



2025世界机器人大会在北京经济技术开发区北人亦创国际会展中心盛大召开。此次大会以“让机器人更智慧,让具身体更智能”为主题,吸引了200余家国内外优秀机器人企业,携1500余件展品亮相,其中首发新品超100款。在这场科技盛宴中,银河通用的Galbot机器人表现非常优秀,凭借GroceryVLA大模型的支持,在1:1还原的真实商超场景下自主完成了从接收指令到移动到目标商品,再抓取商品后送到顾客手中的整个过程。全程无需远程遥控,不依赖于事先采集的场景数据,充分展现出在复杂零售场景下,“视觉感知-语言理解-导航+操作” 的全链路协同能力。

▲说明:现场用户向Galbot发出指令后,Galbot取回商品给用户

在复杂的商超场景中,机器人要准确执行任务,精准的视觉环境感知是基础。因为只有机器人能识别到目标商品,才能为后续的动作决策提供准确的依据。
多模态大模型的感知
在机器人视觉感知中,单纯依靠视觉特征可能存在模糊性(例如:有些商品包装雷同),难以准确识别出目标商品。因此需要结合其他的模态特征来加以区分。
CLIP是目前主流且经典的多模态感知大模型,它通过大规模图像-文本对的对比学习,建立了视觉和语言之间的语义关联,为视觉感知注入了丰富的语义信息。在商超场景下,将视觉上的商品特征与文本标签对应起来(例如将红色罐装且带有特定图案的视觉特征与 “可口可乐易拉罐” 的文本标签对应上),可以帮助机器人准确识别出歧义商品。在一些结合CLIP的具身智能项目中,(1)、CoW(CLIP on Wheels)[1],利用CLIP进行目标定位和经典探索策略结合进行零样本视觉语言对象导航,在HABITAT MP3D上的导航效率(SPL)与训练5亿步的SemanticNav-ZSON相当,在ROBOTHOR子集上的成功率显著优于EmbCLIP-ZSON(提升了15.6%)(2)、Robotic-CLIP[2]在Alpha-CLIP上进行了改进,因此Robotic-CLIP能更准确的识别感知,例如在Grasp-Anything数据集上,Robotic-CLIP抓取检测的IoU达0.51,相较于CLIP提升了5%,显著减少了误识别情况,并且在CARLA模拟器上测试,导航成功率达86%,高出基于CLIP基线的9%,抓取成功率提升了12%。

▲说明:让CoW机器人去找位于桌子上的姜饼屋

自然语言指令解析对于机器人理解人类意图至关重要。由于人们下达的指令往往都是模糊、口语化的,因此,该算法需要准确的将这些自然语言转化为机器人可理解并执行的任务指令,让机器人明白用户的真实需求,才能为后续的动作决策提供准确的依据。
基于大模型的指令解析
LLaMA是一款强大的大语言模型。只需要构建大规模零售领域指令的数据集,让LLaMA学习不同指令与商品类别、位置等信息的映射关系。然后结合LoRA技术进行微aMA调,大幅减低微调成本和显存占用,微调后的LLaMA模型就可以高度适配零售领域,从而精准把握用户需求(例如:“帮我找一下放在角落里的打折洗发水”,目标位置->角落,目标商品->洗发水,特点:打折商品)。在一些结合LLaMA的具身智能项目中,ManipLLM[3]采用LLaMa-Adapter作为BackBone,CLIP作为视觉编码器,通过微调CLIP-Adapter和LLaMa-Adapter并冻结CLIP、LLaMa的主要参数,最后得到一个只需要一张图片和一条指令就可以推理出操作任务的具身模型,在真实环境下测试,操作成功率高达80%。

