




作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
码哥源码部分
码哥讲源码-原理源码篇【2024年最新大厂关于线程池使用的场景题】
码哥讲源码-原理源码篇【揭秘join方法的唤醒本质上决定于jvm的底层析构函数】
码哥源码-原理源码篇【Doug Lea为什么要将成员变量赋值给局部变量后再操作?】
码哥讲源码【谁再说Spring不支持多线程事务,你给我抽他!】
打脸系列【020-3小时讲解MESI协议和volatile之间的关系,那些将x86下的验证结果当作最终结果的水货们请闭嘴】
TCP 巨复杂 ,它为了保证可靠性,用了巨多的机制来保证,真是个「伟大」的协议,写着写着发现这水太深了。。。
本文的全部图片都是小林绘画的,非常的辛苦且累,不废话了,直接进入正文,Go!
相信大家都知道 TCP 是一个可靠传输的协议,那它是如何保证可靠的呢?
为了实现可靠性传输,需要考虑很多事情,例如数据的破坏、丢包、重复以及分片顺序混乱等问题。如不能解决这些问题,也就无从谈起可靠传输。
那么,TCP 是通过序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输的。
今天,将重点介绍 TCP 的 重传机制、滑动窗口、流量控制、拥塞控制。
# 重传机制
TCP 实现可靠传输的方式之一,是通过序列号与确认应答。
在 TCP 中,当发送端的数据到达接收主机时,接收端主机会返回一个确认应答消息,表示已收到消息。
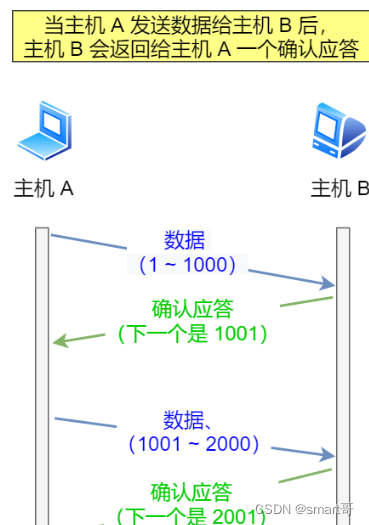
但在错综复杂的网络,并不一定能如上图那么顺利能正常的数据传输,万一数据在传输过程中丢失了呢?
所以 TCP 针对数据包丢失的情况,会用 重传机制 解决。
接下来说说常见的重传机制:
- 超时重传
- 快速重传
- SACK
- D-SACK
# 超时重传
重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据,也就是我们常说的 超时重传 。
TCP 会在以下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
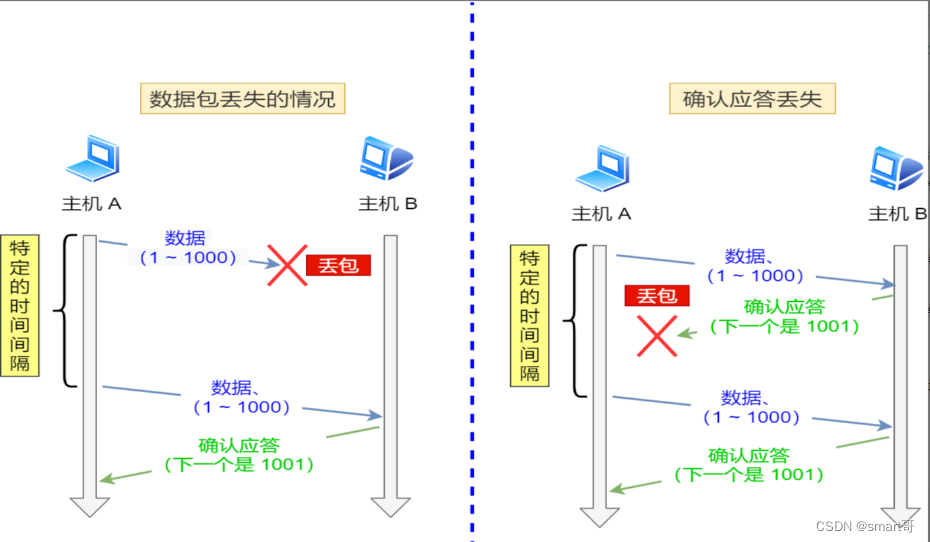
超时时间应该设置为多少呢?
