







1 数据准备
CREATE TABLE TEST1 AS SELECT D.* ,trunc(dbms_random.value(0,100)) AS RAN_VAL FROM DBA_OBJECTS D;
2 性能改善
2.1 写法一
SELECT DISTINCT T1.OWNER
FROM TEST1 T1
WHERE RAN_VAL
< (SELECT MAX(T2.RAN_VAL)
FROM TEST1 T2
WHERE T1.OWNER = T2.OWNER);
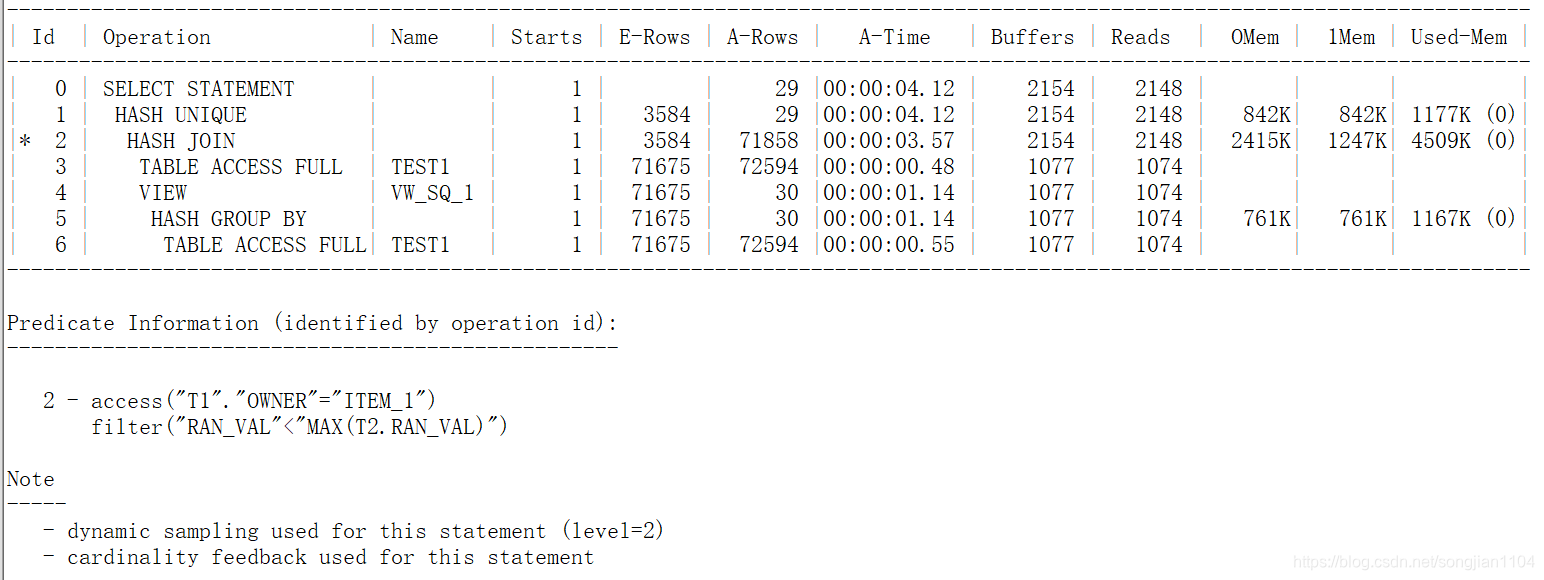
优化器还是很智能的,走了Hash+Filter筛选,避开了Filter连接。
2.2 写法二
SELECT DISTINCT T1.OWNER
FROM TEST1 T1,
(SELECT T2.OWNER, MAX(T2.RAN_VAL) as MAX_VAL
FROM TEST1 T2
GROUP BY T2.OWNER) T3
WHERE T1.OWNER=T3.OWNER
AND T1.RAN_VAL<T3.MAX_VAL;

