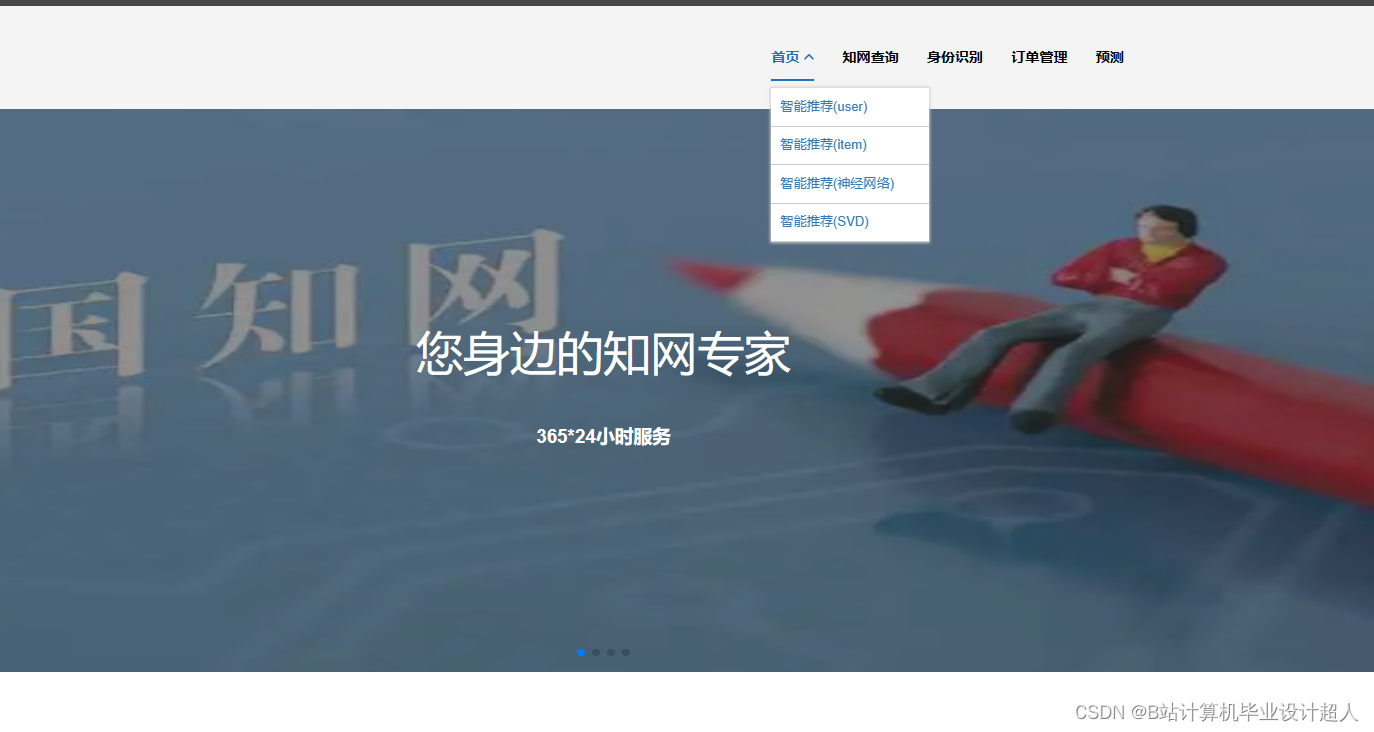
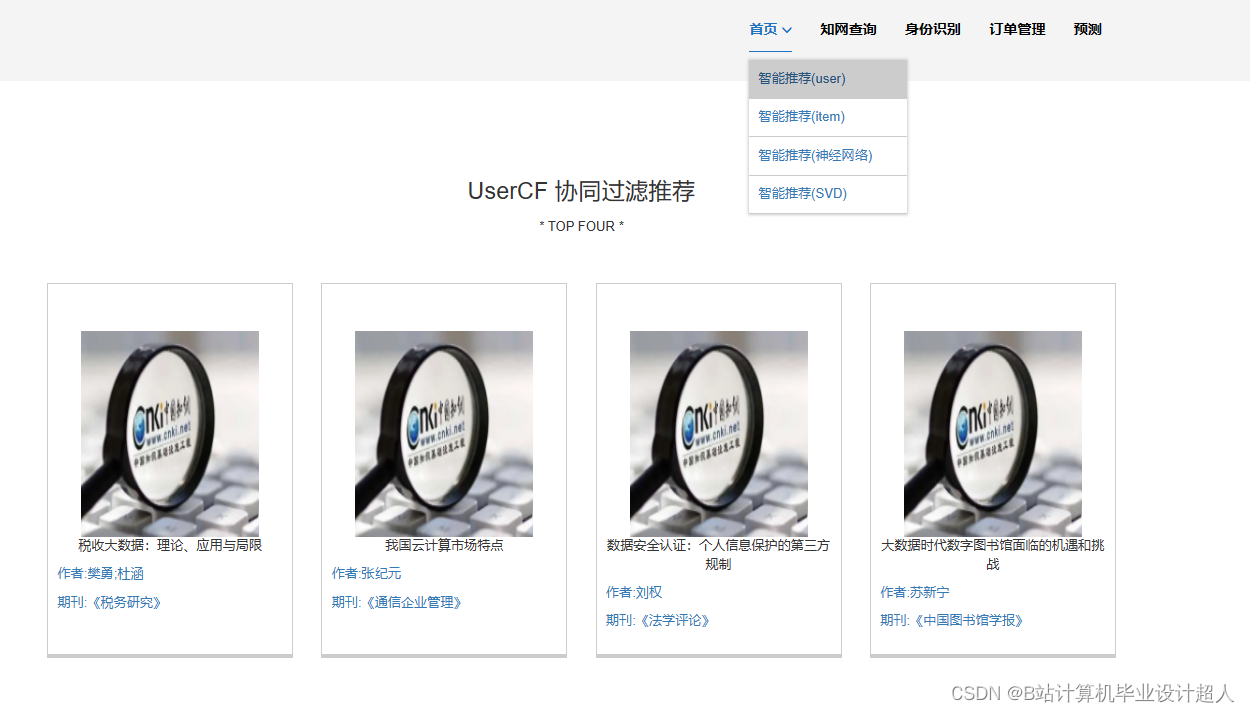
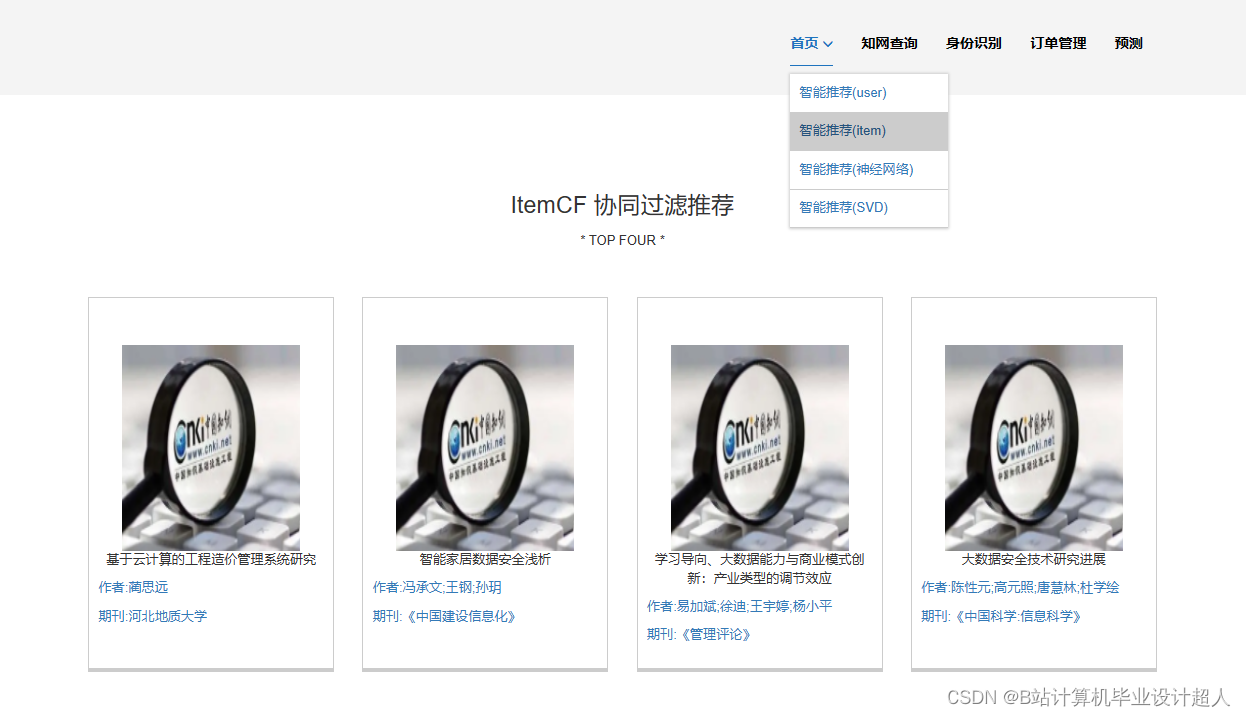
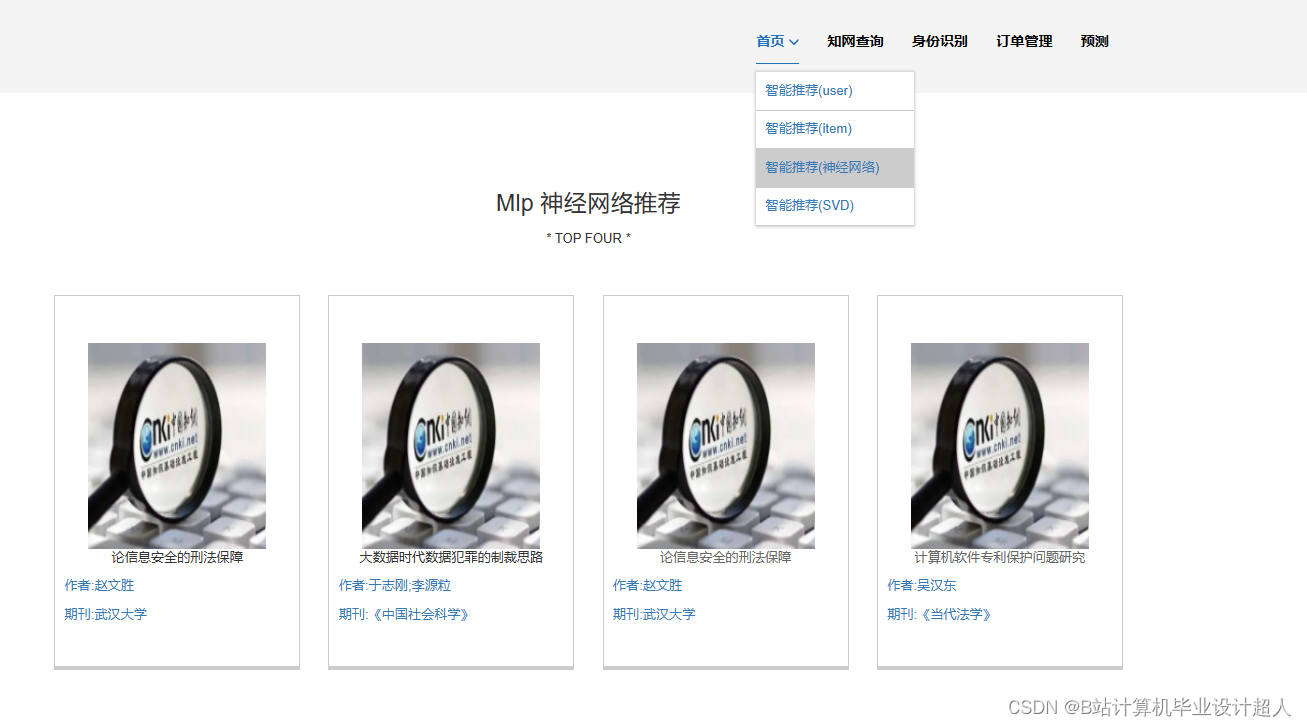
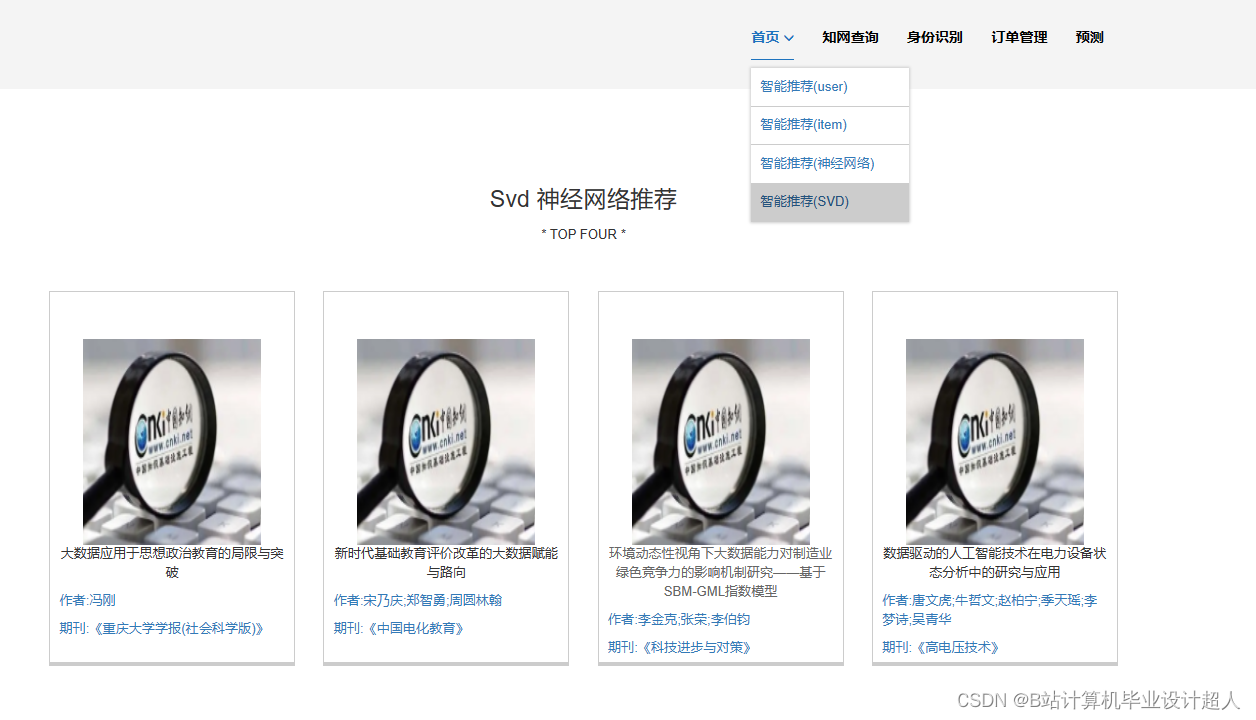
- 推荐算法研究:研究文献推荐的算法模型,包括基于内容的推荐、协同过滤推荐等。
- 系统设计与实现:设计并开发文献推荐系统,包括用户界面设计、推荐算法实现等。
