






引言
多线程环境下,我们通常会使用线程安全的 ConcurrentHashMap 或 Hashtable。然而,Hashtable 逐渐被淘汰,而 ConcurrentHashMap 成为了主流选择。那么,Hashtable 为什么会被淘汰?它和 ConcurrentHashMap 之间存在哪些关键区别?本文将围绕这些高频面试问题展开。
ConcurrentHashMap和hashtable都是线程安全的,他们的区别主要体现在实现线程安全的机制有所不同。
1. Hashtable 的线程安全机制
Hashtable 通过 synchronized 关键字对所有方法进行加锁,从而保证线程安全。例如,get() 和 put() 方法都被 synchronized 修饰:
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
for (Entry<?,?> e = tab[(hash & 0x7FFFFFFF) % tab.length];
e != null; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
虽然这种方式保证了线程安全,但由于锁是作用于整个 Hashtable 实例的,这导致所有线程访问该对象时都必须等待锁释放,即使是不同的线程访问不同的键,它们仍然会被串行化处理,无法真正实现高并发。
2. ConcurrentHashMap 的线程安全机制
ConcurrentHashMap 采用了更高效的机制来保证线程安全,JDK1.7及之前和JDK1.8及之后采用了不同的实现方式。
2.1 JDK 1.7 及之前的 ConcurrentHashMap
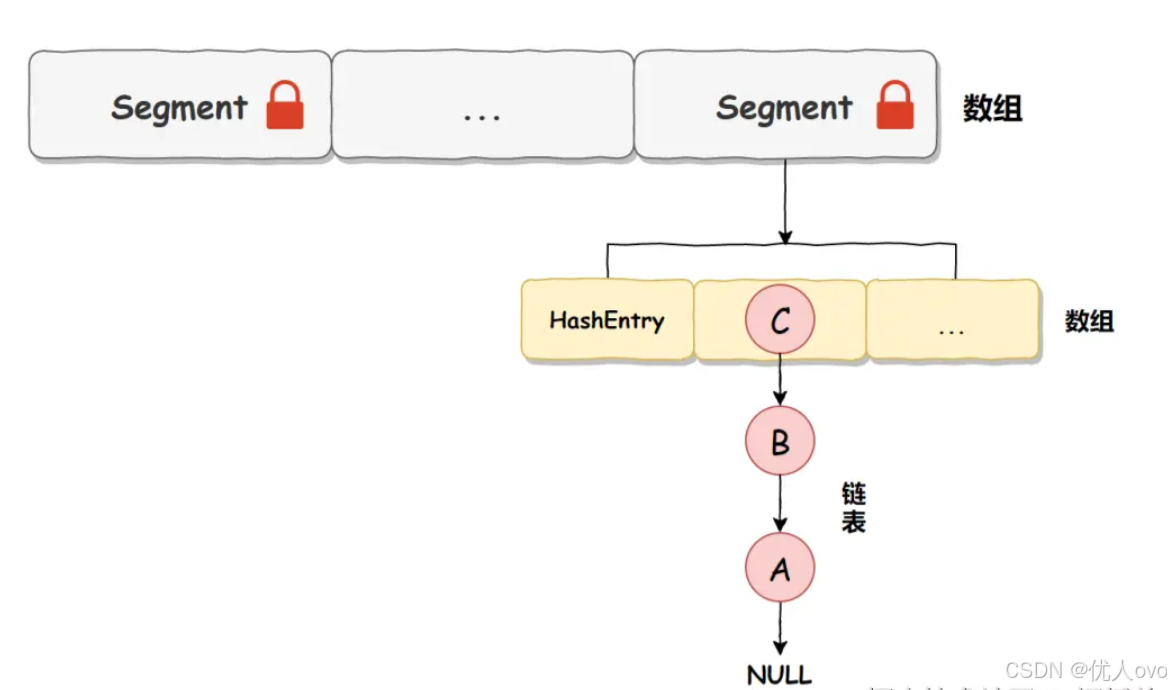
在 JDK 1.7 及之前,ConcurrentHashMap 采用 分段锁(Segment Lock) 来提高并发能力。
- 内部结构是 Segment + HashEntry 数组,其中 Segment 类似于小型 Hashtable,每个 Segment 维护一部分数据。
- 通过 ReentrantLock(可重入锁)来控制对不同 Segment 的访问,使得多个线程可以并发访问不同的 Segment。 内部结构是 Segment + HashEntry 数组,其中 Segment 类似于小型 Hashtable,每个 Segment 维护一部分数据。 通过 ReentrantLock(可重入锁)来控制对不同 Segment 的访问,使得多个线程可以并发访问不同的 Segment。
2.2 JDK 1.8 及之后的 ConcurrentHashMap
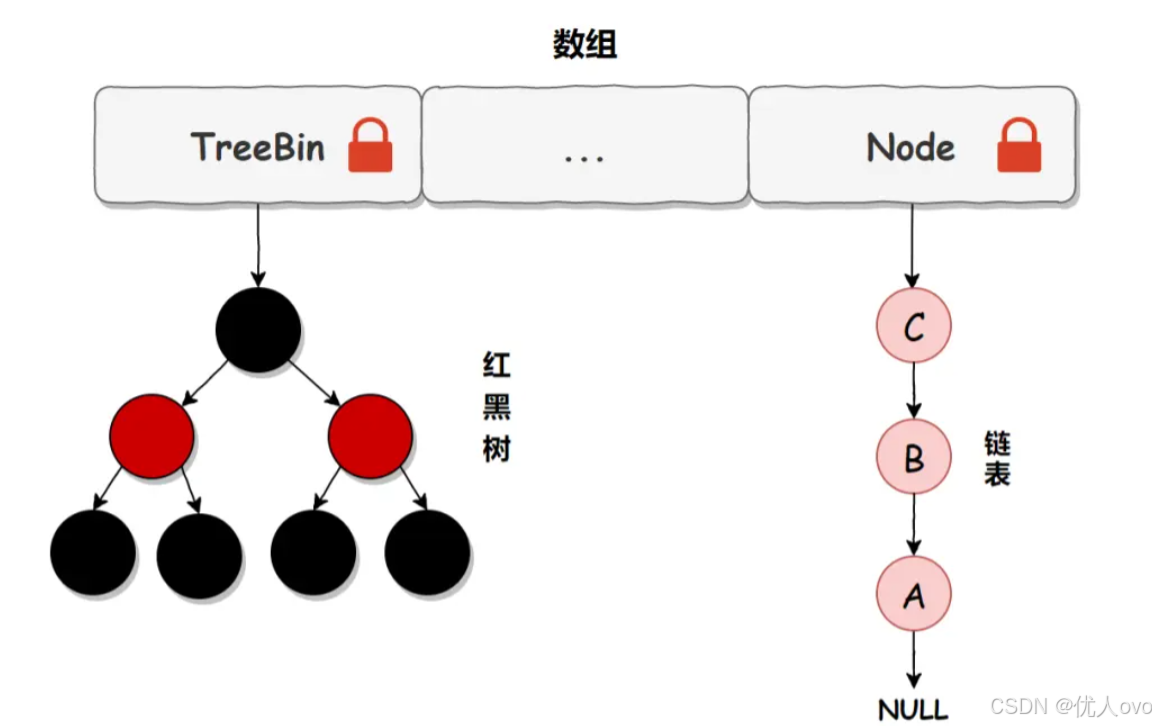
JDK 1.8 之后,ConcurrentHashMap主要做出了以下三点优化:
- 采用 Node 数组 + 链表 + 红黑树 结构,锁加在Node上,也就是数组中每个桶位的链表的头节点上(或是红黑树的的根节点上)。
- 使用volatile+ CAS + synchronized 机制减少锁冲突,提高并发能力。
- 当链表长度超过 8 时,转换为 红黑树,提高查询效率(从 O(n) 降到 O(logn))(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)。
线程向ConcurrentHashMap中添加元素时的过程如下:
-
初始化检查:首先判断 ConcurrentHashMap是否为空,如果为空,则使用 volatile + CAS 进行初始化,以确保线程安全的延迟加载。
-
定位桶索引并尝试插入:计算键的哈希值,根据哈希值确定数据存储的索引位置。
- 如果该位置为空,则使用 CAS 插入新节点。
// 在 tab[i] 表示哈希表中索引为i的桶位的头节点
if (tab == null || (f = tab[i = (n - 1) & hash]) == null) {
// 在 tab[i] 仍然是 null 的情况下原子性地插入新节点
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break;
}
3. 解决哈希冲突:如果该位置已存在数据(即哈希冲突),则使用 synchronized 进行加锁,并遍历链表。
// 锁住当前桶位的头节点,防止其他线程同时修改该链表
synchronized (f) {
// 双重检查:如果头节点仍然是 f,则执行插入或更新操作,保证数据一致性
if (tab[i] == f) {
// 进行插入或更新操作
}
}
-
扩容:若链表长度超过 8,则将链表转换为 红黑树,提高查询效率(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)。
-
完成插入:操作完成后,ConcurrentHashMap通过 volatile 确保数据可见性,并通知其他线程更新状态。
JDK 1.8 之后的ConcurrentHashMap相比于JDK1.7之前的ConcurrentHashMap有以下优点:
- 锁的粒度更小:JDK 1.8 之后 ConcurrentHashMap采用 Node 级别锁 而非 Segment,减少了锁冲突,提高并发度。
- volatile + CAS +
synchronized机制:在多线程环境下,利用 CAS 操作进行无锁更新,提高效率。 - 红黑树优化查询:当桶中链表过长时,自动转换为红黑树,提高查询速度。

















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









