




 本文深入探讨Python的多线程技术,通过threading库介绍如何创建和管理线程,包括基本使用、队列获取返回值、线程锁以及Python的假多线程机制。示例代码展示线程同步、并发执行和共享内存的安全性。
本文深入探讨Python的多线程技术,通过threading库介绍如何创建和管理线程,包括基本使用、队列获取返回值、线程锁以及Python的假多线程机制。示例代码展示线程同步、并发执行和共享内存的安全性。
文章目录
前言
这篇博客写的不是很好(有时间我会重新写一写本篇博客,的确写的不是很好),建议先看的的另一篇Java多线程的文章再来看这篇文章会好理解很多。并且上面那篇博客里面也将Java多线程的例子用python写了,可以对照学习。
一、多线程(Threading)是什么?
关于概念性问题参考Java多线程这篇博客
二、threading库
下面演示怎么使用threading使用python多线程功能
1.初识多线程
| function | 功能 |
|---|---|
| threading.active_count() | 返回当前活动的线程数 |
| threading.enumerate() | 返回当前活动的线程列表 |
| threading.current_thread() | 返回当前线程对象 |
import threading
def main():
print(threading.active_count()) # 返回当前活动的线程数
print(threading.enumerate()) # 返回当前活动的线程列表
print(threading.current_thread()) # 返回当前线程对象
if __name__ == '__main__':
main()
输出:
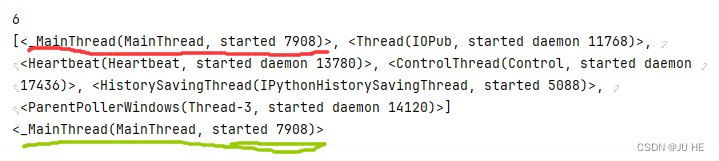
可以看到,目前显示有6个线程在运行中,其中画线的main就是我们mian函数运行的线程,并且可以看到当前正在运行的线程对象就是我们刚定义的main函数。线程对象列表里面其他几个线程不用管,应该是编辑器或者环境开启就有了的。
这么一看,我们可以将一个线程绑定一个python里面某个功能的主函数,那个这个线程就会干那个主函数干的活了。
2.增加新线程
可以看到上面main函数还是在一个脚本里面干一件事啊,如果要同时干第二件事怎么办,那就要添加新线程,并将其绑定到我们需要干的另一个主函数上,下面继续演示。
2.1 多线程的基本使用
import threading
def main():
add_thread = threading.Thread(target=another_main, name='thread2') # 创建线程,并于another_main函数绑定
add_thread.start() # 启动线程
print(threading.active_count()) # 返回当前活动的线程数
print(threading.enumerate()) # 返回当前活动的线程列表
print(threading.current_thread()) # 返回当前线程对象
def another_main():
# 定义另一件事情
print('-------another_main---------')
while True:
# while循环是为了让线程一直运行,不然线程会自动结束,便于观察线程的状态
a=1
if __name__ == '__main__':
main()
输出:
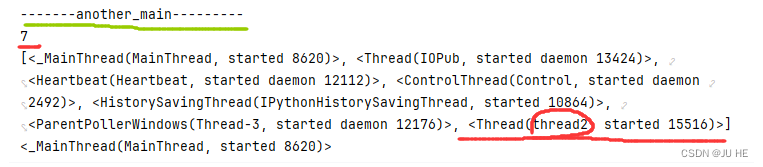
可以看到输出了another_main干的事情,线程数由6变成了7,并且线程列表里面增加了名为thread2的新线程。
实现了在做main里面的事情的同时还在做another_main的事情。
【注】:这和在main里面直接调another_main不一样,直接调这两件事情是有一个先后顺序的,是在共用一个线程;但如果是another_main绑定上一个新线程,那么这两件事情就是平级关系,同时在干。
有没有发现上面演示的没有穿参数进去,如果要传参又应该怎么办呢!python里面传函数是不能带括号()的,似乎麻烦了。放心了,怎么可能开发者没有想到这一点呢,在给一个参数传参数不就可以了,嘿嘿!
import threading
def main():
# 创建线程并传递字符串和数字参数
thread = threading.Thread(target=another_main, args=('Hello', 123))
thread.start()
print("Main thread is done!")
def another_main(string_param, int_param):
# 打印接收到的参数
print("Received string parameter:", string_param)
print("Received integer parameter:", int_param)
if __name__ == '__main__':
main()
输出:

2.2 对多线程是同时进行的进行一个直观上的演示(非重点–理解是实时就行)
上面由于another_main功能几乎是瞬时完成的,根本显示不出来这个同时性,反而像是直接调用打印一样。所以这里用time库进行一个直观上的演示。
import threading
import time
def main():
# 创建线程并传递字符串和数字参数
thread = threading.Thread(target=another_main)
thread.start()
print("Main thread is done!")
def another_main():
print('新thread started') # 打印线程开始
for i in range(10):
time.sleep(0.1) # 暂停0.1秒后再继续运行
print('新thread stop') # 打印线程结束
if __name__ == '__main__':
main()
输出:(这里建议去终端运行效果更好)

可以看到"Main thread is done!"并不是最后才输出,这就说明不是直接调,而是两个工作在同时做,没有先后顺序。
2.3 thread.join()功能
有时我们想要等到我们添加了的新线程完全结束才运行主mian中thread.start()后面的代码·(此时有先后了),就要用到
thread.join()
【注】:thread.join()还有一个非常重要的功能,阻塞主线程,防止主线程跑完了,子线程1,2等还没跑完。这警告我们写多线程对每一个子线程进行thread.join()是必不可少的。
import threading
import time
def main():
# 创建线程并传递字符串和数字参数
thread = threading.Thread(target=another_main)
thread.start()
thread.join() # 等待线程结束,才执行下面的代码
print("Main thread is done!")
def another_main():
print('新thread started') # 打印线程开始
for i in range(10):
time.sleep(0.1) # 暂停0.1秒后再继续运行
print('新thread stop') # 打印线程结束
if __name__ == '__main__':
main()
输出:

可以注释了thread.join()观察结果有什么不同,很简单的。
下面我们看看如果没有对子线程进行thread.join()会发生什么,(用time将子线程延迟一下)就是前面注里面强调的情况:
import threading
import time
def main():
# 创建线程并传递字符串和数字参数
thread = threading.Thread(target=job1)
thread.start()
# thread.join() # 等待线程结束,才执行下面的代码
print("Main thread is done!") # 主线程结束
def job1():
time.sleep(2) # 暂停1秒,为了让演示效果更明显
print('job1 started') # 打印线程开始
for i in range(10):
time.sleep(0.1) # 暂停0.1秒后再继续运行
print('job1 stop') # 打印线程结束
if __name__ == '__main__':
main()
输出:

输出仅有一个主线程结束的打印,子线程完全没走完就结束了,所以join方法也是防止这种情况的。因此对每个子线程进行join是必不可少的流程。
2.4 使用queue(队列)功能获取多线程的返回值(重要,这就是前面那个例子怎么用多线程处理一个很大很大的数据(分成小数据集用多线程)的模板)
前面我们讲了传参问题解决了,还有一个问题,如果有返回值呢?threading本身是没有返回值的,其本来是用来做一些要一直开着的功能,例如程序运行中看门狗一样监视外部用户是不是修改了文件,这种情况就是要求一直开着的。但是我们可以借用队列来接住多线程的返回值。
示例1:输出不一定按顺序的草稿,不完整的模板
import threading
from typing import List
from queue import Queue
def job(l:List[int], q:Queue):
for i in range(len(l)):
l[i] = l[i]**2
# 不能用return,因为这是线程,没有返回值,只能用Queue()来存储数据
q.put(l)
def multithreading(data:List[List[int]]):
# 主线程创建一个Queue(),用来存储其他线程数据(共享内存)
q = Queue()
threads = []
for i in range(4):
t = threading.Thread(target=job, args=(data[i], q)) # Thread()和Queue()都是大写,表面这是类的实例化(object)
t.start()
threads.append(t)
for thread in threads:
thread.join()
results = []
for i in range(4):
results.append(q.get())
print(results)
if __name__ == '__main__':
data = [[1,2,3], [4,5,6], [7,8,9], [10,11,12]]
multithreading(data)
输出:
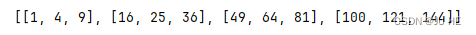
这是一个有返回值的多线程模板,碰到了要会用。但是上面的有一个小问题,并不能保证队列里面的是按输入顺序的。别看目前上面好像是按顺序的,其实都是相同的job,还有一个简单的先后顺序,换其他情况就不一定了。例如下面我用time来进行一些限制演示:
import threading
from typing import List
from queue import Queue
import time
def job(l:List[int], q:Queue):
time.sleep(1)
for i in range(len(l)):
l[i] = l[i]**2
# 不能用return,因为这是线程,没有返回值,只能用Queue()来存储数据
q.put(l)
def job2(l:List[int], q:Queue):
for i in range(len(l)):
l[i] = l[i]**2
# 不能用return,因为这是线程,没有返回值,只能用Queue()来存储数据
q.put(l)
def multithreading(data:List[List[int]]):
# 主线程创建一个Queue(),用来存储其他线程数据(共享内存)
q = Queue()
threads = []
for i in range(4):
t = threading.Thread(target=job, args=(data[i], q)) # Thread()和Queue()都是大写,表面这是类的实例化(object)
t.start()
threads.append(t)
jb2 = threading.Thread(target=job2, args=(data[-1], q))
jb2.start()
for thread in threads:
thread.join()
jb2.join()
results = []
for i in range(5):
results.append(q.get())
print(results)
if __name__ == '__main__':
data = [[1,2,3], [4,5,6], [7,8,9], [10,11,12],[20,444,78999]]
multithreading(data)
输出:
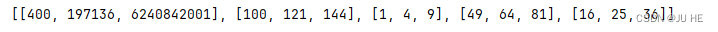
可以看到最后第一个跑第一个来了,不是按照顺序来了。
有什么解决办法,可以将结果与一个顺序标识符一起入队,另一种解决办法就是采用lock功能,推荐lock功能,下面演示lock功能的模板。建议先看完后面的lock功能在看下面示例。
示例2:有输出顺序的标准模板
import threading
from typing import List
from queue import Queue
import time
def job(l:List[int], q:Queue , lock:threading.Lock):
lock.acquire()
time.sleep(1)
for i in range(len(l)):
l[i] = l[i]**2
# 不能用return,因为这是线程,没有返回值,只能用Queue()来存储数据
q.put(l)
lock.release()
def job2(l:List[int], q:Queue, lock:threading.Lock):
lock.acquire()
for i in range(len(l)):
l[i] = l[i]**2
# 不能用return,因为这是线程,没有返回值,只能用Queue()来存储数据
q.put(l)
lock.release()
def multithreading(data:List[List[int]]):
# 主线程创建一个Queue(),用来存储其他线程数据(共享内存)
q = Queue()
lock = threading.Lock()
threads = []
for i in range(4):
t = threading.Thread(target=job, args=(data[i], q, lock)) # Thread()和Queue()都是大写,表面这是类的实例化(object)
t.start()
threads.append(t)
jb2 = threading.Thread(target=job2, args=(data[-1], q, lock))
jb2.start()
for thread in threads:
thread.join()
jb2.join()
results = []
for i in range(5):
results.append(q.get())
print(results)
if __name__ == '__main__':
data = [[1,2,3], [4,5,6], [7,8,9], [10,11,12],[20,444,78999]]
multithreading(data)
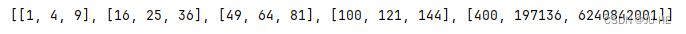
这不就又变回了按顺序了哈哈哈。
最后,lock对象不放到global里面去我自己都有点慌,哈哈哈,开个玩笑。
2.5 多线程的锁(lock)功能(保护共享内存的安全性)
讲lock功能就要结合join功能来讲,通过了解二者的区别,join和lock就都能掌握了。
join和Lock是threading.Thread类提供的两个不同的方法,它们的功能和用途不同:
join方法:
join方法用于让当前线程等待调用它的线程执行完毕。在调用线程中调用join方法后,该线程执行完后当前线程后,thread.join()后面的代码才会运行。与lock主要区别就在于thread.join()代码前面还是所有线程都在运行,而lock则一时间绝对保证只有一个线程在跑。
通常情况下,主线程会调用其他线程的join方法,以确保其他线程执行完毕后再继续执行主线程。这样可以控制程序的执行顺序,等待必要的任务完成后再进行下一步操作。
Lock对象:
Lock对象用于实现线程间的同步和互斥,防止多个线程同时访问共享资源导致的数据竞争和错误。
当一个线程获得了Lock对象的锁时,其他线程必须等待这个线程释放锁之后才能继续执行。这样可以确保在同一时间内只有一个线程可以访问共享资源,从而避免了竞态条件和数据不一致的问题。
示例1:join功能在join前半段仍然是所有线程一起交替进行
这里涉及到了一些全局变量(共享内存)的知识点,不是很清楚的话参考博客python传参
import threading
import time
def job1():
global A # 声明是共享内存(全局变量)
for i in range(10):
A += 1
time.sleep(0.1)
print('job1', A)
def job2():
global A
for i in range(10):
A += 10
time.sleep(0.2)
print('job2', A)
if __name__ == '__main__':
A = 0 # 全局变量,定义一个共享内存
t1 = threading.Thread(target=job1) # 定义线程1
t2 = threading.Thread(target=job2) # 定义线程2
t1.start() # 开启线程1
t2.start() # 开启线程2
t1.join() # 等待线程1结束
print('t1 end')
t2.join() # 等待线程2结束
print('t2 end')
输出:


