







 本文介绍Python中正则表达式的使用方法,包括创建正则表达式对象、使用search及findall方法查找字符串中的匹配项,并讲解了如何利用正则表达式进行模式匹配和分组。
本文介绍Python中正则表达式的使用方法,包括创建正则表达式对象、使用search及findall方法查找字符串中的匹配项,并讲解了如何利用正则表达式进行模式匹配和分组。
----Python编程快速上手_让繁琐工作自动化
使用正则表达式前:检查字符串是否匹配模式
1.检查字符串是否匹配模式
自己动手:def isPhoneNumber(text):
if not len(text) == 12:
return False #
for i in range(12):
if not text[:3].isdecimal():
return False
elif not text[3] == '-':
return False
elif not text[4:7].isdecimal():
return False
elif not text[7] == '-':
return False
elif not text[8:].isdecimal():
return False
else:
return True
print('Please type corect phone number:')
num = input()
print('Your number is '+str(isPhoneNumber(num)))默认参数:
DEF函数默认参数
我们在定义函数时有时候有些参数在大部分情况下是相同的,只不过为了提高函数的适用性,提供了一些备选的参数, 为了方便函数调用,我们可以将这些参数设置为默认参数,那么该参数在函数调用过程中可以不需要明确给出。
#基本使用
1 def function_name(para_1,...,para_n=defau_n,..., para_m=defau_m):
2 expressions函数声明只需要在需要默认参数的地方用 = 号给定即可, 但是要注意所有的默认参数都不能出现在非默认参数的前面。
#实例
1 def sale_car(price, color='red', brand='carmy', is_second_hand=True):
2 print('price', price,
3 'color', color,
4 'brand', brand,
5 'is_second_hand', is_second_hand,)在这里定义了一个 sale_car 函数,参数为车的属性,但除了 price 之外,像 color, brand 和 is_second_hand 都是有默认值的,如果我们调用函数 sale_car(1000), 那么与 sale_car(1000, 'red', 'carmy', True) 是一样的效果。当然也可以在函数调用过程中传入特定的参数用来修改默认参数。通过默认参数可以减轻我们函数调用的复杂度。
2.找出字符串中的特定模式字符
def isPhoneNumber(text):
if not len(text) == 12:
return False
for i in range(12):
if not text[:3].isdecimal():
return False
elif not text[3] == '-':
return False
elif not text[4:7].isdecimal():
return False
elif not text[7] == '-':
return False
elif not text[8:].isdecimal():
return False
else:
return True
print('Type something,I can find the phone number!')
num = input()
for i in range(len(num)):
phoneNum = num[i:i+12] #切片结尾下标超出实际最大下标值,不影响实际使用!
if isPhoneNumber(phoneNum):
print('Find it!'+phoneNum.rjust(15,' '))
print('Done!')创建正则表达式对象
Python中所有的正则表达式的函数都在re模块中,所以在使用正则表达式函数前都要记得导入re模块!
向re.compile()传入一个字符串值,表示正则表达式,它将返回一个Regex对象(全称Regex模式对象)
import re
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') ?一定要用原始字符串吗?有何优势?
he = phoneNumRegex.search('My phone number is 338-297-8023')
print('The phone number is '+he.group()) ?若有多个实际匹配对象,还是直接用group()方法吗?!!!re模块下的compile()函数将返回一个Regex对象,而Regex对象的search()方法将返回一个Match对象,最终Match对象的group()方法将放回被查找字符串的实际匹配文本
正则表达式使用步骤:
1.用import re 导入正则表达式模块。
2.用re.compile()函数创建一个Regex 对象(记得使用原始字符串)。
3.向Regex 对象的search()方法传入想查找的字符串。它返回一个Match 对象。
4.调用Match 对象的group()方法,返回实际匹配文本的字符串。
解答:一定要用原始字符串吗?有何优势?
import re
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
he = phoneNumRegex.findall('My phone number is 338-297-8023anbfASBDfshbfsdbfhsdbf444454-465-4654zdrhzdfhzdh789-789-4564h')
for i in he:
print(i) 2.直接调用re模块中findall()函数import re
m = re.findall(r'\d\d\d-\d\d\d-\d\d\d\d','My phone number is 338-297-8023anbfASBDfshbfsdbfhsdbf444454-465-4654zdrhzdfhzdh789-789-4564h')
for i in m:
print(i)利用括号给正则表达式分组
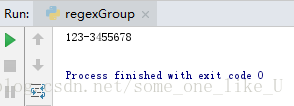
import re
chRegex = re.compile(r'(\d\d\d-\d\d\d)-(\d\d\d\d)')
mo = chRegex.search('csjdhfjcd123-345-5678')
print(mo.group(1)+mo.group(2))
用管道匹配多个分组
字符|称为“管道”。希望匹配许多表达式中的一个时,就可以使用它。例如,
正则表达式r'Batman|Tina Fey'将匹配'Batman'或'Tina Fey'。
如果Batman 和Tina Fey 都出现在被查找的字符串中,第一次出现的匹配文本,
将作为Match 对象返回。在交互式环境中输入以下代码:
可选匹配:
(regex)? 0次或1次

(regex)* 0次或多次

(regex)+ 1次或多次

(regex){aldecimal}|(regex){aldecimal1,aldecimal2}
特定次数|特定范围(从aldecimal1-->aldecimal2)
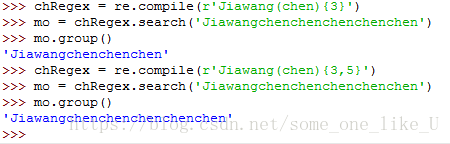
贪心匹配和非贪心匹配
Python 的正则表达式默认是“贪心”的,这表示在有二义的情况下,它们会尽
可能匹配最长的字符串。花括号的“非贪心”版本匹配尽可能最短的字符串,即在
结束的花括号后跟着一个问号。

PS:问号在正则表达式中可能有两种含义:声明非贪心匹配或表示可选的
分组。这两种含义是完全无关的。
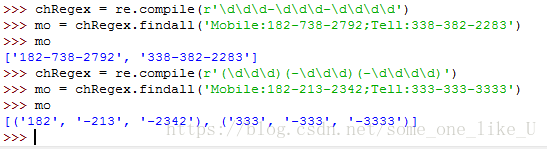
findall方法:
与search()方法的区别:search()方法只返回一个Match对象,findall返回所有Match对象
返回值:如果regex没有分组,则返回一个字符串list;如果regex有分组,则返回一个元组list,元组中元素对对应每一个分组

















 5948
5948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









