




 本文详细介绍了如何使用ApacheFlink在HDFS上读取CSV文件,创建表并执行SQL查询,最终将数据导入到MySQL数据库,同时讨论了地震数据分析的重要性和国内外研究现状。
本文详细介绍了如何使用ApacheFlink在HDFS上读取CSV文件,创建表并执行SQL查询,最终将数据导入到MySQL数据库,同时讨论了地震数据分析的重要性和国内外研究现状。
核心算法代码分享如下:
#Flink连接HDFS上面的CSV文件 使用Flink_SQL分析完入表
## 启动hadoop
## cd /data/hadoop/sbin
## sh /data/hadoop/sbin/start-all.sh
## 启动hive
## cd /data/hive
## nohup hive --service metastore &
## nohup hive --service hiveserver2 &
import os
from pyflink.common import Row
from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema,
DataTypes, FormatDescriptor)
from pyflink.table.expressions import lit, col
from pyflink.table.udf import udtf
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
jars = []
for file in os.listdir(os.path.abspath(os.path.dirname(__file__))):
if file.endswith('.jar'):
file_path = os.path.abspath(file)
jars.append(file_path)
str_jars = ';'.join(['file:///' + jar for jar in jars])
table_env.get_config().get_configuration().set_string("pipeline.jars", str_jars)
# table_env.get_config().get_configuration().set_float('taskmanager.memory.network.fraction',0.8)
# table_env.get_config().get_configuration().set_string('taskmanager.memory.network.min','8gb')
# table_env.get_config().get_configuration().set_string('taskmanager.memory.network.max','16gb')
table_env.get_config().get_configuration().set_string('parallelism.default','1')
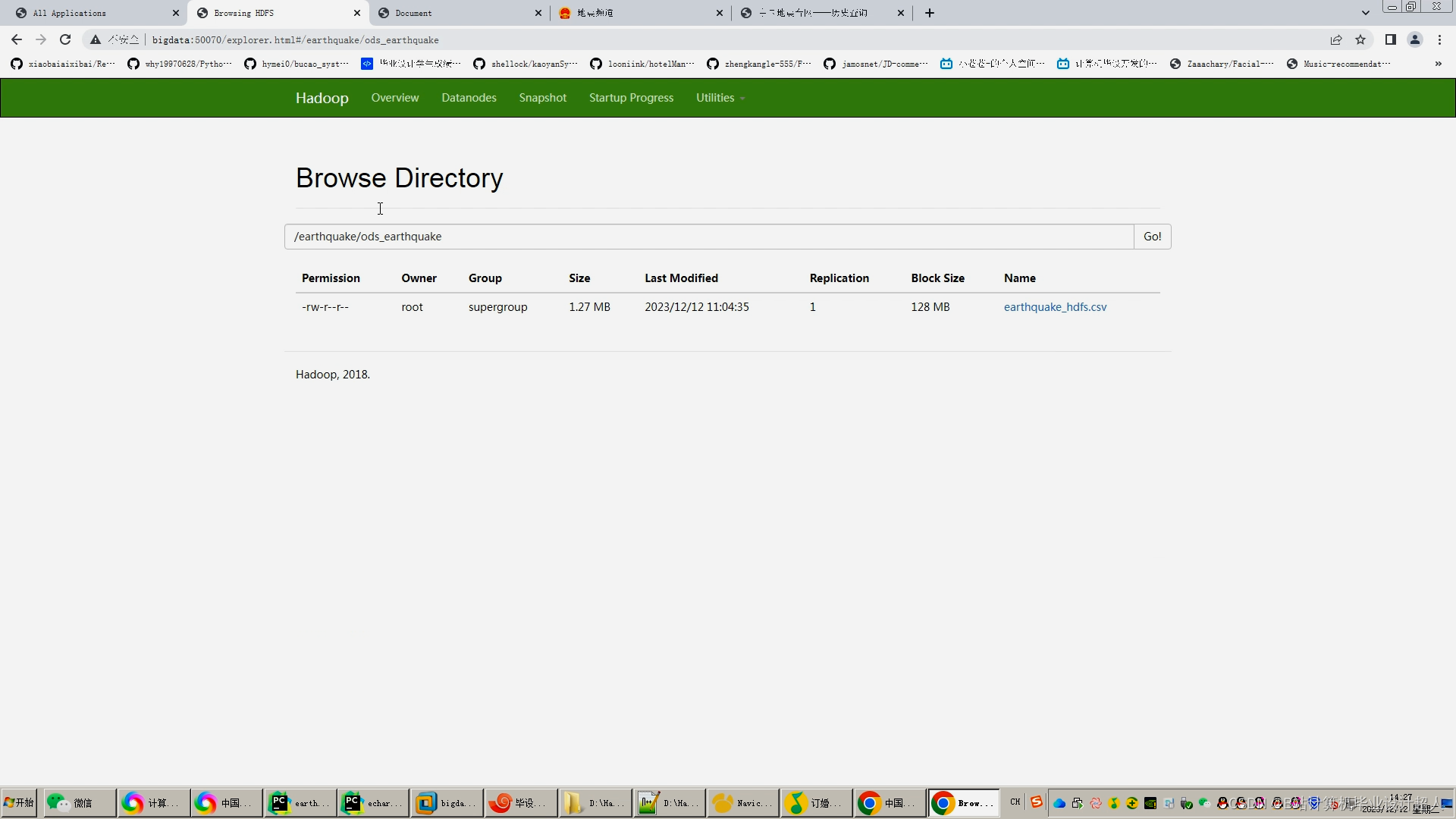
#先读取hadoop_hdfs上的CSV文件
table_env.execute_sql(
"""
create table ods_earthquake(
`magnitude` double COMMENT '震级(M)',
`stime_long` string COMMENT '发震时刻(UTC+8)',