可以很明显的看到,前半段还是两个线程不断切换,共享内存A被两个线程反复更新,这在实际中多线程共享内存时时刻刻都在耦合在一起,明显很容易出现问题,因此我们需要lock功能对象用于实现线程间的同步和互斥,防止多个线程同时访问共享资源导致的数据竞争和错误。
示例2:lock对象的使用
import threading
import time
def job1():
global A # 声明是共享内存(全局变量)
lock.acquire() # 锁住
for i in range(10):
A += 1
time.sleep(0.1)
print('job1', A)
lock.release() # 释放
def job2():
global A
lock.acquire() # 锁住
for i in range(10):
A += 10
time.sleep(0.2)
print('job2', A)
lock.release() # 释放
if __name__ == '__main__':
A = 0 # 全局变量,定义一个共享内存
lock = threading.Lock() # 定义一个线程锁
t1 = threading.Thread(target=job1) # 定义线程1
t2 = threading.Thread(target=job2) # 定义线程2
t1.start() # 开启线程1
t2.start() # 开启线程2
t1.join() # 等待线程1 join()方法的作用是阻塞主进程(防止主线程跑玩了,线程1和2还没跑完),等待子线程执行完毕,主进程再继续执行
t2.join() # 等待线程2 join()方法的作用是阻塞主进程(防止主线程跑玩了,线程1和2还没跑完),等待子线程执行完毕,主进程再继续执行
# 因此只要是多线程,对每一个子线程进行join()是必不可少的,否则主线程会在子线程未完成的情况下结束,导致子线程被迫结束
输出:


可以看到现在完全是先job1,在job2了这样就维护了共享内存A的安全性。
【注】:为什么不用lock对象也在函数内部声明是全局变量,首先其是一个可变数据,在函数内部只涉及到了修改操作,没有赋值操作,也就不会改变其地址,就一直是共享内存,但为了安全性,除非特别熟练,建议还是放到global里面声明一下。总之,不声明如果不熟练有可能出错,声明一定不会出错。看你的python理解程度了。
2.6 python多线程的假多线程机制 ---- 假的多线程(通过不断切换线程,给一种多线程同时进行的假象)
import threading
import time
import copy
from queue import Queue
def job(l, q):
res = sum(l)
q.put(res)
def multithreading(l):
q = Queue()
threads = []
for i in range(4):
t = threading.Thread(target=job, args=(copy.copy(l),q),name='T%i'%i)
t.start()
threads.append(t)
[t.join() for t in threads]
total = 0
for _ in range(4):
total += q.get()
print(total)
def normal(l):
total = sum(l)
print(total)
if __name__ == '__main__':
l = list(range(1000000))
s_t=time.time()
# 使用自己的单线程
normal(l*4)
print('normal:',time.time()-s_t)
s_t=time.time()
# 使用多线程(4个多线程处理同等规模问题)
multithreading(l)
print('multithreading:',time.time()-s_t)
输出:
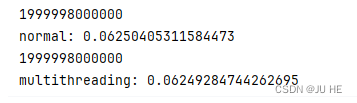
比较二者的运行时间,是差不多的,所以是一种假的多线程。
总结
没想到这么一个简单的功能写了这么多,看样子貌似写的很详细。如果喜欢的话点个赞呗!

















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









