




论文“通胀”背后……
——选择即代价
2025年,如果要在顶会中找一个近乎“通胀”的研究方向,多智能体系统当之无愧。
不仅是论文数量的激增——
以NeurIPS 2025为例:会议近三分之二(60.19%)的论文,都被“智能体与具身智能”相关研究占领。
换言之,每五篇顶会论文中,就有三篇在探讨智能体如何感知、决策与行动。
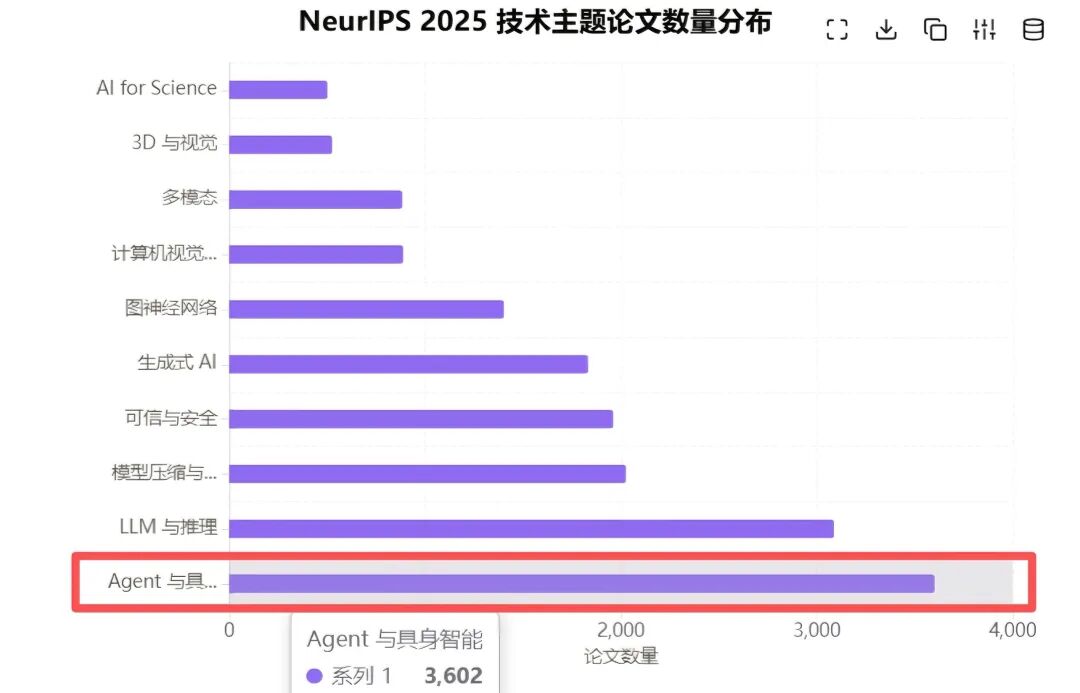
▲图源网络
其背后,一个更具揭示性的结构性变化正在发生:多智能体协同——
正迅速演变为决定整个具身智能高度的“核心战力区”。
当前多智能体研究正高度集中于两条互补且竞争的技术路线上:
基于学习的方法——其内核是分布式涌现,追求一种自下而上的、去中心化的适应性;
基于多模态大模型的方法——其内核是集中式规划,追求一种自上而下的、全局最优的秩序。
今天这篇文章,我们将以2025年Science Robotics、NeurIPS、CoRL、IROS等顶会顶刊的最新工作为切片,聚焦多智能体具身智能这一领域。

基于学习的方法,正是从“个体行为”出发,通过算法让智能体在局部互动中自然浮现。
基于强化学习的多智能体控制
-
Science Robotics:将图神经网络 (GNN) 与强化学习结合,解决多机械臂协同问题。
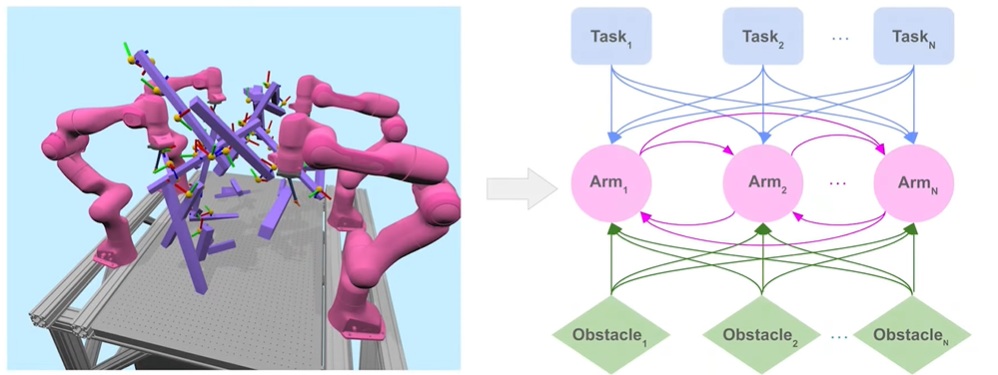
▲图RoboBallet: Planning for Multi-Robot Reaching with Graph Neural Networks and Reinforcement Learning