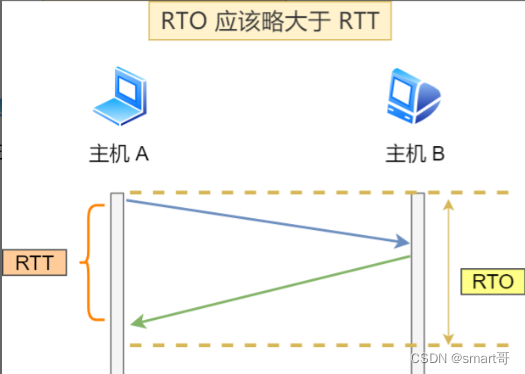
我们先来了解一下什么是 RTT(Round-Trip Time 往返时延),从下图我们就可以知道:
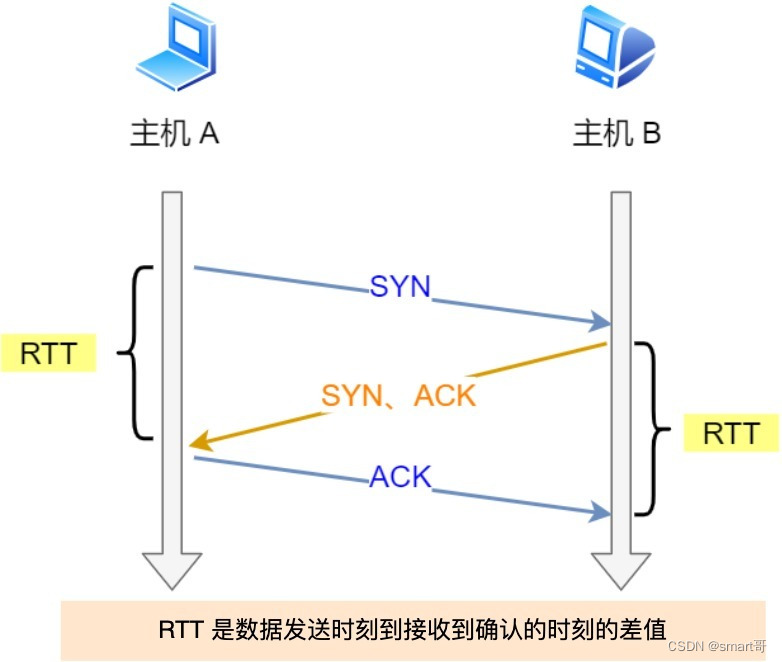
RTT 指的是 数据发送时刻到接收到确认的时刻的差值 ,也就是包的往返时间。
超时重传时间是以 RTO (Retransmission Timeout 超时重传时间)表示。
假设在重传的情况下,超时时间 RTO 「较长或较短」时,会发生什么事情呢?
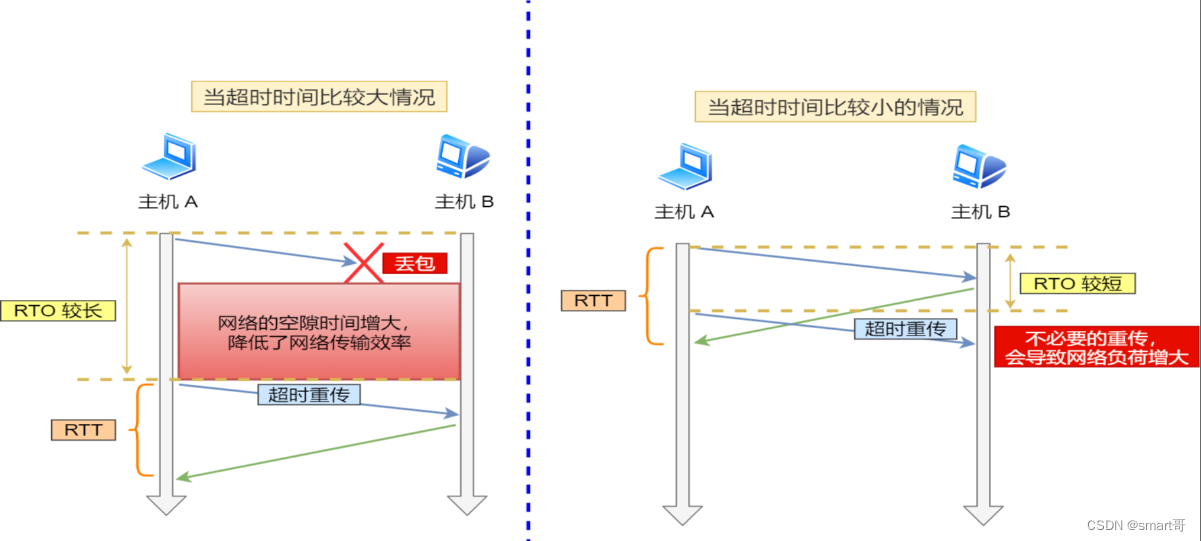
上图中有两种超时时间不同的情况:
- 当超时时间 RTO 较大 时,重发就慢,丢了老半天才重发,没有效率,性能差;
- 当超时时间 RTO 较小 时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
精确的测量超时时间 RTO 的值是非常重要的,这可让我们的重传机制更高效。
根据上述的两种情况,我们可以得知, 超时重传时间 RTO 的值应该略大于报文往返 RTT 的值 。
至此,可能大家觉得超时重传时间 RTO 的值计算,也不是很复杂嘛。
好像就是在发送端发包时记下 t0 ,然后接收端再把这个 ack 回来时再记一个 t1,于是 RTT = t1 – t0。没那么简单, 这只是一个采样,不能代表普遍情况 。
实际上「报文往返 RTT 的值」是经常变化的,因为我们的网络也是时常变化的。也就因为「报文往返 RTT 的值」 是经常波动变化的,所以「超时重传时间 RTO 的值」应该是一个 动态变化的值 。
我们来看看 Linux 是如何计算 RTO 的呢?
估计往返时间,通常需要采样以下两个:
- 需要 TCP 通过采样 RTT 的时间,然后进行加权平均,算出一个平滑 RTT 的值,而且这个值还是要不断变化的,因为网络状况不断地变化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









