










 本文深入解析Dubbo框架的实现原理,包括RPC与SOA的概念、Dubbo的底层机制、多种通信协议的优缺点,以及服务暴露和消费的详细过程。同时,文章探讨了Dubbo与SpringCloud的区别,ZooKeeper的作用,和Java并发、锁机制等内容。
本文深入解析Dubbo框架的实现原理,包括RPC与SOA的概念、Dubbo的底层机制、多种通信协议的优缺点,以及服务暴露和消费的详细过程。同时,文章探讨了Dubbo与SpringCloud的区别,ZooKeeper的作用,和Java并发、锁机制等内容。
1.Dubbo底层实现原理和机制
Dubbo :是一个rpc框架,soa框架
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来。 接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。 这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
实际上SOA只是一种架构设计模式,而SOAP、REST、RPC就是根据这种设计模式构建出来的规范,其中SOAP通俗理解就是http+xml的形式,REST就是http+json的形式,RPC是基于socket的形式。上文提到的CXF就是典型的SOAP/REST框架,dubbo就是典型的RPC框架,而SpringCloud就是遵守REST规范的生态系统。
作为RPC:支持各种传输协议,如dubbo,hession,json,fastjson,底层采用mina,netty长连接进行传输!典型的provider和cusomer模式!
作为SOA:具有服务治理功能,提供服务的注册和发现!用zookeeper实现注册中心!启动时候服务端会把所有接口注册到注册中心,并且订阅configurators,服务消费端订阅provide,configurators,routers,订阅变更时,zk会推送providers,configuators,routers,启动时注册长连接,进行通讯!proveider和provider启动后,后台启动定时器,发送统计数据到monitor!提供各种容错机制和负载均衡策略!!

Dubbo支持的协议
在通信过程中,不同的服务等级一般对应着不同的服务质量,那么选择合适的协议便是一件非常重要的事情。你可以根据你应用的创建来选择。例如,使用RMI协议,一般会受到防火墙的限制,所以对于外部与内部进行通信的场景,就不要使用RMI协议,而是基于HTTP协议或者Hessian协议。Dubbo支持8种左右的协议,如下所示:
- (1) dubbo:// Dubbo协议
- (2) rmi:// RMI协议
- (3) hessian:// Hessian协议
- (4) http:// HTTP协议
- (5) webservice:// WebService协议
- (6) thrift:// Thrift协议
- (7) memcached:// Memcached协议
- (8)redis:// Redis协议
| 名称 | 实现描述 | 连接描述 | 适用场景 |
|---|---|---|---|
| dubbo | 传输服务: mina, netty(默认), grizzy 序列化: dubbo, hessian2(默认), java, fastjson 自定义报文 | 单个长连接 NIO异步传输 | 1.常规RPC调用 2.传输数据量小 3.提供者少于消费者 |
| rmi | 传输:java rmi 服务序列化:java原生二进制序列化 | 多个短连接 BIO同步传输 | 1.常规RPC调用 2.与原RMI客户端集成 3.可传少量文件 4.不支持防火墙穿透 |
| hessian | 传输服务:servlet容器 序列化:hessian二进制序列化 | 基于Http 协议传输,依懒servlet容器配置 | 1.提供者多于消费者2.可传大字段和文件 3.跨语言调用 |
| http | 传输服务:servlet容器 序列化:http表单 | 依懒servlet容器配置 | 数据包大小混合 |
| thrift | 与thrift RPC 实现集成,并在其基础上修改了报文头 | 长连接、NIO异步传输 |
在通信过程中,不同的服务等级一般对应着不同的服务质量,那么选择合适的协议便是一件非常重要的事情。你可以根据你应用的创建来选择。例如,使用RMI协议,一般会受到防火墙的限制,所以对于外部与内部进行通信的场景,就不要使用RMI协议,而是基于HTTP协议或者Hessian协议。
部分协议的特点和使用场景如下:
1、dubbo协议
Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
缺省协议,使用基于mina1.1.7+hessian3.2.1的tbremoting交互。
连接个数:单连接
连接方式:长连接
传输协议:TCP
传输方式:NIO异步传输
序列化:Hessian二进制序列化
适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用dubbo协议传输大文件或超大字符串。
适用场景:常规远程服务方法调用为什么要消费者比提供者个数多:
因dubbo协议采用单一长连接,
假设网络为千兆网卡(1024Mbit=128MByte),
根据测试经验数据每条连接最多只能压满7MByte(不同的环境可能不一样,供参考),
理论上1个服务提供者需要20个服务消费者才能压满网卡。
为什么不能传大包:
因dubbo协议采用单一长连接,
如果每次请求的数据包大小为500KByte,假设网络为千兆网卡(1024Mbit=128MByte),每条连接最大7MByte(不同的环境可能不一样,供参考),
单个服务提供者的TPS(每秒处理事务数)最大为:128MByte / 500KByte = 262。
单个消费者调用单个服务提供者的TPS(每秒处理事务数)最大为:7MByte / 500KByte = 14。
如果能接受,可以考虑使用,否则网络将成为瓶颈。
为什么采用异步单一长连接:
因为服务的现状大都是服务提供者少,通常只有几台机器,
而服务的消费者多,可能整个网站都在访问该服务,
比如Morgan的提供者只有6台提供者,却有上百台消费者,每天有1.5亿次调用,
如果采用常规的hessian服务,服务提供者很容易就被压跨,
通过单一连接,保证单一消费者不会压死提供者,
长连接,减少连接握手验证等,
并使用异步IO,复用线程池,防止C10K问题。2、RMI
RMI协议采用JDK标准的java.rmi.*实现,采用阻塞式短连接和JDK标准序列化方式
Java标准的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:TCP
传输方式:同步传输
序列化:Java标准二进制序列化
适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。
适用场景:常规远程服务方法调用,与原生RMI服务互操作3、hessian
Hessian协议用于集成Hessian的服务,Hessian底层采用Http通讯,采用Servlet暴露服务,Dubbo缺省内嵌Jetty作为服务器实现
基于Hessian的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:Hessian二进制序列化
适用范围:传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。
适用场景:页面传输,文件传输,或与原生hessian服务互操作4、http
采用Spring的HttpInvoker实现
基于http表单的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:表单序列化(JSON)
适用范围:传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看,可用表单或URL传入参数,暂不支持传文件。
适用场景:需同时给应用程序和浏览器JS使用的服务。5、webservice
基于CXF的frontend-simple和transports-http实现
基于WebService的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:SOAP文本序列化
适用场景:系统集成,跨语言调用。6、thrif
Thrift是Facebook捐给Apache的一个RPC框架,当前 dubbo 支持的 thrift 协议是对 thrift 原生协议的扩展,在原生协议的基础上添加了一些额外的头信息,比如service name,magic number等。
rpc通信协议http和thrift之间的区别
使用thrift等工具可以实现二进制传输,相比http的文传输无疑大大提高了传输效率;http通常使用的json,需要用户序列化/反序列化,性能和复杂度高。相比之下,Thrift等工具,使用了成熟的代码生成技术,将通信接口的IDL文件(IDL(Interface Definition Language)即接口定义语言)生成了对应语言的代码接口,实现了远程调用接近于本地方法的调用。另外无论是网络传输编码、解码,还是传输内容大小还是网络开销都相比http有较大的优势,另外一个企业内部的开发语言、框架不会有太大的异构性,http并无优势。
服务暴露和消费的详细过程
(1)服务提供者暴露一个服务的详细过程
(1)暴露本地服务
