






问题:配置好路径后,使用YOLO v9进行分割任务时train.py”出现“RuntimeError: shape '[32, 68, -1]' is invalid for input of size 268800”错误。
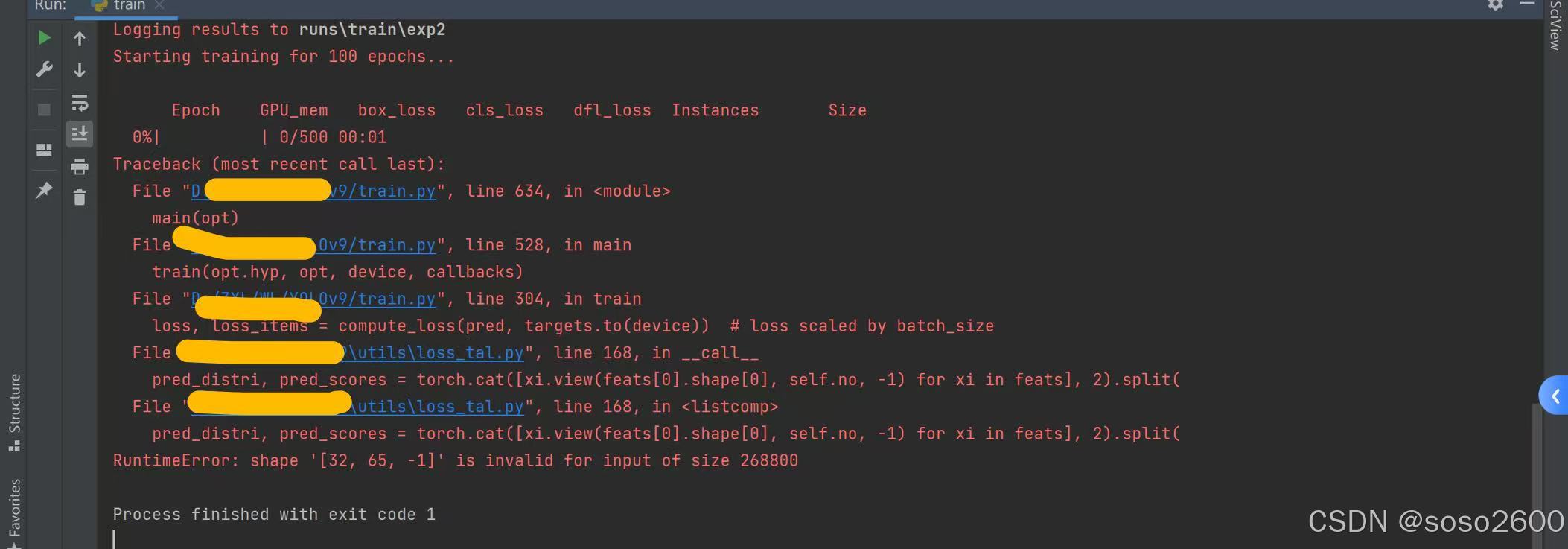
原因:使用了错误的文件——"train.py",如下图。执行的是分割任务,使用的是目标检测的训练文件。
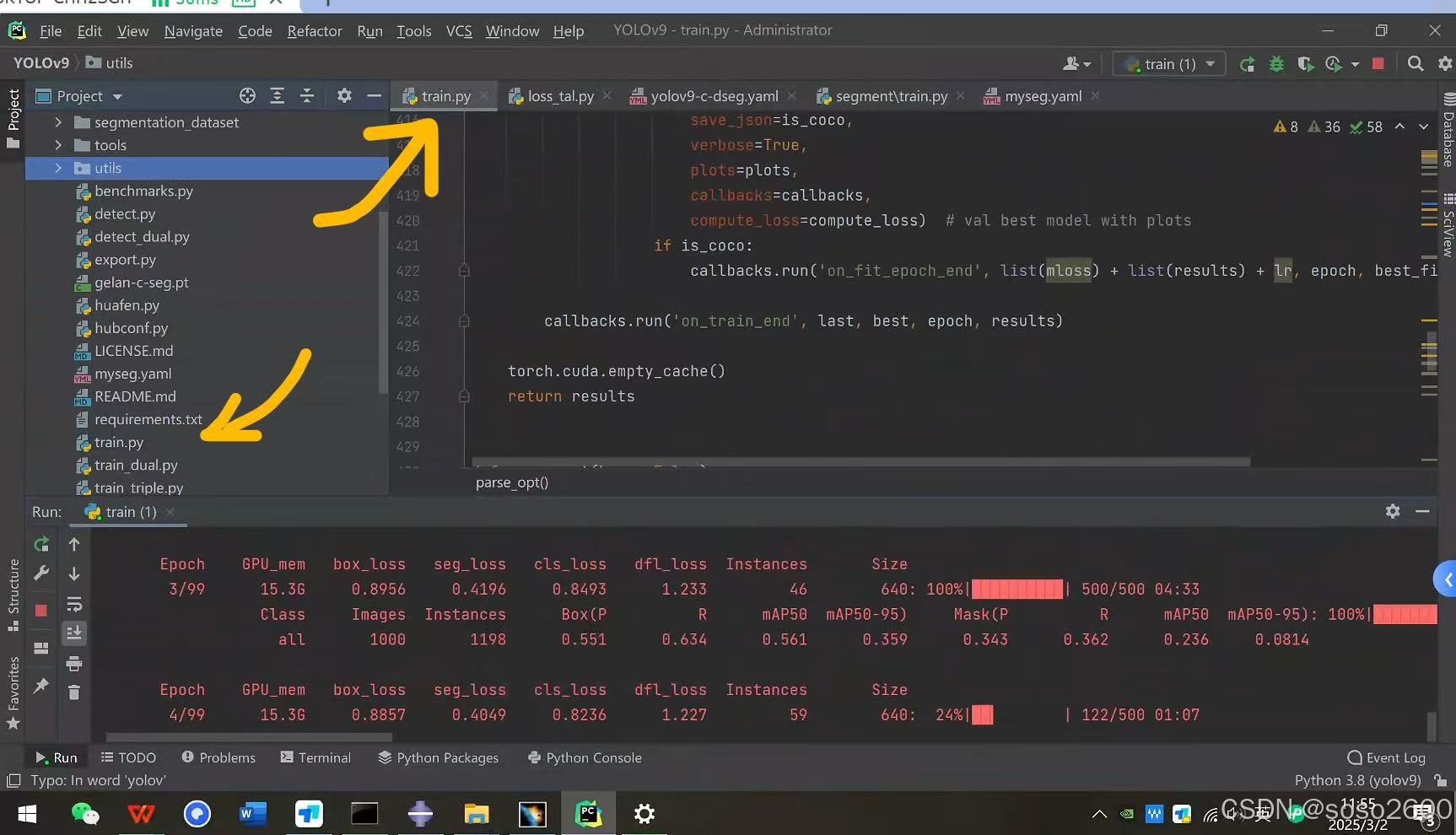
