







一、背景
关于OCR识别的大模型,张小白做了2次探索:
张小白:PP-DocBee 表格识别能力初探(使用百度AI Studio)
和
张小白:另一个表格识别大模型GOT-OCR2.04
这次得知olmOCR也可以做这个:
https://huggingface.co/allenai/olmOCR-7B-0225-previewhuggingface.co/allenai/olmOCR-7B-0225-previewhuggingface.co/allenai/olmOCR-7B-0225-preview
代码仓:
https://github.com/allenai/olmocrgithub.com/allenai/olmocrgithub.com/allenai/olmocr
那就试一试吧!
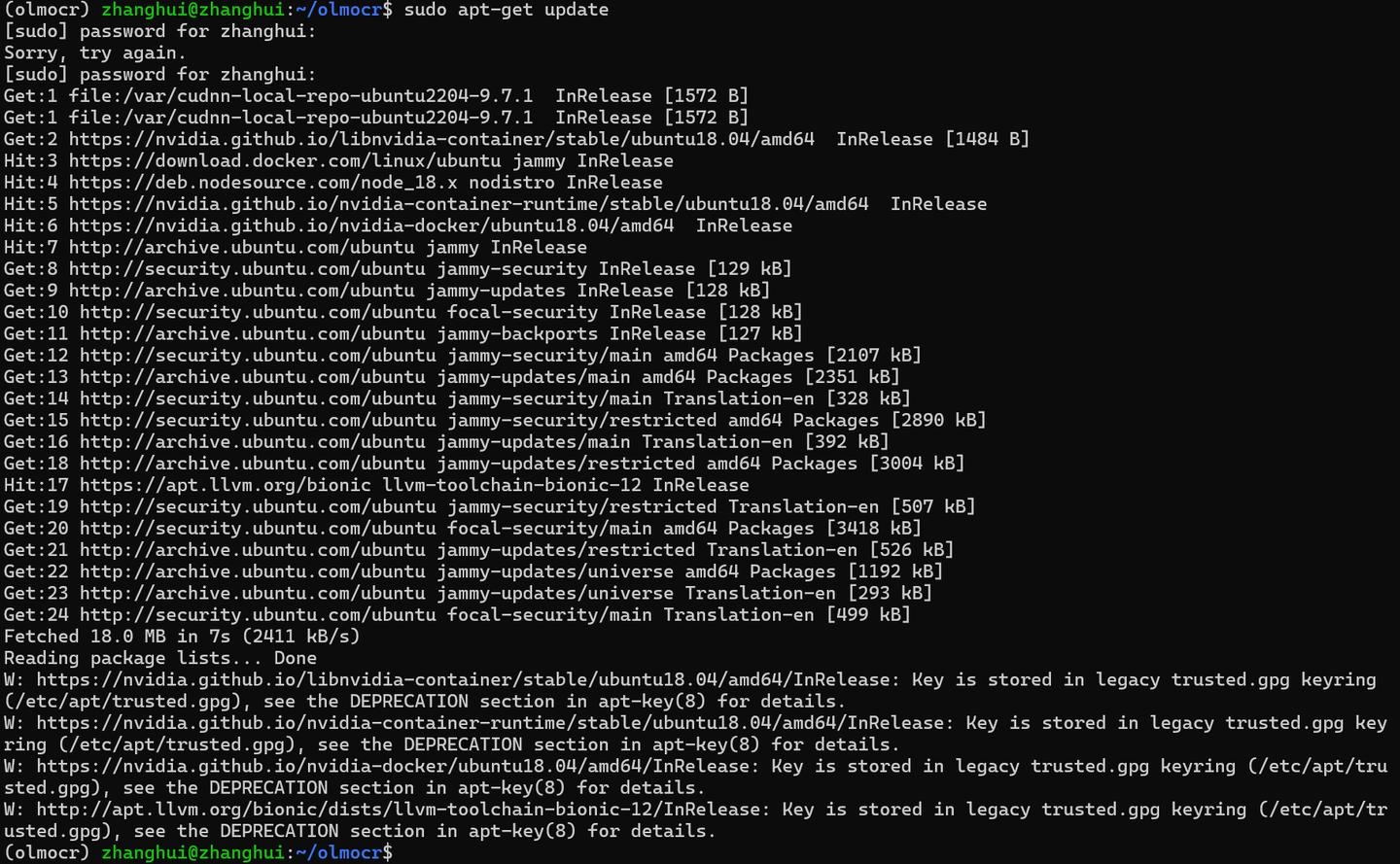
二、安装系统软件
安装系统软件
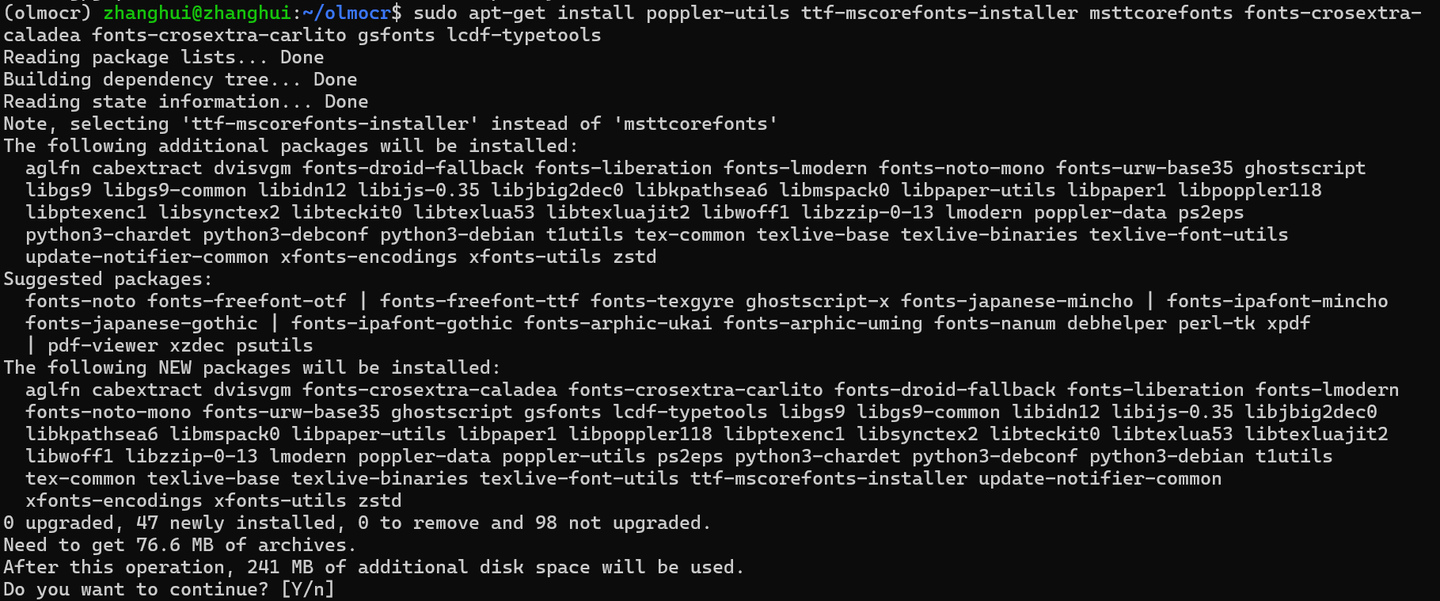
