







 EM算法是一种用于含有隐变量的概率模型参数估计的迭代方法。本文详细介绍了EM算法的原理,包括E步和M步,并展示了其在NLP自动文本分类中的应用,通过随机选择初始中心,不断迭代更新类中心直至收敛。此外,还给出了一个三硬币模型的简单实例及其Python实现,帮助理解EM算法的工作机制。
EM算法是一种用于含有隐变量的概率模型参数估计的迭代方法。本文详细介绍了EM算法的原理,包括E步和M步,并展示了其在NLP自动文本分类中的应用,通过随机选择初始中心,不断迭代更新类中心直至收敛。此外,还给出了一个三硬币模型的简单实例及其Python实现,帮助理解EM算法的工作机制。
EM算法是一种迭代算法,全称为期望极大算法(expectation maximization algorithm),用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计。
一、EM算法的原理
EM算法
输入:观测变量数据Y,隐变量数据Z,联合分布P(Y,Z|θ),条件分布P(Z|Y,θ);
输出:模型参数θ
(1)选择参数的初值θ0,开始迭代;
(2)E步:记θi为第i次迭代参数θ的估计值,在第i+1次迭代的E步,计算
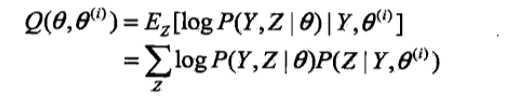
这里,P(Z|Y,θi)是在给定观测数据Y和当前的参数估计θi下隐变量数据Z的条件概率分布;
(3)M步:求使Q(θ,θi)极大化的θ,确定第i+1次迭代的参数的估计值θi+1
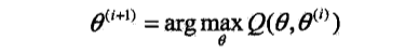
(4)重复第(2)步和第(3)步,直到收敛。
其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









