



 本文介绍了在金融保险企业环境中,如何利用Splunk Enterprise和Splunk Forwarder结合自定义脚本来安全地收集Windows系统的虚拟内存数据。通过讨论不同实现方式的优缺点,选择了Splunk作为解决方案,并详细阐述了配置过程,包括设置DeploymentServer、推送脚本、配置数据输入等步骤。
本文介绍了在金融保险企业环境中,如何利用Splunk Enterprise和Splunk Forwarder结合自定义脚本来安全地收集Windows系统的虚拟内存数据。通过讨论不同实现方式的优缺点,选择了Splunk作为解决方案,并详细阐述了配置过程,包括设置DeploymentServer、推送脚本、配置数据输入等步骤。
需求
目前有很多运维需求场景是基于CMDB配置信息的监控、自动化处理等等,需要梳理IT资产的信息,包括操作系统参数、软件参数、进程信息等等。本文就模拟一个Windows虚拟内存数据的采集
实现
根据不同的IT环境,选择不同的实现方式很重要
- 脚本实现:缺点是需要选择合理的认证方式,如果是比较严格的生产系统的话,这种方式就会遇到挑战,对比其他几种方式,优势在于比较单纯,不需要了解太多其他技术细节。
- Agent实现:目前生产系统上都会有一些比较成熟的商业监控软件Agent,比如一些监控软件Zabbix、Solarwinds、APM等等,都会支持一些自定义监控指标的上报功能,有插件或者脚本多种模式,优点就在于有成熟插件可使用或者平台承载自定义脚本,缺点其实就是需要了解这类监控
- 端口扫描:也就是根据一些协议如SNMP、TCP\IP、SYSLOG等等,优点就是数据格式都比较规范,缺点在于只有这些标准规范的数据
综合上述实现方式,选择适合自己企业的IT运行环境,比如下文中我要继续表述的为什么要基于Splunk,因为对象是金融保险企业,IT生产合规性要求高,不允许随意运行脚本,有严格的认证控制和准入机制,但正因为合规性要求高,所以已经有一些成熟监控软件比如Solarwinds和Splunk,但Solarwinds实现的NPM功能非SAM,所以采用Splunk的方式
环境
- Splunk Enterprise (Splunk 平台)
- Splunk Forwarder (Splunk 转发器,相当于Agent转发采集服务器信息)
- 自定义采集的脚本 (放入$SPLUNK_HOME\bin\scripts)
- 采集对象以及指标 (我这里主要描述的是Windows)
配置
安装步骤就略过了,唯一需要提醒的就是安装Splunk Forward的时候,需要选择DeploymentServer也就是集中管理服务器,推送脚本用

也可以通过命令行
$SPLUNK_HOME\bin\splunk set deploy-poll 192.168.56.1:8089
另外还可以配置收集器Splunk Forward自带的一些数据收集功能的,比如Windows的Events等等,然后在平台上配置一个接收器,当然如果都想通过脚本的话也可以不配置减少消耗

