



 本文深入探讨Kafka的三大关键能力:发布与订阅、容错存储及处理记录流,详细解析其在构建实时数据管道和流应用程序的应用场景。涵盖四大API(Produce、Consumer、Stream、Connector)、Topic管理、负载均衡、地域复制等特性,同时对比生产者与消费者的负载均衡策略,阐述消息持久性保障与命名规则。此外,详述Producer、Consumer和Broker的配置参数,如acks、buffer.memory、auto.offset.reset等,帮助读者掌握Kafka的高效配置与优化。
本文深入探讨Kafka的三大关键能力:发布与订阅、容错存储及处理记录流,详细解析其在构建实时数据管道和流应用程序的应用场景。涵盖四大API(Produce、Consumer、Stream、Connector)、Topic管理、负载均衡、地域复制等特性,同时对比生产者与消费者的负载均衡策略,阐述消息持久性保障与命名规则。此外,详述Producer、Consumer和Broker的配置参数,如acks、buffer.memory、auto.offset.reset等,帮助读者掌握Kafka的高效配置与优化。
一.概述
1.三个关键能力
a.发布和订阅记录流
b.容错存储记录流
c.处理记录流
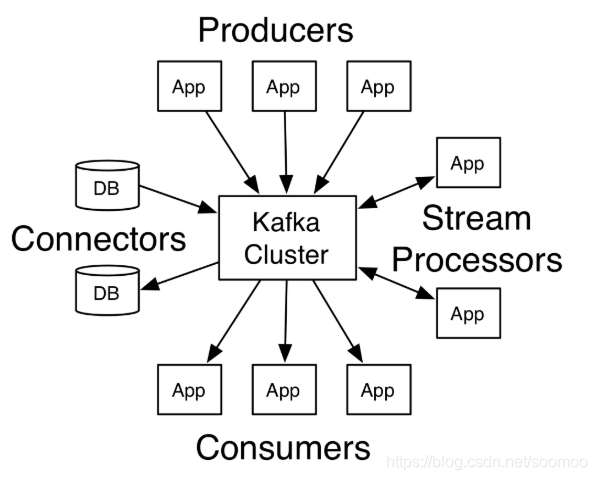
2.两个应用场景
a.构建系统和应用之间可靠获取数据的实时流数据管道
b.构建转换或响应数据流的实时流应用程序
3.概念
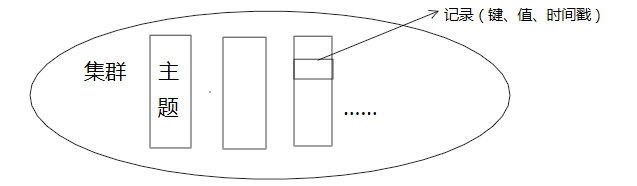
4.API
a.Produce API
b.Consumer API
c.Stream API
d.Connector API
5.Topic and logs
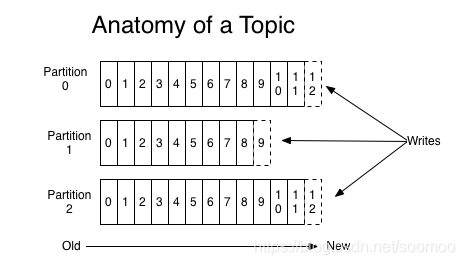
a.可设置存储期限
b.可读取任意位置信息
c.一个主题可以有多个partition
6.负载均衡
7.地域复制
8.生产者
a.循环分区实现负载均衡
b.语义分区
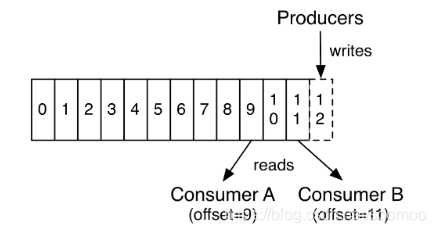
9.消费者
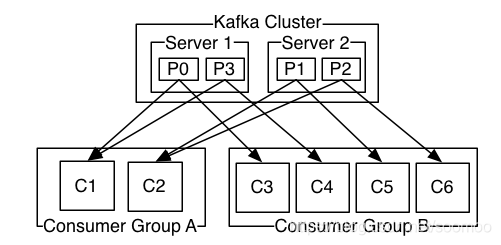
a.相同组的实例负载均衡,不同组的实例广播
b.同一组的不同实例负责不同分区,每个实例只能获**取部分log
10.保证
a.消息按发送顺序在log中存偏移量
b.消费者看到的消息按日志中偏移量
c.具有复制因子n的主题允许n-1个服务器故障
11.名词辨析
a.broker
b.leader、follower
二.命令行执行
- 下载code
- 安装
- 创建topic
- 发送消息
- 创建消费者
- 设置集群
- 事务使用Kafka connect导入、导出数据
- 用kafka streams处理数据
三.配置
1.Producer
a.参数
| 参数 | 默认值 | 可填值 | 说明 |
|---|---|---|---|
| key.serializer | key的序列化类(实现序列化接口) | ||
| value.serializer | value的序列化类(实现序列化接口) | ||
| acks | 1 | [all, -1, 0, 1] | 生产者需要leader确认请求完成之前接收的应答数。此配置控制了发送消息的耐用性,支持以下配置:acks=0 如果设置为0,那么生产者将不等待任何消息确认。消息将立刻添加到socket缓冲区并考虑发送。在这种情况下不能保障消息被服务器接收到。并且重试机制不会生效(因为客户端不知道故障了没有)。每个消息返回的offset始终设置为-1。acks=1,这意味着leader写入消息到本地日志就立即响应,而不等待所有follower应答。在这种情况下,如果响应消息之后但follower还未复制之前leader立即故障,那么消息将会丢失。acks=all 这意味着leader将等待所有副本同步后应答消息。此配置保障消息不会丢失(只要至少有一个同步的副本或者)。这是最强壮的可用性保障。等价于acks=-1。 |
