






API参考
超函数
time_bucket()
把一段时间内的数据按照一个固定时间间隔进行聚合,比如2016-01-01当天的所有出租车行程数据按照每30min进行聚合算总次数。
① 使用例子,两个必需参数bucket_width、ts
按官方文档,两个必需参数, bucket_width 就是间隔时间,下面例子用的 '30 minutes', ts 就是用于分桶的时间戳字段名,这里用的 pickup_datetime
下面是按照每30分钟,基于pickup_datetime字段,对一个范围内的数据进行聚合
select time_bucket('30 minute', pickup_datetime) as thirty_min, count(*)
from rides r
where pickup_datetime > '2016-01-01 09:23'
and pickup_datetime < '2016-01-01 10:25'
group by thirty_min
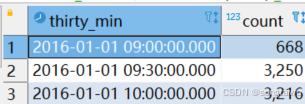
ORDER BY thirty_min按照30min,数据库会按照整数的时间范围进行分隔,从 9:23开始,那么它落到9:00~09:30, 它是第一个区间,然后是9:30~10:00, 最后是10:00~10:30。
每个区间中,对于数据是包含最左的范围,比如9:30~10:00,它包含正好是9:30的数据,不包含正好是10:00的数据。
② 报告存储桶的中间位置,而不是默认的左边缘
设置offset偏移量,并不影响每个存储桶的统计结果,只是把时间显示往前或往后移动了,也就是只是报告的时间变了。
比如我们计算2016年1月1日,从00:00~03:00中每30min的出租车旅程总次数。展示的时间是00:00, 00:30, 01:10....等等。
select time_bucket('30 minute', pickup_datetime) as thirty_min, count(*)
from rides r
where pickup_datetime >= '2016-01-01 00:00'
and pickup_datetime < '2016-01-01 03:00'
group by thirty_min
ORDER BY thirty_min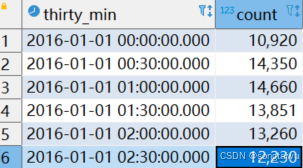
如果报告存储桶的中间位置,而不是左边缘, 如下,加一个 【+ '15 minutes'】,这样能让存储桶的中间位置位于30分钟标记处。
select time_bucket('30 minute', pickup_datetime) + '15 minutes' as thirty_min, count(*)
from rides r
where pickup_datetime >= '2016-01-01 00:00'
and pickup_datetime < '2016-01-01 03:00'
group by thirty_min
ORDER BY thirty_min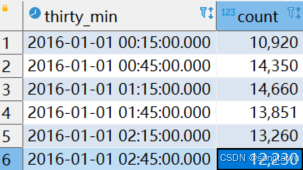
③ 移动对齐位置
如果希望存储桶的对齐位置(我理解就是实际存储桶统计的范围),这里用到的就是origin参数。
比如我们统计的数据虽然桶的大小是30min的,但是不希望是从 01:00 ~ 01:30, 而是往前移动15min,变为 00:45~01:15, 就需要通过设置origin来实现。
select time_bucket('30 minute', pickup_datetime, '-15 minutes'::INTERVAL) as thirty_min, count(*)
from rides r
where pickup_datetime >= '2016-01-01 00:00'
and pickup_datetime < '2016-01-01 03:00'
group by thirty_min
ORDER BY thirty_min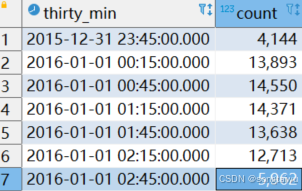
如上,第一个桶里面实际就统计的 23:45 ~ 00:15的数据。
可以使用时间戳、timestampz 或 日期类型传递的origin参数。这样可以让存储桶相对于此时间戳对齐。如果我们不使用这个origin参数,那么对于不包括月份或年份间隔的存储桶,默认值为 2000 年 1 月 3 日的午夜,对于月份、年份和世纪存储桶,默认值为 2000 年 1 月 1 日的午夜。
提供给函数的 origin 可以早于、期间或晚于所分析的数据。所有存储桶都是相对于此 origin 计算的。
举个例子,我们查询1月份的数据,按照“周”来聚合,它默认从2000年1月3日开始对齐,这一天是周一,也就是说,按周聚合,实际就是从周一到周日。
select time_bucket('1 week', pickup_datetime) as one_week, count(*)
from rides r
where pickup_datetime >= '2016-01-01 00:00'
and pickup_datetime < '2016-02-01 00:00'
group by one_week
order by one_week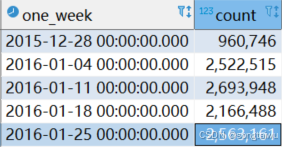
如上,2015-12-28是周一。
如果我们想改变到从2016年1月1日周五作为对齐,可以这么写
select time_bucket('1 week', pickup_datetime, TIMESTAMPTZ '2016-01-01') as one_week, count(*)
from rides r
where pickup_datetime >= '2016-01-01 00:00'
and pickup_datetime < '2016-02-01 00:00'
group by one_week
order by one_week
实例--纽约出租车
一、资料使用
在timescale的官方网站的“教程”菜单中,有几个不同业务场景的例子,其中就有运输行业的例子。我访问中文站点的时候,关于教程的几个步骤内容刷不出来,所以还是建议访问英文站点。
https://docs.timescale.com/tutorials/latest/nyc-taxi-cab/
对于出租车的数据,不用去 NYC TLC官网去下载,他们现在都是parquet格式数据,还得了解怎么去用,没必要。如果想了解关于这些数据的背景信息,可以看看他们官方站点https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
二、准备工作步骤
2.1 安装 TimescaleDB
本机安装就用docker方式,参考
https://docs.timescaledb.cn/self-hosted/latest/install/installation-docker/
拿到镜像
docker pull timescale/timescaledb-ha:pg16
目前无法通过docker pull直接下载,需要有代理的地方提前准备好镜像
运行容器
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=password timescale/timescaledb-ha:pg16
我本机已经有一个pg库用了5432:5432,这里可以改为端口 -p 54329:5432
在 timescaledb-ha:pg16 镜像中,默认用户和数据库都是 postgres。在运行镜像时,您在 POSTGRES_PASSWORD 中设置密码,这里就是password。
连接
通过工具 DBeaver可以方便的连接数据库。