▲说明:ManipLLM让机械臂打开抽屉

如何让机器人导航目标商品前?其关键技术点在于:首先要让机器人知道自己在哪里(定位+建图,定位往往需要伴随者建图的,定位的本质是确定“自身在环境中的位置”,而地图则是定义“环境坐标系统”的基准);然后要让机器人知道要去哪里(路径规划)、最后还要告诉机器人怎么去(轨迹追踪/运动控制规划)
环境构建与定位
要让机器人能够导航,一般需要构建环境地图,这种地图大致分为2种:一种是事先构建好的先验地图(例如OpenBench[4]使用OSM提供先验地图,然后使用MobileSAM对地图进行分割后,使用CLIP模型进行标签分类,从而形成语义信息,然后叠加上激光雷达数据,形成语义地图,当定位时,将激光数据和语义地图进行scan match,从而得到定位信息)、另一种是过程中构建地图,例如对于未知区域的机器人探索导航问题,一般会实时构建frontier地图,驱使规划器尽可能的朝着frontier的方向进行路径规划,以便促使机器人朝着未知区域进行移动,从而达到探索未知区域的目的,当所有frontier消耗殆尽,则说明所有区域都已经完成探索。(例如1、Mem2Ego[5]通过从全局记忆模块中自适应检索与任务相关的线索,然后将这些线索映射到智能体的自我视角中进行观察,通过将全局上下文信息与输入的局部感知信息相结合,使智能体做出明智的行动决策;2、MTU3D[6]是一个将主动感知与三维视觉-语言学习相结合的统一具身导航框架,通过将未探索区域表示为frontier地图查询以及对物体定位与frontier选择的联合优化问题来实现定位与探索的统一)
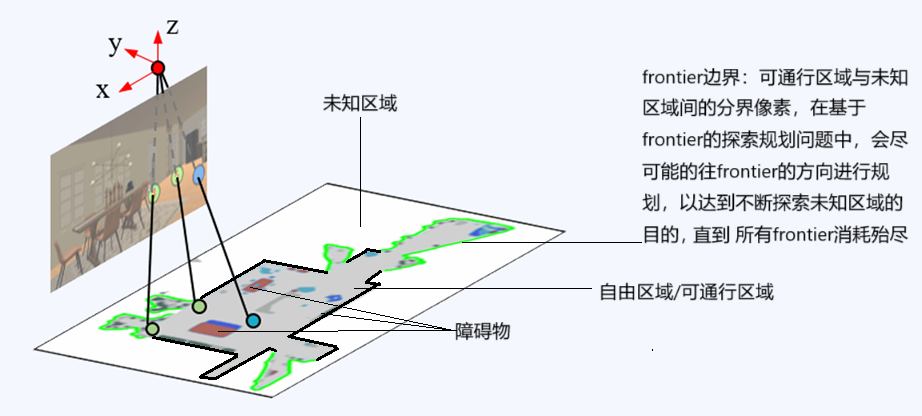
▲说明:以此图来说明展示frontier©️【深蓝具身智能】编译
路径规划与轨迹追踪/运动控制规划
当有了导航地图,机器人也能实时获取自身在地图中的位姿后,这时只需要解析用户的指令,得到目标位置的方位(例如:“帮我找一下放在角落里的打折洗发水”,目标商品->洗发水,结合语义地图信息,可以获取到洗发水区货架的坐标位置),然后结合路径规划算法生成轨迹路径(由于场景并不复杂,因此一般传统的方法即可,如探索类如A*、D*,采样算法如RRT,优化算法如MPC等都可以),最后机器人不断追踪轨迹移动并实时调整(可以结合PID或MPC等控制方法进行实现)。例如在【环境构建与定位】种提到的方案OpenBench[4],导航模式下使用多级Dijkstra(MLD)算法进行路径规划,MLD通过利用分层图减少搜索空间,从而能够快速确定最优路径,探索模式下,将OSM转换为代价地图以便进行A*路径搜索,随后使用TEB进行轨迹跟踪。

