



 ApacheSpark3.0版的DeltaLake3.5发布,引入DeltaUniForm和IncrementalKernel,提升性能和数据处理效率。Linux基金会赞赏这一开源进展,强调了互操作性和扩展性的重要性。Hudi与DeltaLake相比在某些场景下更具优势,但DeltaLake更稳定且适合大规模数据湖应用。
ApacheSpark3.0版的DeltaLake3.5发布,引入DeltaUniForm和IncrementalKernel,提升性能和数据处理效率。Linux基金会赞赏这一开源进展,强调了互操作性和扩展性的重要性。Hudi与DeltaLake相比在某些场景下更具优势,但DeltaLake更稳定且适合大规模数据湖应用。
我们很高兴地宣布在 Apache Spark 3.0 上发布 Delta Lake 3.5(发行说明),其功能使其更易于在 Delta Lake 上使用和标准化。
此版本包括数百个改进和错误修复,但我们想指出以下内容:
- Delta UniForm:扩展了与所有引擎的兼容性,
- 增量内核:使构建和维护增量连接器更简单,
- 更快的 DML 语句
Delta Lake 3.0 标志着使 Delta Lake 可跨格式互操作、更易于使用和提高性能的集体承诺。
Linux 基金会对 Delta Lake 3.0 的发布表示赞赏,其中包括 Delta Kernel 和 UniForm,展示了开源生态系统的持续进步和创新。随着数据处理步伐的加快,Delta Lake 3.0 的发布表明了社区驱动项目的至关重要性,这些项目优先考虑可扩展性、可靠性和互操作性,以实现技术的未来。
——Jim Zemlin,Linux基金会执行董事
三角洲湖 3.0 有什么新功能?
自三角洲湖 2.0 以来,三角洲湖一直在迅速引入功能。本博客将回顾其中的一些将对性能和互操作性产生影响的内容。

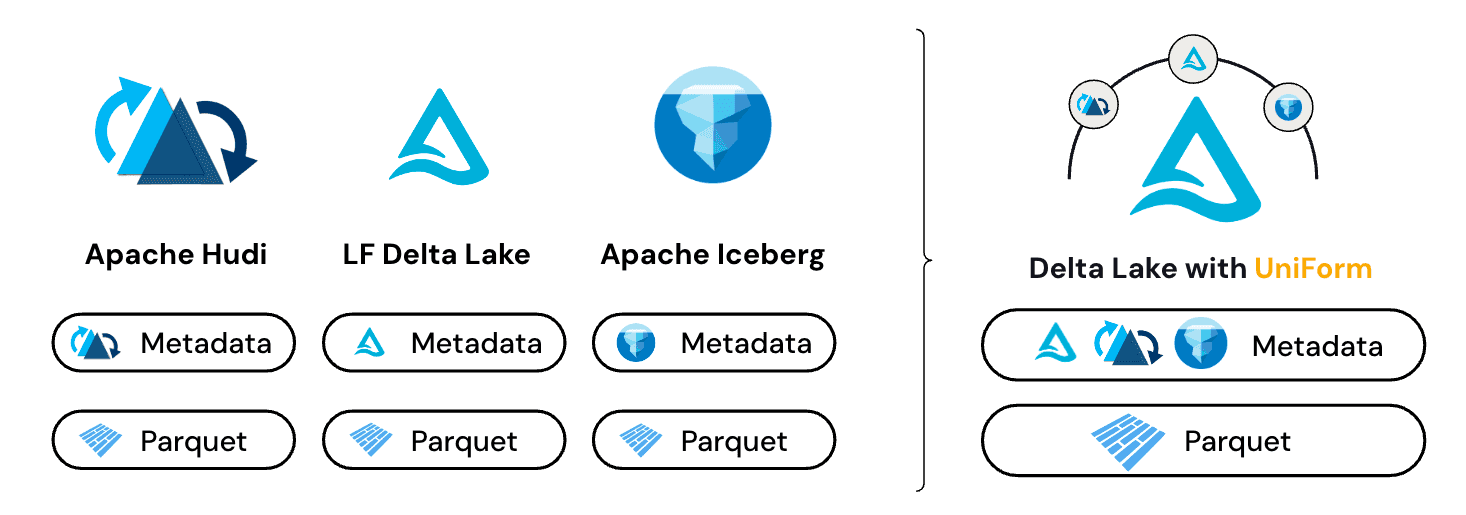
Delta Universal Format (Delta UniForm)