sudo apt-get update sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools
三、在conda环境安装pip软件包
conda create -n olmocr python=3.11 -y conda activate olmocr git clone https://github.com/allenai/olmocr.git cd olmocr pip install -e .
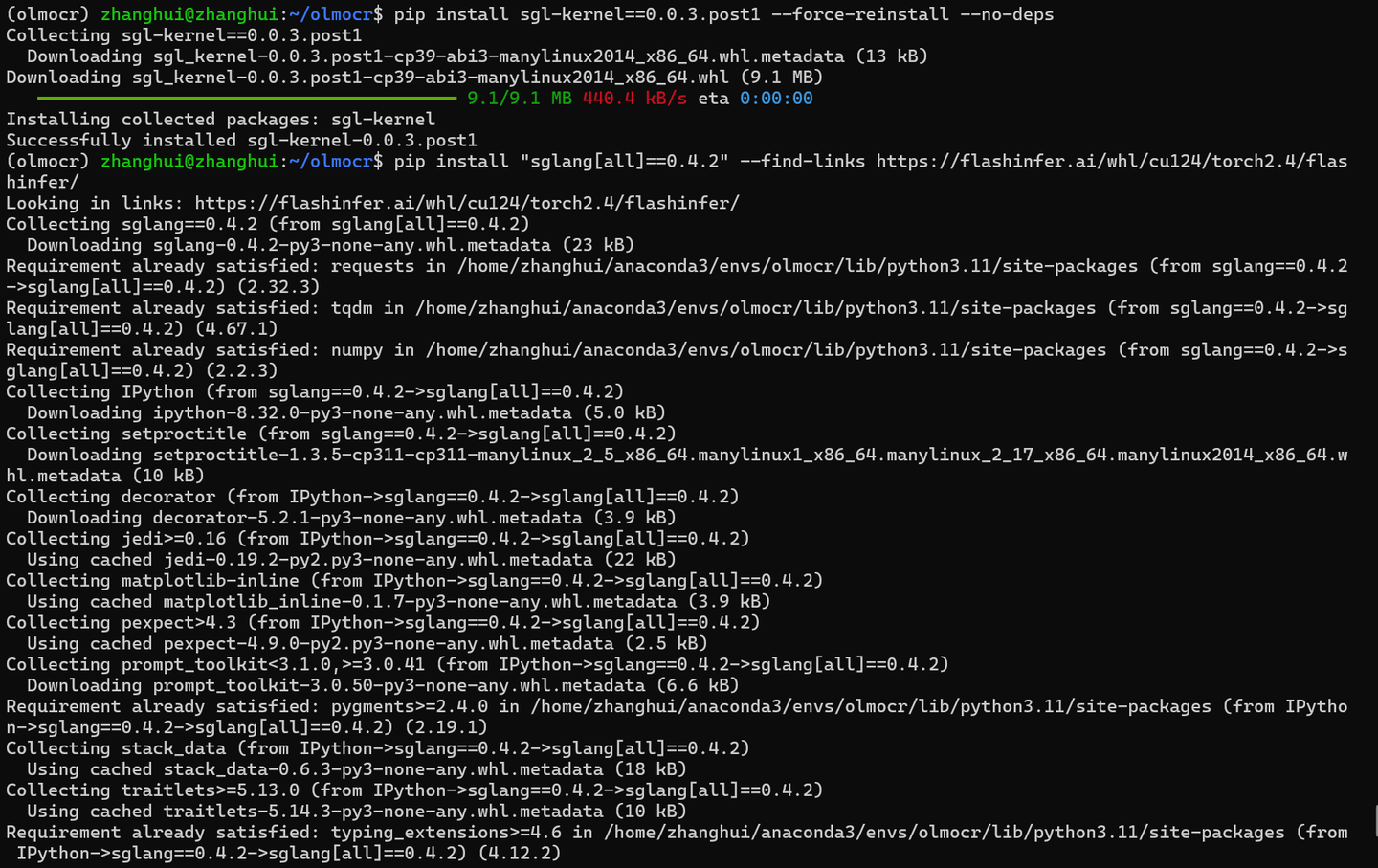
pip install sgl-kernel==0.0.3.post1 --force-reinstall --no-deps pip install "sglang[all]==0.4.2" --find-links https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/

四、验证olmocr
vi test_olmocr.py
import torch
import base64