该研究将多机器人协作建模为图结构,机器人、任务和障碍物为节点,关系为边。
系统可同时协调 8 个机械臂 (56 自由度) 处理 40 个任务,每步规划仅需 0.3 毫秒,实现零碰撞协作。具备零样本泛化能力,无需额外训练即可适应新环境,大幅提升工业自动化效率。

-
NeurIPS 2025:首次引入分层基准策略的两阶段强化学习框架。
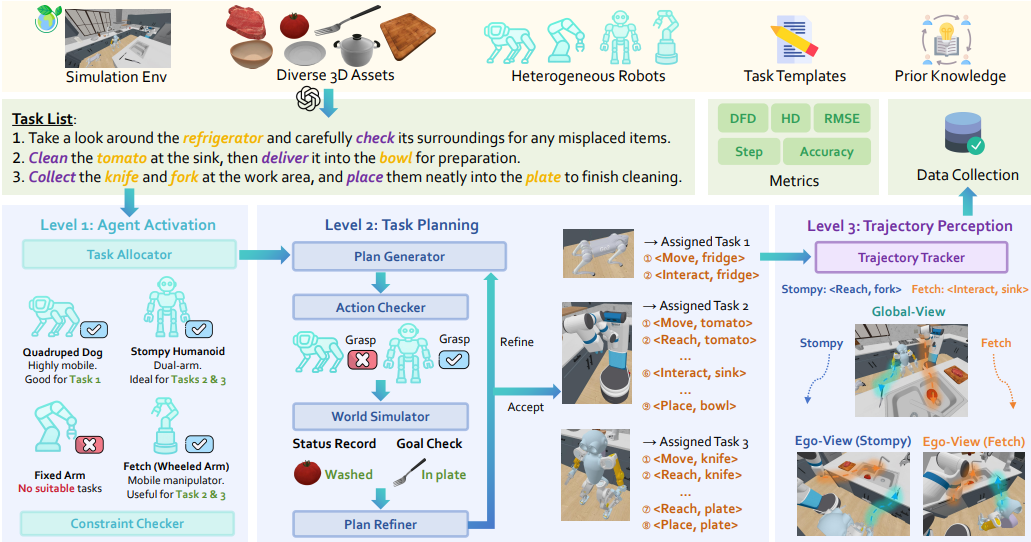
▲图VIKI-R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning
针对异构智能体协作中 “视觉推理弱、奖励信号模糊” 的痛点,该研究先利用思维链注释对预训练视觉语言模型进行微调,再通过多级奖励信号下的强化学习进行优化。
并结合视觉语言模型来增强视觉推理,通过强化学习促进异构智能体的合作模式。
基于模仿学习的多智能体控制
-
ICRA最佳学生论文奖:万机器人部署,终身多智能体路径规划的可扩展模仿学习
首次实现 10,000 个机器人协同路径规划,每步规划耗时 < 1 秒,解决超大规模部署难题。
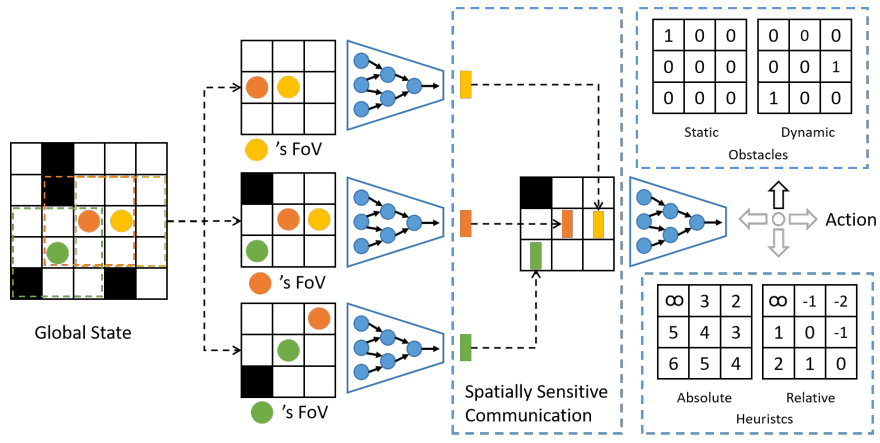
▲图Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding
摒弃传统模仿弱算法的局限,直接模仿高效可扩展的 W-MAPF-LNS 算法(2023 国际竞赛冠军核心),通过自举迭代训练(12 轮迭代,每轮收集 1500 万动作 - 观测对),解决 “训练 - 部署场景脱节” 问题,确保大规模泛化性。
