



摘要
在具身智能和机器人自主导航研究中,如何让机器人理解语言并据此做出连续、自然的运动,一直是一个难题。尤其在开放环境中,面对从未见过的目标和场景,大多数方法仍局限于离散动作、受限传感器和特定任务。这篇 CVPR 2025 论文提出了 VLFly——一个完全基于视觉输入的飞行导航系统。不同于传统方法,VLFly 不依赖 GPS、深度传感器或动作模板,仅凭单目摄像头和语言提示,就能控制无人机连续飞行、完成导航任务。
©️【深蓝AI】编译
它整合了三大能力:用大语言模型理解指令,用视觉语言模型识别目标,再通过路径规划器输出实时控制指令。更令人惊讶的是,这一方法无需在特定场景下微调,就能直接在仿真和真实环境中完成多种导航任务,表现全面优于现有基线。VLFly 展现了一种全新的视角:如何在缺乏精确地图与定位的情况下,仅通过视觉和语言实现智能决策。这不仅对机器人系统有重要启示,也为具身智能的实际部署打开了新通路。

在机器人与人工智能(AI)领域,实现机器人根据自然语言指令执行复杂任务的能力,长期以来都是一个具有吸引力的研究目标。尤其在自主导航领域,这一能力可广泛应用于家庭助理、城市巡检和环境探索等场景。在这些任务中,机器人需要识别出属于特定类别的目标物体,并基于语言指令和视觉观察结果高效地导航至目标,这一挑战通常被称为“视觉-语言导航”(Vision-Language Navigation,简称 VLN)。
例如,当用户说“找到一个粉色玩具”时,机器人应当根据环境中的视觉线索有目的地进行搜索,而不是盲目遍历整个空间。为了胜任这类任务,一个合格的 VLN 系统应具备以下三项能力:(1)能在像素级别理解视觉与语言特征;(2)能将融合后的视觉-语言信息精确映射为可在环境中执行的导航动作;(3)能在非结构化或从未见过的环境中保持稳健的泛化能力。
然而,现有的 VLN 系统尚未完全实现上述能力,尤其是在应用于真实环境中飞行的无人机(UAV)时。当前的自主导航研究主要可分为三类:传统方法、端到端学习方法以及模块化学习方法。传统方法(如SLAM和SfM)擅长基于像素级别特征提取进行几何重建,虽能完成低层次导航任务,但缺乏对语言的理解能力。端到端学习方法(如模仿学习或强化学习)可实现从图像到动作的直接映射,但在数据需求、训练效率及从仿真到现实的泛化能力方面仍面临巨大挑战。模块化方法试图融合两者优势,通过将传统导航流程中的关键模块替换为可学习的网络结构,以实现更好的可解释性与泛化能力,但仍依赖大量真实数据,且容易出现模块误差积累,缺乏人类式的推理能力。
近期,大型语言模型(LLM)与视觉语言模型(VLM)的发展为自主导航提供了新的可能。这些模型既可嵌入端到端框架中,以更高效地从图像中提取语义特征并用于导航训练,也可服务于模块化框架,用于构建语义地图,辅助人类语义引导下的探索。
然而,目前大多数 VLN 研究仍集中于地面机器人,且默认离散动作空间,与 UAV 在真实环境中所需的连续动作控制存在显著差异。此外,飞行过程中的视角遮挡与不稳定视觉输入也加剧了空地差异,限制了地面 VLN 方法向 UAV 场景的迁移能力。
为解决上述问题,本文提出VLFly,一个专为 UAV 设计的新型 VLN 框架,具备开放词汇目标理解与室内外场景的零样本泛化能力。
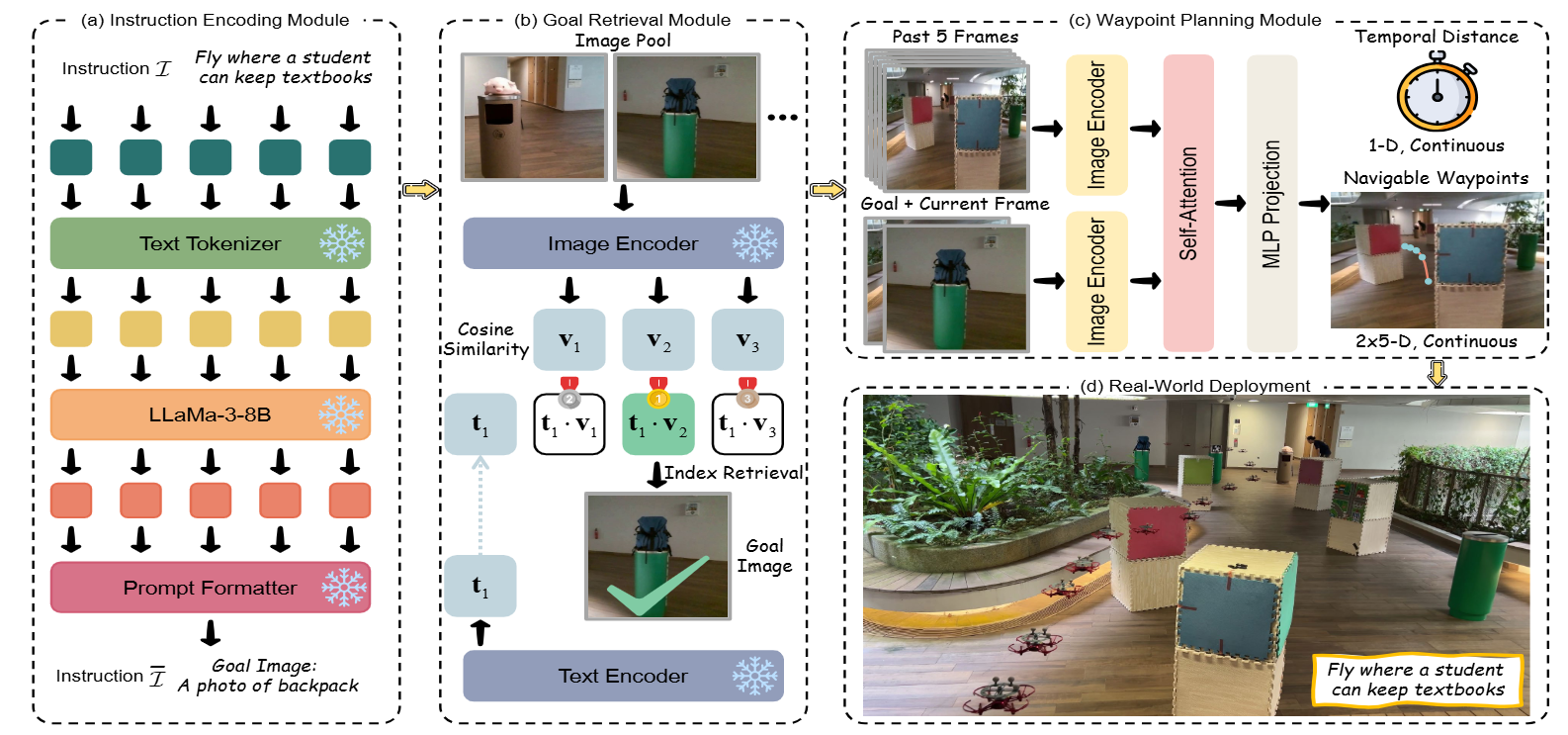
图1|全文方法总览