| bootstrap.servers | host/port列表,用于初始化建立和Kafka集群的连接。列表格式为:host1:port1,host2:port2,…,无需添加所有的集群地址,kafka会根据提供的地址发现其他的地址(你可以多提供几个,以防提供的服务器关闭) | ||
| buffer.memory | 生产者用来缓存等待发送到服务器的消息的内存总字节数。如果消息发送比可传递到服务器的快,生产者将阻塞max.block.ms之后,抛出异常。此设置应该大致的对应生产者将要使用的总内存,但不是硬约束,因为生产者所使用的所有内存都用于缓冲。一些额外的内存将用于压缩(如果启动压缩),以及用于保持发送中的请求。 | ||
| compression.type | 33554432 | [0,…] | 数据压缩的类型。默认为空(就是不压缩)。有效的值有 none,gzip,snappy, 或 lz4。压缩全部的数据批,因此批的效果也将影响压缩的比率(更多的批次意味着更好的压缩)。 |
| retries | 0 | [0,…,2147483647] | 送失败则会重新发送。注意,这个重试功能和客户端在接到错误之后重新发送没什么不同。如果max.in.flight.requests.per.connection没有设置为1,有可能改变消息发送的顺序,因为如果2个批次发送到一个分区中,并第一个失败了并重试,但是第二个成功了,那么第二个批次将超过第一个。 |
| batch.size | 16384 | [0,…] | 当多个消息要发送到相同分区的时,生产者尝试将消息批量打包在一起,以减少请求交互。这样有助于客户端和服务端的性能提升。该配置的默认批次大小(以字节为单位):不会打包大于此配置大小的消息。发送到broker的请求将包含多个批次,每个分区一个,用于发送数据。较小的批次大小有可能降低吞吐量(批次大小为0则完全禁用批处理)。一个非常大的批次大小可能更浪费内存。因为我们会预先分配这个资源。 |
| client.id | “” | 当发出请求时传递给服务器的id字符串。这样做的目的是允许服务器请求记录记录这个【逻辑应用名】,这样能够追踪请求的源,而不仅仅只是ip/prot。 | |
| linger.ms | 0 | [0,…] | 生产者组将发送的消息组合成单个批量请求。正常情况下,只有消息到达的速度比发送速度快的情况下才会出现。但是,在某些情况下,即使在适度的负载下,客户端也可能希望减少请求数量。此设置通过添加少量人为延迟来实现。- 也就是说,不是立即发出一个消息,生产者将等待一个给定的延迟,以便和其他的消息可以组合成一个批次。这类似于Nagle在TCP中的算法。此设置给出批量延迟的上限:一旦我们达到分区的batch.size值的记录,将立即发送,不管这个设置如何,但是,如果比这个小,我们将在指定的“linger”时间内等待更多的消息加入。此设置默认为0(即无延迟)。假设,设置 linger.ms=5,将达到减少发送的请求数量的效果,但对于在没有负载情况,将增加5ms的延迟。 |
| max.block.ms | 60000 | [0,…] | 该配置控制 KafkaProducer.send() 和 KafkaProducer.partitionsFor() 将阻塞多长时间。此外这些方法被阻止,也可能是因为缓冲区已满或元数据不可用。在用户提供的序列化程序或分区器中的锁定不会计入此超时。 |
| transactional.id | null | 用于事务传递的TransactionalId。这样可以跨多个生产者会话的可靠性语义,因为它允许客户端保证在开始任何新事务之前使用相同的TransactionalId的事务已经完成。如果没有提供TransactionalId,则生产者被限制为幂等传递。请注意,如果配置了TransactionalId,则必须启用enable.idempotence。 默认值为空,这意味着无法使用事务。 | |
| enable.idempotence | false | 当设置为‘true’,生产者将确保每个消息正好一次复制写入到stream。如果‘false’,由于broker故障,生产者重试。即,可以在流中写入重试的消息。此设置默认是‘false’。请注意,启用幂等式需要将max.in.flight.requests.per.connection设置为1,重试次数不能为零。另外acks必须设置为“全部”。如果这些值保持默认值,我们将覆盖默认值。 如果这些值设置为与幂等生成器不兼容的值,则将抛出一个ConfigException异常。如果这些值设置为与幂等生成器不兼容的值,则将抛出一个ConfigException异常。 | |
