




 一位拥有100万粉丝的软件研发专家介绍其工作室,专注于计算机专业毕设项目实战,提供代码分析和爬虫技术,包括如何使用requests和BeautifulSoup抓取Steam游戏信息作为实例。
一位拥有100万粉丝的软件研发专家介绍其工作室,专注于计算机专业毕设项目实战,提供代码分析和爬虫技术,包括如何使用requests和BeautifulSoup抓取Steam游戏信息作为实例。
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
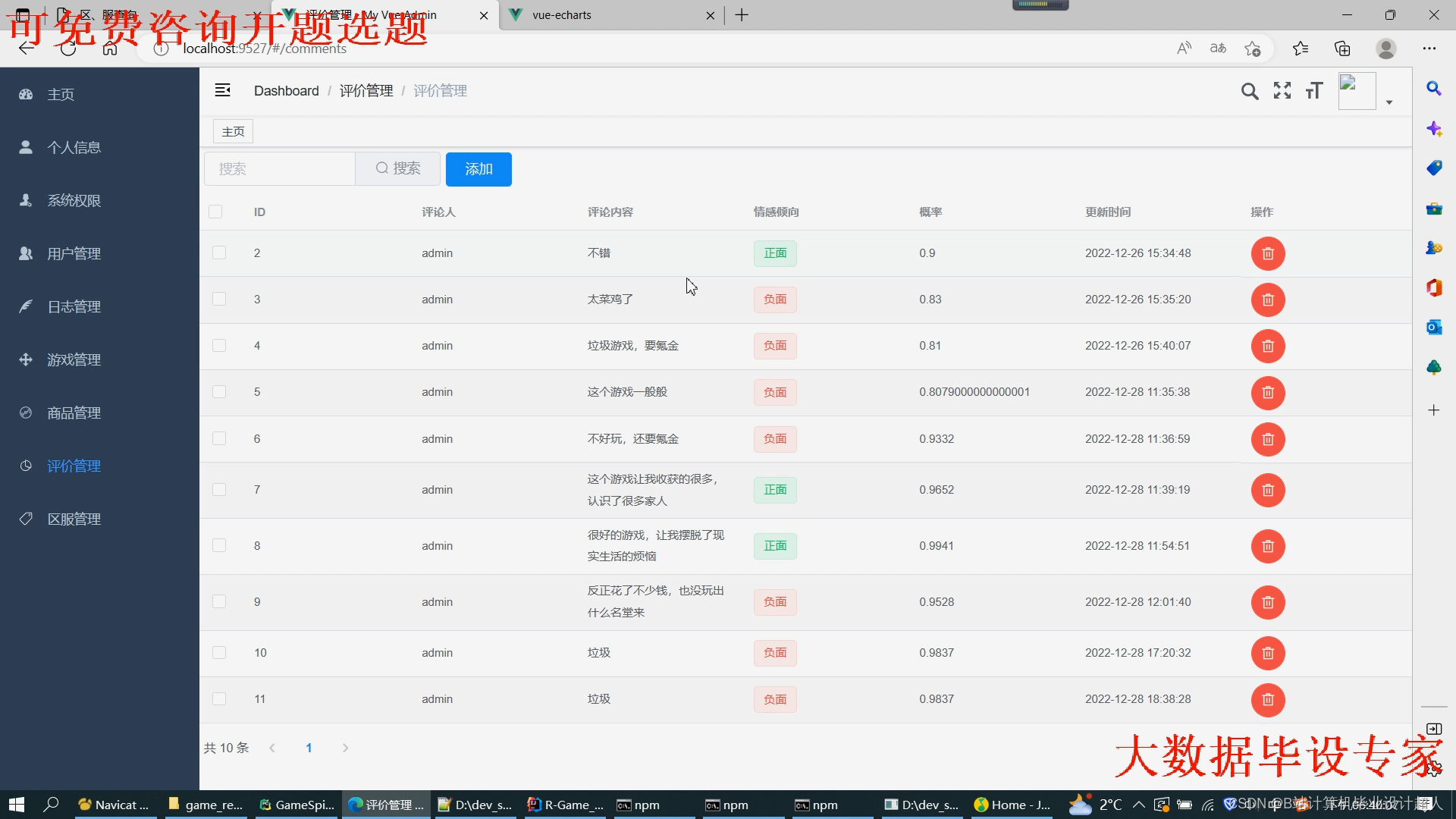
文章包含:项目选题 + 项目展示图片 (必看)

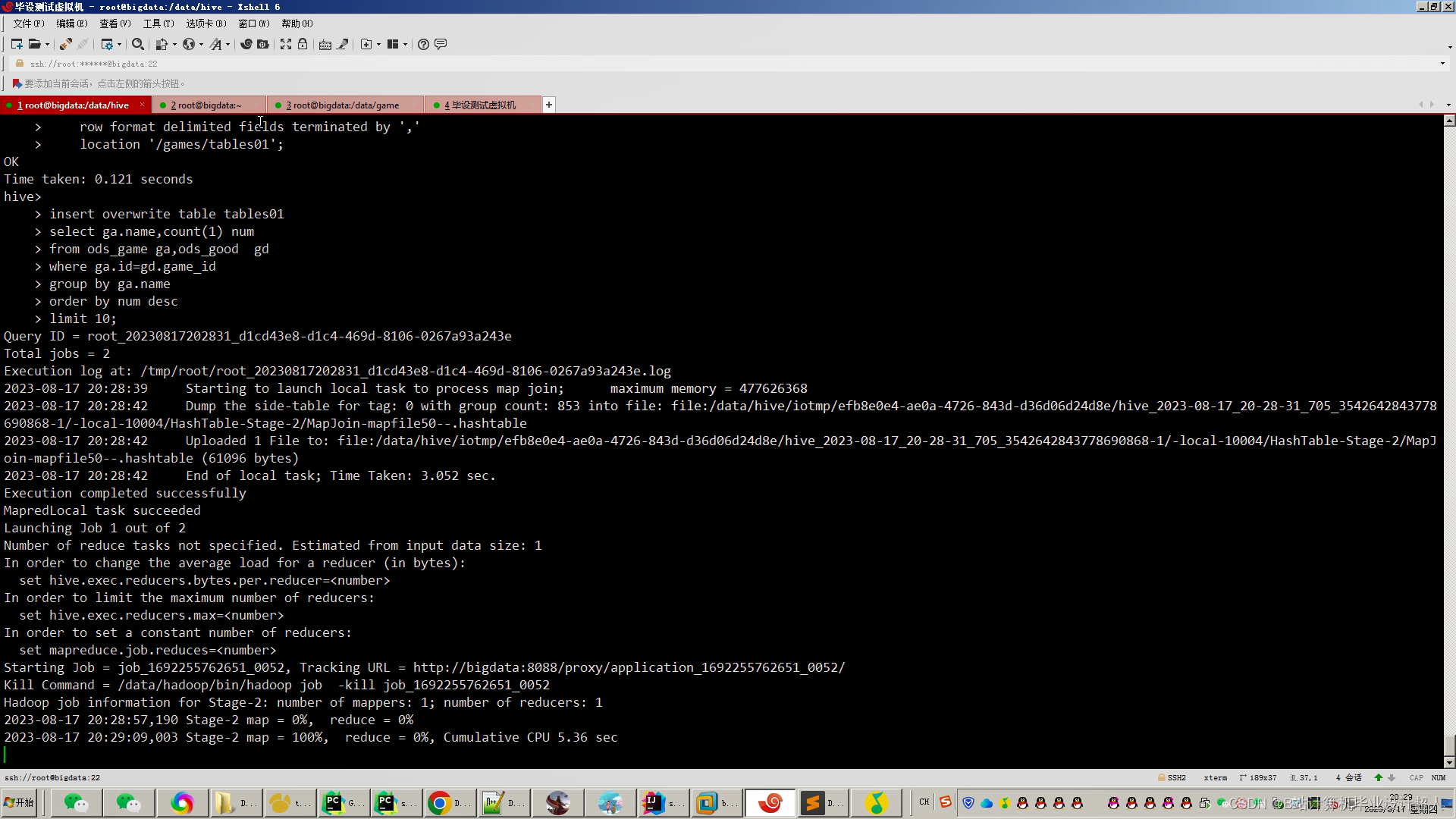
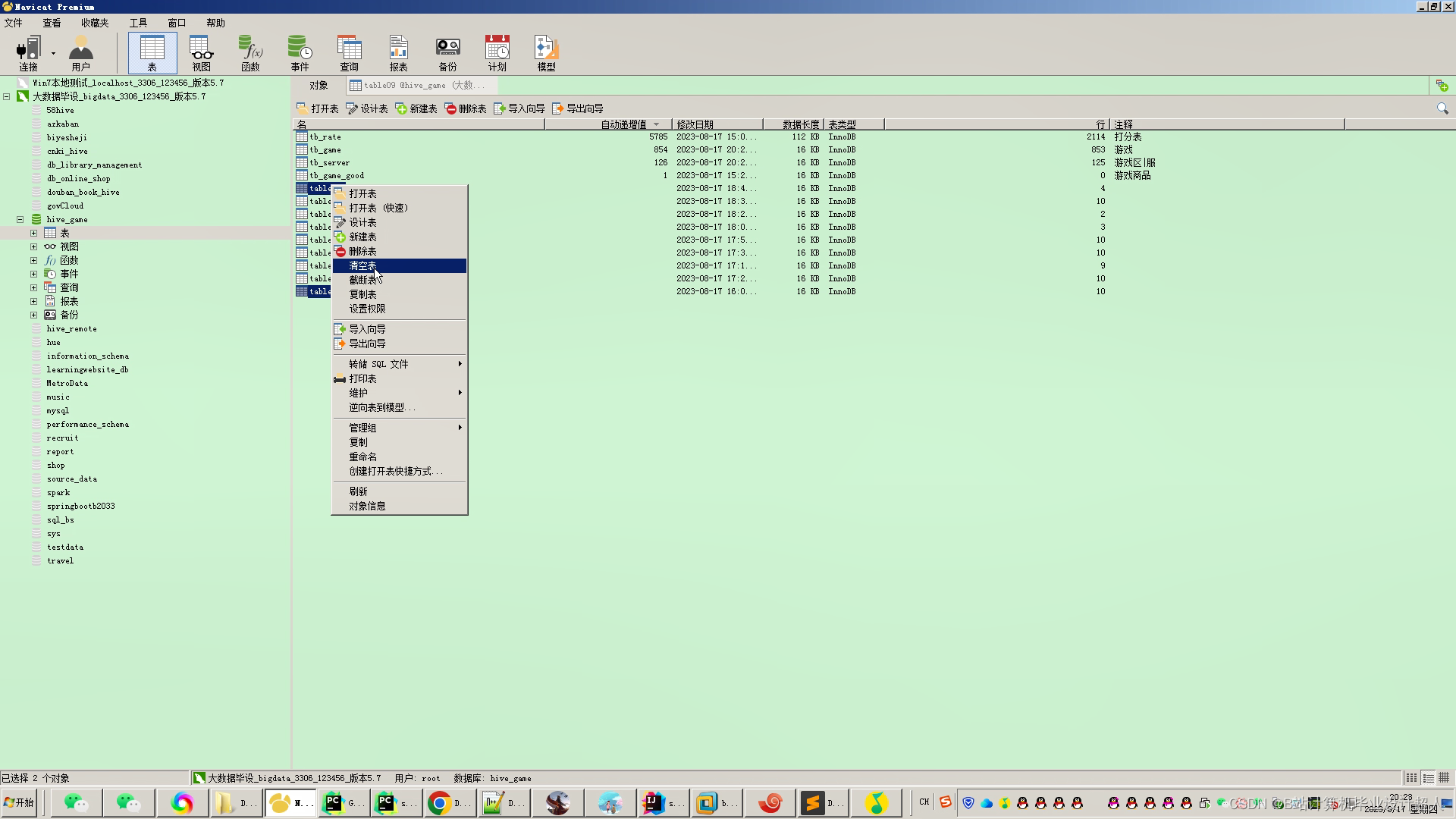