-
ICCV 2025 & CVPR 2025 MEIS 杰出论文奖:首个多智能体具身操作基准
RoboFactory聚焦于探索具身智能体在组合约束下的协作问题。
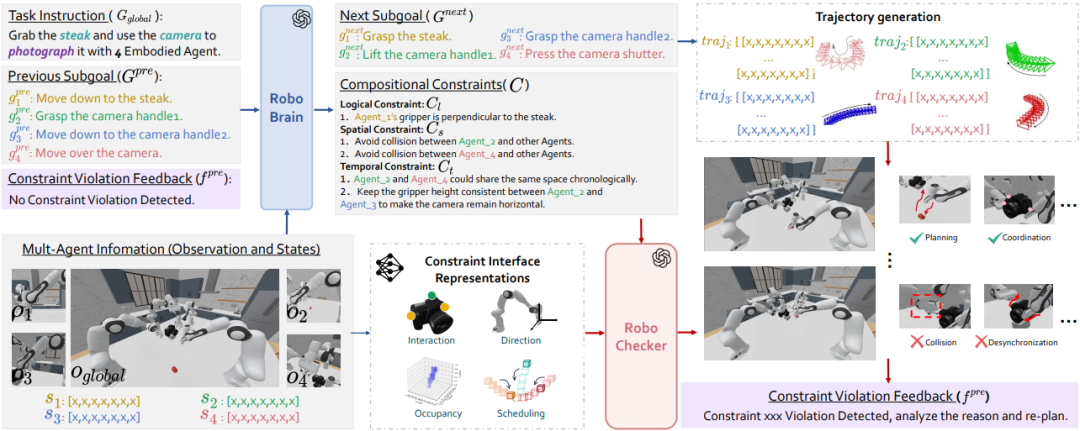
▲图RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints
其核心是:引入逻辑、空间和时间这三类组合约束,以此解决多智能体协作时的安全与效率难题,并开发了自动化数据收集框架。
构建了首个具身多智能体操作基准,填补了多智能体协作操作领域基准和高效数据生成方法的空白。

▲图例:RoboFactory使用4条机械臂进行拍照
基于分层学习的多智能体控制
强化学习与模仿学习解决的是智能体 “如何学” 的问题,而分层学习解决 “学什么(如何拆分任务)” 。
举个例子:IL/RL 是 “学生学习的两种模式”(跟着老师学 / 自己试错学),分层学习是 “学习的组织方式”(先学基础知识点、再学综合应用),二者可叠加(比如 “分层跟着老师学”“分层自己试错学”)。
因此分层学习并非完全独立的方向,常与RL/IL交叉使用。
-
CoRL 2025:首次实现无专家演示的端到端学习
聚焦 3v3 多无人机排球的具身竞争任务,提出全新的强化学习框架——分层协同自博弈(Hierarchical Co-Self-Play, HCSP),把复杂的排球对抗任务拆分为:
-