也可以通过psql命令行工具连接,如下图,直接进入运行timescaledb的容器,然后通过psql连接,通过\dx 检查是否安装了TimescaleDB。

2.2 准备基础表
所有内容都在官方文档中,照着操作就好,就是创建表, 我们把这些SQL都直接粘贴到 DBeaver工具直接运行就行。
https://docs.timescale.com/tutorials/latest/nyc-taxi-cab/dataset-nyc/#set-up-the-database
创建超表之前,先是创建一个PostgreSQL表,用于存储出租车的行程信息
CREATE TABLE "rides"(
vendor_id TEXT,
pickup_datetime TIMESTAMP WITHOUT TIME ZONE NOT NULL,
dropoff_datetime TIMESTAMP WITHOUT TIME ZONE NOT NULL,
passenger_count NUMERIC,
trip_distance NUMERIC,
pickup_longitude NUMERIC,
pickup_latitude NUMERIC,
rate_code INTEGER,
dropoff_longitude NUMERIC,
dropoff_latitude NUMERIC,
payment_type INTEGER,
fare_amount NUMERIC,
extra NUMERIC,
mta_tax NUMERIC,
tip_amount NUMERIC,
tolls_amount NUMERIC,
improvement_surcharge NUMERIC,
total_amount NUMERIC
);然后把标准版转换为超表,
SELECT create_hypertable('rides', by_range('pickup_datetime'), create_default_indexes=>FALSE);
SELECT add_dimension('rides', by_hash('payment_type', 2));为了高效查询,创建索引
CREATE INDEX ON rides (vendor_id, pickup_datetime DESC);
CREATE INDEX ON rides (rate_code, pickup_datetime DESC);
CREATE INDEX ON rides (passenger_count, pickup_datetime DESC);创建两个普通表,用于做关联数据
① 存储支付类型
CREATE TABLE IF NOT EXISTS "payment_types"(
payment_type INTEGER,
description TEXT
);
INSERT INTO payment_types(payment_type, description) VALUES
(1, 'credit card'),
(2, 'cash'),
(3, 'no charge'),
(4, 'dispute'),
(5, 'unknown'),
(6, 'voided trip');② 存储费率数据
CREATE TABLE IF NOT EXISTS "rates"(
rate_code INTEGER,
description TEXT
);
INSERT INTO rates(rate_code, description) VALUES
(1, 'standard rate'),
(2, 'JFK'),
(3, 'Newark'),
(4, 'Nassau or Westchester'),
(5, 'negotiated fare'),
(6, 'group ride');2.3 导入行程数据
从上一步就给的官方连接中,页面里面有数据下载地址,下载 nyc_data.tar.gz, 解压后,会有sql文件,我们在站点上面给的零散sql都是一模一样的,它就是集合了所有建表语句。然后就是数据文件nyc_data_rides.csv, 这个文件 1.6G 很大。
我们通过psql命令行方式导入csv数据。
我用容器运行的TimescaleDB, 先通过docker inspect 确认容器和本地目录的映射关系,把nyc_data_rides.csv传到容器中。

用psql连上数据库,切到我创建的mytest库,导入csv数据

三、查询
参考官方文档,按步骤练习写sql查询,https://docs.timescaledb.cn/tutorials/latest/nyc-taxi-cab/query-nyc/
3.1 平均车费是多少?
查询2016年1月第一周所有行程的平均车费
select date_trunc('day', pickup_datetime) as day, avg(fare_amount)
from rides r
where pickup_datetime < '2016-01-08 00:00'
group by day
order by dayselect time_bucket('1 day', pickup_datetime) as day, avg(fare_amount)
from rides r
where pickup_datetime < '2016-01-08 00:00'
group by day
order by day3.2 每种费率类型的乘坐次数是多少?
SELECT rate_code, COUNT(vendor_id) AS num_trips
FROM rides
WHERE pickup_datetime < '2016-01-08'
GROUP BY rate_code
ORDER BY rate_code;3.3 往返机场的行程类型是什么?
rides表中的ride_code记录了行程的类型,当是2,3时代表是两个机场有关的订单。为了能拿到ride_code对应的ride_description值,还得与rates表连表查询。
我们查询2016年1月第一周与两个机场相关的行程,并返回行程次数、平均行程时长、平均行程成本以及平均乘客数。
SELECT rates.description,
COUNT(vendor_id) AS num_trips,
AVG(dropoff_datetime - pickup_datetime) AS avg_trip_duration,
AVG(total_amount) AS avg_total,
AVG(passenger_count) AS avg_passengers
FROM rides
JOIN rates ON rides.rate_code = rates.rate_code
WHERE rides.rate_code IN (2,3) AND pickup_datetime < '2016-01-08'
GROUP BY rates.description
ORDER BY rates.description;3.4 2016年新年当天有多少乘坐?
我们导入到表rides的数据是从2016-01-01开始的,下面sql,就相当于限制了1号当天,通过time_bucket()超函数,按照每30分钟聚合数据得到数据桶。
SELECT time_bucket('30 minute', pickup_datetime) AS thirty_min, count(*)
FROM rides
WHERE pickup_datetime < '2016-01-02 00:00'
GROUP BY thirty_min
ORDER BY thirty_min;
















 6224
6224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