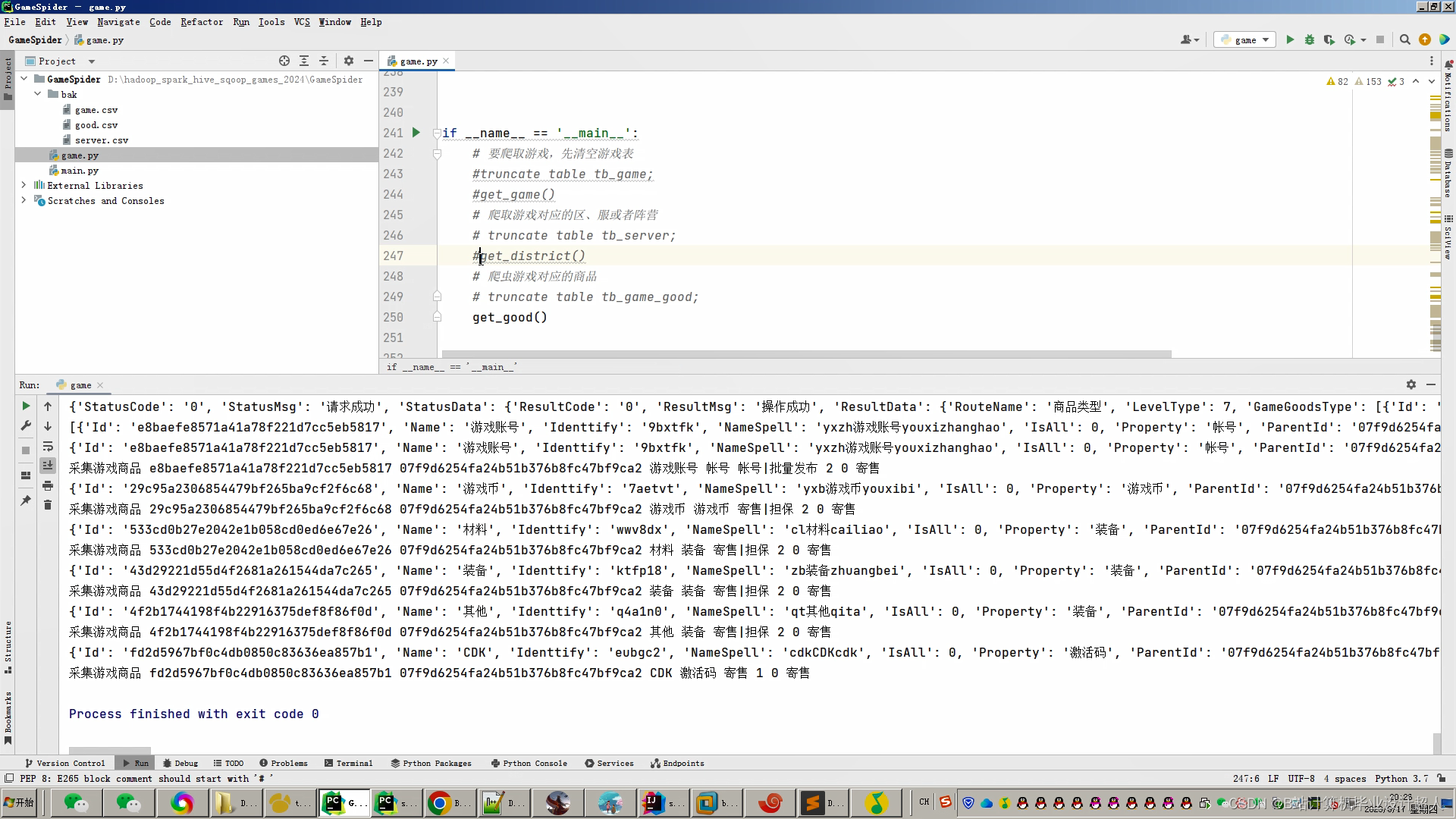
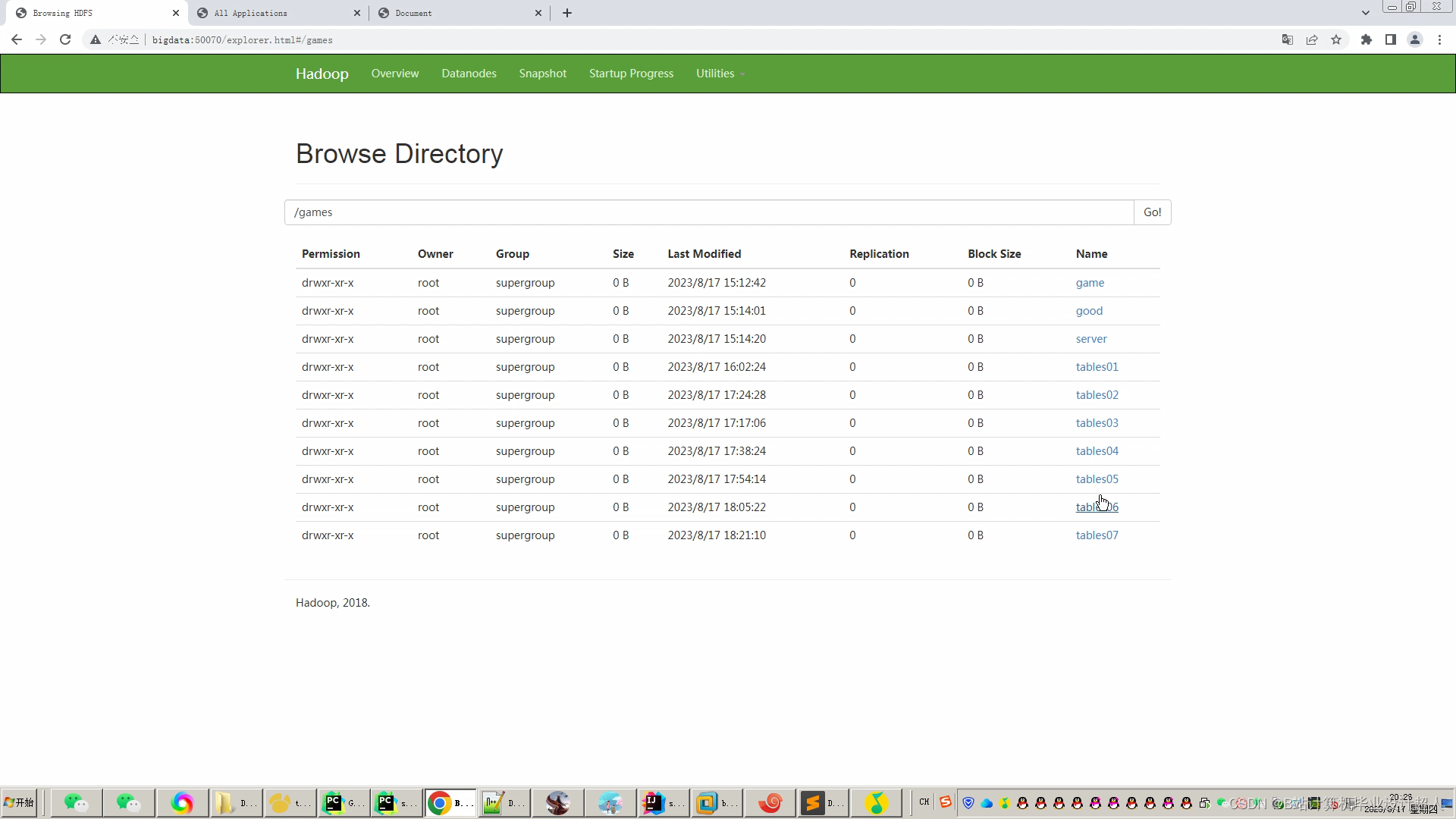
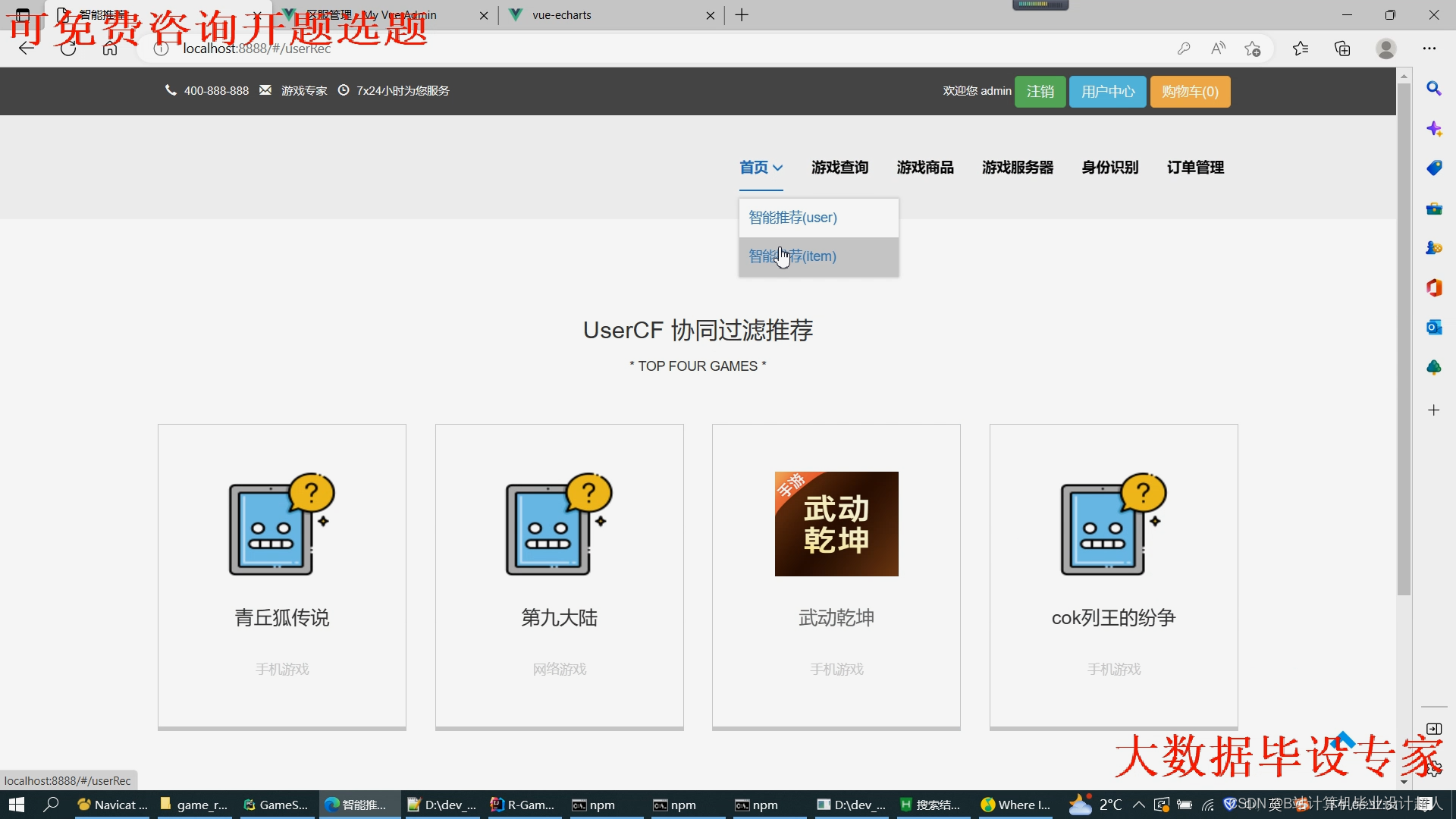
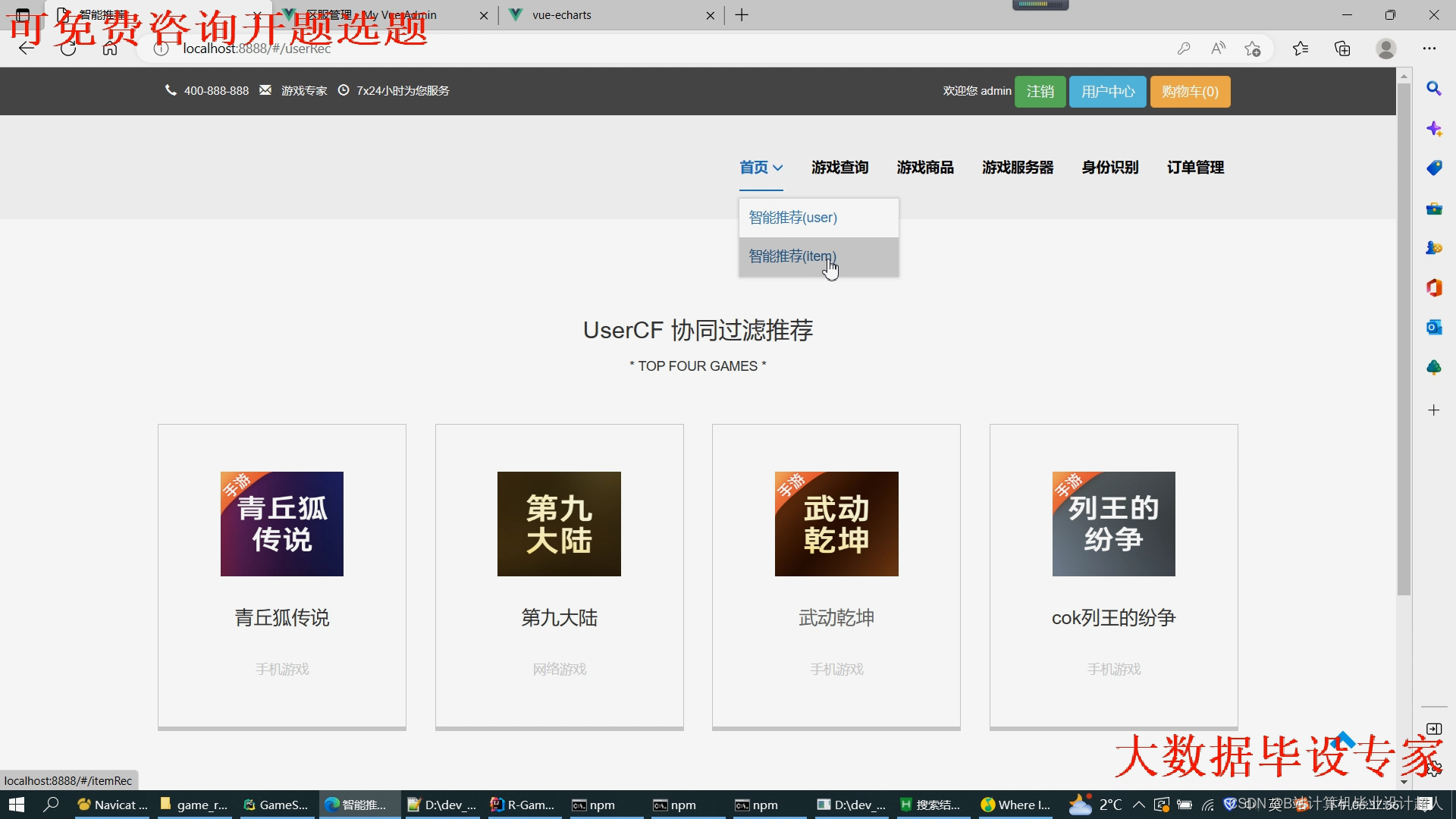