`latitude` string COMMENT '纬度(°)',
`longitude` string COMMENT '经度(°)',
`depth` bigint COMMENT '深度(千米)',
`addr` string COMMENT '参考位置',
`stime_short` string COMMENT '年月日',
`data_type` string COMMENT '数据类型(用于区分中国外国)',
`long_province` string COMMENT 'echarts中国地图省份专用字段(外国是:无(外国))',
`stime_year` string COMMENT '年',
`stime_month` string COMMENT '月',
`stime_clock` string COMMENT '时刻中的时'
) WITH(
'connector' = 'filesystem',
'path' ='hdfs://bigdata:9000/earthquake/ods_earthquake/earthquake_hdfs.csv',
'format' = 'csv'
)
"""
)
#设置下沉到mysql的表
table_env.execute_sql(
"""
create table table06(
`addr` string primary key ,
`num` bigint
) WITH(
'connector' = 'jdbc',
'url' = 'jdbc:mysql://bigdata:3306/hive_earthquake',
'table-name' = 'table06',
'username' = 'root',
'password' = '123456',
'driver' = 'com.mysql.jdbc.Driver'
)
"""
)
#数据分析并且导入
#result=table_env.sql_query("select * from ods_zymk limit 10 ")
table_env.execute_sql("""
insert into table06
select addr , count(*) num
from ods_earthquake
GROUP BY addr
order by num desc
limit 10;
""").wait()
#print("表结构",result.get_schema())
#print("数据检查",result.to_pandas())
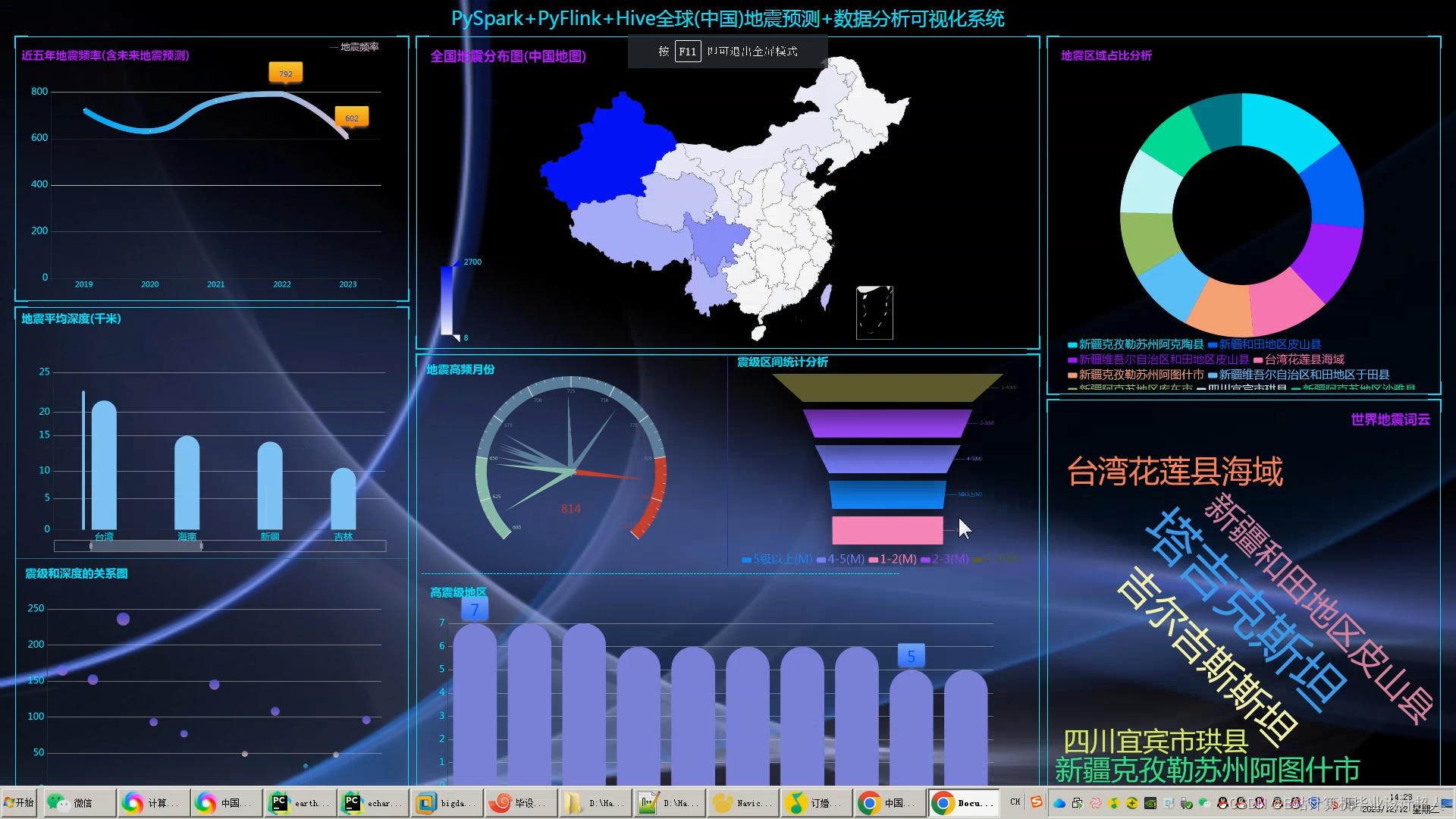
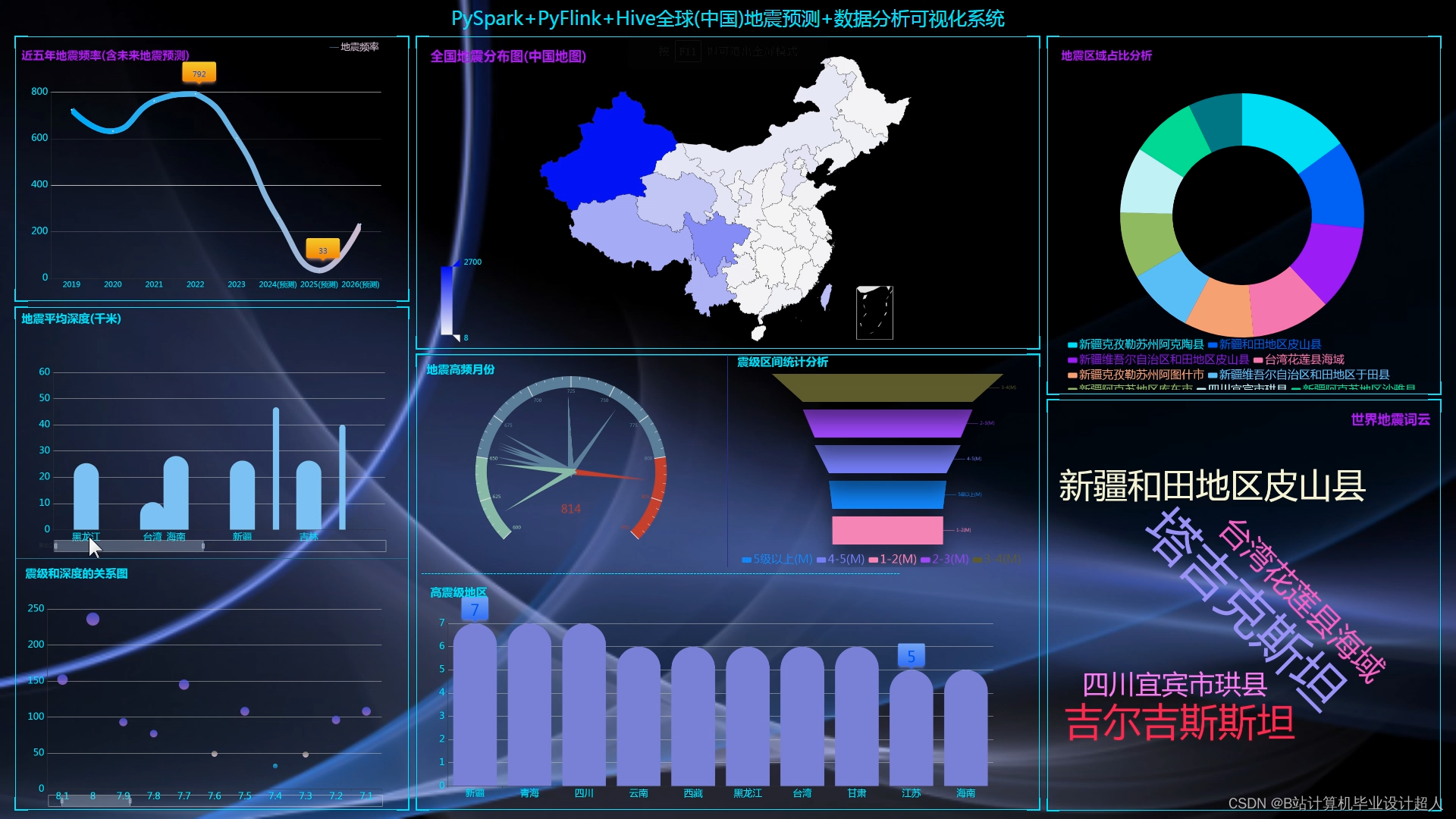
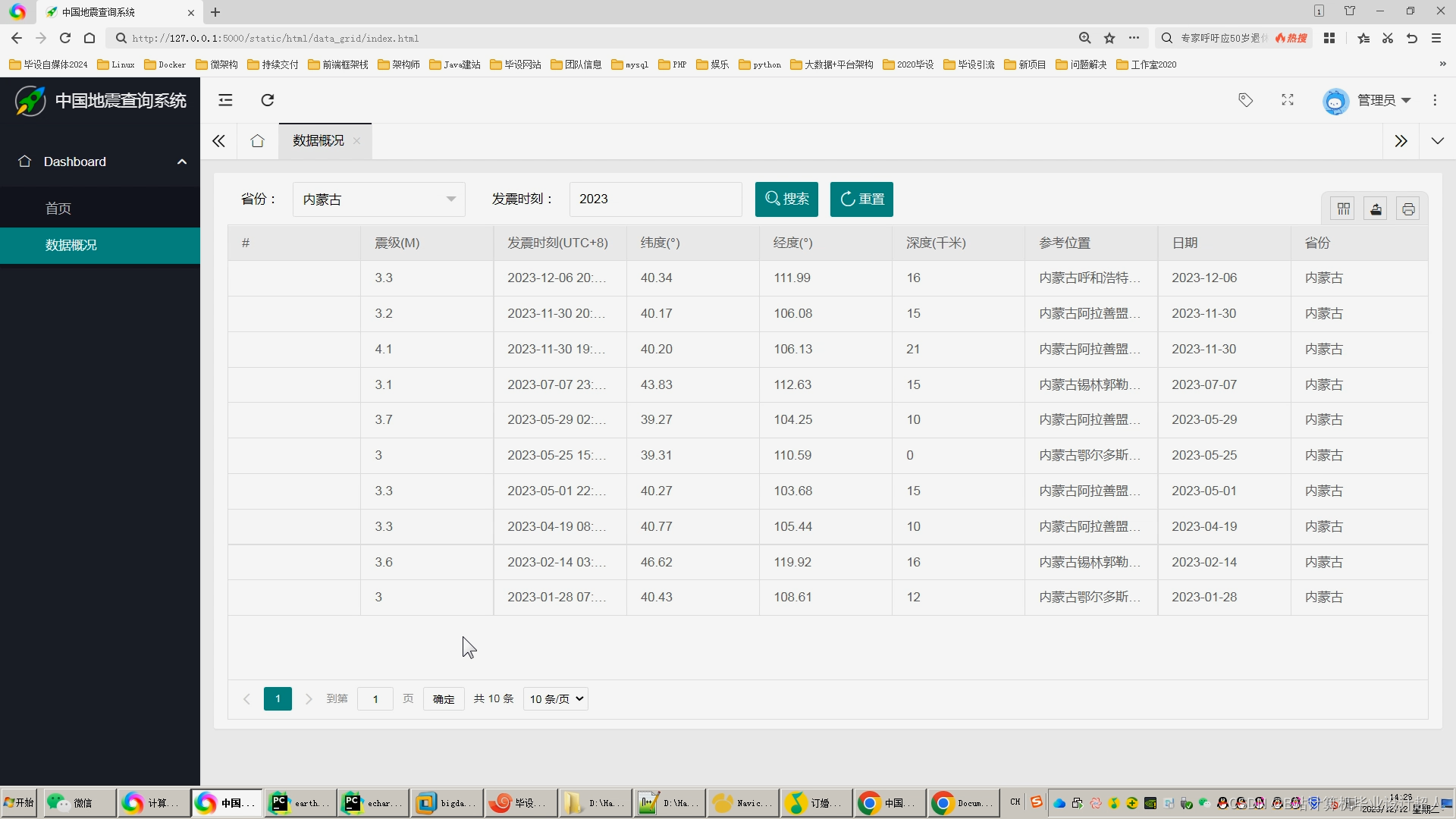
(一)研究的背景和意义
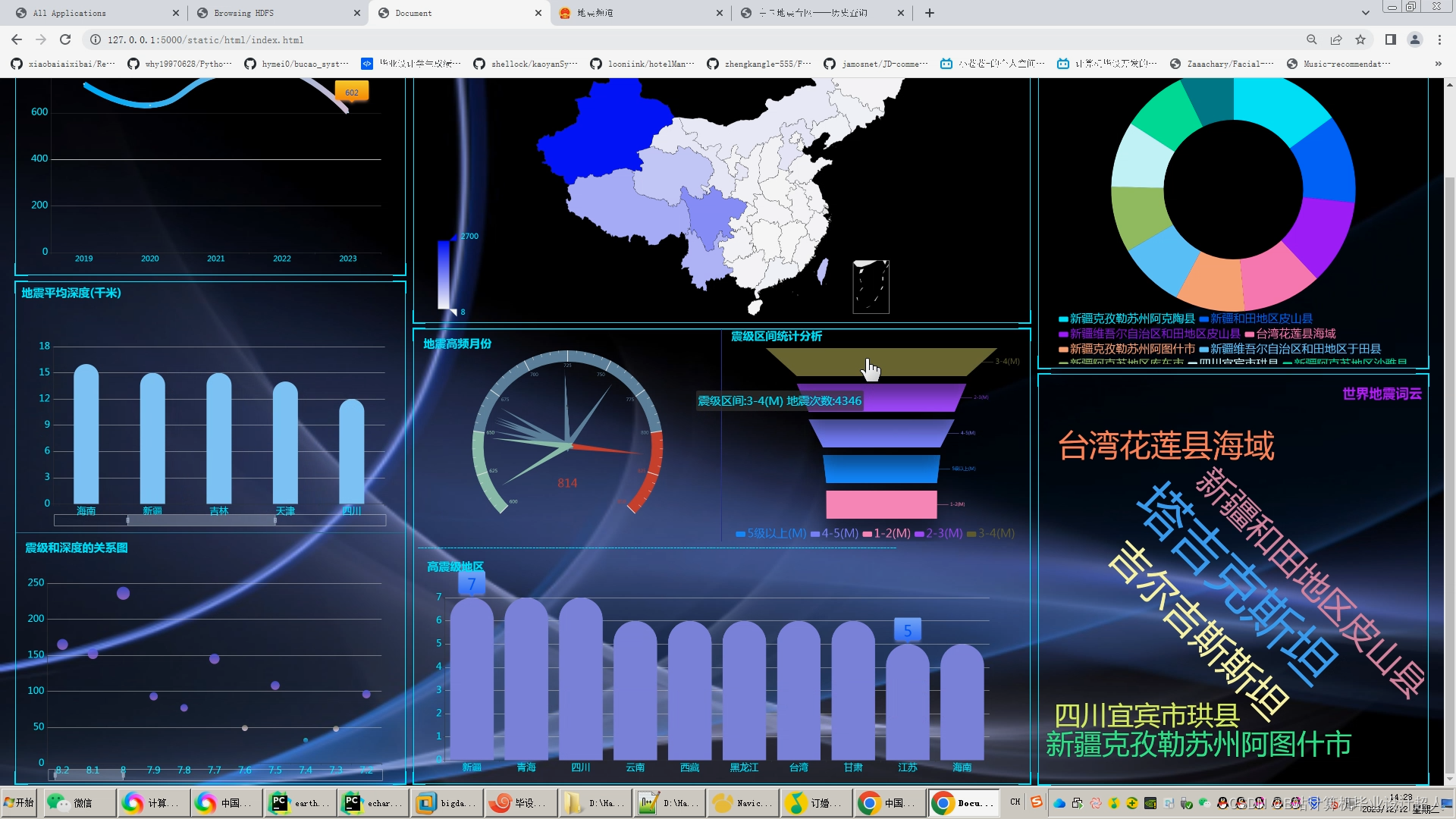
地震是一个全球性的自然灾害,对人类社会和自然环境都造成了极大的影响。中国位于环太平洋地震带和欧亚地震带之间,是世界上地震活动最频繁的国家之一,地震给人们的生命和财产安全带来极大的危害。因此,通过对地震数据的分析和可视化,可以更好地了解地震的分布、发生规律和发展趋势。
地震数据分析与可视化不仅可以提高对地震的认识,为地震预测和预防提供帮助,还可以为政府和企业提供决策支持,减少地震造成的损失。
