




 本文详细介绍了numpy库中的通用函数,包括np.meshgrid函数用于创建二维矩阵,以及np.where函数实现向量化的三元表达式。通过实例展示了如何使用这些函数进行数组操作,如计算sqrt(x^2 + y^2)和条件判断。此外,还提及了numpy在数学和统计方法、布尔数组方法以及排序等方面的应用。
本文详细介绍了numpy库中的通用函数,包括np.meshgrid函数用于创建二维矩阵,以及np.where函数实现向量化的三元表达式。通过实例展示了如何使用这些函数进行数组操作,如计算sqrt(x^2 + y^2)和条件判断。此外,还提及了numpy在数学和统计方法、布尔数组方法以及排序等方面的应用。
numpy通用函数
一种对narray中的数据执行元素级运算的函数
可以认为这个ufunc可以把一些简单的函数做快速的向量化封装,输入是一个以上的标量,输出也是一个以上的标量。
很多ufuncs都是点对点的变换,像sqrt或exp:
import numpy as np
arr = np.arange(10)
arr
Out : array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.sqrt(arr)
Out : array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
np.exp(arr)
Out : array([ 1.00000000e+00, 2.71828183e+00, 7.38905610e+00,
2.00855369e+01, 5.45981500e+01, 1.48413159e+02,
4.03428793e+02, 1.09663316e+03, 2.98095799e+03,
8.10308393e+03])
x = np.random.randn(8)
y = np.random.randn(8)
np.maximum(x, y)
add或maximum,需要两个数组(binary ufuncs),并返回一个数组作为结果:



数组处理
np.meshgrid函数取两个1维的数组,产生一个2维的矩阵,对应于所有两个数组中(x, y)的组合
m, n = (5, 3)
x = np.linspace(0, 1, m)
y = np.linspace(0, 1, n)
X, Y = np.meshgrid(x, y)
x : array([ 0. , 0.25, 0.5 , 0.75, 1. ])
y : array([ 0. , 0.25, 0.5 , 0.75, 1. ])
X : array([[ 0. , 0.25, 0.5 , 0.75, 1. ],
[ 0. , 0.25, 0.5 , 0.75, 1. ],
[ 0. , 0.25, 0.5 , 0.75, 1. ]])
Y : array([[ 0. , 0. , 0. , 0. , 0. ],
[ 0.5, 0.5, 0.5, 0.5, 0.5],
[ 1. , 1. , 1. , 1. , 1. ]])
把X和Y画出来后,就可以看到网格了:
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
plt.plot(X, Y, marker='.', color='blue', linestyle='none')
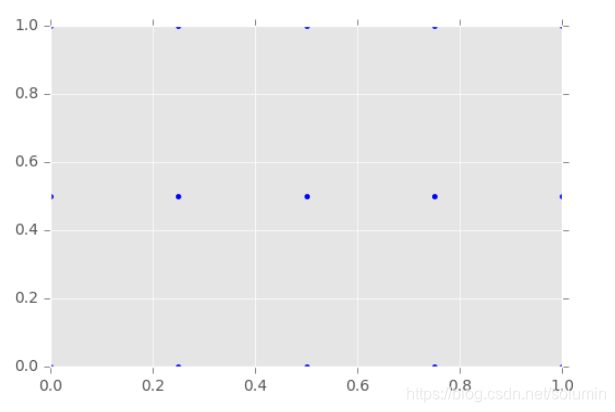
可以用zip得到网格平面上坐标点的数据:
z = [i for i in zip(X.flat, Y.flat)]
z : [(0.0, 0.0),
(0.25, 0.0),
(0.5, 0.0),
(0.75, 0.0),
(1.0, 0.0),
(0.0, 0.5),
(0.25, 0.5),
(0.5, 0.5),
(0.75, 0.5),
(1.0, 0.5),
(0.0, 1.0),
(0.25, 1.0),
(0.5, 1.0),
(0.75, 1.0),
(1.0, 1.0)]
用np.meshgrid函数计算sqrt(x ^ 2 + y^2 )
points = np.arange(-5, 5, 0.01) # 1000 个间隔相同的点
xs, ys = np.meshgrid(points, points) # xs和ys是一样的
ys
ys :
array([[-5. , -5. , -5. , …, -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, …, -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, …, -4.98, -4.98, -4.98],
…,
[ 4.97, 4.97, 4.97, …, 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, …, 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, …, 4.99, 4.99, 4.99]])
z = np.sqrt(xs ** 2 + ys ** 2)
z ;
array([[7.07106781, 7.06400028, 7.05693985, …, 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, …, 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, …, 7.03571603, 7.04278354,
7.04985815],
…,
[7.04988652, 7.04279774, 7.03571603, …, 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, …, 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, …, 7.04279774, 7.04985815,