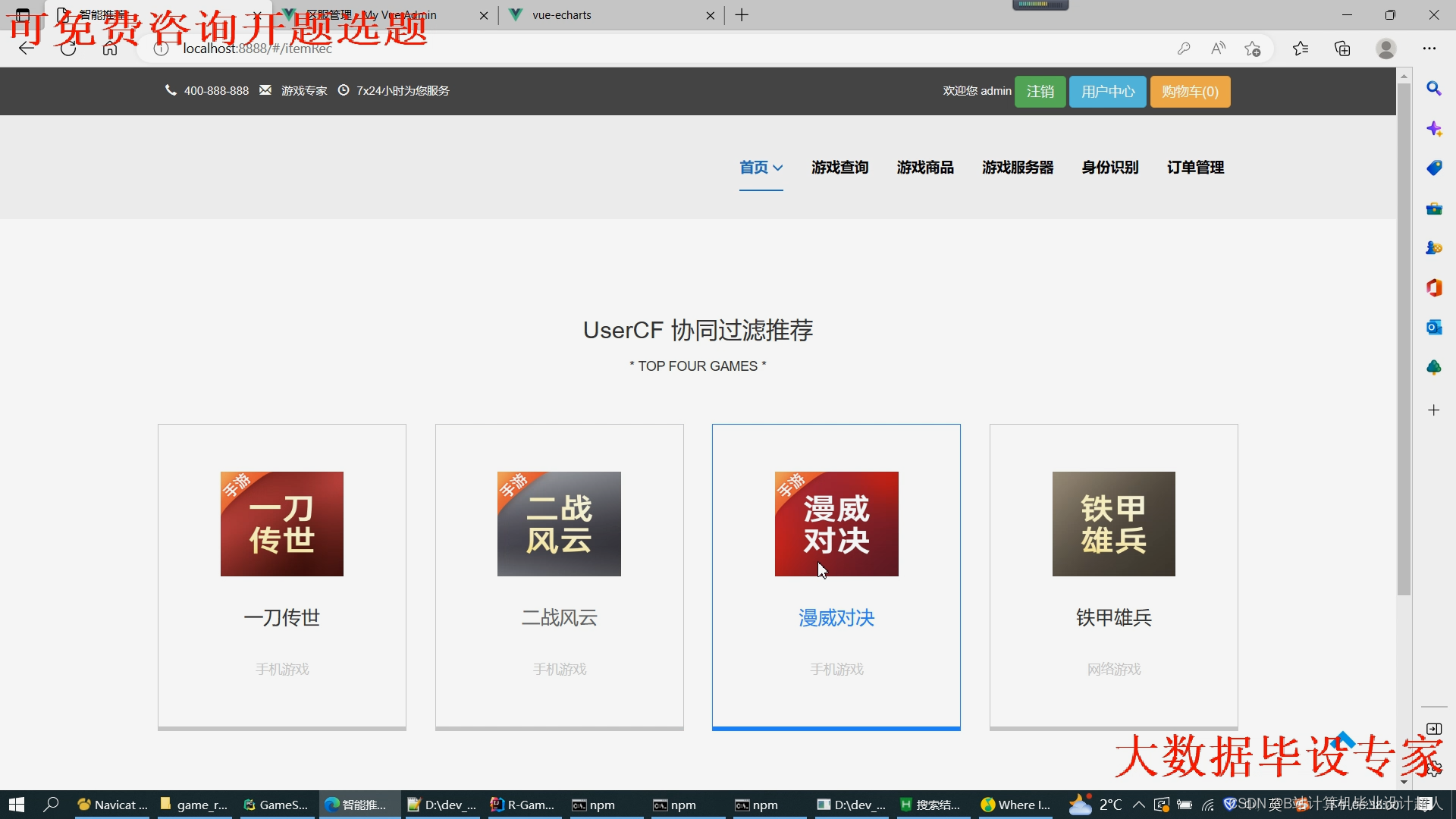
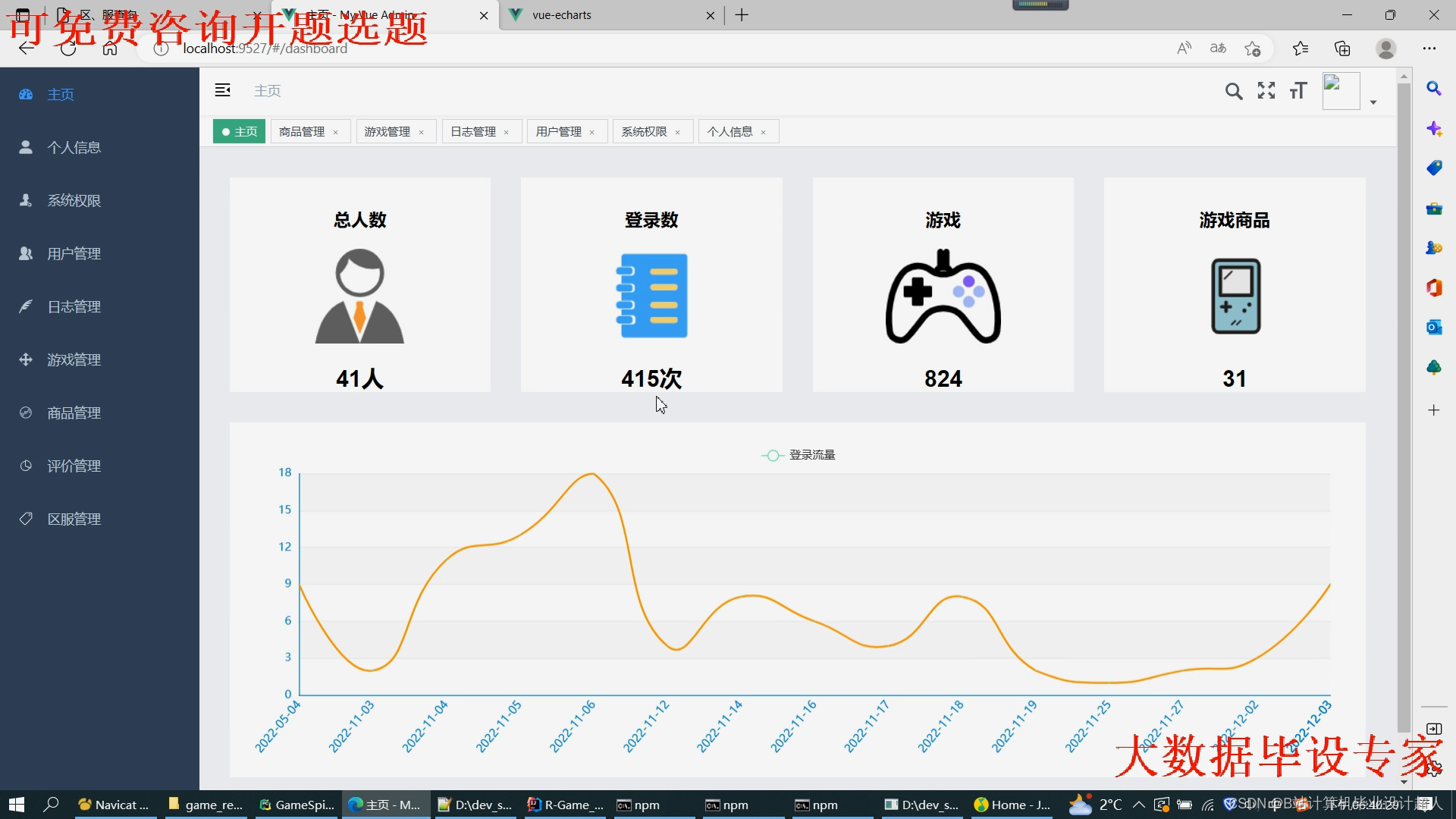
代码分析解析分享如下:
import requests
from bs4 import BeautifulSoup
def get_steam_game_info(game_id):
# 构建Steam游戏页面的URL
url = f"https://store.steampowered.com/app/{game_id}/"
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 发送请求
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code != 200:
print(f"Failed to retrieve page for game ID {game_id}. Status code: {response.status_code}")
return None
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.content, 'html.parser')
# 提取游戏名称
title = soup.find("div", class_="apphub_AppName").text.strip()
# 提取其他所需信息,例如价格、发行日期、开发者等
# 这里只是示例,具体信息的位置可能会随Steam网站布局的变化而变化
# 返回游戏信息
return {
'title': title,
# 'price': price, # 需要根据页面结构提取
# 'release_date': release_date, # 需要根据页面结构提取
# ...
}
# 示例:爬取游戏ID为730的游戏信息(这通常是Dota 2的ID)
game_info = get_steam_game_info(730)
if game_info:
print(game_info)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











