




 本文是关于Ruia异步爬虫框架的快速入门教程,通过爬取Hacker News实例,介绍如何定义Item、测试、编写Spider、运行及扩展功能,包括Middleware和MongoDB数据持久化。
本文是关于Ruia异步爬虫框架的快速入门教程,通过爬取Hacker News实例,介绍如何定义Item、测试、编写Spider、运行及扩展功能,包括Middleware和MongoDB数据持久化。

基于Ruia快速实现一个以Hacker News为目标的爬虫
概述
Ruia是一个基于asyncio和aiohttp的异步爬虫框架,目标在于让开发者编写爬虫尽可能地方便快速。
写更少的代码,获取更快的运行速度:
- 教程:中文文档 |documentation
- Github 组织: python-ruia
- 插件:awesome-ruia(你贡献的任何插件都是值得赞赏且可贵的!)
特性
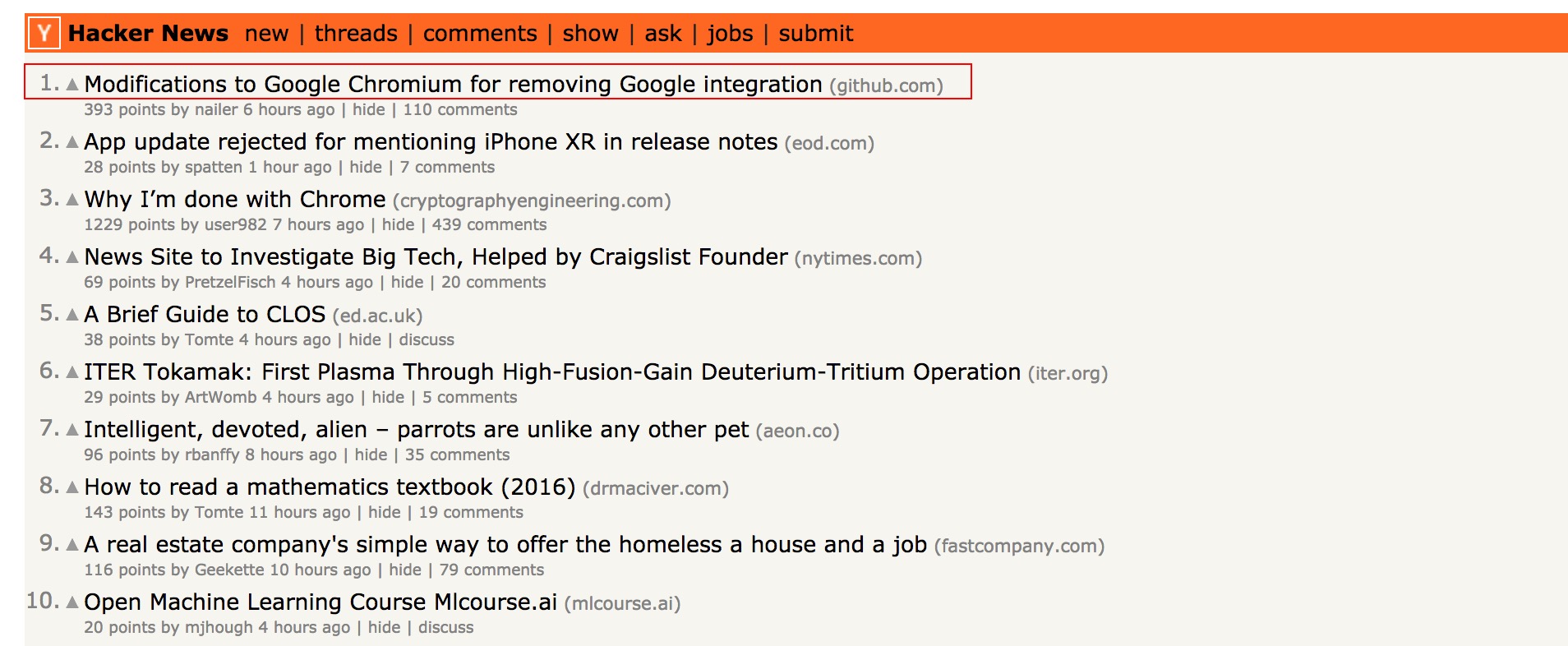
本文主要通过对Hacker News的爬取示例来展示如何使用Ruia,下图红框中的数据就是爬虫脚本需要爬取的目标:
开始前的准备工作:
-
确定已经安装Ruia:
pip install ruia -U -
确定可以访问Hacker News
第一步:定义 Item
Item的目的是定义目标网站中你需要爬取的数据,此时,爬虫的目标数据就是页面中的Title和Url,怎么提取数据,Ruia的Field类提供了以下三种方式提取目标数据:
这里我们使用CSS Selector来提取目标数据,用浏览器打开Hacker News,右键审查元素:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1593
1593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