import urllib.request
from io import BytesIO
from PIL import Image
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from olmocr.data.renderpdf import render_pdf_to_base64png
from olmocr.prompts import build_finetuning_prompt
from olmocr.prompts.anchor import get_anchor_text
# Initialize the model
model = Qwen2VLForConditionalGeneration.from_pretrained("allenai/olmOCR-7B-0225-preview", torch_dtype=torch.bfloat16).eval()
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Grab a sample PDF
urllib.request.urlretrieve("https://molmo.allenai.org/paper.pdf", "./paper.pdf")
# Render page 1 to an image
image_base64 = render_pdf_to_base64png("./paper.pdf", 1, target_longest_image_dim=1024)
# Build the prompt, using document metadata
anchor_text = get_anchor_text("./paper.pdf", 1, pdf_engine="pdfreport", target_length=4000)
prompt = build_finetuning_prompt(anchor_text)
# Build the full prompt
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_base64}"}},
],
}
]
# Apply the chat template and processor
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
main_image = Image.open(BytesIO(base64.b64decode(image_base64)))
inputs = processor(
text=[text],
images=[main_image],
padding=True,
return_tensors="pt",
)
inputs = {key: value.to(device) for (key, value) in inputs.items()}
# Generate the output
output = model.generate(
**inputs,
temperature=0.8,
max_new_tokens=50,
num_return_sequences=1,
do_sample=True,
)
