




 本文介绍了博主带领团队专注于计算机专业毕业设计项目,涵盖从爬虫采集数据、数据清洗、存储到数据分析、实时计算和可视化的过程,包括使用PyFlink、Hadoop和Hive技术,以及推荐系统的选装模块。
本文介绍了博主带领团队专注于计算机专业毕业设计项目,涵盖从爬虫采集数据、数据清洗、存储到数据分析、实时计算和可视化的过程,包括使用PyFlink、Hadoop和Hive技术,以及推荐系统的选装模块。
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
文章包含:项目选题 + 项目展示图片 (必看)
1.模拟生成/爬虫采集1000万条车险数据存入mysql作为数据集;
2.使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs;
3.使用hive数仓技术建表建库,导入.csv数据集;
4.离线分析采用hive_sql完成,实时分析利用Flink之Scala、FlinkSQL完成;
5.统计指标使用sqoop导入mysql数据库;
6.使用flask+echarts进行可视化大屏幕炫酷展示;
创新点/特色:
0.全新PyFlink而不是Flink!吊打一切!全网都没啥教程!属于最新最屌最流行!
1.Python爬虫/模拟数据生成;
2.可视化炫酷大屏幕;
3.虚拟机显摆敲命令碾压答辩现场(市面上全是假算法假爬虫假大数据都不带用虚拟机的);
4.1000万海量数据集;
5.Flink实时计算+Hive、Hadoop离线计算双实现有效避免导师喷你;
注意:如果还被喷项目工作量简单或者课设级别等理由不让你过,直接1秒内无缝对接选装推荐系统、后台管理、前台系统、预测算法、知识图谱等
## 可选装项目模块如下:
1.推荐系统(4种深度学习推荐算法 协同过滤基于用户 基于物品 SVD神经网络 MLP)。附带AI、支付、短信、lstm情感分析。
2.预测系统(KNN CNN RNN卷积神经预测 K-means 线性回归)。
3.知识图谱neo4j可视化关系网络图。
4.后台管理系统。
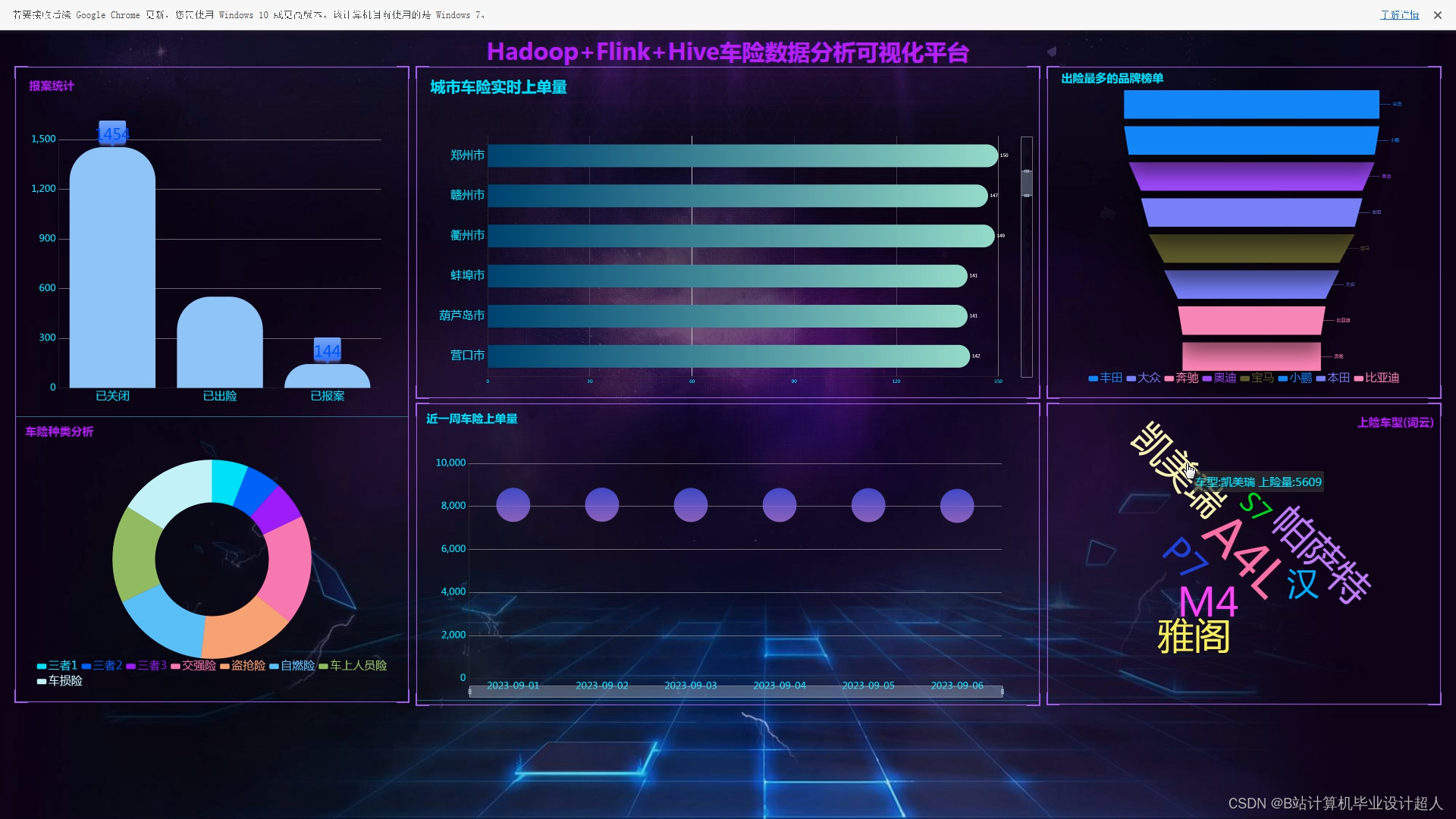
计算机毕业设计吊打导师PyFlink+Hadoop+Hive车险数据分析可视化大屏 车险推荐系统 汽车保险分析 车险爬虫 车险大数据 知识图谱 机器学习 大数据
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 假设你有一个CSV文件,其中包含用于预测车险费用的特征(如驾驶者年龄、车辆类型、驾驶记录等)和对应的车险费用
data = pd.read_csv('car_insurance_data.csv')
# 查看数据的前几行
print(data.head())
# 选择特征和目标变量
# 假设'age'是驾驶者年龄,'vehicle_type'是车辆类型(编码为数字或类别),'driving_record'是驾驶记录(可能是违规次数或类似指标),'insurance_cost'是车险费用
X = data[['age', 'vehicle_type', 'driving_record']]
y = data['insurance_cost']
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测测试集的车险费用
y_pred = model.predict(X_test)
# 计算均方误差和R^2得分
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R^2 Score: {r2}")
# 可视化结果(可选)
import matplotlib.pyplot as plt
plt.scatter(y_test, y_pred)
plt.xlabel('Actual Insurance Cost')
plt.ylabel('Predicted Insurance Cost')
plt.title('Actual vs Predicted Insurance Cost')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=4)
plt.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











