




 TCP的滑动窗口机制用于高效传输数据,同时通过接收端反馈的窗口大小调整发送速率,实现流量控制。当接收窗口为0时,使用窗口探测报文避免死锁。此外,TCP还包括拥塞控制,通过慢启动、拥塞避免、快速恢复等算法动态调整拥塞窗口,确保网络稳定。糊涂窗口综合症则通过Nagle算法优化小数据块发送,防止无效传输。
TCP的滑动窗口机制用于高效传输数据,同时通过接收端反馈的窗口大小调整发送速率,实现流量控制。当接收窗口为0时,使用窗口探测报文避免死锁。此外,TCP还包括拥塞控制,通过慢启动、拥塞避免、快速恢复等算法动态调整拥塞窗口,确保网络稳定。糊涂窗口综合症则通过Nagle算法优化小数据块发送,防止无效传输。
引言
我们知道TCP是每发送一个数据,都要进行一次确认应答报文的。当上一个收到应答时,才会继续发送下一个。这种方式很显然效率比较低
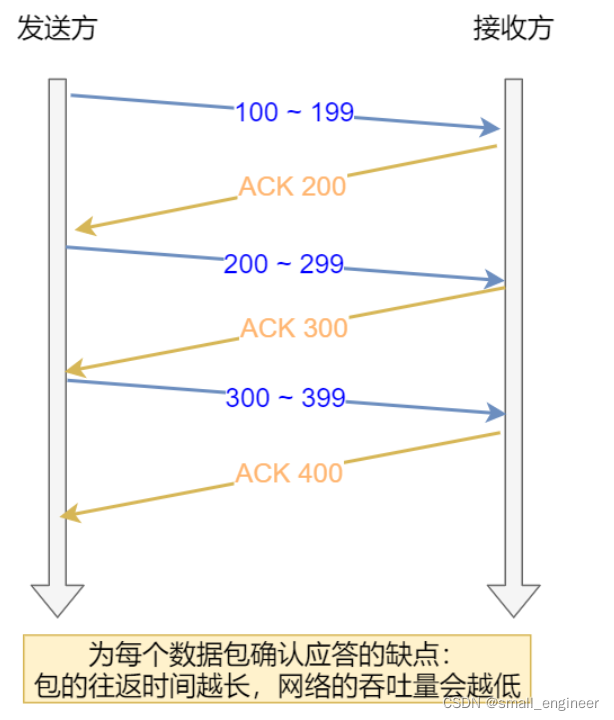
滑动窗口
窗口大小就是无需等待应答,而可以继续发送数据的最大值
滑动窗口实际上就是在操作系统中开辟一个缓存空间,发送方在等待应答报文之前,必须保留前面未确定的数据。如果收到了应答,则可以从缓冲区清楚
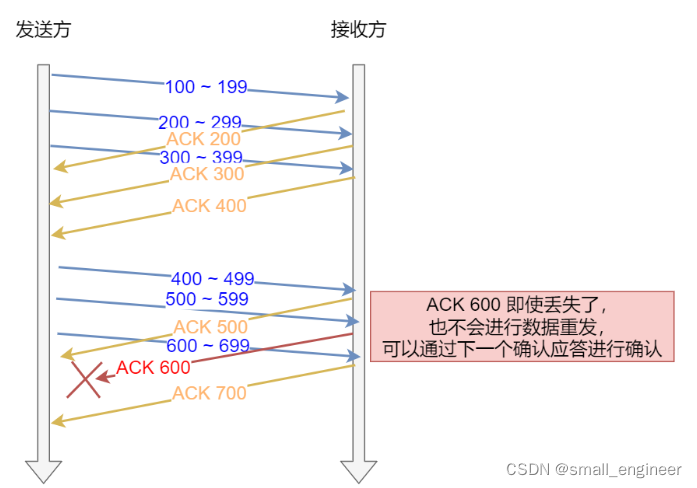
图中的 ACK 600 确认应答报文丢失,也没关系,因为可以通过下一个确认应答进行确认,只要发送方收到了 ACK 700 确认应答,就意味着 700 之前的所有数据「接收方」都收到了。这个模式就叫
累计确认或者累计应答。
窗口大小由哪一方决定?