# Decode the output
prompt_length = inputs["input_ids"].shape[1]
new_tokens = output[:, prompt_length:]
text_output = processor.tokenizer.batch_decode(
new_tokens, skip_special_tokens=True
)
print(text_output)
# ['{"primary_language":"en","is_rotation_valid":true,"rotation_correction":0,"is_table":false,"is_diagram":false,"natural_text":"Molmo and PixMo:\\nOpen Weights and Open Data\\nfor State-of-the']
python test_olmocr.py

显存消耗:20G左右。
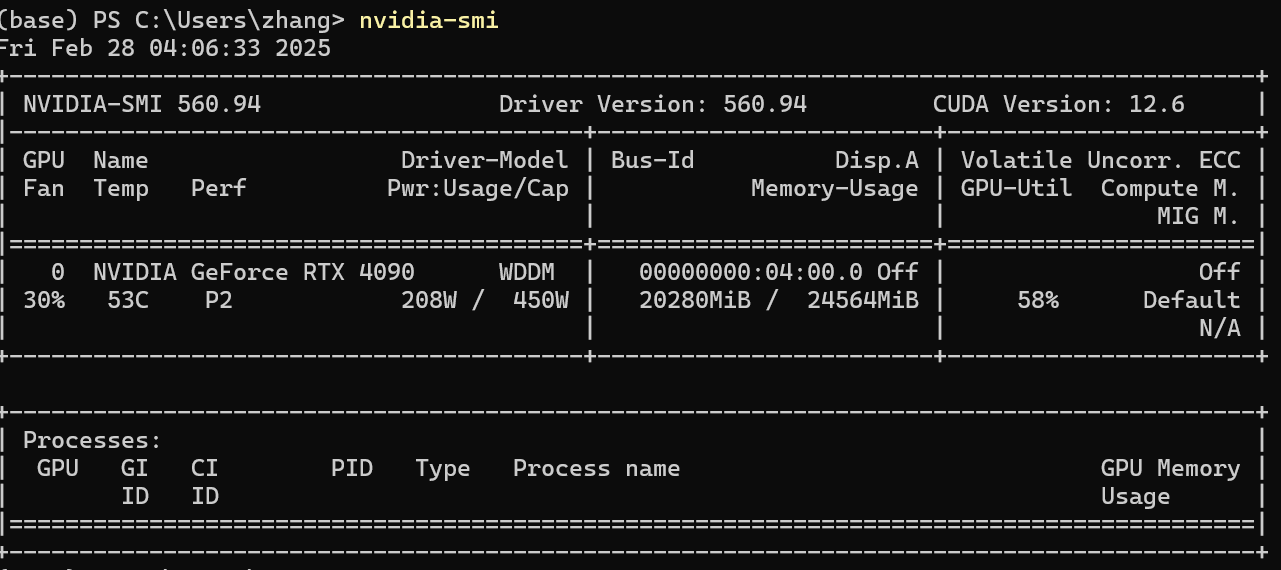