因为owner列的数据倾斜很大,两表用这种方式连接,结果集类似笛卡儿积。具体参见我的另一篇博客,链接如下:
https://blog.youkuaiyun.com/songjian1104/article/details/91349960
2.3 写法三
SELECT DISTINCT T1.OWNER
FROM TEST1 T1,
(SELECT T2.OWNER, MAX(T2.RAN_VAL) as MAX_VAL
FROM TEST1 T2
WHERE ROWNUM>0
GROUP BY T2.OWNER) T3
WHERE T1.OWNER=T3.OWNER
AND T1.RAN_VAL<T3.MAX_VAL;
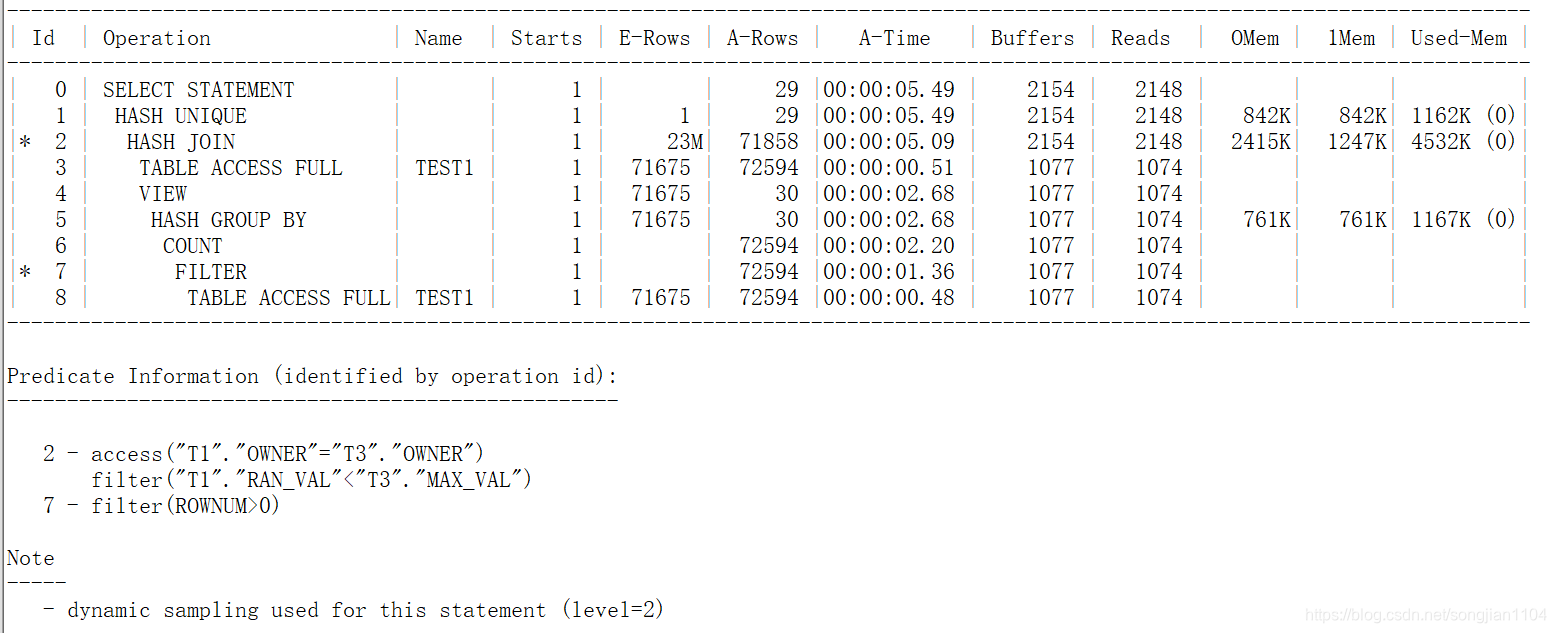
我们故意在T3的子查询里面加了个WHERE ROWNUM>0,为了不让T3内联视图展开,避开写法二的执行计划。
这个执行计划与写法一的执行计划类似。
2.4 写法四
SELECT DISTINCT TT.OWNER
FROM (SELECT T1.OWNER, T1.RAN_VAL
,MAX(T1.RAN_VAL) OVER(PARTITION BY T1.OWNER) AS MAX_VAL_PEROWNER
FROM TEST1 T1) TT
WHERE TT.RAN_VAL<TT.MAX_VAL_PEROWNER;
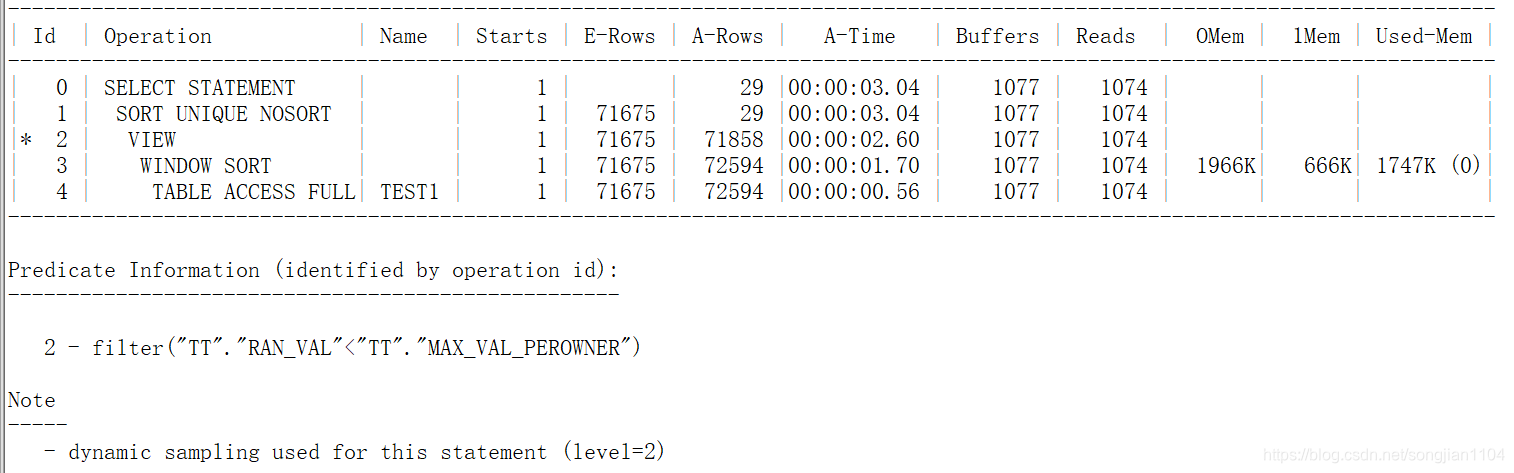
相比之下,这种分析函数改写性能更好,因为减少了扫描次数,同时也避开了自连接。

















 5076
5076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









