




 这篇博客介绍了DPG(Deterministic Policy Gradient)方法在强化学习中的应用,对比了Policy Gradient (PG)和Stochastic Policy Gradient (SPG)的优缺点。DPG通过确定性策略减少了样本需求并提高了控制明确性,但面临探索问题。为了解决这个问题,文章探讨了Off-Policy Deterministic Actor-Critic (OPDAC)和Compatible Off-Policy Deterministic Actor-Critic (COPDAC)算法,其中COPDAC通过Compatible Function Approximation消除了梯度偏差。博主对算法细节和关键点提出了疑问,并鼓励读者进行讨论。
这篇博客介绍了DPG(Deterministic Policy Gradient)方法在强化学习中的应用,对比了Policy Gradient (PG)和Stochastic Policy Gradient (SPG)的优缺点。DPG通过确定性策略减少了样本需求并提高了控制明确性,但面临探索问题。为了解决这个问题,文章探讨了Off-Policy Deterministic Actor-Critic (OPDAC)和Compatible Off-Policy Deterministic Actor-Critic (COPDAC)算法,其中COPDAC通过Compatible Function Approximation消除了梯度偏差。博主对算法细节和关键点提出了疑问,并鼓励读者进行讨论。
1. Policy Gradient (PG)方法的优点:
相对于一般的 Value Based 方法(如估计Q(s,a)值), PG更加适合运用在连续的或者较大的Action Space(实际的机器人控制等等),因为随着 Action Space的增大,Q(s,a)的规模也会相对增大,对具体的实现造成很大的困难(如DQN的输出与Action的个数有关)。而对PG来说这种问题的影响就小多了。
2. Stochastic Policy Gradient (SPG)
SPG的Performance Objective为:
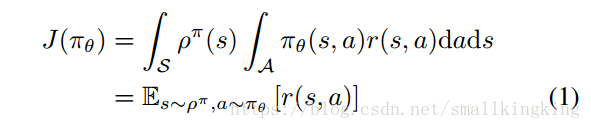
即为按照Policy 运行得到的action value的期望值,目标为改变Policy使Performance Objective尽可能大,可以使用梯度上升方法寻找局部最大值,其梯度如下:
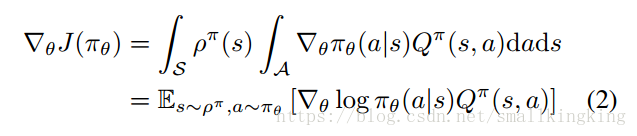
原文(Sliver的“”Deterministic Policy Gradient Algorithms“”)指出的

个人理解是因为![]() 对于某一个state输出的是所有action的概率,故他说是over state and action space。从而引出了DPG的优点,DPG最终得到的Policy为
对于某一个state输出的是所有action的概率,故他说是over state and action space。从而引出了DPG的优点,DPG最终得到的Policy为![]() ,它是某一个state到某一个action的映射而不是所有action概率的映射,故训练Deterministic Policy(DP)较Stochastic Policy(SP) 需要的样本量少,且更加明确,在控制中即包含了较少的噪声(因为其输出的是某一个确定的值而不是一个概率)。
,它是某一个state到某一个action的映射而不是所有action概率的映射,故训练Deterministic Policy(DP)较Stochastic Policy(SP) 需要的样本量少,且更加明确,在控制中即包含了较少的噪声(因为其输出的是某一个确定的值而不是一个概率)。
3. Deterministic Policy Gradient (DPG)
上部分说了DP较SP的优点(需要较少的样本,得出的Policy更加明确),然而使用DP也会带来问题
如何保证exploration:
论文使用off-policy deterministic actor-critic (OPDAC)方法,利用stochastic behavior policy 来产生训练数据从而达到增强exploration的目的。这样一来又引出了许多问题:
1)actor的问题:
对于那些基于表格的(一般来说state,action space较小的)的问题,一般使用GPI的方式,即先估计Q(s,a)的值,再根据估计的Q值来提升Policy,提升的方法一般是argmax操作:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4088
4088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