如图1所示,VLFly 框架包含三个主要模块:指令编码模块、目标检索模块和航点规划模块。
● 指令编码模块:接收自然语言描述,借助大语言模型 LLaMA 将其转化为结构化的视觉目标提示(prompt),以统一格式表达目标语义。
● 目标检索模块:利用 CLIP 模型在图文嵌入空间中比对结构化提示与预先采集的候选图像池,通过相似度检索确定目标图像。
● 航点规划模块:将目标图像与当前观测帧结合,生成引导 UAV 飞向目标的连续航点,并转化为可执行的速度指令。
尽管这三个模块在功能上是分离的,但在推理时整个系统是端到端运行的,从视觉观测直接输出动作命令。该设计实现了结构清晰又高效可部署的视觉-语言导航能力。
指令编码模块
该模块将高层的自然语言任务描述转化为适用于目标图像检索的结构化提示。首先,对自然语言指令进行分词和标号编码。然后通过 LLaMA 生成与视觉目标语义一致的统一提示,提升图文嵌入的对齐能力。这一提示将在后续模块中用于匹配目标图像。
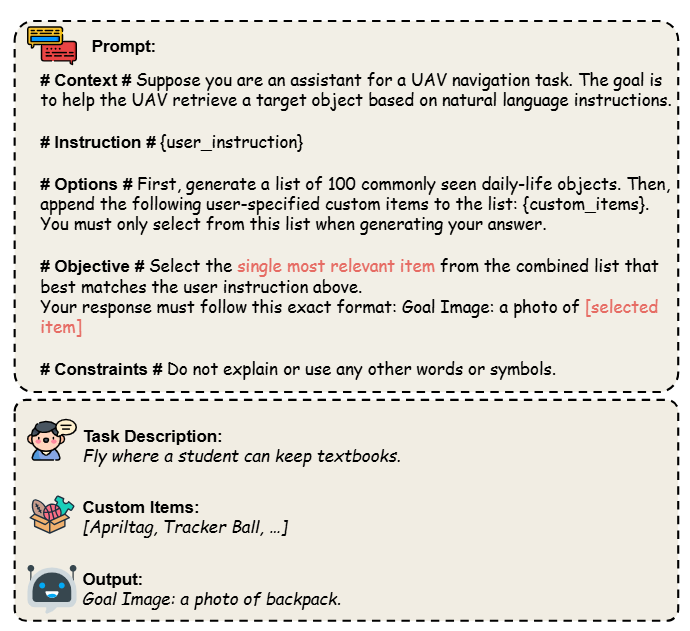
图2|指令编码模块中采用了一种提示词生成策略。该策略会将自然语言指令与一组自定义物品列表输入给语言模型,从而生成一种标准化格式的提示语,这种格式化提示有助于实现目标的统一检索
目标检索模块
在该模块中,结构化提示被送入文本编码器,候选图像被送入图像编码器,二者被投影到共享嵌入空间。通过计算点积相似度,并经过 softmax 转换为概率分布,系统从中选择最匹配的目标图像用于后续导航
航点规划模块
该模块接收当前和过去若干时刻的第一人称 RGB 图像序列,以及已确定的目标图像。它输出两个关键结果:(1)预计达到目标所需的步数;(2)未来多个时间步的相对航点轨迹,每个航点表示在 UAV 视角下的相对位移。
为实现这一过程:
● 首先对每帧图像进行特征编码;
● 然后将当前帧与目标图像拼接,输入专用的融合编码器,生成“目标引导差异特征”;
● 所有特征加上位置编码后送入 Transformer 解码器;
● 最终使用 MLP 输出航点轨迹。
该模块针对无人机视角的特殊性进行了设计,尤其考虑到航拍图像的视角变化大、场景复杂,确保了规划模块的泛化与鲁棒性
动作执行模块
给定由航点规划模块生成的连续轨迹(已归一化),本文设计了一个简单的 PID 控制器,将这些相对位移转换为可执行的线速度和角速度指令。该控制逻辑直接驱动无人机在真实环境中执行航点动作,整个系统可实现实时控制