- 系统评估与优化:对推荐系统进行性能评估,并针对用户反馈进行系统优化。
三、研究方法与技术路线
-
研究方法:本研究将采用实证研究方法,结合数据分析和机器学习技术,通过大量文献数据的分析和用户行为数据的挖掘,建立文献推荐模型,并对模型进行评估和优化。
-
技术路线:
- 文献数据采集与处理:使用网络爬虫技术从知网等学术文献数据库中获取文献数据,并进行清洗和整理。
- 推荐算法研究:结合内容过滤、协同过滤等算法,构建文献推荐模型。
- 系统设计与实现:基于Python等技术,设计并实现文献推荐系统的用户界面和后台功能。
- 系统评估与优化:通过用户调查、实验评估等方法,对推荐系统的性能进行评估,并针对性能瓶颈进行优化。
四、预期成果与应用价值
-
预期成果:完成基于知网文献数据库的文献推荐系统,并具有较高的推荐准确度和用户满意度。
-
应用价值:
- 提高学术研究效率:帮助研究者快速找到与其研究领域相关的文献资源,节省检索时间。
- 促进学术交流与合作:推荐系统可以发现潜在的合作伙伴,促进学术交流和合作。
- 促进学术发展:通过推荐系统,研究者可以接触到更广泛、更新颖的研究成果,促进学术创新和发展。
五、进度安排与预算
-
进度安排:
- 阶段一(第1-3个月):文献数据采集与处理,推荐算法研究。
- 阶段二(第4-6个月):系统设计与实现。
- 阶段三(第7-9个月):系统评估与优化,论文撰写。
- 阶段四(第10-12个月):论文修改完善,成果发布。
-
预算:本研究预计需要经费XXX万元,主要用于人员费用、设备购置、数据采集等方面。
六、存在问题与解决方案
-
存在问题:推荐系统的准确性和用户体验如何保障?如何解决用户隐私和数据安全问题?
-
解决方案:通过算法优化和用户反馈机制,不断提升推荐系统的准确性和用户满意度;采用数据加密和权限管理等措施,保障用户隐私和数据安全。


















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