TCP头有个字段叫做Window,也就是窗口大小,如下图:
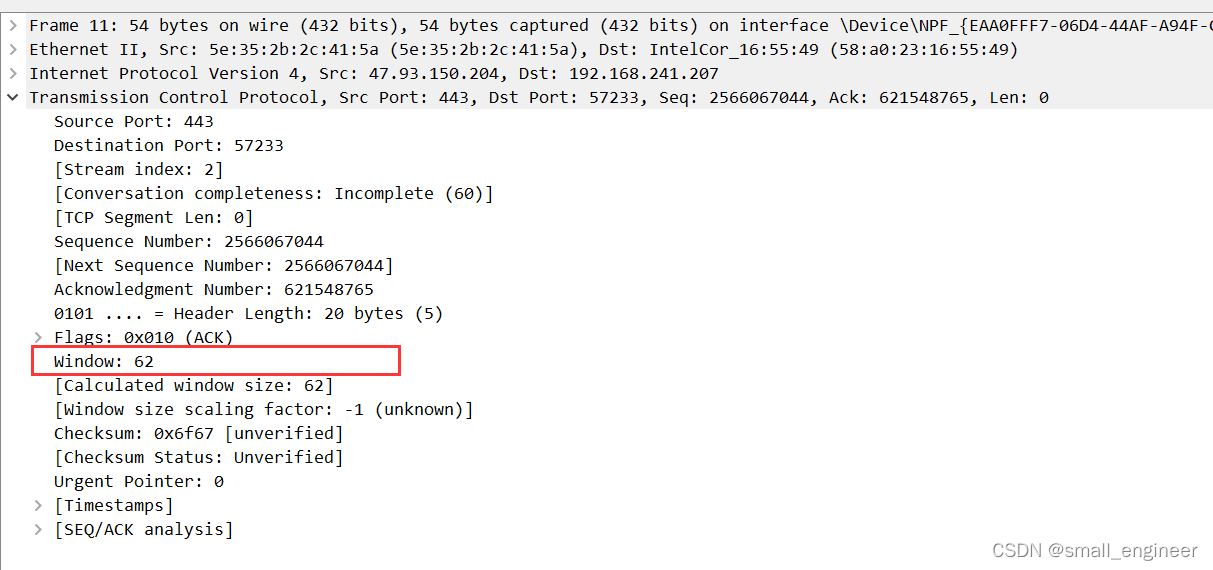
这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
所以,通常窗口的大小是由接收方的窗口大小来决定的。
发送方的滑动窗口
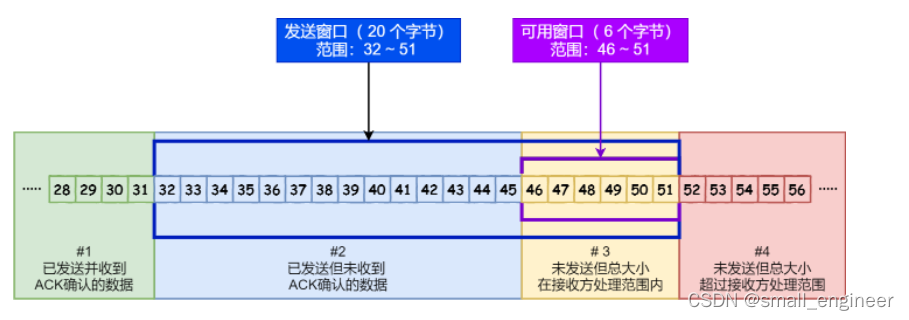
接收方的滑动窗口

接收窗口和发送窗口的大小是相等的吗?
并不是完全相等,接收窗口的大小是约等于发送窗口的大小的。
因为滑动窗口并不是一成不变的。比如,当接收方的应用进程读取数据的速度非常快的话,这样的话接收窗口可以很快的就空缺出来。那么新的接收窗口大小,是通过 TCP 报文中的 Windows 字段来告诉发送方。那么这个传输过程是存在时延的,所以接收窗口和发送窗口是约等于的关系。
流量控制
流量控制可以让发送端根据接收端的实际接受能力控制发送的数据量。它的具体操作是,接收端主机向发送端主机通知自己可以接收数据的大小,于是发送端会发送不会超过该大小的数据,该限制大小即为窗口大小,即窗口大小由接收端主机决定。
为什么需要流量控制?
