




作者简介:大家好,我是码炫码哥,前中兴通讯、美团架构师,现任某互联网公司CTO,兼职码炫课堂主讲源码系列专题
代表作:《jdk源码&多线程&高并发》,《深入tomcat源码解析》,《深入netty源码解析》,《深入dubbo源码解析》,《深入springboot源码解析》,《深入spring源码解析》,《深入redis源码解析》等
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬。码炫课堂的个人空间-码炫码哥个人主页-面试,源码等
回答
主要是因为 MySQL 使用 B+ 树作为索引结构,当数据量较小时,B+ 树的的高度较低,查询时需要访问的节点较少,性能也就高些。当数据量增加到千万级别,B+ 树的高度就会增加,树的高度增加会导致每次查询需要访问更多的磁盘页,增加了磁盘 I/O 操作次数,导致查询性能下降。
扩展
MySQL 的 B+ 树高度计算
Mysql的默认存储引擎是InnoDB,InnoDB 将表的数据存储在数据页中,每个数据页的默认大小是 16KB。
B+树的叶子节点存的是数据,非叶子节点存的是键值+指针,索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中查找所需的数据。如下:
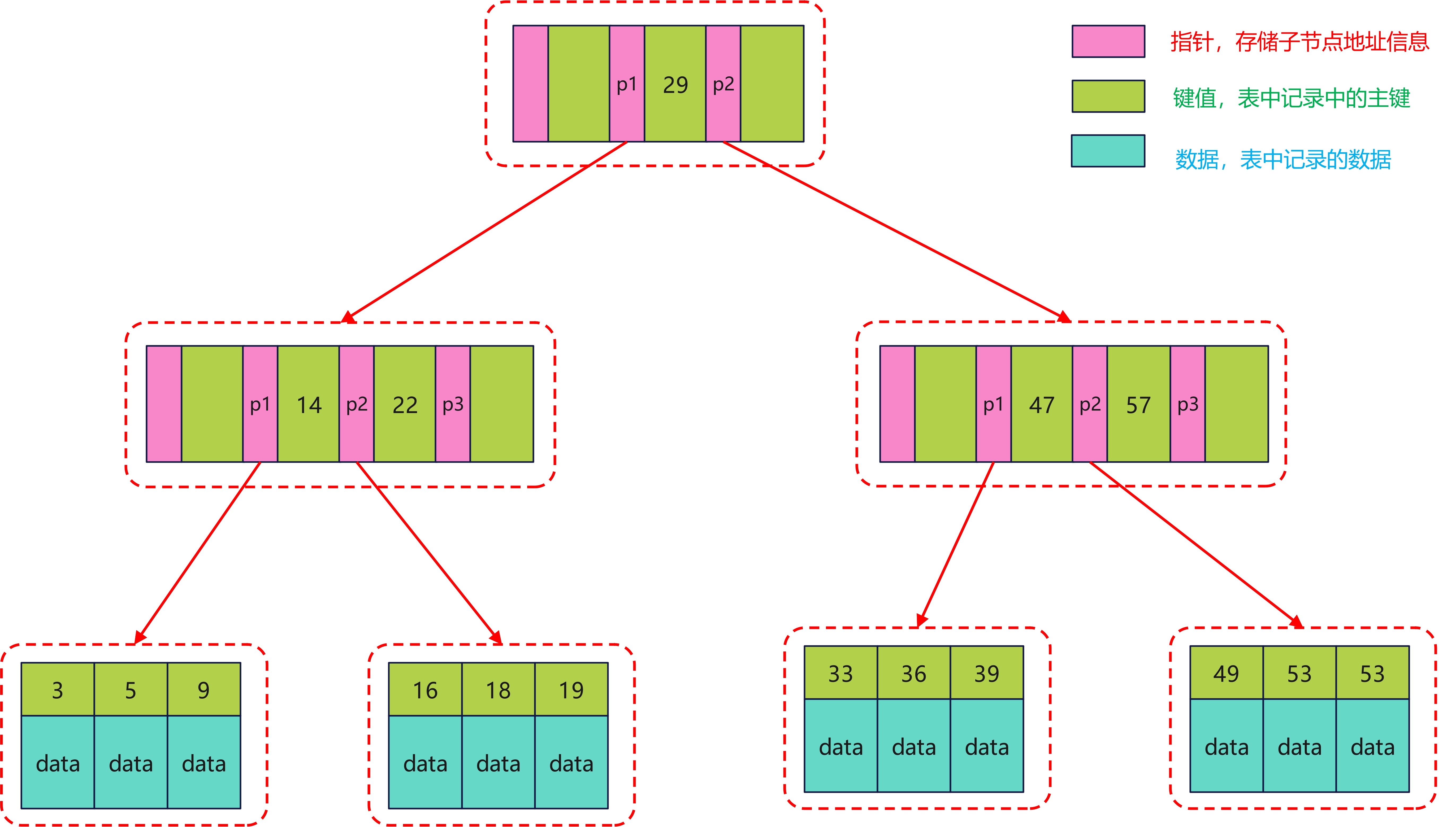
假设我们有一张表,其主键类型为 bigint(长度为 8 字节),在 InnoDB 中,指针的大小为 16 字节,所以非叶子节点能够存储的数据个数为 16KB / 14B = 1170,所以 2 层的话就能代表 1170 * 1170 个叶子页。
加入我们一行数据为 1KB,那么单个叶子页就能存储 16 条数据,所以:
- 一颗高度为 2 的 B+ 树,能够存储的数据为
1170 * 16 = 18720条数据 - 一颗高度为 3 的 B+ 树,能够存储的数据为
1170 * 1170 * 16 = 21902400条数据
所以,一个层数为 3 的B+ 树,大致可以存放 2000 万条数据。在一般情况下,B+树高度一般为 1-3 层,如果层数到达 4 层,或者超过 4 层,则在查询的时候会有更多的磁盘 IO 次数,会降低 MySQL 的性能。
当然,上面仅仅只是一个理论值,叶子节点数据的大小不同,会导致每页存储的数据量也不同,上面是 1KB,如果大小为 5KB 呢?,又或者远远小于 1KB 呢,这两种情况都会导致在第 3 层存储的数据两与 2000 万都不一样。
所以,我们在实际生产环境中不要生搬硬套,不一定偏要到了千万级别就去分库分表,又或者到了千万级别我们也不一定要去分库分表,都是根据实际情况来的,要灵活多变。


















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