与Delta Lake一样,Apache Iceberg和Apache Hudi在Parquet数据之上包含元数据。在 Delta UniForm 发布之前,跨表格式操作的主要方法是复制和/或转换元数据。虽然这种方法是可行的,但它有一个明显的缺点,即对 Parquet 数据或湖屋格式之一的每次更改都需要触发更新的转换。
Delta UniForm 根据其共享的基础 Parquet 数据的单个副本自动生成 Iceberg 和 Delta Lake 的元数据。Delta UniForm 为所有读者提供数据的实时视图,无需额外的数据复制或转换。
若要设置增量 UniForm 表,只需设置表属性:
CREATE TABLE main.default.table_name (msg STRING)
TBLPROPERTIES('delta.universalFormat.enabledFormats' = 'iceberg');将表启用为 Delta UniForm 表后,任何表修改都会触发 Iceberg 元数据的异步生成。然后,任何Iceberg阅读器都可以使用数据而无需进一步修改,前提是客户端已写入开源Iceberg规范。对 Hive 元存储的支持也可用。
增量内核
三角洲湖连接器生态系统在过去几年中经历了急剧增长。该项目的受欢迎程度和成功值得庆祝,但我们认识到这给开发人员带来了一些挑战:连接器之间的性能和正确性变化,以及采用新协议功能的时间更长。
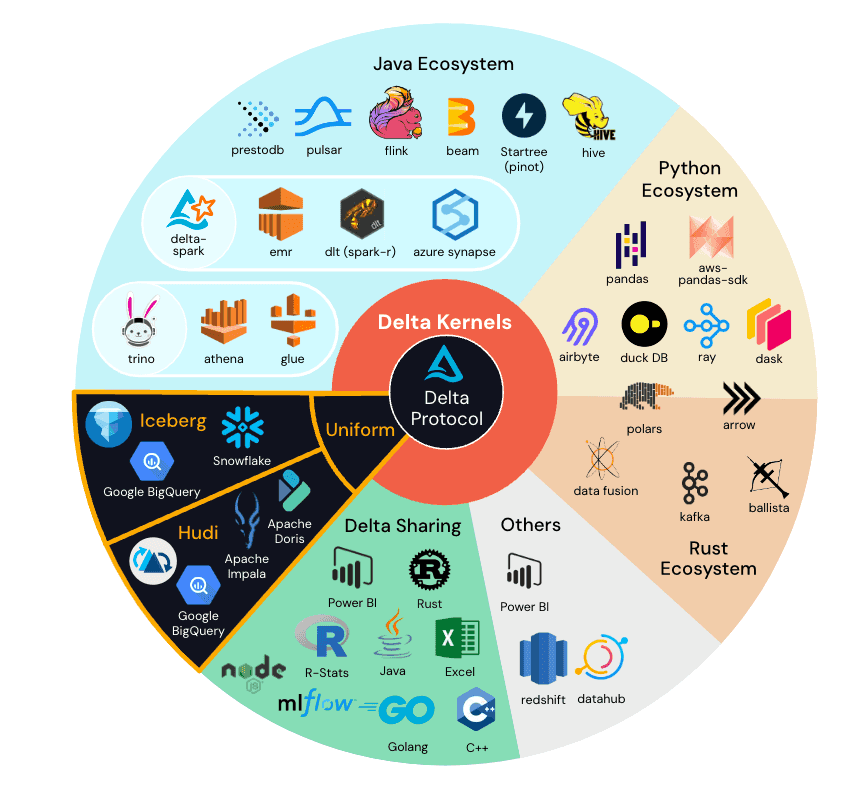
Delta 内核在 2023 年数据 + AI 峰会上推出,抽象出简单核心库 API 背后的 Delta Lake 协议细节。这种简化意味着开发人员可以使用稳定的 API 调用构建连接器,并且 Kernel 应用特定于协议的逻辑来返回正确的行数据。
有关如何在独立 Java 程序或分布式处理连接器中使用内核的更多信息,请参阅用户指南。
合并、更新和删除性能增强
合并
对命令的增强功能被纳入三角洲湖PR 1827。主要改进包括:MERGE
- 仅合并的数据跳过
MATCHED - 增强了对仅合并的处理
INSERT - 高效的行更改写入
- 高效的指标计数器
您可以通过阅读合并 — Delta Lake 文档、观看技术讲座 |潜入三角洲湖第 3 部分:如何在 YouTube 上删除、更新和合并工作视频,或查看我们之前的博客三角洲湖合并。MERGE