- 其实第一步就是根据我们在XMl中配置的文件,对<dubbo: >标签的bean进行解析,然后注册的Spring容器中,供后面使用
- 然后当Spring 容器发布刷新事件的时候,会触发 ServiceBean 的 onApplicationEvent()方法,然后执行方法中的export()方法,这个方法是真正dubbo开始暴露本地方法的开始
- 然后进入export()之后是检查,没有的问题的话,就执行doExport()方法,然后又是一顿检查,检查提供者是不是为空、有没有初始化、接口名称是不是合法,然后没问题的话,再去执行 doExportUrls()方法,暴露服务。
- 进入 doExportUrls()方法之后,然后是加载注册中心的链接,遍历是那种调用方式(比如dubbo协议、dubbo直连),然后下一步是调用这个方法doExportUrlsFor1Protocol()组装URL。
- doExportUrlsFor1Protocol()方法中的这个过程的核心就是为了让从本地过来的一些核心参数转换为URL,这样更方便在网络中进行传输,比如把版本、时间戳、方法名以及各种配置对象的字段信息、上下文路径、主机名以及端口号等信息都放到URL中
- 然后是继续执行这个方法doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List registryURLs)的第二个重要的部分,把服务导出到本地JVM还是远程,会根据URL中scope参数决定导出服务的方式scope = none,不导出服务scope != remote,导出到本地scope != local,导出到远程。
- 然后是由ProxyFactory的一个代理工厂调用getInvoker(T proxy, Class type, URL url)方法来创建一个Invoker。其实这个Invoker就是一个包含了本地要暴露的代理对象(比如代理对象生成的代理类UserServiceImpl)、类型信息和上一步包装好的URL信息,就是一个执行者的完整信息对象,然后在进行包装成wrapperInvoker对象进行暴露出去,下一步调用export()方法
- 然后是通过Protocol.export(wrapperInvoker)把这个完成的Invoker对象暴露出去,这里使用了Java的SPI机制进行获取到的Protocol对像。只要一调用exporter就会生成一个Exporter对象,然后会使用下面的DubboProtocol对象进行暴露(先拿到注册中心的URL地址),其实也就是在进行一次Export()调用,然后会得到一个DubboExporter对象,使用是dubbo协议

- 然后通过DubboExporter去进行调用openServer()方法去开启服务器,因为刚开始没有服务器,所以需要创建一个ExchangeServer对象,然后继续进行通过bind()方法进行绑定对应的url。(然后一直进去发现其实调用的还是Netty的底层实现),然后启动服务器,监听端口
- 然后是把提供者的注册信息注册到ProviderConsumerRegTable对象中进行维护。

服务提供者暴露服务的主过程:

首先ServiceConfig类拿到对外提供服务的实际类ref(如:HelloWorldImpl),然后通过ProxyFactory类的getInvoker方法使用ref生成一个AbstractProxyInvoker实例,
到这一步就完成具体服务到Invoker的转化。接下来就是Invoker转换到Exporter的过程。
Dubbo处理服务暴露的关键就在Invoker转换到Exporter的过程(如上图中的红色部分),下面我们以Dubbo和RMI这两种典型协议的实现来进行说明:
Dubbo的实现:
Dubbo协议的Invoker转为Exporter发生在DubboProtocol类的export方法,它主要是打开socket侦听服务,并接收客户端发来的各种请求,通讯细节由Dubbo自己实现。
RMI的实现:
RMI协议的Invoker转为Exporter发生在RmiProtocol类的export方法,
它通过Spring或Dubbo或JDK来实现RMI服务,通讯细节这一块由JDK底层来实现,这就省了不少工作量。
2)服务消费者消费一个服务的详细过程
服务消费的主过程:

(一)大概描述一下整个服务调用的过程的准备工作和总体流程,后面一步一步分析
先说一下dubbo调用服务的原理需要的前置步骤,相当于准备工作:
- dubbo在引用服务的时候是分两种方式的,第一种是我们正常使用的懒汉式的加载方式的,其实就是我们用@Reference注解的时候使用的就是懒汉式的加载方式
- 第二种是当我们在 Spring 容器调用 ReferenceBean 的 afterPropertiesSet 方法时引用服务,这种调用方式其实是一种饿汉式的加载方式,然后两者调用的开始其实就是从ReferenceBean 的 getObject 方法开始
现在调用完事之后,下一步就是决定引用那种服务,有三种可供选择的嗲用服务的方式:
- 第一种是引用本地 (JVM) 服务
- 第二是通过直连方式引用远程服务
- 第三是通过注册中心引用远程服务
- 然后最终都会生成一个Invoker对象,此时的Invoker对象已经具备调用本地或远程服务的能力了,但是不能直接暴露给用户,会对一下业务造成侵入,然后需要使用代理工厂类代理对象去调用Invoker的逻辑。
总的概括一下总的调用流程:
首先是ReferenceConfig类先去调用init()方法,然后会在init方法中调用Protocol的refer()方法生成一个Invoker对象实例,这里是消费服务的关键,然后会在init方法中通过createProxy(map)方法生成一个代理对象,然后在CreateProxy方法中进行判断是采用哪种调用方式(就是上面三种方式之一),并去调用refer()方法生成一个Invoker对象,接下来会把Invoker对象转换为客服端需要的对象(UserService),
首先ReferenceConfig类的init方法调用Protocol的refer方法生成Invoker实例(如上图中的红色部分),这是服务消费的关键。
接下来把Invoker转换为客户端需要的接口(如:HelloWorld)。
Dubbo的远程服务调用
(1)首选Dubbo是通过Poxy对象来生成一个代理对象的
- 具体实现是在ReferenceConfig对象中调用的private T createProxy(Map<String, String> map)方法的,这个方法中有三种生成Invoker对象的方式,第一种是通过本地JVM,第二种是通过URL对象是不是为空判断进行判断,然后如果为空就从注册中心获取这个Invoker对象,否则就是从ReferenceConfig中的URL中拿到
- 上面那个方法中还会通过获取到的Invoker这里的【生成Invoker的过程后面补充】的对象去通过ProxyFactory生成Poxy对象,代码为:
return proxyFactory.getProxy(this.invoker);,这里proxyFactory其实就是
//ProxyFactory接口的javassist扩展类JavassistProxyFactory的getProxy方法实现
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {
return Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));
}
- 然后通过第2步的getPoxy()方法去动态代理生成代理Poxy对象
public static Proxy getProxy(Class<?>... ics) {
return getProxy(ClassHelper.getClassLoader(Proxy.class), ics);
}
/**
* Get proxy.
*
* @param cl class loader.
* @param ics interface class array. 可以实现多个接口
* @return Proxy instance.
*/
public static Proxy getProxy(ClassLoader cl, Class<?>... ics) {
if (ics.length > 65535)
throw new IllegalArgumentException("interface limit exceeded");
StringBuilder sb = new StringBuilder();
for (int i = 0; i < ics.length; i++) {
String itf = ics[i].getName();
if (!ics[i].isInterface())
throw new RuntimeException(itf + " is not a interface.");
Class<?> tmp = null;
try {
tmp = Class.forName(itf, false, cl);
} catch (ClassNotFoundException e) {
}
if (tmp != ics[i])
throw new IllegalArgumentException(ics[i] + " is not visible from class loader");
sb.append(itf).append(';');
}
// use interface class name list as key.
