



引言
在人工智能的快速发展中,LLMs已成为构建具身决策制定代理的强大工具。这些代理不仅需要理解自然语言指令,还需在数字和物理环境中通过一系列动作实现指定目标。尽管LLMs在决策制定中的潜力巨大,但我们对其在具身环境中的全面能力和局限性的理解仍然有限。现有的评估方法由于缺乏标准化的任务、模块和细粒度评估指标,往往无法提供深入的洞察。近日,由斯坦福大学吴家俊团队提出的EMBODIED AGENT INTERFACE(EAI)框架,这项工作被NIPS 2024接收为oral。该框架专注于评估LLMs在具身决策制定中的表现,旨在通过标准化的方法全面评估LLMs的性能。
论文题目:Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
论文作者:Manling Li , Shiyu Zhao , Qineng Wang, et al.
1 具身决策制定的挑战
在具身决策制定(Embodied Decision Making)领域,具身代理不仅要精准理解自然语言指令,更需在纷繁复杂的环境中,通过物理动作将这些指令一一实现。这一过程极具挑战。
1.1 自然语言到物理世界的映射
具身代理面临的首要考验,便是如何将抽象的语言指令转化为具体的物理行动。例如,“准备晚餐”这一简单指令,实则蕴含了切菜、烹饪等一系列繁琐步骤。LLMs需具备解读这些指令并将其拆解为可执行动作序列的能力。
1.2 环境交互与状态变化
具身代理需洞察并预测其动作对环境状态的微妙影响。这要求LLMs具备卓越的环境建模能力,能够实时追踪并推理物体的状态变化,如“杯子已满”或“门已敞开”。
1.3 复杂推理与规划
在动态环境中,具身代理需展现出非凡的推理与规划能力。这不仅涵盖简单的动作序列生成,更需应对突发状况、规划多步骤任务及实现长期目标。
1.4 常识性知识和物理约束
LLMs需掌握一定的常识性知识,以执行那些虽未明确提及但至关重要的动作。例如,喝水前需先拧开瓶盖,这便是常识的体现。
2 EMBODIED AGENT INTERFACE 框架解读
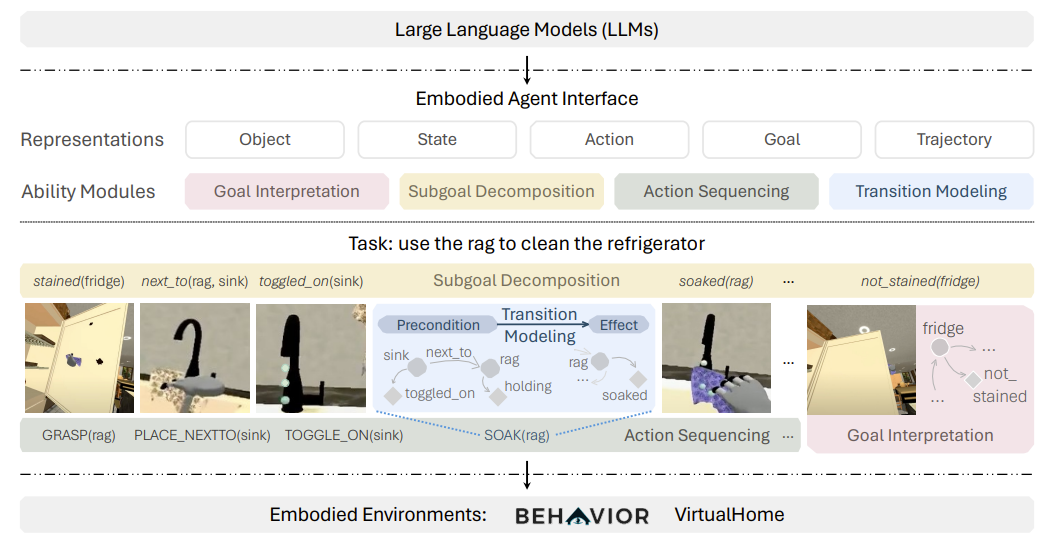
图 1| 具身代理界面统一了涉及状态和时间扩展目标的一系列任务,以及四个基于 LLM 的决策模块
2.1目标阐释
目标阐释模块,如同一位翻译家,将自然语言描述的目标转化为可执行的符号化目标。它巧妙地将自然语言指令转化为预定义的状态与动作组合。
-
自然语言目标(Natural Language Goal):lg