解决方法:使用':/yolov9/segment/train.py'目录下的'train.py'文件,更改数据集、模型等路径后执行分割任务即可解决。更改路径参考https://blog.youkuaiyun.com/heart_warmonger/article/details/136249119
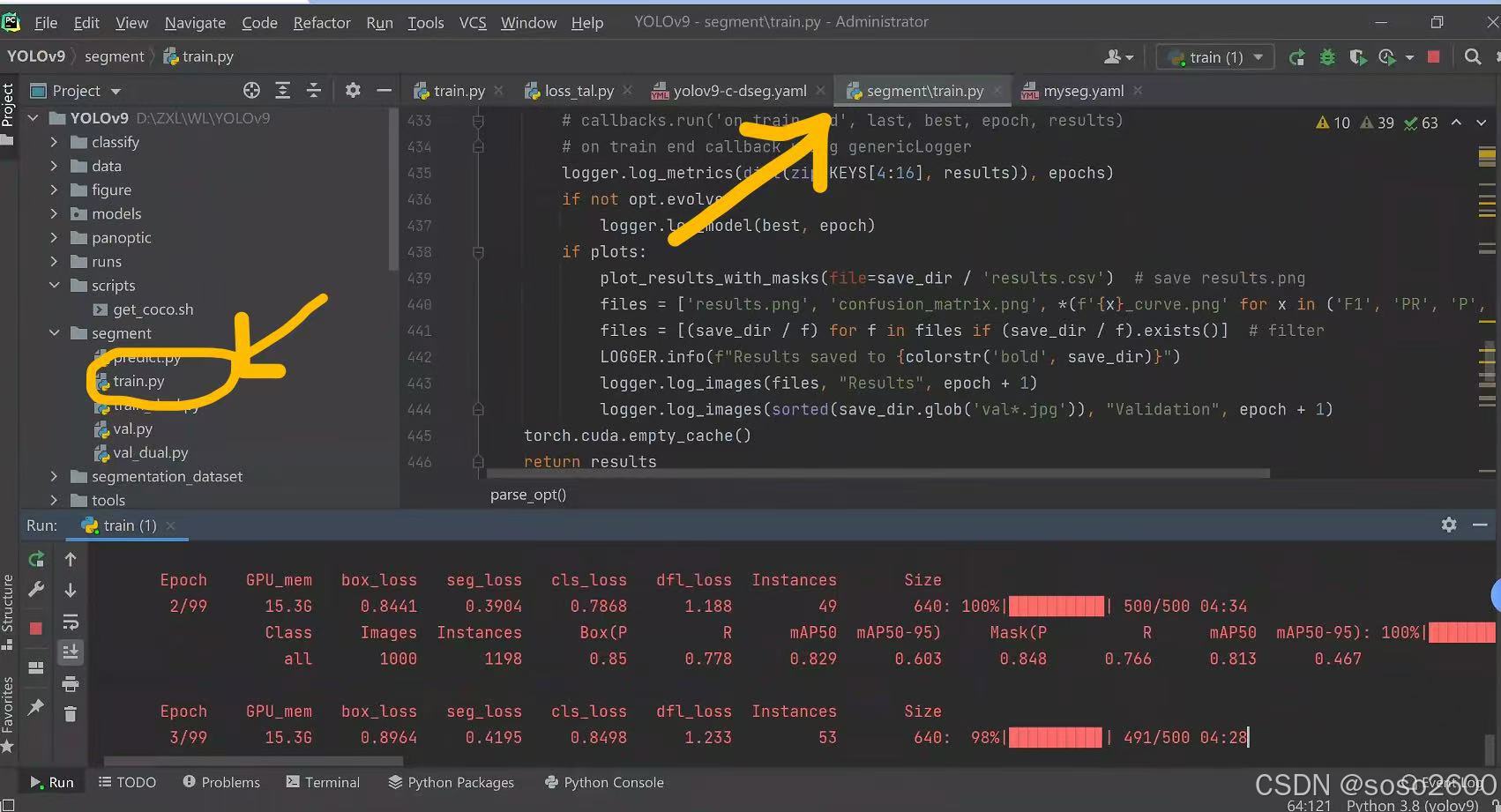
可能您的问题不是由此原因引起的,可以检查您的配置和YAML文件或者参考其他方案。

















 3822
3822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