测试单个pdf识别:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/horribleocr.pdf
待识别的pdf文件如下:

cd ./localworkspace/results

识别结果如下:
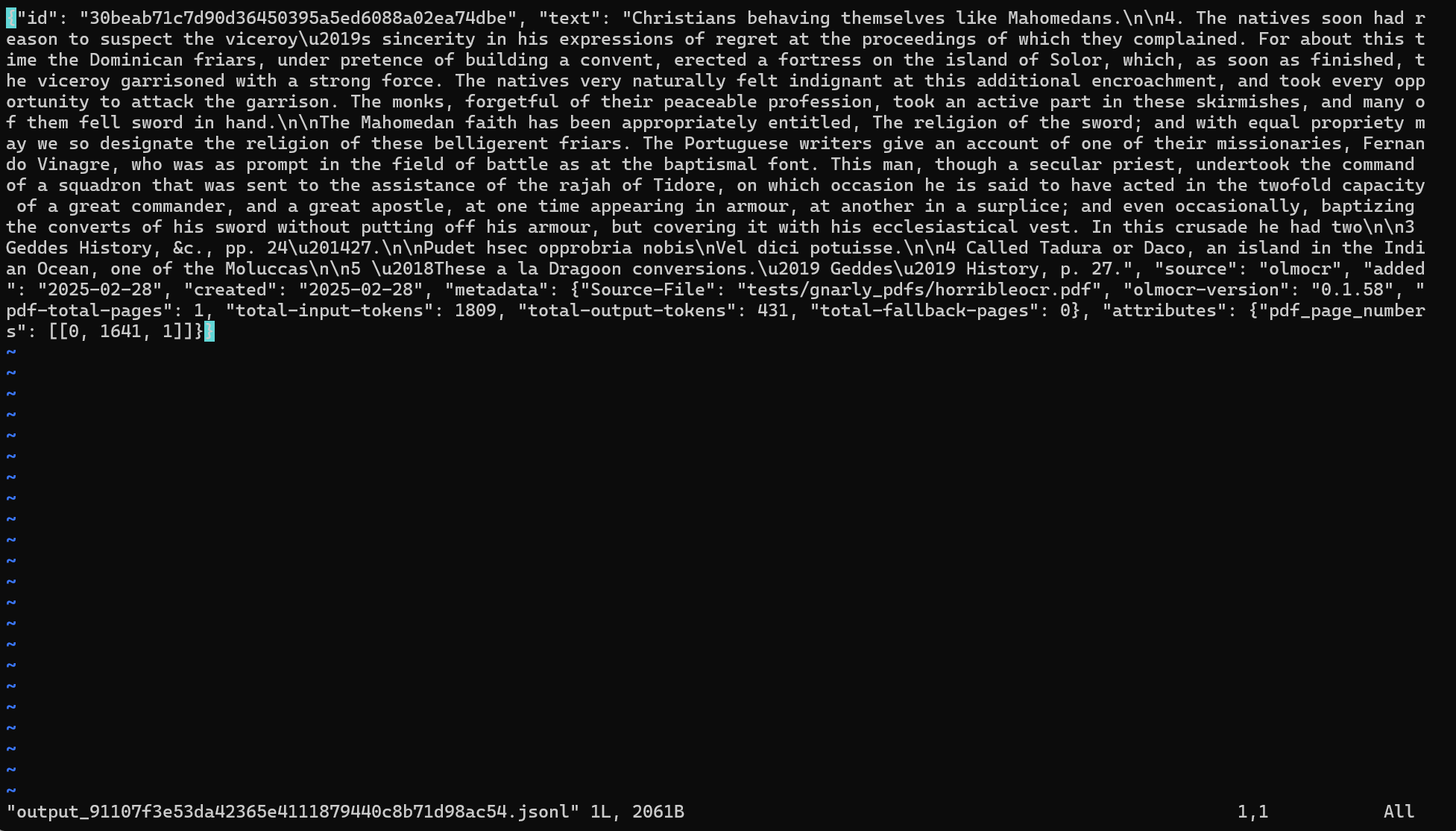
测试一批pdf识别:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/*.pdf
显存消耗依然是20G左右:
查看结果:
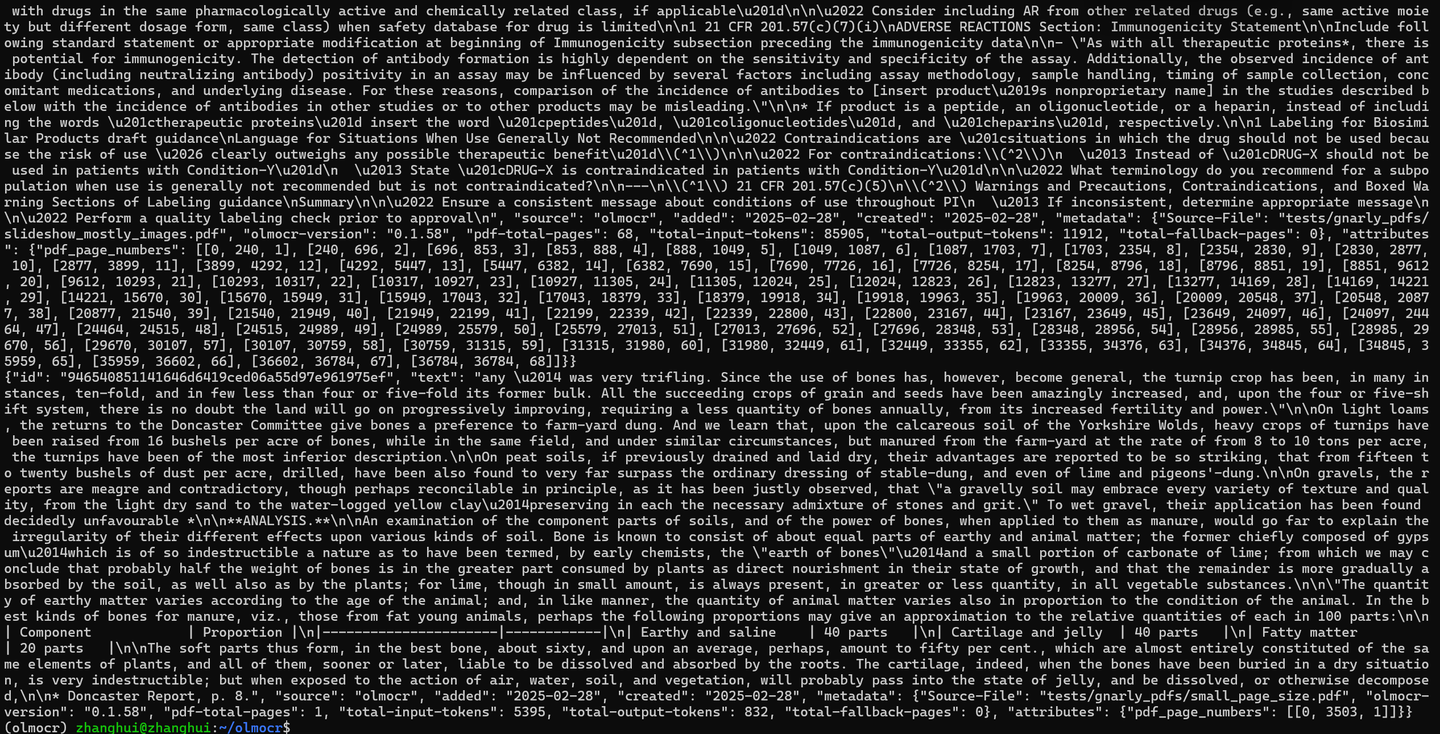
cat localworkspace/results/output_*.jsonl
转换结果:
python -m olmocr.viewer.dolmaviewer localworkspace/results/output_*.jsonl


浏览器打开 ./dolma_previews/tests_gnarly_pdfs_horribleocr_pdf.html