// 用接口类名做key,多个接口以分号分开。
String key = sb.toString();
// get cache by class loader.
// 缓存
Map<String, Object> cache;
synchronized (ProxyCacheMap) {
cache = ProxyCacheMap.get(cl);
if (cache == null) {
cache = new HashMap<String, Object>();
ProxyCacheMap.put(cl, cache);
}
}
Proxy proxy = null;
synchronized (cache) {
do {
Object value = cache.get(key);
if (value instanceof Reference<?>) {
//如果有存在引用对象,返回缓存对象。
proxy = (Proxy) ((Reference<?>) value).get();
if (proxy != null)
return proxy;
}
//对象正在生成,线程挂起,等待
if (value == PendingGenerationMarker) {
try {
cache.wait();
} catch (InterruptedException e) {
}
} else {//放入正在生成标识
cache.put(key, PendingGenerationMarker);
break;
}
}
while (true);
}
//类名称后自动加序列号 0,1,2,3...
long id = PROXY_CLASS_COUNTER.getAndIncrement();
String pkg = null;
//ClassGenerator dubbo用javassist实现的工具类
ClassGenerator ccp = null, ccm = null;
try {
ccp = ClassGenerator.newInstance(cl);
Set<String> worked = new HashSet<String>();
List<Method> methods = new ArrayList<Method>();
for (int i = 0; i < ics.length; i++) {
//检查包名称及不同包的修饰符
if (!Modifier.isPublic(ics[i].getModifiers())) {
String npkg = ics[i].getPackage().getName();
if (pkg == null) {
pkg = npkg;
} else {
if (!pkg.equals(npkg))
throw new IllegalArgumentException("non-public interfaces from different packages");
}
}
//代理类添加要实现的接口Class对象
ccp.addInterface(ics[i]);
for (Method method : ics[i].getMethods()) {
//获取方法描述符,不同接口,同样的方法,只能被实现一次。
String desc = ReflectUtils.getDesc(method);
if (worked.contains(desc))
continue;
worked.add(desc);
int ix = methods.size();
//方法返回类型
Class<?> rt = method.getReturnType();
//方法参数类型列表
Class<?>[] pts = method.getParameterTypes();
//生成接口的实现代码,每个方法都一样
StringBuilder code = new StringBuilder("Object[] args = new Object[").append(pts.length).append("];");
for (int j = 0; j < pts.length; j++)
code.append(" args[").append(j).append("] = ($w)$").append(j + 1).append(";");
code.append(" Object ret = handler.invoke(this, methods[" + ix + "], args);");
if (!Void.TYPE.equals(rt))
code.append(" return ").append(asArgument(rt, "ret")).append(";");
methods.add(method);
ccp.addMethod(method.getName(), method.getModifiers(), rt, pts, method.getExceptionTypes(), code.toString());
}
}
if (pkg == null)
pkg = PACKAGE_NAME;
// create ProxyInstance class.
// 具体代理类名称,这里是类全名
String pcn = pkg + ".proxy" + id;
ccp.setClassName(pcn);
ccp.addField("public static java.lang.reflect.Method[] methods;");
ccp.addField("private " + InvocationHandler.class.getName() + " handler;");
//创建构造函数
ccp.addConstructor(Modifier.PUBLIC, new Class<?>[]{InvocationHandler.class}, new Class<?>[0], "handler=$1;");
ccp.addDefaultConstructor();
Class<?> clazz = ccp.toClass();
//通过反射,把method数组放入,静态变量methods中,
clazz.getField("methods").set(null, methods.toArray(new Method[0]));
// create Proxy class.
String fcn = Proxy.class.getName() + id;
ccm = ClassGenerator.newInstance(cl);
ccm.setClassName(fcn);
ccm.addDefaultConstructor();
//设置父类为抽象类,Proxy类子类,
ccm.setSuperClass(Proxy.class);
//生成实现它的抽象方法newInstance代码
//new 的实例对象,是上面生成的代理类 pcn
ccm.addMethod("public Object newInstance(" + InvocationHandler.class.getName() + " h){ return new " + pcn + "($1); }");
Class<?> pc = ccm.toClass();
proxy = (Proxy) pc.newInstance();
} catch (RuntimeException e) {
throw e;
} catch (Exception e) {
throw new RuntimeException(e.getMessage(), e);
} finally {
// release ClassGenerator
if (ccp != null)
ccp.release();
if (ccm != null)
ccm.release();
synchronized (cache) {
if (proxy == null)
cache.remove(key);
else
//放入缓存,key:实现的接口名,value 代理对象,这个用弱引用,
//当jvm gc时,会打断对实例对象的引用,对象接下来就等待被回收。
cache.put(key, new WeakReference<Proxy>(proxy));
cache.notifyAll();
}
}
return proxy;
}
(2)这里是进行补充上面的那个【Invoker的怎么生成的步骤】,看一下Invoker中都包含了什么信息这么重要,这里需要强调一下这个Invoker生成的过程和Dubbo服务的暴露和导出生成的Invoker不太一样
- invoker对象是通过 InvokerInvocationHandler构造方法传入,而InvokerInvocationHandler对象是由JavassistProxyFactory类getProxy(Invoker invoker, Class<?>[] interfaces)方法创建。
这还要回到调用proxyFactory.getProxy(invoker);方法的地方,即ReferenceConfig类的createProxy(Map<String, String> map)方法中 - 所以这个Invoker其实是通过ReferenceConfig 中的createProxy(Map<String, String> map)方法来生成的Invoker对象,这个就是下面中使用到的对象refprotocol ,
private static final Protocol refprotocol = (Protocol)ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
if (urls.size() == 1) {//只有一个直连地址或一个注册中心配置地址
//这里的urls.get(0)协议,可能是直连地址(默认dubbo协议),也可能是regiter注册地址(zookeeper协议)
//我们这里走的是注册中心,所以
invoker = refprotocol.refer(interfaceClass, urls.get(0));//本例通过配置一个注册中心的形式(***看这里***)
} else {//多个直连地址或者多个注册中心地址,甚至是两者的组合。
List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();
URL registryURL = null;
for (URL url : urls) {
//创建invoker放入invokers
invokers.add(refprotocol.refer(interfaceClass, url));
if (Constants.REGISTRY_PROTOCOL.equals(url.getProtocol())) {
registryURL = url; // 多个注册中心,用最后一个registry url
}
}
if (registryURL != null) { //有注册中心协议的URL,
//对多个url,其中存在有注册中心的,写死用AvailableCluster集群策略
//这其中包括直连和注册中心混合或者都是注册中心两种情况
URL u = registryURL.addParameter(Constants.CLUSTER_KEY, AvailableCluster.NAME);
invoker = cluster.join(new StaticDirectory(u, invokers));
} else { // 多个直连的url
invoker = cluster.join(new StaticDirectory(invokers));
}
}
上面的代码可以看出生成Invoker的有三种方式,
- 第一种是refprotocol.refer(this.interfaceClass, (URL),这里的接口用的是SPI机制的dubbo对应下面的那个@SPI注解=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol这一句,所以这一种主要是使用的是Dubbo直连的协议都会走这一层
- 第二种是 cluster.join(new StaticDirectory(u, invokers));,这个是加了路由的负载均衡相关的,这一部分主要都是路由层的东西
- 第三种是 this.invoker = cluster.join(new StaticDirectory(invokers));也是路由层的东西, 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> var1) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> var1, URL var2) throws RpcException;
void destroy();
}
因为Dubbo中在实现远程调用的时候其实是通过Poxy对象生成的Invoker对象,那么就先看一下Invoker的怎么生成的,里面都包含了什么信息?