7.05692568]])
用matplotlib把图画出来:
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
plt.imshow(z, cmap=plt.cm.gray); plt.colorbar()
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")

numpy.where函数是一个向量版的三相表达式,x if condition else y。
假设我们有一个布尔数组和两个数组
xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
cond = np.array([True, False, True, True, False])
假设如果cond中为true,我们取xarr中对应的值,否则就取yarr中的值。列表表达式的话会这么写
result = [(x if c else y)
for x, y, c in zip(xarr, yarr, cond)]
result :
[1.1000000000000001, 2.2000000000000002, 1.3, 1.3999999999999999, 2.5]
这么做的话会有很多问题。首先,对于很大的数组,会比较慢。第二,对于多维数组不起作用。但np.where能让我们写得更简洁:
result = np.where(cond, xarr, yarr)
result
array([ 1.1, 2.2, 1.3, 1.4, 2.5])
np.where中第二个和第三个参数不用必须是数组。where在数据分析中一个典型的用法是基于一个数组,产生一个新的数组值。假设我们有一个随机数字生成的矩阵,我们想要把所有的正数变为2,所有的负数变为-2。用where的话会非常简单:
arr = np.random.randn(4, 4)
arr
array([[ 2.18194474, 0.15001978, -0.77191684, 0.18716397],
[ 1.2083149 , -0.22911585, 1.30880201, 0.14197253],
[ 0.65639111, -1.28394185, 0.65706167, 1.14277598],
[-0.32639966, -0.26880881, -0.10225964, 0.4739671 ]])
arr > 0
array([[ True, True, False, True],
[ True, False, True, True],
[ True, False, True, True],
[False, False, False, True]], dtype=bool)
np.where(arr > 0, 2, -2)
array([[ 2, 2, -2, 2],
[ 2, -2, 2, 2],
[ 2, -2, 2, 2],
[-2, -2, -2, 2]])
我们可以结合标量和数组。比如只把整数变为2,其他仍未原来的数字:
np.where(arr > 0, 2, arr) # set only positive value to 2
array([[ 2. , 2. , -0.77191684, 2. ],
[ 2. , -0.22911585, 2. , 2. ],
[ 2. , -1.28394185, 2. , 2. ],
[-0.32639966, -0.26880881, -0.10225964, 2. ]])
Mathematical and Statistical Methods (数学和统计方法)
一些能计算统计值的数学函数能基于整个数组,或者沿着一个axis(轴)。可以使用aggregations(often called reductions,汇总,或被叫做降维),比如sum, mean, and std(标准差).
下面是一些aggregate statistics(汇总统计):
arr = np.random.randn(5, 4)
arr
array([[-1.53575656, -1.39268394, -1.02284353, -1.03165049],
[ 0.53301867, 0.50258973, -0.49389656, 0.24610963],
[ 0.95377174, -1.57268184, 0.42969986, 1.22912566],
[ 0.73686692, -2.82328155, 0.48018497, -1.38046692],
[ 0.94164808, 0.19599722, -0.88779738, -0.87556277]])
arr.mean()
-0.33838045197794597
np.mean(arr)
-0.33838045197794597
arr.sum()
-6.767609039558919
mean, sum这样的函数能接受axis作为参数来计算统计数字,返回的结果维度更少:
arr.mean(axis=1)
array([-1.24573363, 0.19695537, 0.25997886, -0.74667415, -0.15642871])
arr.sum(axis=0)
array([ 1.62954886, -5.09006038, -1.49465263, -1.81244489])
这里arr.mean(1)表示,compute mean acros the columns(计算各列之间的平均值)。arr.sum(0)表示,compute sum down the rows(计算各行总和)。
其他一些方法,像cumsum和cumprod不做汇总,而是产生一个中间结果的数组:
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7])
arr.cumsum()
array([ 0, 1, 3, 6, 10, 15, 21, 28])
上面的计算是一个累加的结果,0+1=1,1+2=3,3+3=6以此类推。
np.cumsum?