五、测试报表pdf的识别能力
python -m olmocr.pipeline ./localworkspace --pdfs tests/caiwu/zichan.pdf

python -m olmocr.viewer.dolmaviewer localworkspace/results/output_*.jsonl
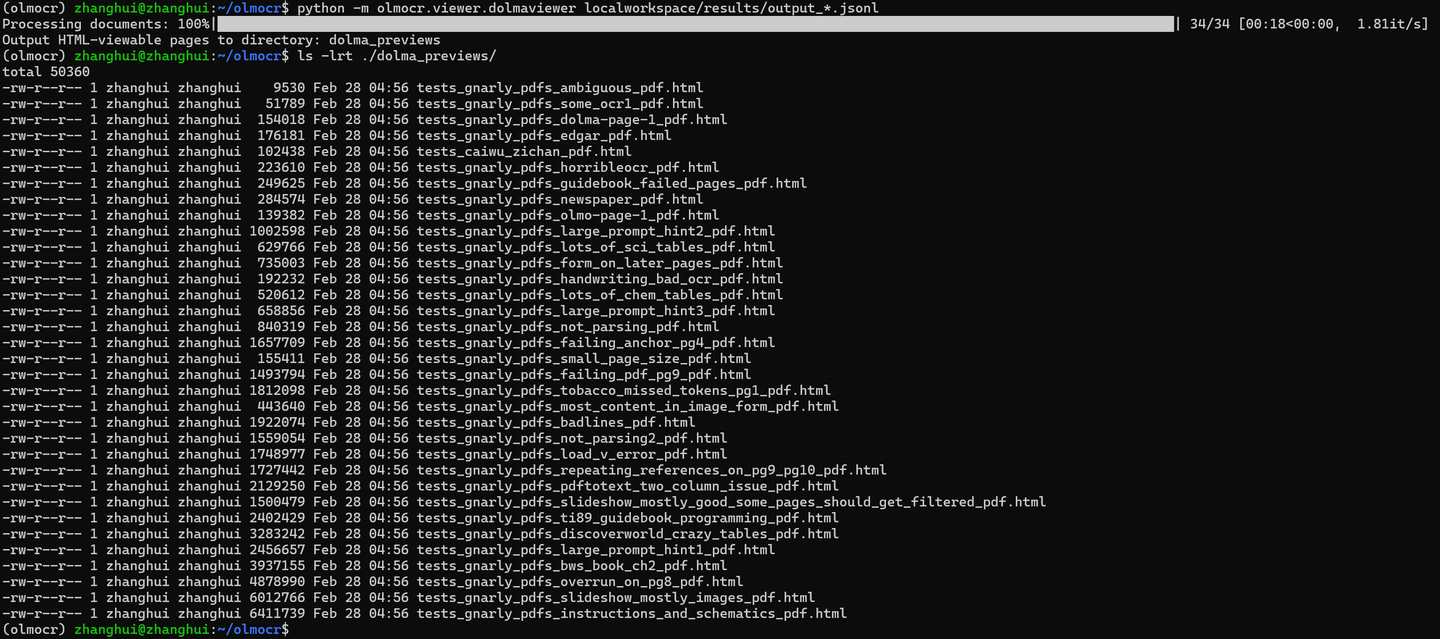
浏览器打开 ./dolma_previews/tests_caiwu_zichan_pdf.html
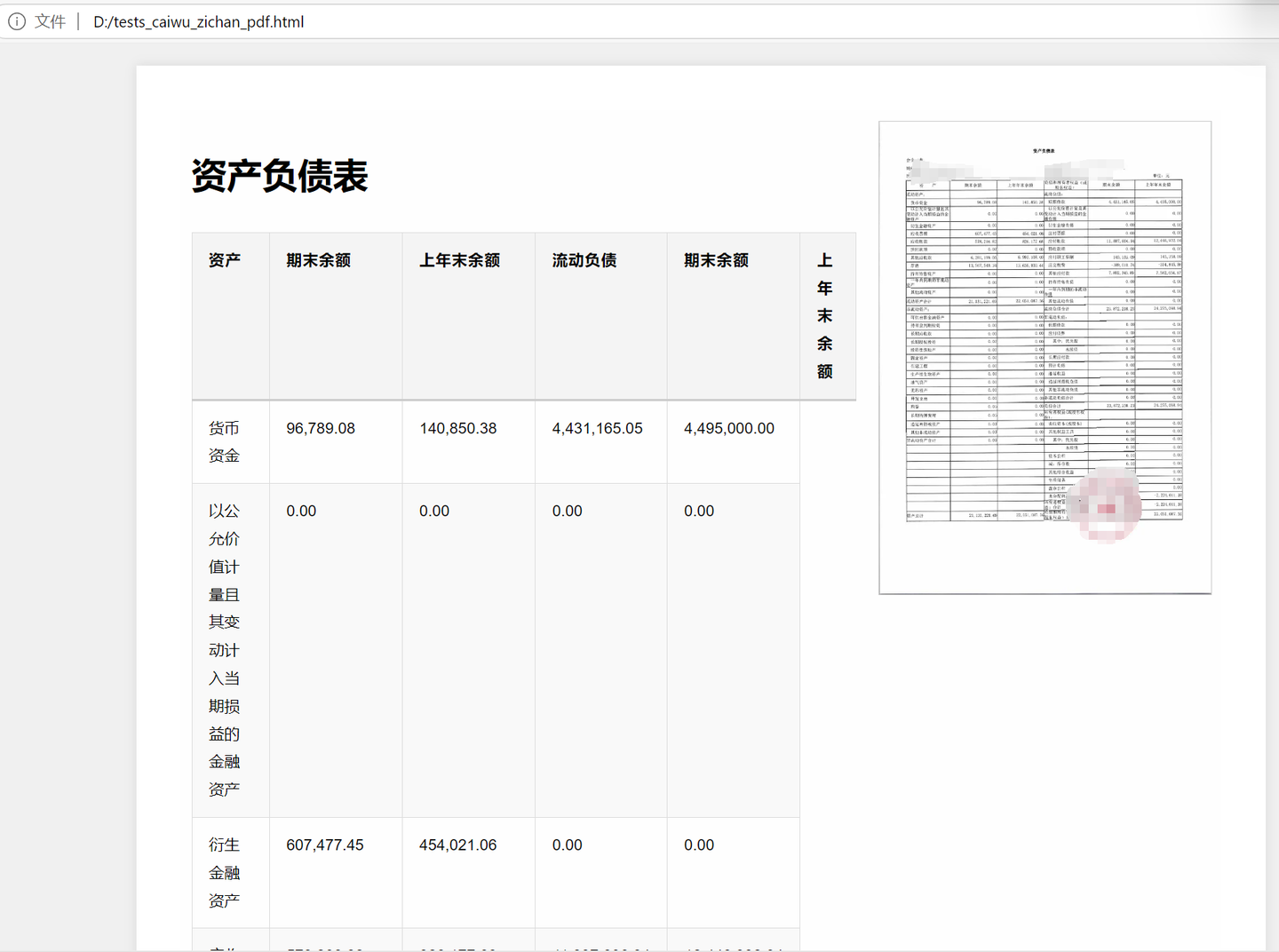
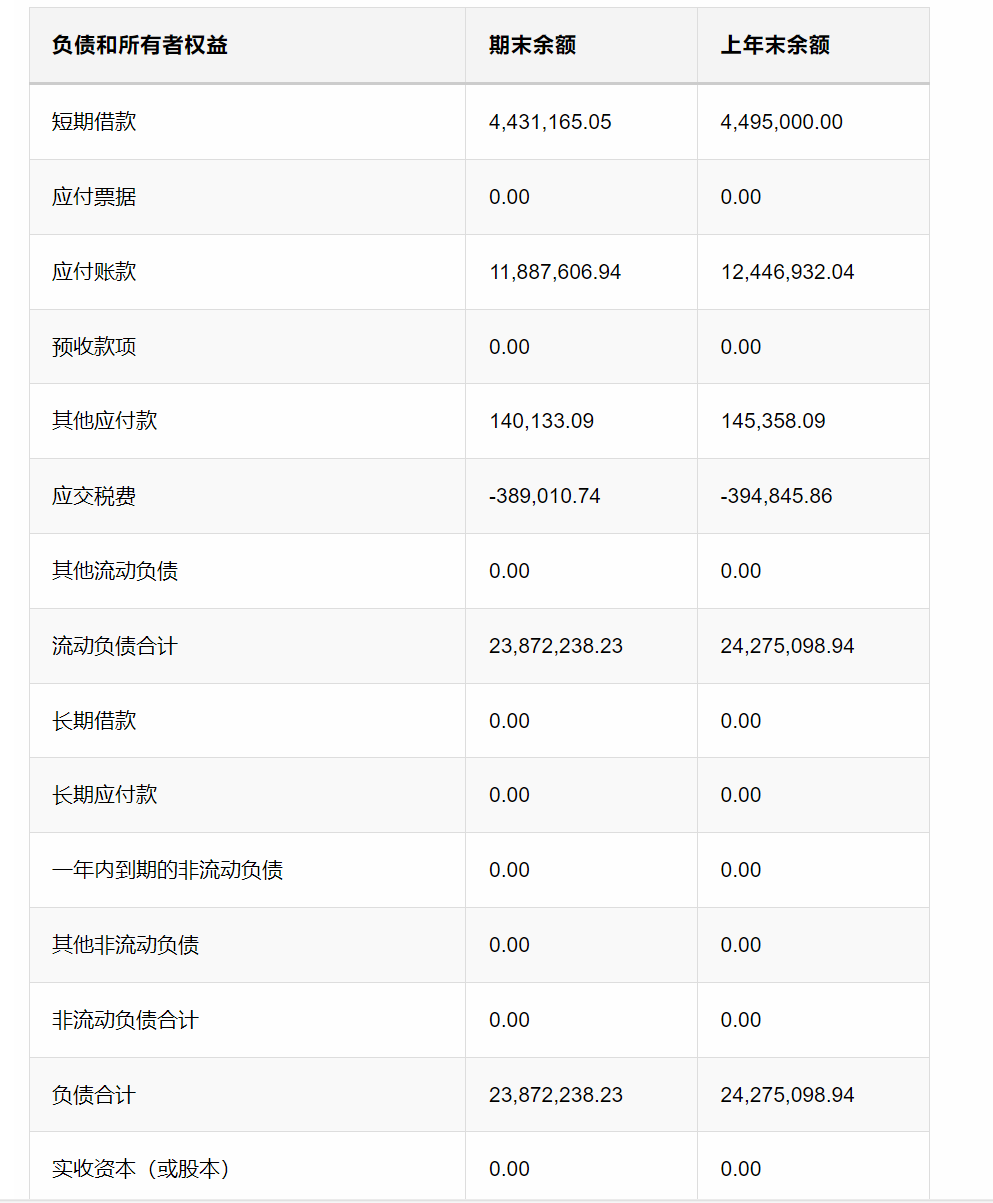
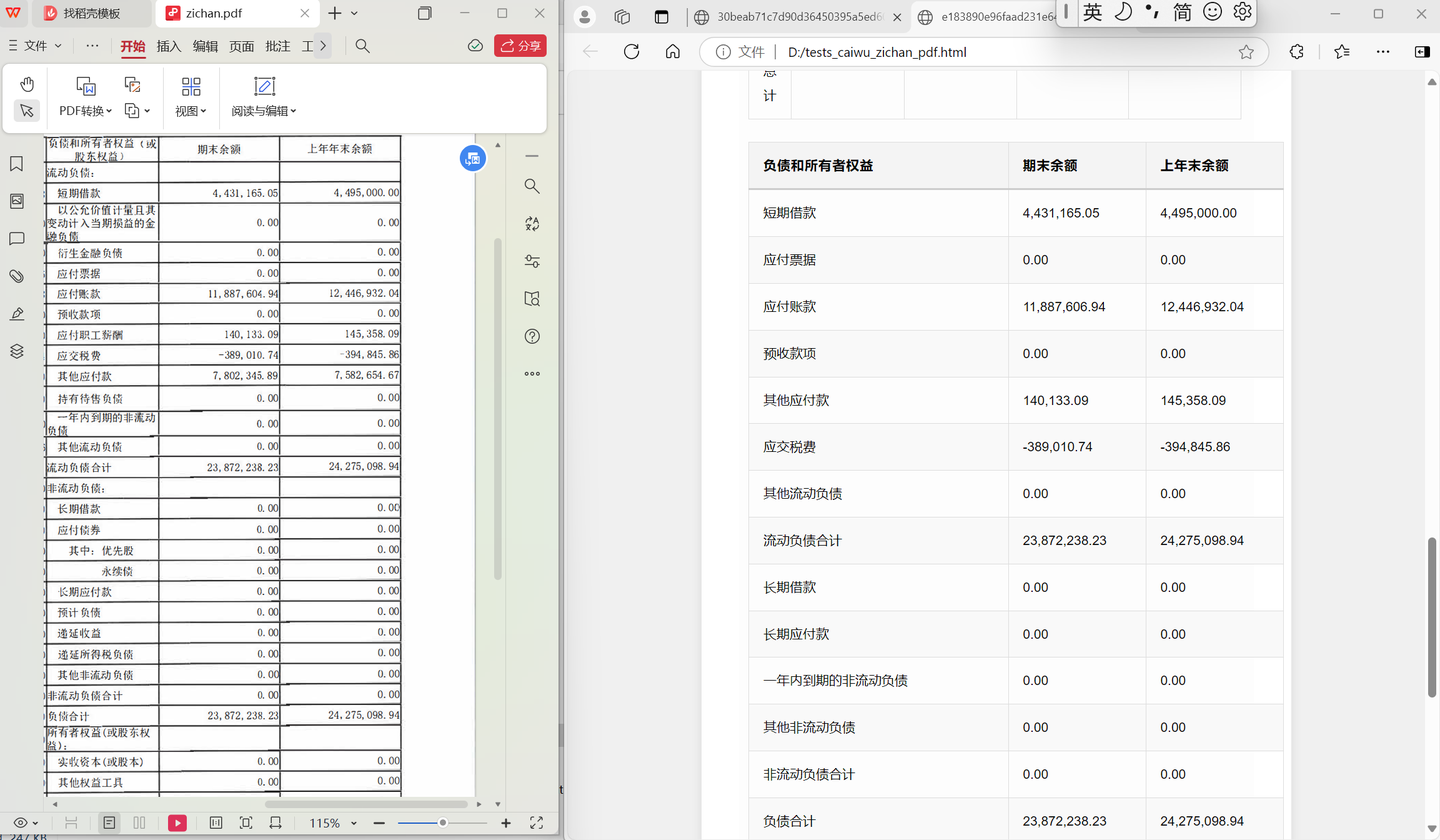
对于表格pdf,貌似还是有识别漏了的情况。


















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