国内外研究或应用现状:在地震数据分析与可视化方面,国内外已经有很多研究工作。例如,利用地震震级和发生时间的数据,进行地震预测和预防的研究;利用地震数据的空间分布和时间序列分析,研究地震活动的特征和规律等。此外,一些商业软件和开源软件也被广泛应用于地震数据的分析和可视化。
(二)国内外研究现状
随着互联网技术的迅速发展和大数据时代的到来,如何在各种资源中获取地震数据变得尤为重要。中国地震数据分析与可视化研究已经取得了很多成果。例如,利用Python中的Pandas库对地震数据进行处理和分析[1][2],利用Matplotlib库对地震数据进行可视化,利用NumPy库对地震数据进行数学建模和模拟等。
国外地震数据分析与可视化研究也取得了很多成果。例如,利用Python中的NumPy和Pandas库对地震数据进行处理和分析[3][4],利用Matplotlib和Seaborn库对地震数据进行可视化,利用PyQt和PySide库[5]开发地震数据可视化交互式界面[6]等。
在地震数据分析方面,常用的数据分析方法包括历史数据分析、趋势分析等。地段分析,了解地震以往的发生频率与趋势,从而为目标用户提供更准确的可视化分析。
近年来,越来越多的学者开始关注Python在地震数据分析应用研究[6]。例如王超群.网络爬虫技术研究就利用爬虫技术[7],我们系统就可以利用此项技术对地震数据抓取以积累并使用历史数据[5][8]对比,然后进行可视化分析。
类似地, 范开勇,陈宇收MySQL 数据库性能优化研究[9] 使用MySQL数据库对爬虫回来的数据进行持久化存储,因为爬虫抓取的会有大量数据,参考数据库性能优化研究就很必要,系统的好坏跟数据库设计优化息息相关。
(三)参考文献
[1] 陈剑雪.Python 程序设计课程教学研究[J.南方农机.2019.(24).
[2] 詹重咏MySQL 数据库中数据导入与导出探析.数字技术与应用2017(12):231+233.
[3] Beecham ,Matthew.Global market review of front-end modules for passenger cars and lighttrucks - forecasts to 2017: 2010 edition: Appendix 2 Q&A with PYTHONJJJust - Auto, 2018.pp.32-35.
[4] Myers D, Mcguffee J W. Choosing ScrapylJ]. Journal of Computing Sciences in Colleges.2018.31(1):83-89.
[5]Yu-Jin Kim. Tracking Dynamics between Digital Design Agencies and Clients of HybridOutsourcing in the Double Diamond Website Development Process[J. Archives of DesignResearch.2020.33(1).
[6] 蔡敏.Python 语言的 Web 开发应用分析J.无线互联科技,2019.(4)
[7] 吴俊杰.Python 语言与 javascript 语言的区别吴俊杰[J].电子制作,2019,(2).
[8] 王超群.网络爬虫技术研究[.移动信息,2016(6):00181-00182
[9] 范开勇,陈宇收MySQL 数据库性能优化研究J中国新通信,2019.21(01):57.


















 7842
7842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