负责团队战术与角色分配的高层策略(high-level strategy);
-
负责每架无人机的精细飞行与击球动作的低层技能(low-level skill);
通过三阶段无演示训练让多无人机从零涌现排球协同技能。
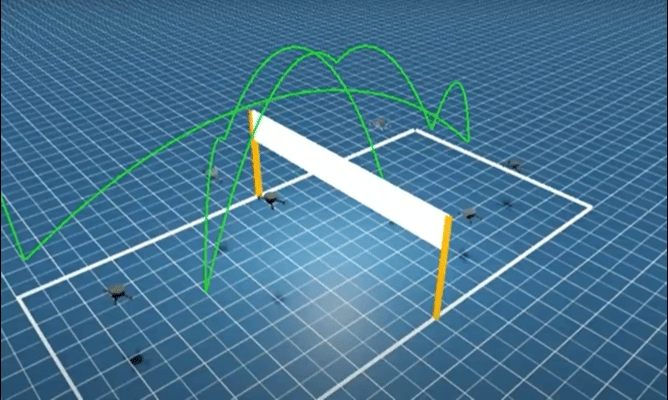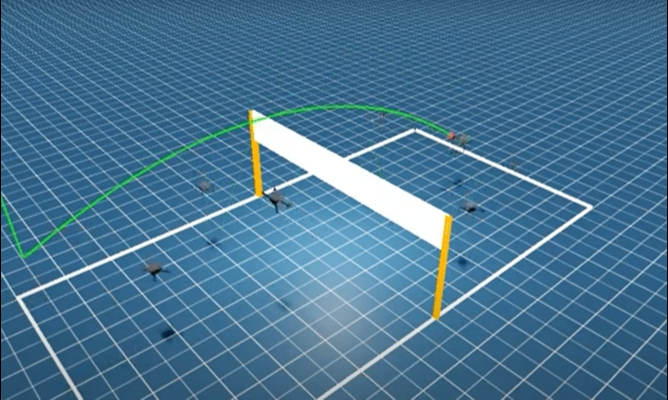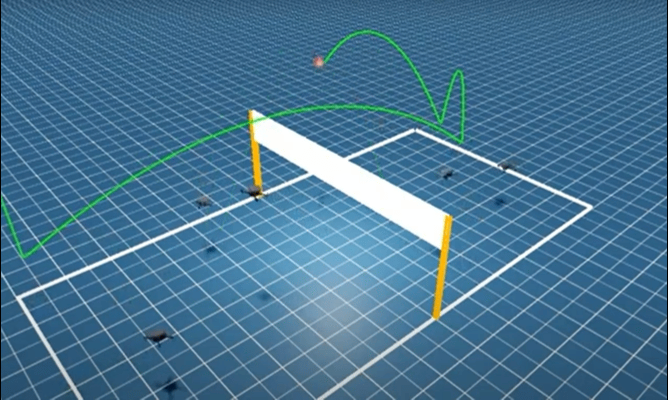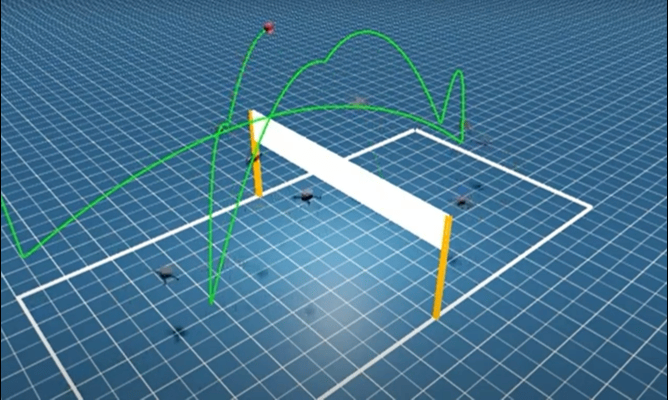
▲图Mastering Multi-Drone Volleyball through Hierarchical Co-Self-Play Reinforcement Learning
小结
无论是强化学习带来的灵活策略探索,模仿学习赋予的规模化行为复制,还是分层学习实现的行为抽象与长期规划,它们共同构建了一个“自下而上”的协作体系。
然而,其瓶颈也相对明显:可扩展性受限、通信成本高昂、长期任务协调困难,且严重依赖仿真环境与密集训练。
这也恰恰为另一条技术路线——基于多模态大模型的方法——提供了切入的契机。

这类方法不再满足于让智能体在试错中摸索协作,而是依靠大模型对任务、场景与交互的深度理解,直接生成统筹方案。
其路径的核心假设是:真正的群体智能,必须先有“全局观”,再有“分布式执行”,形成了一种“自上而下”的协作体系。
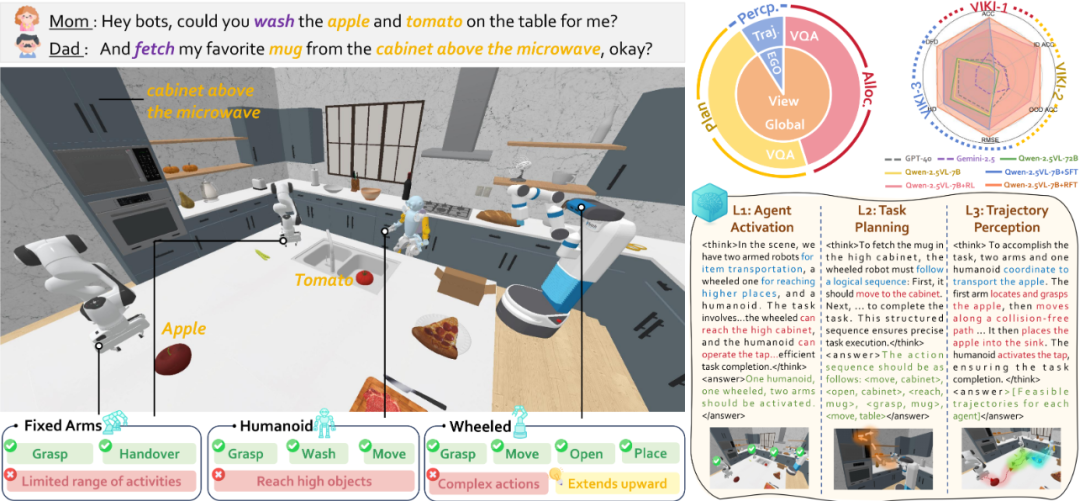