| buffer.memory | 控制生产者可用于缓冲的内存总量。如果记录的发送速度快于它们可以发送到服务器的速度,那么这个缓冲区空间将耗尽。当缓冲区空间耗尽时,将阻止其他发送调用。阻塞时间的阈值由max.block.ms确定,在此阈值之后,它将抛出TimeoutException。 |
注:
1. 如果应用程序启用幂等,建议不设置retries config,因为它将默认为integer.max_value。
b.方法
| 方法名 | 说明 |
|---|---|
| send() | 异步 |
| close() | |
| flush() | |
| partionFor |
2.Consumer
a.参数
| 参数 | 默认值 | 可填值 | 说明 |
|---|---|---|---|
| key.deserializer | key的解析序列化接口实现类(Deserializer) | ||
| value.deserializer | alue的解析序列化接口实现类(Deserializer) | ||
| bootstrap.servers | host/port,用于和kafka集群建立初始化连接。因为这些服务器地址仅用于初始化连接,并通过现有配置的来发现全部的kafka集群成员(集群随时会变化),所以此列表不需要包含完整的集群地址(但尽量多配置几个,以防止配置的服务器宕机)。 | ||
| group.id | 此消费者所属消费者组的唯一标识。如果消费者用于订阅或offset管理策略的组管理功能,则此属性是必须的。 | ||
| enable.auto.commit | true | 如果为true,消费者的offset将在后台周期性的提交 | |
| client.id | 在发出请求时传递给服务器的id字符串。 这样做的目的是通过允许将逻辑应用程序名称包含在服务器端请求日志记录中,来跟踪ip/port的请求源。 | ||
| auto.commit.interval.ms | 5000 | [0,…] | 如果enable.auto.commit设置为true,则消费者偏移量自动提交给Kafka的频率(以毫秒为单位)。 |
| Max.poll.records | |||
| Auto.offset.reset |
b.方法
| 方法名 | 说明 |
|---|---|
| poll() | |
| commitySync() | |
| subscribe() | |
| assign() |
3.Broker
a.参数
| 参数 | 默认值 | 可填值 | 说明 |
|---|---|---|---|
| zookeeper.connect | zookeeper host string | ||
| broker.id | -1 | 服务器的broker id。如果未设置,将生成一个独一无二的broker id。要避免zookeeper生成的broker id和用户配置的broker id冲突,从reserved.broker.max.id + 1开始生成。 | |
| log.dirs | 保存日志数据的目录。如果未设置,则使用log.dir中的值 | ||
| log.dir | /tmp/kafka-logs | 保存日志数据的目录 (补充log.dirs属性) |
注:1. 优先级:per-broker > cluster-wide > server.properties > default
b.方法
4.Topic
5.Streams
6.Connect
7.AdminClient
四.设计
1.动机
2.持久性
以页缓存为中心的设计风格
3.效率
4.生产者
5.消费者
Push
pull
6.消息传递保障
7.副本和leader选举
Node “alive”
落后:replica.lay.max.messages
卡住:replica.lay.time.max.ms

















 4035
4035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