- 这里的invoker对象,通过InvokerInvocationHandler构造方法传入,而InvokerInvocationHandler对象是由JavassistProxyFactory类
getProxy(Invoker invoker, Class<?>[] interfaces)方法创建
Dubbo的SPI机制的底层是如何实现的?
(一)什么是SPI机制?Java中的SPI机制是如何实现的?
(1)首先先说一下JavaSPI机制(Service Provider Interface)其实说白了就是定义一个接口,但是可以有多个实现该接口的实现类,其实也是一种服务发现机制。
- 其实SPI机制的本质就是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类
(2)那么Dubbo中的SPI机制和Java中的SPi机制又有什么区别呢?
-
首先Java中的SPI机制是基于接口的编程+策略模式+配置文件的组合方式实现的动态加载机制
-
其实具体的JavaSPI的实现就是:
- 1.你先定义一个A接口,比如是com.wangwei.A这个接口
- 2.然后你需要在src/main/resources/ 下建立 /META-INF/services 目录下定义和A接口相同的文件com.wangwei.A名字,然后需要在这个com.wangwei.A文件中 定义一些你需要实现这个接口的实现类这里有多个实现类的
- 3.然后你在使用的时候需要去遍历这个接口的所有实现类,然后拿到你想要拿到的实现类,然后使用,是这样的一个流程。
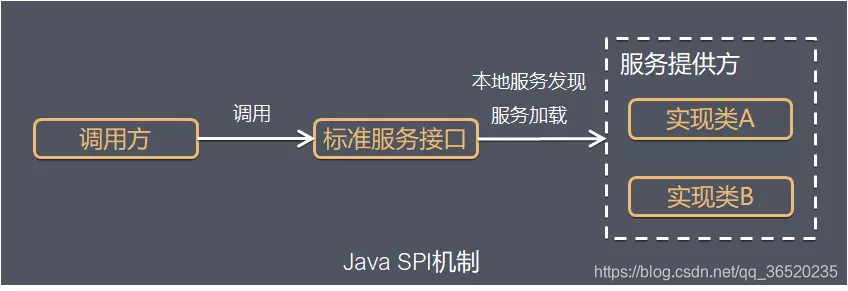
(二)dubbo的SPI机制底层是如何实现的?
(1)dubbo中的SPI机制
- 其实为什么在dubbo中又重新定义了一套dubbo的SPI机制,就是因为java中的SPI机制的一些缺点,不能满足dubbo的使用场景或者说效率没有那么高效
- 所以dubbo自己封装了一套更强大的SPI机制,直接封装到了ExtensionLoader 类中,通过 ExtensionLoader,我们可以加载指定的实现类。Dubbo SPI 所需的配置文件需放置在 META-INF/dubbo 路径,并且可以直接给实现类进行一个命名,然后在使用的时候,直接通过@SPI(“名字”)去找到具体的实现类,比如:random(名字)=com.alibaba.dubbo.rpc.cluster.loadbalance.RandomLoadBalance(实现类)
(2)dubbo中SPI机制的使用流程:
- 首先如果你想给一个接口需要用dubbo的SPI机制实现,那么首先你需要给这个接口上加上@SPI(“使用默认的实现类的名字”)这个注解
- 然后需要在你接口中的方法上加上一个@Adaptive注解,这个注解的核心功能就是:会为该方法生成对应的代码。方法内部会根据方法的参数,来决定使用哪个扩展,@Adaptive注解用在类上代表实现一个装饰类,类似于设计模式中的装饰模式
- 然后通过你在配置文件中配置好并实现你需要的实现类,然后供其进行调用完成,类似下面
random=com.alibaba.dubbo.rpc.cluster.loadbalance.RandomLoadBalance
roundrobin=com.alibaba.dubbo.rpc.cluster.loadbalance.RoundRobinLoadBalance
leastactive=com.alibaba.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance
consistenthash=com.alibaba.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance
dubbo框架zookeeper注册中心挂了,调用服务会报错吗?
使用过dubbo框架的同学都知道,dubbo框架的服务调用是通过zookeeper注册中心找到服务地址后,进行调用。
如果中途zookeeper注册中心挂了,服务调用会报错吗?
可以的,启动dubbo时,消费者会从zk拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用
注册中心对等集群,任意一台宕掉后,会自动切换到另一台
注册中心全部宕掉,服务提供者和消费者仍可以通过本地缓存通讯
服务提供者无状态,任一台 宕机后,不影响使用
服务提供者全部宕机,服务消费者会无法使用,并无限次重连等待服务者恢复
开发、测试环境可通过指定Url方式绕过注册中心直连指定的服务地址,避免注册中心中服务过多,启动建立连接时间过长,如
<dubbo:reference id="providerService" interface="org.jstudioframework.dubbo.demo.service.ProviderService" url="dubbo://127.0.0.1:29014"/>
Dubbo 和 Spring Cloud 的关系?
Dubbo 是 SOA 时代的产物,它的关注点主要在于服务的调用,流
量分发、流量监控和熔断。而 Spring Cloud 诞生于微服务架构时
代,考虑的是微服务治理的方方面面,另外由于依托了 Spirng、
Spirng Boot 的优势之上,两个框架在开始目标就不一致,Dubbo
定位服务治理、Spirng Cloud 是一个生态。
最大的区别:Dubbo 底层是使用 Netty 这样的 NIO 框架,是基于
TCP 协议传输的,配合以 Hession 序列化完成 RPC 通信。
而 SpringCloud 是基于 Http 协议+Rest 接口调用远程过程的通信,
相对来说,Http 请求会有更大的报文,占的带宽也会更多。但是
REST 相比 RPC 更为灵活,服务提供方和调用方的依赖只依靠一纸契
约,不存在代码级别的强依赖。ZooKeeper提供了什么(本质)?