对于多维数组,accumulation functions(累积函数)比如cumsum,返回的是同样大小的数组,但是部分聚合会沿着指示的轴向较低维度进行切片:
arr = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
arr
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
arr.cumsum(axis=0) # 沿着行加法
array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]])
arr.cumprod(axis=1) # 沿着列乘法
array([[ 0, 0, 0],
[ 3, 12, 60],
[ 6, 42, 336]])
这里有一些基本的统计计算方法:
Methods for Boolean Arrays(布尔数组的方法)
sum是用来计算布尔数组中有多少个true的:
arr = np.random.randn(100)
(arr > 0).sum() # Number of positive values
46
有两个其他方法,any和all,对于布尔数组特别有用。any检测数组中只要有一个ture返回就是true,而all检测数组中都是true才会返回true。
bools = np.array([False, False, True, False])
bools.any()
True
bools.all()
False
4 Sorting(排序)
numpy中也有sort方法:
np.random.randn?
返回符合正态分布的数值
arr = np.random.randn(6)
arr
array([ 1.93663555, -1.29810982, 0.83366006, 0.51674613, 2.32879117,
1.07342758])
arr.sort()
arr
array([-1.29810982, 0.51674613, 0.83366006, 1.07342758, 1.93663555,
2.32879117])
如果是多维数组,还可以按axis来排序:
arr = np.random.randn(5, 3)
arr
array([[-0.76658562, -1.00222899, 0.39039437],
[ 0.23100317, -1.0581081 , 1.69177329],
[ 1.0239365 , 0.84698669, -0.97911915],
[ 0.76255951, 0.27828523, 0.41807172],
[ 0.40792019, -1.19514714, -1.41666804]])
arr.sort(1)
arr
array([[-1.00222899, -0.76658562, 0.39039437],
[-1.0581081 , 0.23100317, 1.69177329],
[-0.97911915, 0.84698669, 1.0239365 ],
[ 0.27828523, 0.41807172, 0.76255951],
[-1.41666804, -1.19514714, 0.40792019]])
上面是直接调用数组的sort方法,会改变原有数组的顺序。但如果使用np.sort()函数的话,会生成一个新的排序后的结果。
一个计算分位数的快捷方法是先给数组排序,然后选择某个排名的值:
large_arr = np.random.randn(1000)
large_arr.sort()
large_arr[int(0.05 * len(large_arr))] # 5% quantile
-1.6908607973872243
Unique and Other Set Logic (单一性和其他集合逻辑)
Numpy也有一些基本的集合操作用于一维数组。np.unique,能返回排好序且不重复的值:
names = np.array([‘Bob’, ‘Joe’, ‘Will’, ‘Bob’, ‘Will’, ‘Joe’, ‘Joe’])
np.unique(names)
array([‘Bob’, ‘Joe’, ‘Will’],
dtype=’<U4’)
ints = np.array([3, 3, 3, 2, 2, 1, 1, 4, 4])
np.unique(ints)
array([1, 2, 3, 4])
如果用纯python代码来实现的话,要这么写:
sorted(set(names))
[‘Bob’, ‘Joe’, ‘Will’]
np.in1d, 测试一个数组的值是否在另一个数组里,返回一个布尔数组:
values = np.array([6, 0, 0, 3, 2, 5, 6])
np.in1d(values, [2, 3, 6])
array([ True, False, False, True, True, False, True], dtype=bool)
这里是一些数组的集合操作

















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









