




 本文介绍了一个专注于计算机专业毕业设计的团队,他们利用Hadoop和Hive进行共享单车数据分析,包括预测和模型训练,旨在帮助学生完成项目并提供相关咨询服务。
本文介绍了一个专注于计算机专业毕业设计的团队,他们利用Hadoop和Hive进行共享单车数据分析,包括预测和模型训练,旨在帮助学生完成项目并提供相关咨询服务。
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
文章包含:项目选题 + 项目展示图片 (必看)
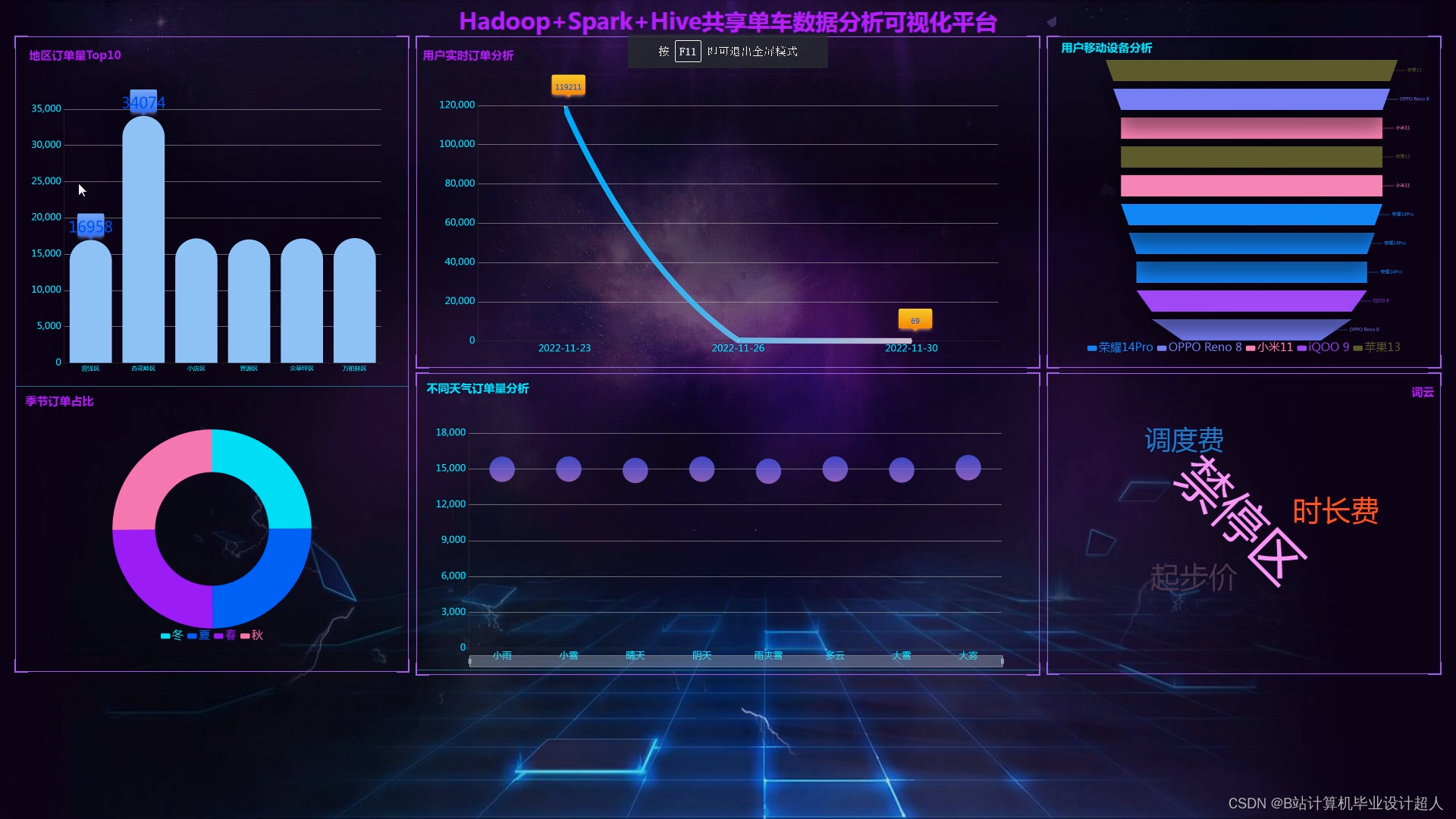
计算机毕业设计吊打导师hadoop+hive共享单车数据分析 共享单车预测 共享单车大数据 共享单车可视化 共享单车爬虫 共享单车数仓
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 假设你有一个名为'bike_data.csv'的数据集,其中包含以下列:
# 'hour_of_day' (一天中的小时), 'weather_conditions' (天气条件), 'location' (地点), 'bike_usage' (共享单车使用情况)
# 加载数据
data = pd.read_csv('bike_data.csv')
# 选择特征和目标变量
X = data[['hour_of_day', 'weather_conditions', 'location']]
y = data['bike_usage']
# 将分类变量(如天气条件和地点)转换为数值型
# 这里我们假设'weather_conditions'和'location'是分类变量
X = pd.get_dummies(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# 你可以使用模型对新数据进行预测
# 例如:
new_data = pd.DataFrame({
'hour_of_day': [10],
'weather_conditions_sunny': [1],
'weather_conditions_rainy': [0],
'weather_conditions_snowy': [0],
'location_A': [1],
'location_B': [0],
'location_C': [0]
})
predicted_usage = model.predict(new_data)
print(f"Predicted bike usage for the given conditions: {predicted_usage[0]}")


















 4057
4057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