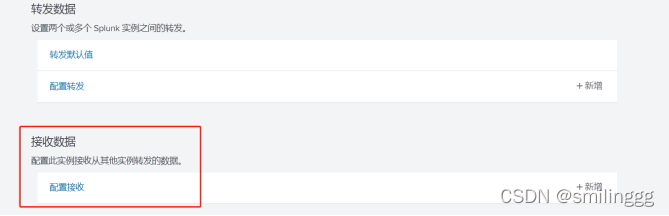
在平台上选择输入设置→转发接收

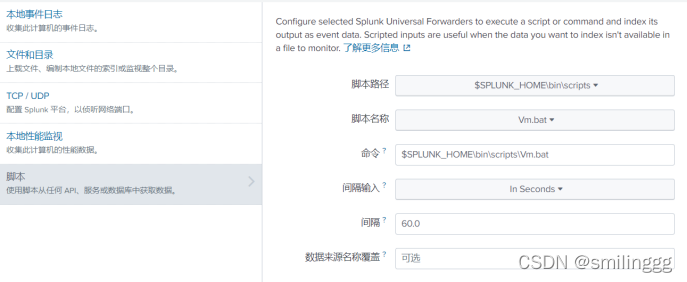
回到脚本推送配置,在平台上选择输入设置→数据输入,选择远程脚本

选择forwarder,可以选择多个成为一组,

选择脚本,也就是我们提前放入bin\scripts下的,然后平台会推送到目标服务器,选择时间间隔等等
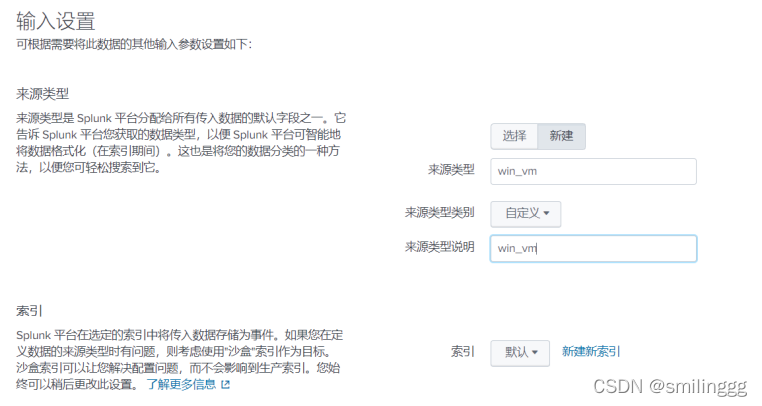
自定义一个类型,方便我们之后通过平台查找所要的数据
配置完成后,就可以看到我们平台推送脚本到目标服务的目录位置了

目标服务器脚本的内容与执行结果

在平台上查询结果,获取值
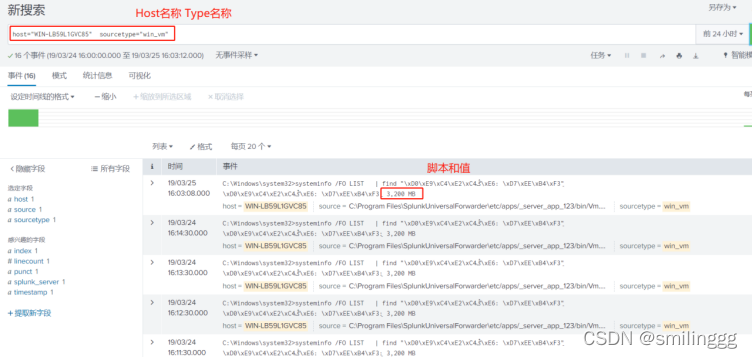
通过REST接口获取数据
先要生成查询
curl -u smilinggg:admin1234 -k -X POST https://localhost:8089/services/search/jobs -d search="search host=\"win-lb59l1gvc85\" sourcetype=\"win_vm\""
返回查询的ID号

然后通过ID号查看查询结果
curl -u smilinggg:admin1234 -k -X GET https://localhost:8089/services/search/jobs/1553512366.104/results
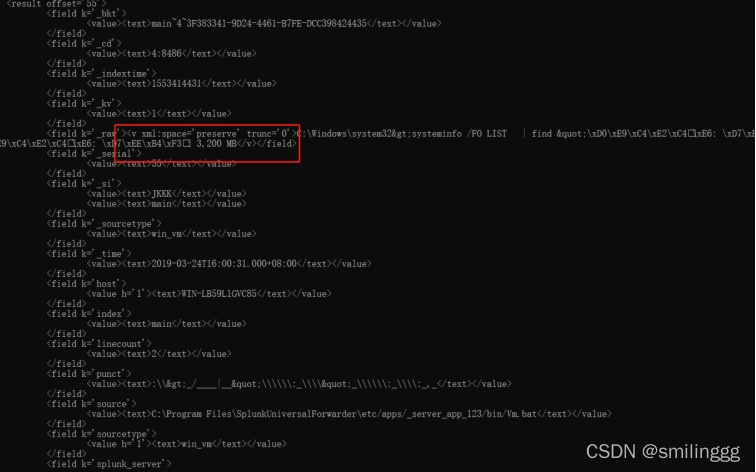
也支持json在后面加?output_mode=json
也支持sdk查询,学习成本较高,就选择标准的REST
总结
关于Splunk的模拟环境,官方有使用版下载可以免费使用30天,如果时间过期,就解决时间的问题
我这里也是有个过期的
链接:https://pan.baidu.com/s/1GStqjc4miFmXf4NLrkblOQ
提取码:ruc1
关于Splunk接口文档,https://docs.splunk.com/Documentation/Splunk/8.2.5/RESTTUT/RESTsearches
关于后续取值后的格式化,Splunk提供正则对数据格式化,也可以通过脚本的时候做格式化,还可以对输入输出关键字段做特殊化标识,当然我们选择了脚本中约定特殊标识,然后在程序了格式化

















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