-
符号化目标(Symbolic Goal):g
例如,指令“清洁冰箱”可转化为符号化目标,表示为一系列动作与状态变化的集合,如 g={clean(fridge)}。
2.2 目标拆解
子目标拆解模块,则像一位策略家,将复杂目标分解为一系列中间状态(子目标),这些子目标是通往最终目标的必经之路。
-
初始状态(Initial State):s0
-
子目标序列(Subgoal Sequence):ϕ={ϕ1,ϕ2,...,ϕn}
例如,实现“准备咖啡”的目标,可能需要拆解为子目标序列 ϕ={研磨咖啡,冲泡咖啡}。
2.3 动作排序
动作排序模块,犹如一位指挥家,负责编排一系列动作,以实现从初始状态到目标状态的华丽蜕变。
-
动作序列(Action Sequence):aˉ={a1,a2,...,an}
例如,实现子目标“研磨咖啡”的动作序列,可能是 aˉ={取研磨机,研磨咖啡豆}。
2.4 转换建模
转换建模模块,则像一位预言家,预测每个动作如何改变环境状态,包括动作的前置条件与效果。
-
前置条件(Preconditions):Pre(a)
-
效果(Effects):Eff(a)
例如,动作“研磨咖啡豆”的前置条件可能是 Pre(研磨咖啡豆)={拥有咖啡豆,拥有研磨机},效果则是 Eff(研磨咖啡豆)={咖啡豆已研磨}。
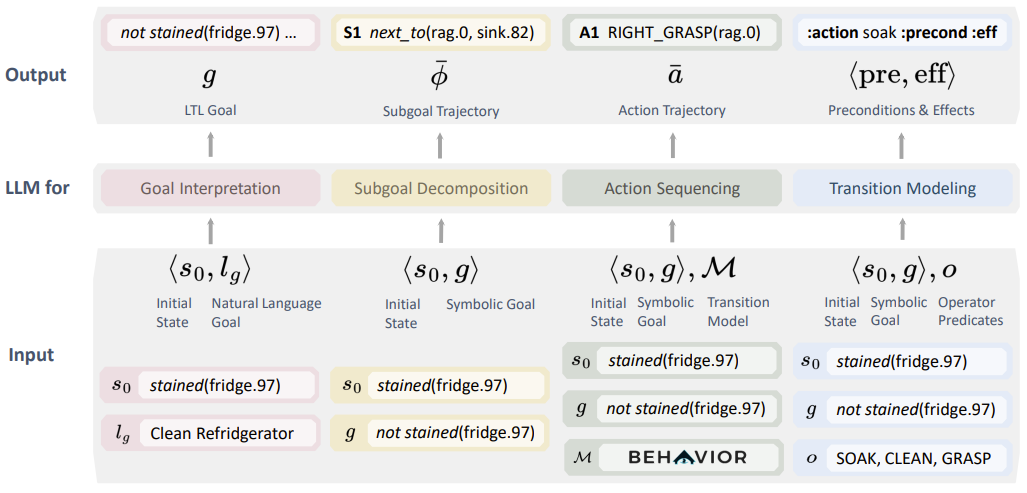
图 2| 具身界面四个能力模块的输入和输出表述
3 实验结果与深度剖析
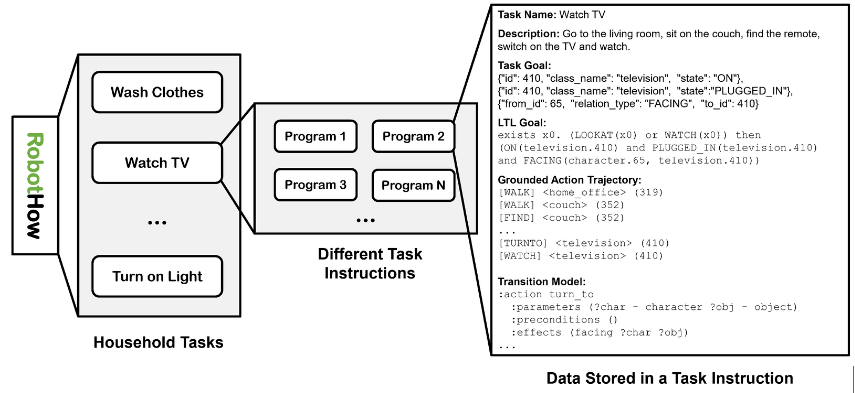
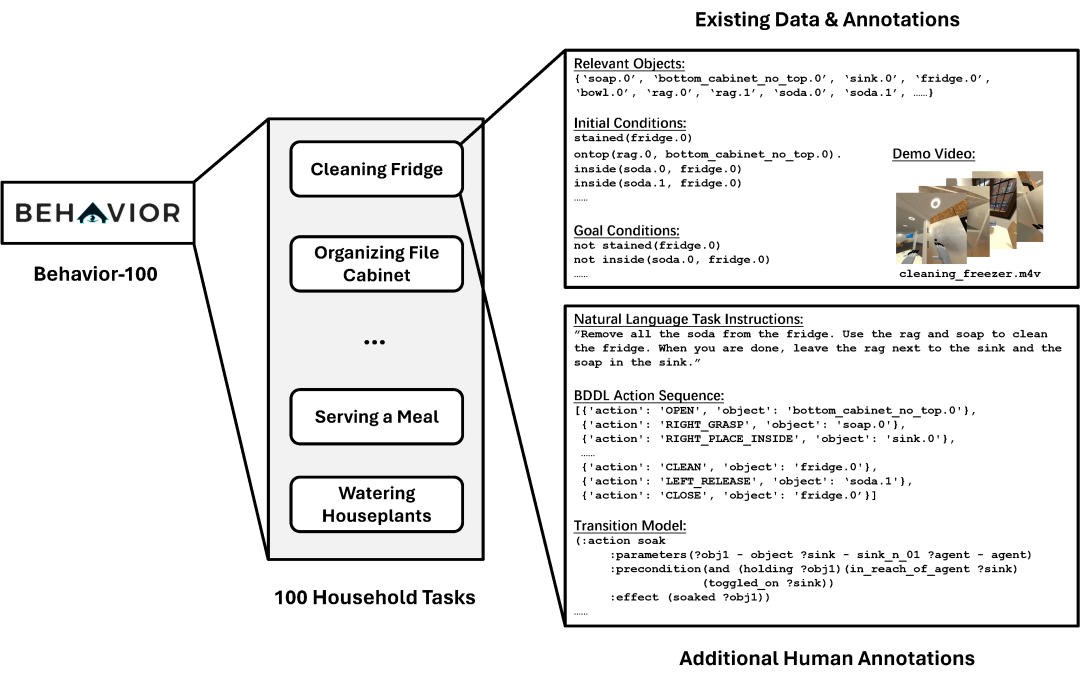
图3| 根据任务长度和场景复杂度,选择 VirtualHome (V) 和 BEHAVIOR (B) 作为评估模拟器
通过一系列实验,研究人员深入剖析了LLMs在具身决策制定中的表现。以下是对实验结果的深度解读。
3.1 目标阐释
-
多数LLMs难以准确将自然语言指令映射至环境中的具体状态,包括物体、物体状态及关系。
-
常见错误包括将中间子目标错误地预测为最终目标的一部分,如在“喝水”任务中误判“冰箱打开”的状态。
这表明LLMs在理解自然语言指令的具体含义,并将其转化为具体环境操作方面存在显著挑战。LLMs往往过于依赖自然语言指令中的词汇,直接将其转化为符号表示,而忽略了指令在实际环境中的执行逻辑。
3.2 子目标拆解与动作排序
-
在推理能力上仍有待提升,轨迹可行性错误频发(45.2%),其中包括遗漏步骤(19.5%)和额外步骤(14.2%)的错误。