在图3所示的模拟实验中,作者构建了三个不同复杂度的环境(箱子环境、家具环境与障碍物环境)来全面评估VLFly的泛化能力与导航性能。在所有环境中,VLFly始终基于单目RGB图像进行输入,并不依赖任何激光雷达或GPS定位系统。
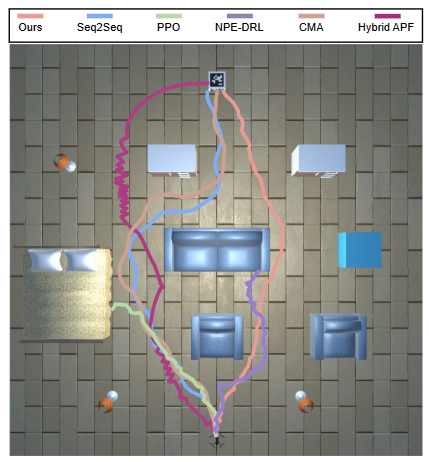
图3|模拟实验轨迹规划结果
如图4所示,VLFly在各项指标中均优于多个基线方法。其中,在中等难度的家具场景中,VLFly的成功率(SR)为82.5%,路径加权成功率(SPL)为0.79;在高难度障碍场景中,仍保持77.3%的成功率和0.75的SPL。这表明VLFly具备稳定的目标导航能力和路径规划能力,即使在复杂场景中也能有效避障并到达目标位置。