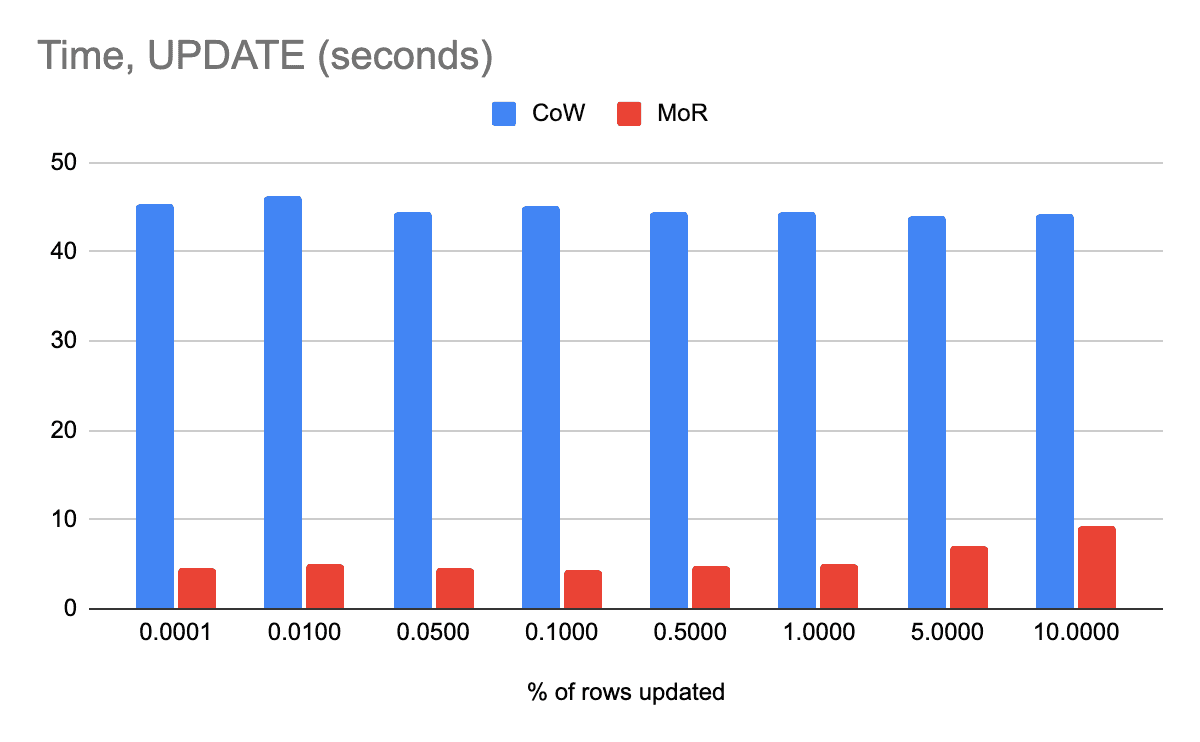
更新
该命令现在支持写入删除向量 (DV)。这将使增量表上的操作速度提高 10 倍,尤其是点更新。有关更多详细信息,请参阅 Delta Lake PR 1942。UPDATEUPDATE
目前必须手动启用此功能:
SET spark.databricks.delta.update.deletionVectors.persistent = 'true;
UPDATE table_name SET id = -1 WHERE id % 2 = 0;
删除
对规范化逻辑的改进减少了对表中每一行的昂贵调用。相反,现在缓存了规范化路径,这会导致启用删除向量时命令的性能提高 2 倍或更多。FILE_PATHPath.toUri.toStringDELETE
三角洲湖 3.0 中的其他功能
- 新的检查点格式 (v2) 解决了 v1 检查点格式的许多现有可靠性问题和限制,并为将来的更多优化打开了大门。有关更多详细信息,请参阅 Delta Lake PR 1793。
- 支持从 Apache Spark 3.5 上的 Iceberg 表零拷贝转换为 Delta。转换为增量会在同一位置生成增量表,而无需重写 Parquet 文件。
- 日志压缩文件已添加到增量协议规范中,这可能会降低增量检查点的频率。在 Delta Spark 中添加了对日志压缩文件的读取支持。
此版本充满了更多功能。有关完整列表,请参阅发行说明。
总结
目前性能上Delta Lake 对数据进与iceberg进行格式统一,这将结束数据湖站“山头”的情况,解决ETL问题,目前delta lake 全球用户7000多,在稳定上没有问题,从性能上delta 和hudi 的性能是相当,在数据load ,数据写入,delta 比hudi 性能提高10%,hudi 增加了很多功能,但是hudi更像是一个数据库,缺乏数据湖的理念,加了很多东西,但是底层比较混乱。如果使用,想稳定可以使用Delta (flink sql 已经支持),如果想激进,尝鲜,hudi比较合适。

















 2773
2773




 到【灌水乐园】发言
到【灌水乐园】发言