1、 文件系统 2、 通知机制Zookeeper文件系统
Zookeeper提供一个多层级的节点命名空间(节点称为znode)。与文件系统不同的是,这些节点 都可以设置 关联的数据 ,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper为了保证高吞吐和低延 迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper 不能用于存放大量的数据 ,每个节点的存 放数据上限为 1M 。2.volatile关键词的作用
被volatile修饰的变量,可以保证不同的线程都能取得最新状态值;volatile保证了可见性,避免线程在缓存中取旧值;
1. volatile 保证可见性
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
2. volatile 不能确保原子性
下面看一个例子:
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
3.Redis淘汰机制(Eviction policies)
首先,需要设置最大内存限制
maxmemory 100mb选择策略
maxmemory-policy noeviction 解释:
noeviction:默认策略,不淘汰,如果内存已满,添加数据是报错。
allkeys-lru:在所有键中,选取最近最少使用的数据抛弃。
volatile-lru:在设置了过期时间的所有键中,选取最近最少使用的数据抛弃。
allkeys-random: 在所有键中,随机抛弃。
volatile-random: 在设置了过期时间的所有键,随机抛弃。
volatile-ttl:在设置了过期时间的所有键,抛弃存活时间最短的数据。
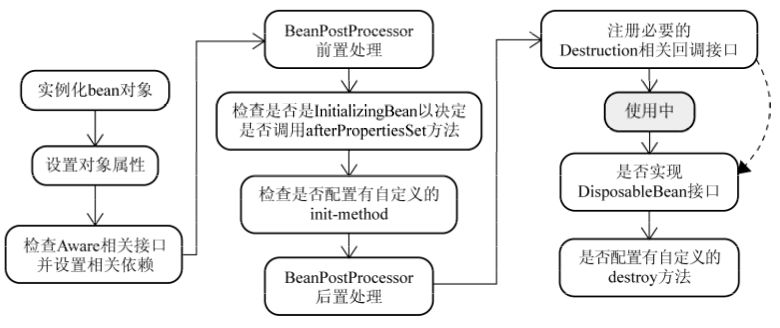
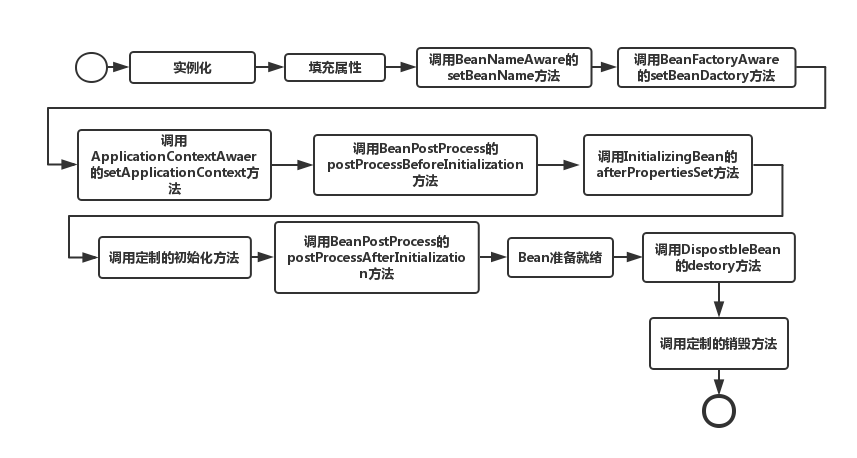
4.Spring中Bean的生命周期是怎样的?
Spring Bean 生命周期 | crossoverJie's Blog
5.Java中Synchronized的用法
synchronized修饰符的使用场景整理总结、分类
| 修饰对象 | 作用范围 | 作用对象 |
|---|---|---|
| 代码块(称为同步代码块) | 大括号{}括起来的代码 | 调用这个代码块的对象 |
| 一般方法(被称为同步方法) | 整个方法 | 调用这个方法的对象 |
| 静态的方法 | 整个静态方法 | 此类的所有对象 |
| 类 | synchronized后面括号括起来的部分 | 此类的所有对象 |
一、修饰一个代码块
修饰的结果:
- 一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程将被阻塞;
- 多个线程访问各子的对象即使有synchronized修饰了同步代码块,但是互不阻塞,但是并不能保证静态变量的线程安全性。
- 当一个线程访问对象的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该对象中的非synchronized(this)同步代码块。
1.synchronized修饰的方法使用:
/**
* 同步线程
*/
class SyncThread implements Runnable {
private static int count;
public SyncThread() {
count = 0;
}
public void run() {
synchronized(this) {
for (int i = 0; i < 5; i++) {
try {
System.out.println(Thread.currentThread().getName() + ":" + (count++));
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public int getCount() {
return count;
}
}2.验证调用代码(创建俩线程,调用一个对象)
public class codeBlock {
public static void main(String[] args) {
SyncThread syncThread = new SyncThread();
Thread thread1 = new Thread(syncThread, "SyncThread1");
Thread thread2 = new Thread(syncThread, "SyncThread2");
thread1.start();
thread2.start();
}
}3.控制台输出
SyncThread2:count:0
SyncThread2:count:1
SyncThread2:count:2
SyncThread2:count:3
SyncThread2:count:4
SyncThread2:count:5
SyncThread2:count:6
SyncThread2:count:7
SyncThread2:count:8
SyncThread2:count:9
SyncThread1:count:10
SyncThread1:count:11
SyncThread1:count:12
SyncThread1:count:13
SyncThread1:count:14
SyncThread1:count:15
SyncThread1:count:16
SyncThread1:count:17
SyncThread1:count:18
SyncThread1:count:194.修改代码块为俩对象(创建俩线程,分别对应俩对象):
public class codeBlock {
public static void main(String[] args) {
Thread thread1 = new Thread(new SyncThread(), "SyncThread1");
Thread thread2 = new Thread(new SyncThread(), "SyncThread2");
thread1.start();
thread2.start();
}
}5.控制台输出(没有保证到线程安全性, 主要由于count是静态变量)
SyncThread1:count:0
SyncThread2:count:1
SyncThread1:count:2
SyncThread2:count:2
SyncThread2:count:3
SyncThread1:count:4
SyncThread2:count:6
SyncThread1:count:5
SyncThread2:count:7
SyncThread1:count:8
SyncThread1:count:10
SyncThread2:count:9
SyncThread2:count:11
SyncThread1:count:12
SyncThread1:count:13
SyncThread2:count:14
SyncThread1:count:15
SyncThread2:count:15
SyncThread1:count:16
SyncThread2:count:16二、修饰一个代码块(非this,而是指定对象)
修饰的结果(同synchronized(this)):
- 一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程将被阻塞;
- 多个线程访问各子的对象即使有synchronized修饰了同步代码块,但是互不阻塞,但是并不能保证静态变量的线程安全性;
- 当一个线程访问对象的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该对象中的非synchronized(this)同步代码块。
代码块:
1.synchronized修饰的方法使用:
/**
* 同步线程
*/
class Food implements Runnable {
public Food(Vegetables vegetables,Fruits fruits) {
this.vegetables =vegetables;
this.fruits=fruits;
}
private Vegetables vegetables;
private Fruits fruits;
@Override
public void run() {
synchronized (vegetables) {
for (int i = 0; i < 10; i++) {
vegetables.addVegetables("cabbage" + i);
System.out.println(Thread.currentThread().getName() + ":" + vegetables.getLastVegetables());
}
}
synchronized (fruits) {
for (int i = 0; i < 10; i++) {
fruits.addFruits("apple" + i);
System.out.println(Thread.currentThread().getName() + ":" + fruits.getLastFruits());
}
}
}
}
class Fruits {
private String[] list = new String[10];
int index;
public Fruits() {
}
public void addFruits(String fruitname) {