当在通信时,发送方和接收方的速率是不一样的。当发送方发送数据给接收方时,接受方来不及处理,就把它放到缓冲区里,如果缓冲区满了,这时候发送方还在发送数据,就会造成数据包丢失,从而产生重传。所以我们需要控制发送方和接收方的发送速率,这就叫做流量控制

窗口探测报文
如果窗口大小为 0 时,就会阻止发送方给接收方传递数据,直到窗口变为非 0 为止,这就是窗口关闭。
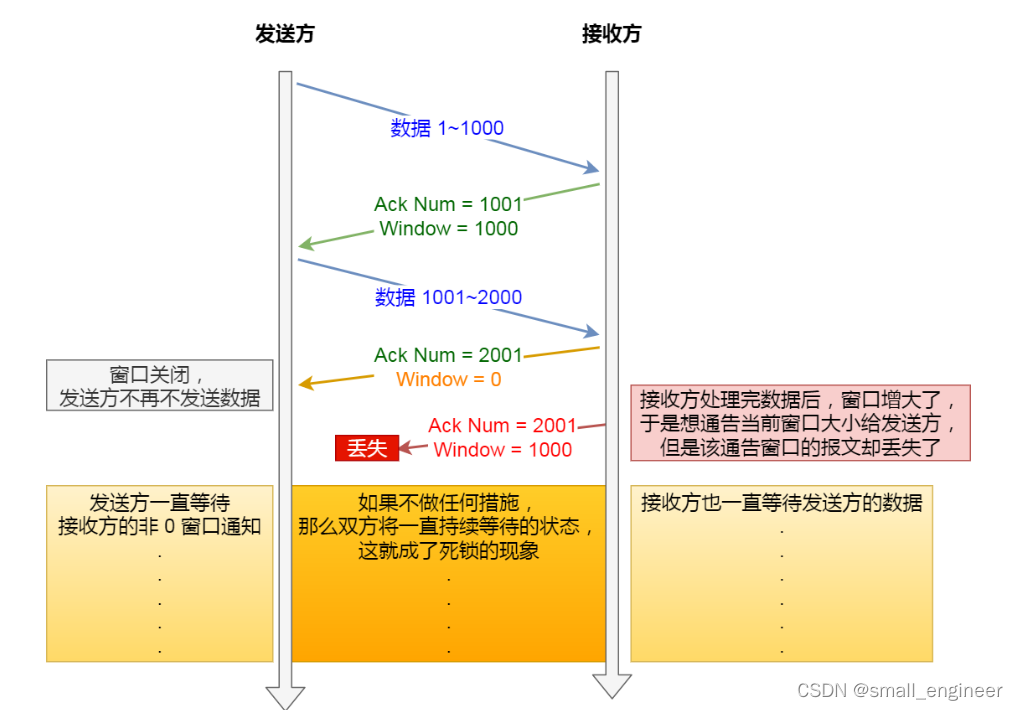
为了解决这种死锁现象,只要任一方接收到了0窗口通知,就会启动一个计时器,如果计时器超时,就会发送窗口探测报文,用于探测对方窗口大小。如果探测了三次还是0的话,就会发送RST报文终止连接
糊涂窗口综合症
如果接受方现在只有几个字节的数据,那么他会通告给发送方,那么发送方会义无反顾的继续发送那么几个字节,这就是
糊涂窗口综合症。tcp和ip头一共就有40个字节了,只发几个字节,显然这是不明智的。
如何解决这个问题呢??
很显然可以从发送方和接收方来处理。
不让接收方通告我有一个小窗口
当「窗口大小」小于 min( MSS,缓存空间/2 ) ,也就是小于 MSS 与 1/2 缓存大小中的最小值时,就会向发送方通告窗口为 0,也就阻止了发送方再发数据过来。不让发送方发送这个小窗口的数据
使用 Nagle 算法:任意时刻,最多只能有一个未被确认的小段。所谓“小段”,指的是小于MSS尺寸的数据块;所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
该算法的思路是延时处理,它满足以下两个条件中的一条才可以发送数据:
1)数据大小 >= MSS。
2)收到之前发送数据的 ack 回包
拥塞控制
拥塞控制和流量控制的区别???
前面的流量控制是避免「发送方」的数据填满「接收方」的缓存,但是并不知道网络的中发生了什么。
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大…
我们的TCP协议是无私的,网络传输中的事情他也要做出自己的贡献(你网络通畅,那我就做好自己,努力尽量的传输自己的东西;你网络堵了,我是个好人,就减少我发的东西,让你网络好一点),于是就有了拥塞控制,目的就是避免发送方的数据填满网络
为了调节我们的发送量,我们定义了一个叫做拥塞窗口的概念
拥塞窗口和发送窗口有什么区别呢??
拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的。
我们在前面提到过发送窗口 swnd 和接收窗口 rwnd 是约等于的关系,那么由于加入了拥塞窗口的概念后,此时发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值。
拥塞控制有什么算法??什么阶段用什么算法??
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
下面就是围绕着这四种算法进行讲解
慢启动
TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数量,如果一上来就发大量的数据,这不是给网络添堵吗?