- ICRA 2025:首次实现大语言模型与经典规划算法,在 “任意数量异构多智能体长时任务规划” 场景下的深度融合

▲图LaMMA-P: Generalizable Multi-Agent Long-Horizon Task Allocation and Planning with LM-Driven PDDL Planner。复杂任务:将手表和钥匙圈放入抽屉,然后关掉电视。
通过 LLM 将自然语言指令转化为高层任务描述,再由 PDDL(经典规划算法Planning Domain Definition Language) 生成约束满足的子任务分配与执行序列,支持 2-4 台不同技能的机器人协同,解决了长时任务(如家庭场景多步骤操作)的子任务依赖与并行调度难题。
-
IROS 2024:将自然语言指令分解为可执行的子任务,并分配给不同智能体
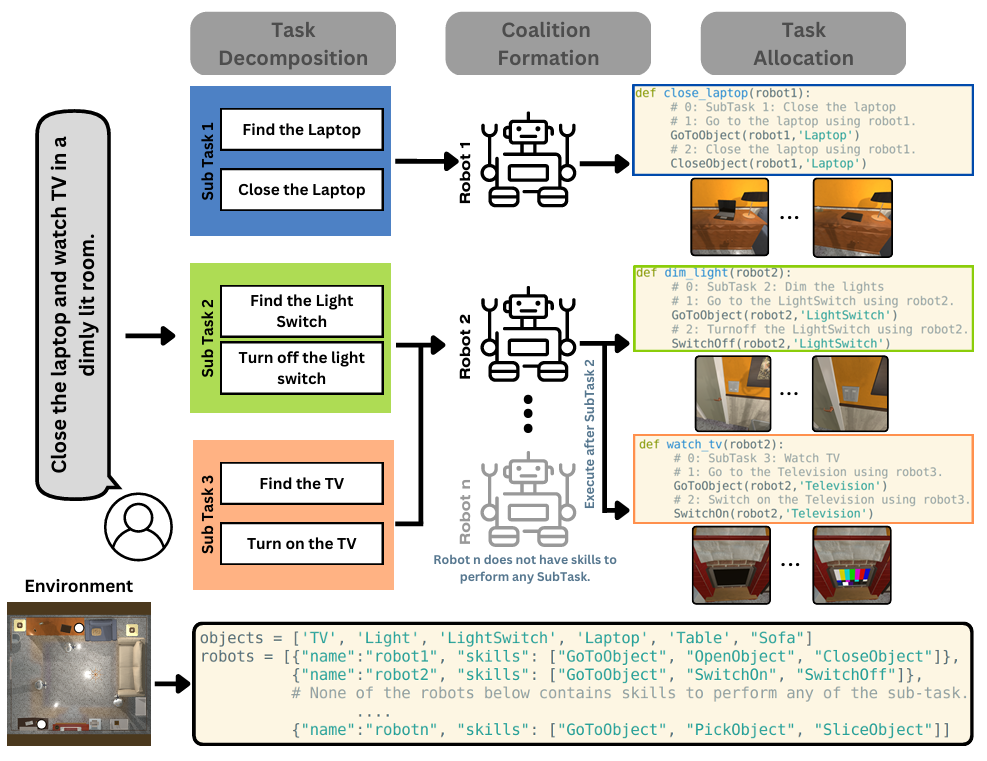
▲图例:SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models
SMART-LLM框架通过以下步骤实现多智能体之间的协作:
Step1:解析全局目标(如“整理房间”),分解为“移动椅子、清扫地面、摆放物品”等子任务;
Step2:根据每个智能体的能力(如机械臂擅长抓取,移动机器人擅长运输)进行子任务分配;
Step3:生成时序约束(如“先移开椅子再清扫”)。

-
NeurIPS 2024:首个聚焦无障碍的具身社会智能基准
它模拟了辅助机器人与行动受限人类(如轮椅使用者、儿童)之间的相互协作。