if (index >= 0 && index <= 9) {
list[index++] = fruitname;
}
}
public String getLastFruits() {
return list[index-1];
}
}
class Vegetables {
private String[] list = new String[10];
int index;
public Vegetables() {
}
public void addVegetables(String Vegetablename) {
if (index >= 0 && index <= 9) {
list[index++] = Vegetablename;
}
}
public String getLastVegetables() {
return list[index-1];
}
}
2.验证调用代码(创建俩线程,调用一个对象)
public class codeBlock04 {
public static void main(String[] args) {
Food food = new Food(new Vegetables(),new Fruits());
Thread thread1 = new Thread(food,"Thread1");
Thread thread2 = new Thread(food,"Thread2");
thread1.start();
thread2.start();
}
}3.控制台输出
Thread2:cabbage0
Thread2:cabbage1
Thread2:cabbage2
Thread2:cabbage3
Thread2:cabbage4
Thread2:cabbage5
Thread2:cabbage6
Thread2:cabbage7
Thread2:cabbage8
Thread2:cabbage9
Thread1:cabbage9
Thread2:apple0
Thread1:cabbage9
Thread2:apple1
Thread1:cabbage9
Thread2:apple2
Thread1:cabbage9
Thread2:apple3
Thread1:cabbage9
Thread2:apple4
Thread2:apple5
Thread1:cabbage9
Thread2:apple6
Thread1:cabbage9
Thread2:apple7
Thread2:apple8
Thread1:cabbage9
Thread1:cabbage9
Thread1:cabbage9
Thread2:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
Thread1:apple9
可以看到对于fruit和vegetable对象而言各自是线程安全的,保证了各自在线程1、2中都是从1递增到9的,另一方面,synchronized控制的分别fruit和vegetable对象的同步,而food对象是可以同时被线程1、2访问并且不互相阻塞。index超过9之后无法加入内置数组。
三、修饰一个代码块
Synchronized修饰一个方法很简单,就是在方法的前面加synchronized,public synchronized void method(){//todo}; synchronized修饰方法和修饰一个代码块类似,只是作用范围不一样,修饰代码块是大括号括起来的范围,而修饰方法范围是整个函数。
代码块:
1.synchronized修饰一个方法:
public synchronized void run() {
for (int i = 0; i < 5; i ++) {
try {
System.out.println(Thread.currentThread().getName() + ":" + (count++));
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}2. synchronized关键字不能继承
.synchronized修饰方法的注意事项
- synchronized修饰接口的定义方法;
- 构造方法不能使用synchronized关键字,但可以synchronized来进行对象的初始化。(解释:由于锁即对象,构造函数用于创建对象,无对象何来锁,锁的安全性也不用顾及);
- synchronized方法不能继承其synchronized关键字。
四、修饰一个修饰一个静态的方法
Synchronized也可修饰一个静态方法,用法如下:
public synchronized static void method() {
// todo
}我们知道静态方法是属于类的而不属于对象的。同样的,synchronized修饰的静态方法锁定的是这个类的所有对象。我们对Demo1进行一些修改如下:
1.synchronized修饰静态方法
/**
* 同步线程
*/
class SyncThread implements Runnable {
private static int count;
public SyncThread() {
count = 0;
}
public synchronized static void method() {
for (int i = 0; i < 5; i ++) {
try {
System.out.println(Thread.currentThread().getName() + ":" + (count++));
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public synchronized void run() {
method();
}
}2.调用main方法:
SyncThread syncThread1 = new SyncThread();
SyncThread syncThread2 = new SyncThread();
Thread thread1 = new Thread(syncThread1, "SyncThread1");
Thread thread2 = new Thread(syncThread2, "SyncThread2");
thread1.start();
thread2.start();3.控制台输出:
SyncThread2:0
SyncThread2:1
SyncThread2:2
SyncThread2:3
SyncThread2:4
SyncThread1:5
SyncThread1:6
SyncThread1:7
SyncThread1:8
SyncThread1:94.分析:
可以看到在对静态方法使用synchronized修饰之后,即使线程1、2调用俩个不同对象,但还是相互有阻塞,仍然保持了线程的同步。这是因为run中调用了静态方法method,而静态方法是属于类的,所以syncThread1和syncThread2相当于用了同一把锁。
五、修饰一个类
Synchronized还可作用于一个类,用法如下:
class ClassName {
public void method() {
synchronized(ClassName.class) {
// todo
}
}
}1.synchronized修饰类
class SyncThread3 implements Runnable {
private static int count;
public SyncThread3() {
count = 0;
}
public static void method() {
synchronized(SyncThread.class) {
for (int i = 0; i < 5; i ++) {
try {
System.out.println(Thread.currentThread().getName() + ":" + (count++));
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public synchronized void run() {
method();
}
}
其效果和synchronized修饰一个静态方法所达到的效果是一样的,synchronized作用于一个类T时,是给这个类T加锁,T的所有对象用的是同一把锁。
6.ReentrantLock使用场景和实例
锁的种类
1.1 可重入锁
如果锁具备可重入性,则称作为可重入锁。synchronized和ReentrantLock都是可重入锁,可重入性在我看来实际上表明了锁的分配机制:基于线程的分配,而不是基于方法调用的分配。举比如说,当一个线程执行到method1 的synchronized方法时,而在method1中会调用另外一个synchronized方法method2,此时该线程不必重新去申请锁,而是可以直接执行方法method2。
1.2 读写锁
读写锁将对一个资源的访问分成了2个锁,如文件,一个读锁和一个写锁。正因为有了读写锁,才使得多个线程之间的读操作不会发生冲突。ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。可以通过readLock()获取读锁,通过writeLock()获取写锁。
1.3 可中断锁
可中断锁,即可以中断的锁。在Java中,synchronized就不是可中断锁,而Lock是可中断锁。 如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
Lock接口中的lockInterruptibly()方法就体现了Lock的可中断性。