-
这些错误通常源于对动作前置条件的忽视,例如,LLMs可能会忽略代理的坐姿或躺姿状态,未在执行其他动作前包含站立动作。
轨迹可行性错误凸显了LLMs在规划动作序列时的不足,特别是在理解和预测动作的物理前置条件方面。额外步骤错误则表明LLMs在判断何时已达到目标并停止执行动作方面存在困难,这可能与模型对环境状态的跟踪与理解能力有关。
3.3 转换建模
-
LLMs在预测动作的前置条件和效果方面表现出显著差异,这直接影响了规划的可行性。
-
非空间关系类别的任务普遍较难,揭示出LLMs在理解复杂关系动态方面的挑战。
转换建模的性能差异反映了不同LLMs在理解和预测动作对环境状态影响能力上的差异。非空间关系任务的低分表明LLMs在处理涉及复杂逻辑和关系的动作时存在困难,这可能与模型对这类任务的训练和理解不足密切相关。
3.4 性能变化与环境复杂性
-
随着轨迹序列长度的增加,轨迹评估性能显著下降;当环境变得更加复杂,涉及更多种类的物体和状态特征时,目标评估性能同样下降。
这一结果表明LLMs在处理长序列和复杂环境时的性能存在局限性,这可能与模型的内存和注意力机制有关,这些机制限制了模型处理长序列和复杂状态变化的能力。
3.5 错误类型分析
-
LLMs的错误不仅包括对不存在的物体和动作的幻觉,还包括忽视了语言中省略的常识性前置条件。
这一发现强调了LLMs在理解和应用常识性知识方面的不足,这些知识对于成功执行任务至关重要。例如,将“把火鸡放在桌子上”理解为“把火鸡放在盘子上,然后把盘子放在桌子上”,需要对日常物品的使用和空间关系有深入的理解。
4 敏感性分析的关键作用
敏感性分析在评估LLMs性能中扮演着举足轻重的角色,它如同一位洞察秋毫的分析师,帮助研究人员深刻理解模型预测中每个动作对整体任务成功率的具体影响。通过这种方法,研究人员能够精准识别出哪些动作是任务成功的关键所在,以及LLMs在预测这些动作时的准确性如何。
实验过程:
-
在敏感性分析中,研究人员首先将LLMs预测的动作替换为真实动作(ground truth),然后使用PDDL规划器检查是否存在可行的解决方案。
-
接着,研究人员逐一替换每个动作,评估替换后对任务成功率的影响。若替换某个动作后,规划器无法找到解决方案,则认为任务对该动作高度敏感。
关键发现:
-
分析显示,某些动作(如“插电”和“走向”)的预测准确性对任务成功至关重要。这些动作因其复杂性和空间要求较高,LLMs在理解和预测时面临严峻挑战。
-
