







 超级会员免费看
超级会员免费看
 本文介绍了一个使用Spark Structured Streaming与Kafka集成进行资源利用率实时计算的实例。首先,从集群中收集CPU和内存利用率数据并写入Kafka,然后通过Spark消费Kafka数据流进行初步分析和聚合,再将结果返回到Kafka。文章涵盖了Kafka的架构、运行机制,以及如何与Spark集成,包括Kafka环境准备、消息生产和消费等关键步骤。
本文介绍了一个使用Spark Structured Streaming与Kafka集成进行资源利用率实时计算的实例。首先,从集群中收集CPU和内存利用率数据并写入Kafka,然后通过Spark消费Kafka数据流进行初步分析和聚合,再将结果返回到Kafka。文章涵盖了Kafka的架构、运行机制,以及如何与Spark集成,包括Kafka环境准备、消息生产和消费等关键步骤。
结合实例,说一说 Spark 与 Kafka 这对“万金油”组合如何使用。随着业务飞速发展,各家公司的集群规模都是有增无减。在集群规模暴涨的情况下,资源利用率逐渐成为大家越来越关注的焦点。毕竟,不管是自建的 Data center,还是公有云,每台机器都是真金白银的投入。
实例:资源利用率实时计算
咱们今天的实例,就和资源利用率的实时计算有关。具体来说,我们首先需要搜集集群中每台机器的资源(CPU、内存)利用率,并将其写入 Kafka。然后,我们使用 Spark 的 Structured Streaming 来消费 Kafka 数据流,并对资源利用率数据做初步的分析与聚合。最后,再通过 Structured Streaming,将聚合结果打印到 Console、并写回到 Kafka,如下图所示。
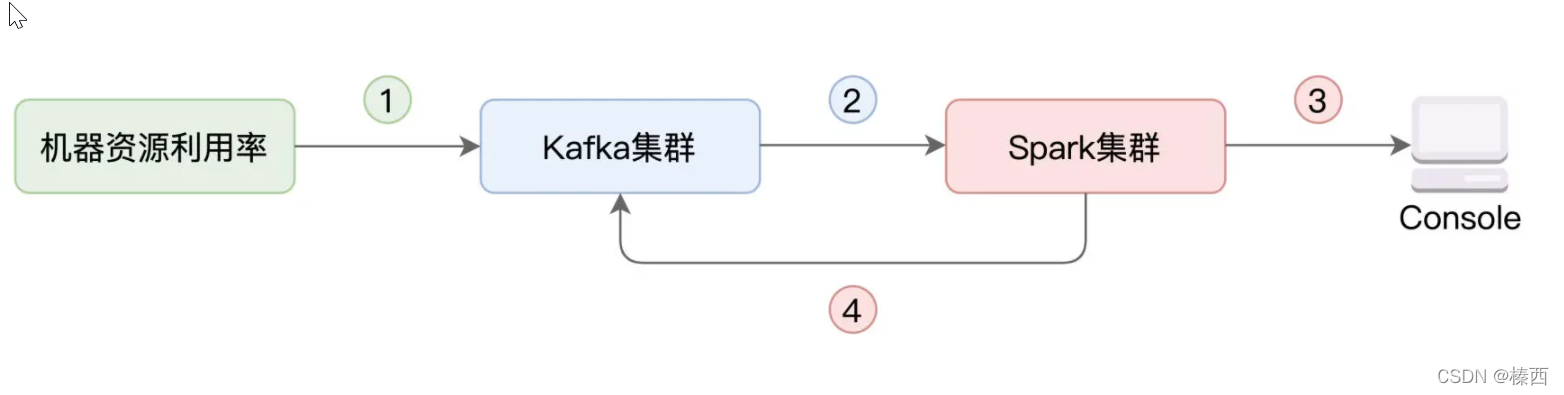
一般来说,在工业级应用中,上图中的每一个圆角矩形,在部署上都是独立的。绿色矩形代表待监测的服务器集群,蓝色矩形表示独立部署的 Kafka 集群,而红色的 Spark 集群,也是独立部署的。所谓独立部署,它指的是,集群之间不共享机器资源,如下图所示。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