1.4 公平锁
公平锁即尽量以请求锁的顺序来获取锁。同时有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该锁,这种就是公平锁。
非公平锁即无法保证锁的获取是按照请求锁的顺序进行的,这样就可能导致某个或者一些线程永远获取不到锁。
synchronized是非公平锁,它无法保证等待的线程获取锁的顺序。对于ReentrantLock和ReentrantReadWriteLock,默认情况下是非公平锁,但是可以设置为公平锁。
Condition:ReentrantLock提供了比Sync更精准的线程调度工具,Condition,一个lock可以有多个Condition,比如在生产消费的业务下,一个锁通过控制生产Condition和消费Condition精准控制。
可重入概念
若一个程序或子程序可以“安全的被并行执行(Parallel computing)”,则称其为可重入(reentrant或re-entrant)的。即当该子程序正在运行时,可以再次进入并执行它(并行执行时,个别的执行结果,都符合设计时的预期)。可重入概念是在单线程操作系统的时代提出的。
场景1:如果发现该操作已经在执行中则不再执行(有状态执行)
a、用在定时任务时,如果任务执行时间可能超过下次计划执行时间,确保该有状态任务只有一个正在执行,忽略重复触发。
b、用在界面交互时点击执行较长时间请求操作时,防止多次点击导致后台重复执行(忽略重复触发)。
以上两种情况多用于进行非重要任务防止重复执行,(如:清除无用临时文件,检查某些资源的可用性,数据备份操作等)

场景2:如果发现该操作已经在执行,等待一个一个执行(同步执行,类似synchronized)
这种比较常见大家也都在用,主要是防止资源使用冲突,保证同一时间内只有一个操作可以使用该资源。
但与synchronized的明显区别是性能优势(伴随jvm的优化这个差距在减小)。同时Lock有更灵活的锁定方式,公平锁与不公平锁,而synchronized永远是公平的。
这种情况主要用于对资源的争抢(如:文件操作,同步消息发送,有状态的操作等)
ReentrantLock默认情况下为不公平锁
不公平锁与公平锁的区别:
公平情况下,操作会排一个队按顺序执行,来保证执行顺序。(会消耗更多的时间来排队)
不公平情况下,是无序状态允许插队,jvm会自动计算如何处理更快速来调度插队。(如果不关心顺序,这个速度会更快)

场景3:如果发现该操作已经在执行,则尝试等待一段时间,等待超时则不执行(尝试等待执行)
这种其实属于场景2的改进,等待获得锁的操作有一个时间的限制,如果超时则放弃执行。
用来防止由于资源处理不当长时间占用导致死锁情况(大家都在等待资源,导致线程队列溢出)。

场景4:如果发现该操作已经在执行,等待执行。这时可中断正在进行的操作立刻释放锁继续下一操作
synchronized与Lock在默认情况下是不会响应中断(interrupt)操作,会继续执行完。lockInterruptibly()提供了可中断锁来解决此问题。(场景2的另一种改进,没有超时,只能等待中断或执行完毕)
这种情况主要用于取消某些操作对资源的占用。如:(取消正在同步运行的操作,来防止不正常操作长时间占用造成的阻塞)

下面是ReentrantLock的一个代码示例
//: concurrency/AttemptLocking.java
// 以下是ReentrantLock中断机制的一个代码实现、如果换成synchronized就会出现死锁
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
public class AttemptLocking {
private ReentrantLock lock = new ReentrantLock();
public void untimed() {
boolean captured = lock.tryLock();
try {
System.out.println("tryLock(): " + captured);
} finally {
if (captured)
lock.unlock();
}
}
public void timed() {
boolean captured = false;
try {
captured = lock.tryLock(2, TimeUnit.SECONDS);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
try {
System.out.println("tryLock(2, TimeUnit.SECONDS): " + captured);
} finally {
if (captured)
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
final AttemptLocking al = new AttemptLocking();
al.untimed(); // True -- 可以成功获得锁
al.timed(); // True --可以成功获得锁
//新创建一个线程获得锁并且不释放
new Thread() {
{
setDaemon(true);
}
public void run() {
al.lock.lock();
System.out.println("acquired");
}
}.start();
Thread.sleep(100);// 保证新线程能够先执行
al.untimed(); // False -- 马上中断放弃
al.timed(); // False -- 等两秒超时后中断放弃
}
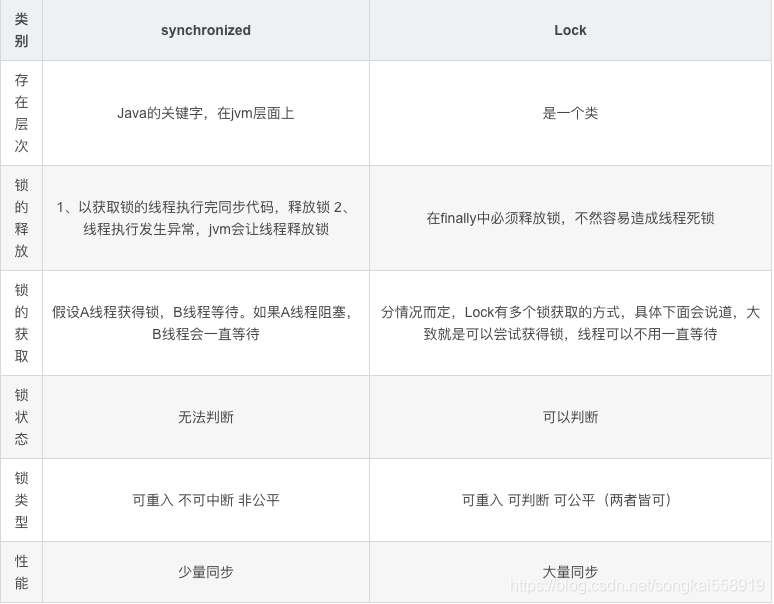
} synchronized和Lock有什么区别?
- 实现层面不一样。synchronized 是 Java 关键字,JVM层面 实现加锁和释放锁;Lock 是一个接口,在代码层面实现加锁和释放锁
- 是否自动释放锁。synchronized 在线程代码执行完或出现异常时自动释放锁;Lock 不会自动释放锁,需要再 finally {} 代码块显式地中释放锁
- 是否一直等待。synchronized 会导致线程拿不到锁一直等待;Lock 可以设置尝试获取锁或者获取锁失败一定时间超时
- 获取锁成功是否可知。synchronized 无法得知是否获取锁成功;Lock 可以通过 tryLock 获得加锁是否成功
- 功能复杂性。synchronized 加锁可重入、不可中断、非公平;Lock 可重入、可判断、可公平和不公平、细分读写锁提高效率
3.1 synchronized和lock的区别
- Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
- synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;
- Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
- 通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
- Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)
- 性能上来说,在资源竞争不激烈的情形下,Lock性能稍微比synchronized差点(编译程序通常会尽可能的进行优化synchronized)。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
7.Redis 持久化
Redis虽然是一种内存型数据库,一旦服务器进程退出,数据库的数据就会丢失,为了解决这个问题Redis提供了两种持久化的方案,将内存中的数据保存到磁盘中,避免数据的丢失。
RDB持久化
redis提供了RDB持久化的功能,这个功能可以将redis在内存中的的状态保存到硬盘中,它可以手动执行,也可以再redis.conf中配置,定期执行。
RDB持久化产生的RDB文件是一个经过压缩的二进制文件,这个文件被保存在硬盘中,redis可以通过这个文件还原数据库当时的状态
RDB的创建与载入
RDB文件可以通过两个命令来生成:
SAVE:阻塞redis的服务器进程,直到RDB文件被创建完毕。BGSAVE:派生(fork)一个子进程来创建新的RDB文件,记录接收到BGSAVE当时的数据库状态,父进程继续处理接收到的命令,子进程完成文件的创建之后,会发送信号给父进程,而与此同时,父进程处理命令的同时,通过轮询来接收子进程的信号。
而RDB文件的载入一般情况是自动的,redis服务器启动的时候,redis服务器再启动的时候如果检测到RDB文件的存在,那么redis会自动载入这个文件。
如果服务器开启了AOF持久化,那么服务器会优先使用AOF文件来还原数据库状态。
RDB是通过保存键值对来记录数据库状态的,采用copy on write的模式,每次都是全量的备份。
自动保存间隔
BGSAVE可以在不阻塞主进程的情况下完成数据的备份。可以通过redis.conf中设置多个自动保存条件,只要有一个条件被满足,服务器就会执行BGSAVE命令。
# 以下配置表示的条件:
# 服务器在900秒之内被修改了1次
save 900 1
# 服务器在300秒之内被修改了10次
save 300 10
# 服务器在60秒之内被修改了10000次
save 60 10000AOF持久化
AOF持久化(Append-Only-File),与RDB持久化不同,AOF持久化是通过保存Redis服务器锁执行的写状态来记录数据库的。