敏感性分析揭示了LLMs在不同任务类别中的性能差异,指出了模型在特定动作预测上的薄弱环节,为未来的模型改进和训练提供了宝贵方向。
5 LLMs的性能比较
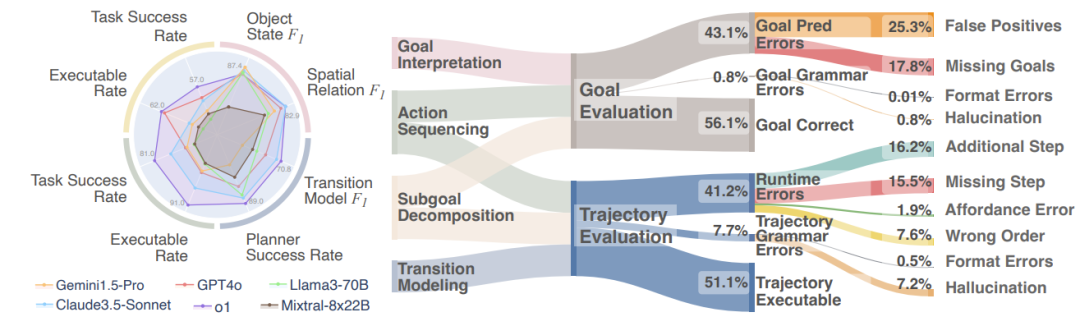
图4| EAI支持一系列细粒度度量标准,并提供自动工具包,用于误差分析和对不同 LLM 在各种具身决策任务中的表现进行基准测试
-
在BEHAVIOR和VirtualHome两个模拟器上,o1-preview模型在多个任务上表现突出,特别是在BEHAVIOR模拟器上,其任务成功率(74.9%)显著高于其他模型(平均64.2%)。
-
Claude-3.5 Sonnet在BEHAVIOR上的目标解释和VirtualHome上的转换建模表现出色,而Mistral Large在VirtualHome上的动作排序任务中表现良好。
这些性能差异可能源于不同模型的训练数据、架构设计和优化策略。o1-preview的优异表现可能与其在处理复杂任务和环境交互时的高级推理能力有关。性能比较还揭示了不同模型在处理特定类型任务时的专长,例如,一些模型在理解空间关系方面表现更好,而其他模型可能在处理非空间关系任务时更为出色。
6 结论与未来方向
6.1 结论
-
LLMs在具身决策制定中展现出潜力,但在理解复杂目标、推理和规划方面存在显著挑战。
-
通过EAI框架的评估,研究人员能够识别LLMs在不同任务中的具体弱点,为改进模型提供了实证基础。
6.2 未来方向
1. 多模态融合:未来的研究可以探索如何将视觉、听觉等多模态信息与LLMs集成,以提高其在具身环境中的感知和理解能力。
2. 物理和几何推理:开发能够进行物理和几何推理的LLMs,以处理涉及空间规划、物体操纵等任务。
3. 记忆系统的集成:研究如何将记忆系统(如情景记忆和状态记忆)集成到LLMs中,以利用过去的经验和环境表示进行更好的决策。
4. 导航和探索:扩展LLMs的应用范围,使其能够在动态环境中进行有效的导航和探索。
5. 前向、后向和反事实预测:评估LLMs在前向预测(动作→状态变化)、后向预测(目标状态→必要子目标)和反事实推理(假设性“如果”场景)的能力。
6. 数据集和模拟环境的多样性:开发新的数据集和模拟环境,以捕捉现实世界场景的复杂性和多样性。
7. 模型微调:利用细粒度错误分析和反馈对LLMs进行微调,使其从错误中学习并提高决策制定能力。
Ref:
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









