







一、系统概述
本文档深入介绍了基于Apache Spark的智能数据挖掘分析处理系统。作为一款高性能、分布式的数据处理平台,它专注于为数据挖掘和分析任务提供强大支持。借助Spark的强大计算能力和灵活架构,系统能够处理海量数据,并融合多种机器学习算法与统计分析工具,轻松实现数据挖掘、清洗、转换、建模及可视化等操作。
从数据源提取原始数据开始,系统就凭借丰富的数据处理功能和强大的挖掘算法,助力用户高效地探索数据规律,快速发现隐藏在海量数据中的模式和趋势。无论是对结构化数据进行深度分析,还是对非结构化数据进行复杂挖掘,它都能胜任。通过可视化和报告模块,还能将挖掘结果以直观易懂的方式呈现,方便非技术用户理解。
二、系统架构
本系统采用模块化架构设计,主要包括以下核心模块:
架构图
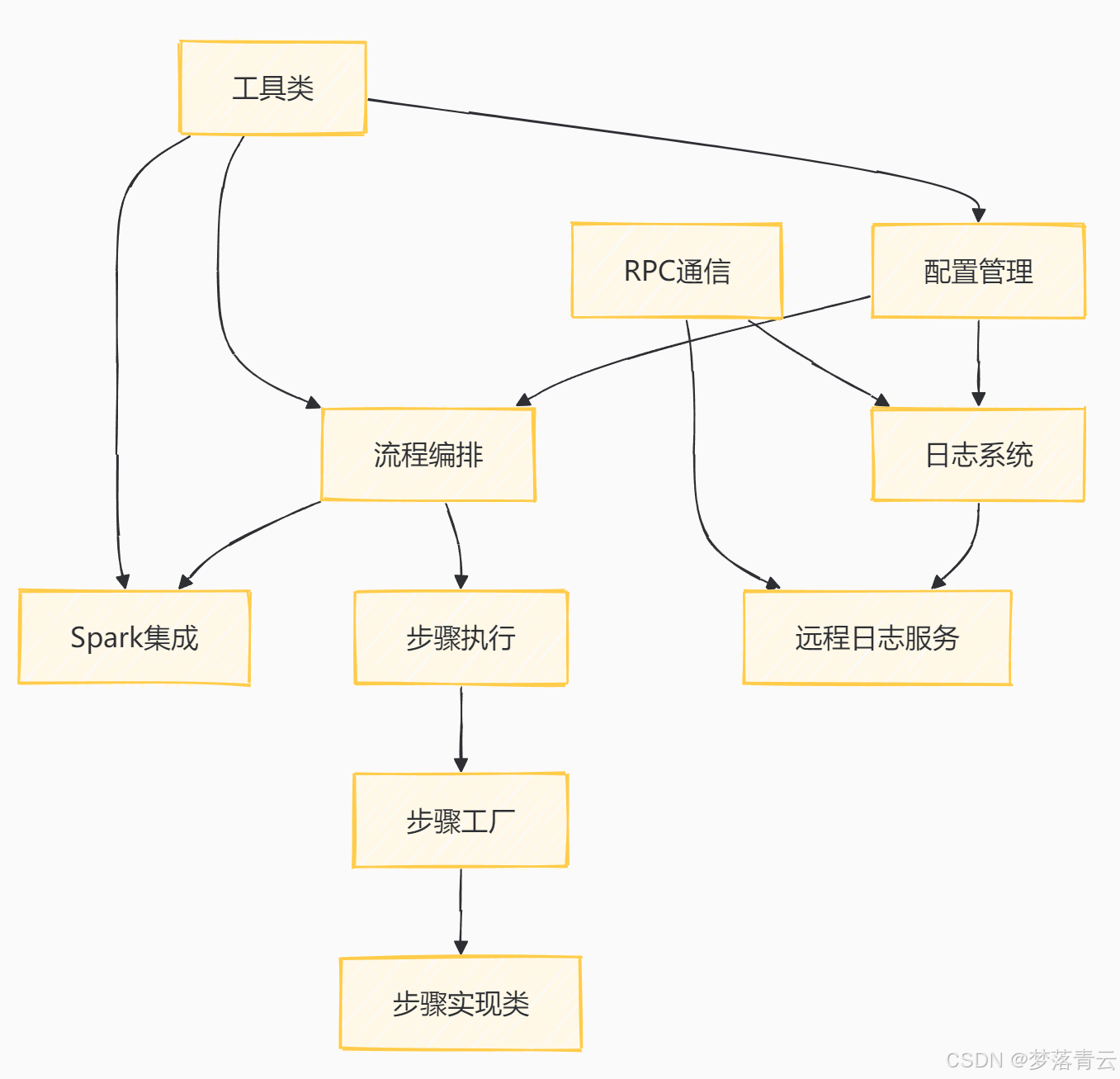
架构详情
-
配置管理模块
负责加载和解析用户提供的JSON配置文件,生成系统运行所需的配置对象。配置文件包含作业的基础信息、数据处理步骤、依赖关系和数据源连接信息等。 -
流程编排模块
使用jgrapht库构建有向图,并通过拓扑排序确保步骤按正确顺序执行。模块解析依赖关系,调度步骤的执行,协调资源分配与回收。 -
Spark集成模块
集成 Apache Spark,支持大规模数据处理和机器学习任务。模块初始化 SparkSession,配置计算资源,注册用户自定义函数(UDF)。 -
步骤执行模块
动态加载和执行数据处理步骤。每个步骤实现FlowStep接口,定义具体的执行逻辑。模块支持数据缓存、视图创建和存储级别配置。 -
日志系统模块
提供日志记录、错误处理和执行报告生成功能。支持本地和远程日志服务,可动态切换日志实现类。 -
工具类模块
提供通用工具类(如文件读取、异常处理、UDF注册等),支持系统的灵活扩展。
三、系统核心功能
-
智能流程编排</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