具体来说,RDB持久化相当于备份数据库状态,而AOF持久化是备份数据库接收到的命令,所有被写入AOF的命令都是以redis的协议格式来保存的。
在AOF持久化的文件中,数据库会记录下所有变更数据库状态的命令,除了指定数据库的select命令,其他的命令都是来自client的,这些命令会以追加(append)的形式保存到文件中。
服务器配置中有一项appendfsync,这个配置会影响服务器多久完成一次命令的记录:
always:将缓存区的内容总是即时写到AOF文件中。everysec:将缓存区的内容每隔一秒写入AOF文件中。no:写入AOF文件中的操作由操作系统决定,一般而言为了提高效率,操作系统会等待缓存区被填满,才会开始同步数据到磁盘。
redis默认实用的是everysec。
redis在载入AOF文件的时候,会创建一个虚拟的client,把AOF中每一条命令都执行一遍,最终还原回数据库的状态,它的载入也是自动的。在RDB和AOF备份文件都有的情况下,redis会优先载入AOF备份文件
AOF文件可能会随着服务器运行的时间越来越大,可以利用AOF重写的功能,来控制AOF文件的大小。AOF重写功能会首先读取数据库中现有的键值对状态,然后根据类型使用一条命令来替代前的键值对多条命令。
AOF重写功能有大量写入操作,所以redis才用子进程来处理AOF重写。这里带来一个新的问题,由于处理重新的是子进程,这样意味着如果主线程的数据在此时被修改,备份的数据和主库的数据将会有不一致的情况发生。因此redis还设置了一个AOF重写缓冲区,这个缓冲区在子进程被创建开始之后开始使用,这个期间,所有的命令会被存两份,一份在AOF缓存空间,一份在AOF重写缓冲区,当AOF重写完成之后,子进程发送信号给主进程,通知主进程将AOF重写缓冲区的内容添加到AOF文件中。
相关配置
#AOF 和 RDB 持久化方式可以同时启动并且无冲突。
#如果AOF开启,启动redis时会加载aof文件,这些文件能够提供更好的保证。
appendonly yes
# 只增文件的文件名称。(默认是appendonly.aof)
# appendfilename appendonly.aof
#redis支持三种不同的写入方式:
#
# no:不调用,之等待操作系统来清空缓冲区当操作系统要输出数据时。很快。
# always: 每次更新数据都写入仅增日志文件。慢,但是最安全。
# everysec: 每秒调用一次。折中。
appendfsync everysec
# 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入.官方文档建议如果你有特殊的情况可以配置为'yes'。但是配置为'no'是最为安全的选择。
no-appendfsync-on-rewrite no
# 自动重写只增文件。
# redis可以自动盲从的调用‘BGREWRITEAOF’来重写日志文件,如果日志文件增长了指定的百分比。
# 当前AOF文件大小是上次日志重写得到AOF文件大小的二倍时,自动启动新的日志重写过程。
auto-aof-rewrite-percentage 100
# 当前AOF文件启动新的日志重写过程的最小值,避免刚刚启动Reids时由于文件尺寸较小导致频繁的重写。
auto-aof-rewrite-min-size 64mb对比
AOF更安全,可将数据及时同步到文件中,但需要较多的磁盘IO,AOF文件尺寸较大,文件内容恢复相对较慢, 也更完整。RDB持久化,安全性较差,它是正常时期数据备份及master-slave数据同步的最佳手段,文件尺寸较小,恢复数度较快。
8.SpringBoot启动过程源码分析
SpringBoot启动流程图

那我们就根据上面的启动流程图进行分析。
初始化SpingApplication对象
我们直接找到初始化SpingApplication对象的initialize方法。
private void initialize(Object[] sources) {
if (sources != null && sources.length > 0) {
this.sources.addAll(Arrays.asList(sources));
}
//检查当前环境是否是web环境
this.webEnvironment = deduceWebEnvironment();
//初始化ApplicationContextInitializer的实现类
setInitializers((Collection) getSpringFactoriesInstances(
ApplicationContextInitializer.class));
//初始化ApplicationListener的实现类
setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));
this.mainApplicationClass = deduceMainApplicationClass();
}9.Hibernate一级缓存和二级缓存的区别
一级缓存
session级别的缓存,当我们使用了get load find Query等查询出来的数据,默认在session中就会有一份缓存数据,缓存数据就是从数据库将一些数据拷贝一份放到对应的地方.
一级缓存不可卸载: (只要使用了session,肯定用到了session的缓存机制,是hibernate控制的,我们不能手动配置)
一级缓存的清理:
close clear这两种方式会全部清理; evict方法是将指定的缓存清理掉
二级缓存
sessionFactory级别的缓存,可以做到多个session共享此信息
sessionFactory缓存分类:
1. 内缓存: 预制的sql语句,对象和数据库的映射信息
2. 外缓存:存储的是我们允许使用二级缓存的对象
适合放在二级缓存中的数据:
1. 经常被修改的数据
2. 不是很想重要的数据,允许出现偶尔并发的数据
3. 不会被并发访问的数据
4. 参考数据
适合放到一级缓存中的数据:
1. 经常被修改的数据
2. 财务数据,绝对不允许出现并发
3. 与其它应用共享的数据
10.过滤器(Filter)和拦截器(Interceptor)的区别
Filter介绍
Filter可以认为是Servlet的一种“加强版”,它主要用于对用户请求进行预处理,也可以对HttpServletResponse进行后处理,是个典型的处理链。Filter也可以对用户请求生成响应,这一点与Servlet相同,但实际上很少会使用Filter向用户请求生成响应。使用Filter完整的流程是:Filter对用户请求进行预处理,接着将请求交给Servlet进行预处理并生成响应,最后Filter再对服务器响应进行后处理。
Filter有如下几个用处。
- 在HttpServletRequest到达Servlet之前,拦截客户的HttpServletRequest。
- 根据需要检查HttpServletRequest,也可以修改HttpServletRequest头和数据。
- 在HttpServletResponse到达客户端之前,拦截HttpServletResponse。
- 根据需要检查HttpServletResponse,也可以修改HttpServletResponse头和数据。
创建一个Filter只需两个步骤
- 创建Filter处理类
- web.xml文件中配置Filter
创建Filter必须实现javax.servlet.Filter接口,在该接口中定义了如下三个方法。
- void init(FilterConfig config):用于完成Filter的初始化。
- void destory():用于Filter销毁前,完成某些资源的回收。
- void doFilter(ServletRequest request,ServletResponse response,FilterChain chain):实现过滤功能,该方法就是对每个请求及响应增加的额外处理。该方法可以实现对用户请求进行预处理(ServletRequest request),也可实现对服务器响应进行后处理(ServletResponse response)—它们的分界线为是否调用了chain.doFilter(),执行该方法之前,即对用户请求进行预处理;执行该方法之后,即对服务器响应进行后处理。
Interceptor介绍
拦截器,在AOP(Aspect-Oriented Programming)中用于在某个方法或字段被访问之前,进行拦截,然后在之前或之后加入某些操作。拦截是AOP的一种实现策略。
Filter和Interceptor的区别
- Filter是基于函数回调的,而Interceptor则是基于Java反射的。
- Filter依赖于Servlet容器,而Interceptor不依赖于Servlet容器。
- Filter对几乎所有的请求起作用,而Interceptor只能对action请求起作用。
- Interceptor可以访问Action的上下文,值栈里的对象,而Filter不能。
- 在action的生命周期里,Interceptor可以被多次调用,而Filter只能在容器初始化时调用一次。
Filter和Interceptor的执行顺序
过滤前-拦截前-action执行-拦截后-过滤后

11.索引创建过多的影响
1.建立索引的字段越多,那数据量大的时候,文件就会越大,查找数据就会变慢.这是最显著的问题.
2.一个索引会在 update 或 insert 时增加一次 I/O,对于操作系统底层来说是非常损耗性能的


















 3412
3412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