创新构建 4 类含真实物理约束的智能体,与 8 个覆盖室内外、含紧急事件的长时协作任务,核心测试智能体从第一视角视觉观测中推断人类意图与约束的社交感知能力,及定制化协作规划能力。
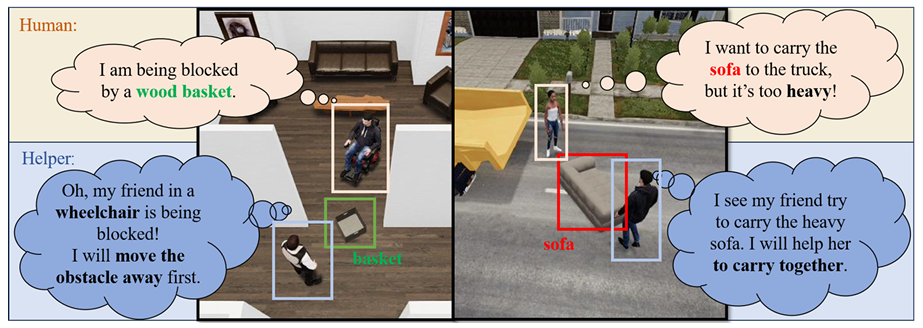
▲Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge人机交互测试效果
小结
大模型为多智能体系统带来了显著的语义理解与全局规划能力,尤其在任务拆解、人机协作、场景泛化等方面展现出独特优势。
然而,这类方法也暴露出一致性难题:响应延迟、实时控制能力弱、对预定义符号体系(如PDDL)的依赖等。

当我们在审视2025年多智能体领域这两条并行演进的技术路线时,会发现:
虽然表面上是“分布式涌现”与“集中式规划”间的“竞争与合作(“大模型规划 + 强化学习执行”的范式)”,但其底层逻辑仍未跳出传统控制与优化理论的范畴——
本质上还是预设架构下的效率竞赛。
我们是否在用解决“单体智能”的思维惯性,来应对真正意义上的“群体智能”挑战?
这也指向一个更根本的转向:从“智能体的群体”(a group of agents)到“群体的智能体”(an agent of group)。
前者是工程组合思维,后者是系统涌现思维。
我们精于在预设的架构中“优化”群体,却尚未学会在开放的环境中“定义”那个能作为整体行动的智能体……


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