当机器人到达目标位置,此时目标商品在机械臂抓取范围内时该如何控制机械臂正确抓取目标商品呢?在前面2个小节中,可以得到视觉特征和用户指令tokens,将它们嵌入融合后输入到多模态大模型内,从而理解用户的意图进行决策,然后交由动作推理模型生成低级别动作指令,从而完成机器人操作任务。
动作推理
动作推理环节是整个机器人操作任务实现的关键执行步骤,其核心在于依据多模态大模型对用户意图理解后的决策结果,生成精确、可行的低级别动作指令,从而驱动机械臂完成对目标商品的抓取。
在这一过程中,首先是输入融合阶段。视觉特征经过前期的视觉处理模块,包含了目标商品的位置、形状、颜色等关键信息,这些信息以特征向量的形式呈现。用户指令 tokens则通过自然语言处理模块转化为计算机可理解的语义表示。随后,将视觉特征向量与指令语义表示进行嵌入融合,形成一个统一的多模态输入向量。这种融合并非简单拼接,而是通过特定的融合算法,使得视觉与语言信息能够相互补充、协同,为后续的模型处理提供更全面、丰富的信息基础 。接着,将融合后的输入向量送入多模态大模型。多模态大模型内部基于Transformer架构等先进技术,通过自注意力机制等运算,对输入信息进行深度处理。模型在大规模数据训练中学习到了丰富的 “指令-视觉场景-动作决策” 映射关系。此时,面对当前融合输入,模型会进行复杂的推理运算,理解用户指令在当前视觉场景下的具体意图,比如用户说 “抓取那个红色瓶子”,模型要结合视觉场景中红色瓶子的位置、姿态等信息,判断出抓取动作的大致策略,是从上方抓取、侧面抓取,还是需要先调整角度再抓取等。最后,基于多模态大模型的决策结果,动作推理模型开始发挥作用。
动作推理模型可以选择Diffusion Policy,它通过概率扩散过程生成动作序列,能天然建模不确定性,提升复杂场景鲁棒性,Diffusion Policy在长时序抓取动作规划中表现出了优异的泛化性与数据效率。譬如,DexGraspVLA[7]将一个指令分成多个阶段的任务,对于每个阶段的任务,将多模态数据(用户提示、头部摄像头观测图像)输入到多模态大模型中,得到目标物体的边界框,然后由Diffusion Policy预测出多步动作序列,然后采用滚动时域控制策略,即在生成新的动作块预测之前,仅执行前个动作,以提高实时响应能力。该方案在 “零样本” 环境下,面对数千种不同的物体、光照和背景组合,灵巧抓取的成功率高达90%以上。

▲说明:DexGraspVLA效果展示
也可以选择结合LAM(Latent Action Model),学习商超场景下抓取商品的视角的特定任务通用策略,在结合低成本的动作解码器,轻松部署到各种机器人上。其优势是通过“潜在动作”作为桥梁,实现跨场景、跨智能体的动作迁移,譬如:UniVLA[8]和智元的ViLLA[9]都采用了LAM,通过这种形式将连续图像投影到隐式动作空间,使隐式动作作为中间过程表征,从而弥合图像、文本输入到机器人动作之间的差距。

尽管上述模块中的各种算法在推动机器人VLA发展上取得了一定成果,但仍存在诸多亟待解决的问题。例如:在数据方面,存在数据量级和多样性不足的问题,训练 VLA模型的数据与纯语言模型相比差距较大,且多来自简单环境,难以覆盖复杂真实场景,限制了模型环境的适应能力。因此,要让机器人VLA走向成熟,充分释放具身智能潜力,学术界和工业界任需在这些关键问题上持续探索突破。
【引文】
[1] CoWson PASTURE: Baselines and Benchmarks for Language-Driven Zero-Shot Object Navigation,https://arxiv.org/pdf/2203.10421
[2] Robotic-CLIP: Fine-tuning CLIP on Action Data for Robotic Applications, https://arxiv.org/pdf/2409.17727v1
[3] ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation,https://arxiv.org/pdf/2312.16217
[4] OpenBench: A New Benchmark and Baseline for Semantic Navigation in Smart Logistics,https://arxiv.org/pdf/2502.09238
[5]MEM2EGO:EMPOWERING VISION-LANGUAGE MODELS WITH
GLOBAL-TO-EGO MEMORY FOR LONG HORIZON EMBODIED NAVIGATION,https://arxiv.org/pdf/2502.14254
[6]Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation,https://www.arxiv.org/pdf/2507.04047
[7]DexGraspVLA: A Vision-Language-Action Framework Towards General Dexterous Grasping,https://arxiv.org/pdf/2502.20900
[8]Learning to Act Anywhere with Task-centric Latent Actions,
https://arxiv.org/pdf/2505.06111
[9]AgiBot World Colosseo: Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems,https://agibot-world.com/blog/agibot_go1.pdf


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