图4|多场景数值实验结果
相较之下,传统强化学习方法(如PPO和NPE-DRL)虽然在训练环境中表现良好,但在陌生场景中普遍表现较差,反映出它们对环境变化的适应性较弱。经典规划方法如Hybrid-APF在简单环境中尚有一定效果,但容易陷入局部最优,导致复杂环境下表现严重下降。
在图5所示的现实环境测试中,VLFly被部署于一个具备实际干扰的无人机平台(Tello Edu),系统仅基于机载RGB相机图像执行连续控制命令。在没有任何外部定位(如OptiTrack)或测距传感器辅助的条件下,VLFly需完成基于自然语言指令的导航任务。
实验设计包括两类指令:直接指令(如“飞到蓝色背包旁”)和间接指令(如“飞到可以放课本的地方”)。在室内和室外环境中分别进行20次测试,结果显示VLFly在直接指令下成功率达83%,在间接指令下为70%。尽管间接指令具有语义歧义,系统仍展现出较强的语言理解与语义推理能力。
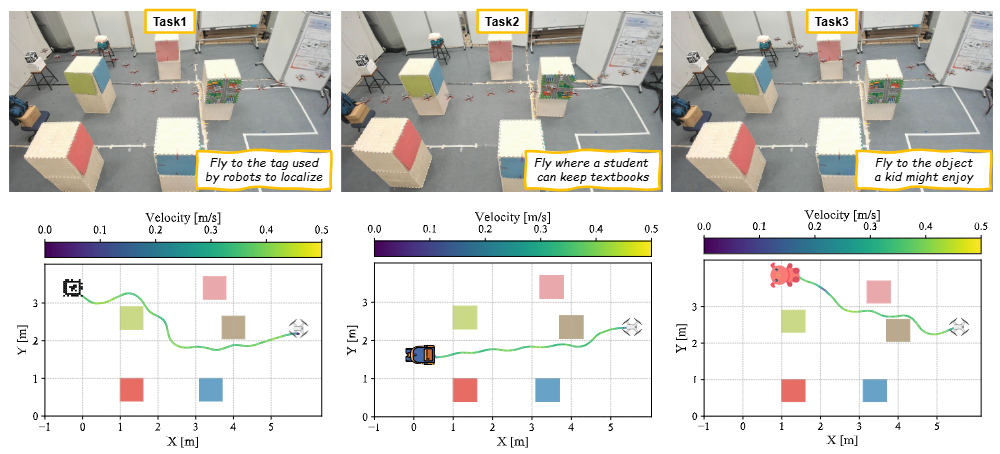

图5|真实实验可视化结果(涵盖室内及室外)

图6|消融实验结果
为验证 VLFly 各模块的实际贡献,作者设计了三种变体模型并在模拟环境中进行消融实验(图6),尤其聚焦于间接语言指令条件下的表现。这三种变体分别是:
1. w/o Prompting(无提示词生成):移除了指令编码模块,直接将原始语言指令输入至目标检索模块,不再生成结构化提示词。
2. w/ Unified VLM(统一视觉语言模型):同时替换了指令编码和目标检索模块,使用统一的视觉语言模型(如 BLIP)进行端到端匹配。
3. w/ RL Policy(使用强化学习策略):用强化学习策略网络取代路径规划模块,直接从当前图像与目标图像输出动作指令,而不再生成中间路径点。
结果分析如下:
● 在所有指标上,这些变体的性能都有明显下降,尤其在处理间接指令时,差距更为显著。
● w/o Prompting 表现不佳的主要原因在于其移除了自然语言到结构化提示词的转化环节,导致系统在语义推理能力上严重受限。该模型只能识别固定文本模板(如“a photo of...”)类型的指令,而无法理解更抽象的语义内容。
● w/ Unified VLM 虽使用了当前先进的大模型(如 BLIP),但仍无法应对非结构化输入。这类模型在视觉问答等任务中表现优秀,但由于缺乏对提示结构的精细控制,其输出往往模糊不清,难以用于精确的语义匹配。此外,其需要对图像池进行逐一推理,导致推理延迟过高,不适合用于实际部署。
● w/ RL Policy 虽然在目标识别方面尚可,但在未见环境中的表现大幅下降。这是因为策略网络容易过拟合训练路径,对于环境变化的适应性较差,缺乏有效的避障和泛化能力。

本文提出了一个专为无人机(UAV)设计的视觉语言导航框架——VLFly。该系统无需外部定位系统或主动测距传感器,仅通过机载单目相机获取的自我视角图像,就能完成导航任务。与传统VLN方法使用离散动作集不同,VLFly输出的是连续控制指令,更适合无人机的运动模式。
整个框架由三个模块组成:一个将自然语言指令转化为结构化提示词的指令编码器,一个通过视觉-语言相似性选择最匹配目标图像的检索器,以及一个根据自我视角图像生成轨迹的路径规划器。大量仿真实验表明,VLFly在多个环境中表现出色,明显优于各类基线方法。此外,真实环境下的室内外飞行测试也表明,该方法在面对直接或间接指令时,均展现出良好的开放词汇理解能力和泛化导航能力,验证了其实用性。
论文出处:arXiv
论文标题:Grounded Vision-Language Navigation for UAVs with Open-Vocabulary Goal Understanding
论文作者:Yuhang Zhang, Haosheng Yu, Jiaping Xiao, Mir Feroskhan

















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