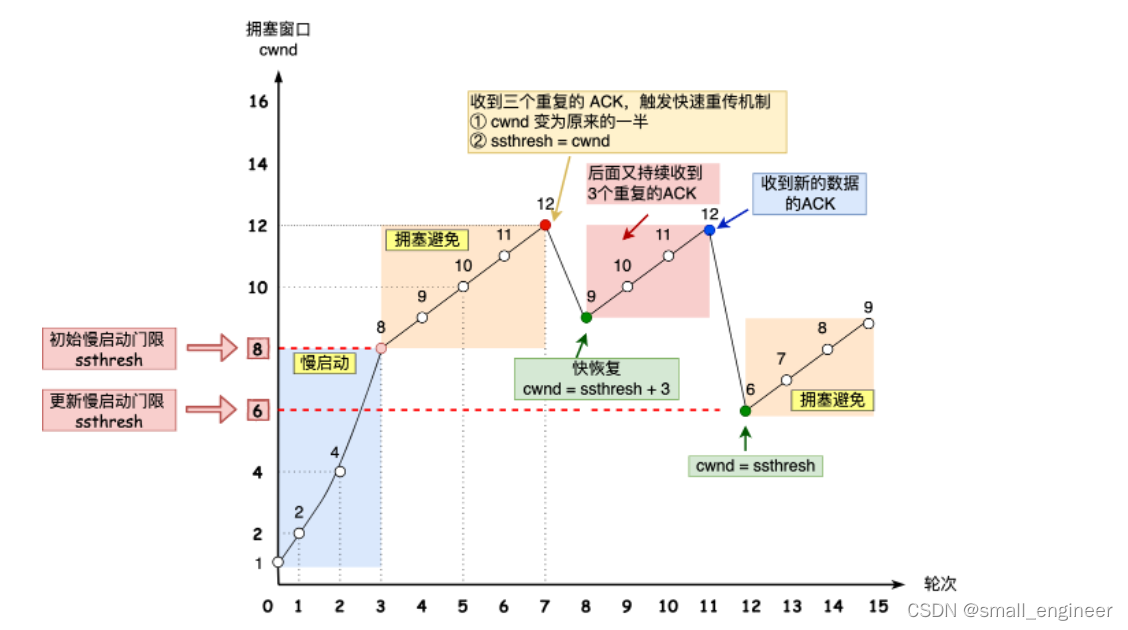
慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
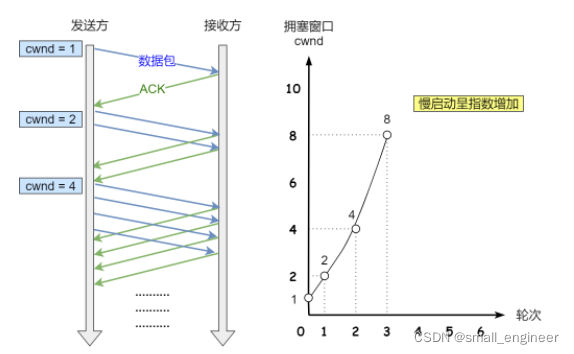
拥塞避免算法
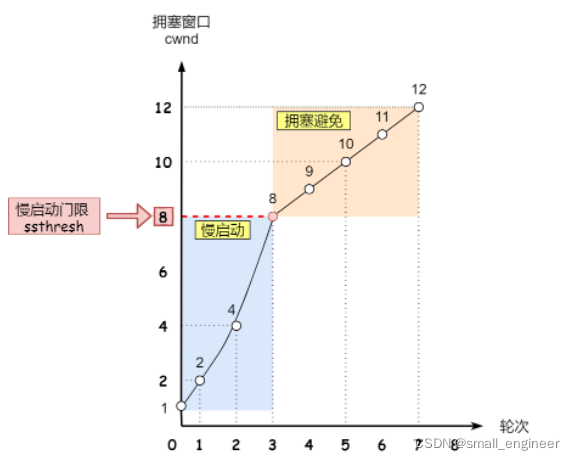
慢启动门限概念
- 当cwnd<ssthresh时,用慢启动算法
- 当cwnd>=ssthresh时,用拥塞避免算法
那么进入拥塞避免算法后,它的规则是:每当收到一个 ACK 时,cwnd 增加 1/cwnd。
拥塞发生算法
当网络中出现拥塞,也就是触发了重传机制,那么就会进入拥塞发生阶段
发生超时重传时,使用的拥塞发生算法如下,因为此时已经认为很拥塞了
这个时候,ssthresh 和 cwnd 的值会发生变化:
- ssthresh 设为 cwnd/2,
- cwnd 重置为 1
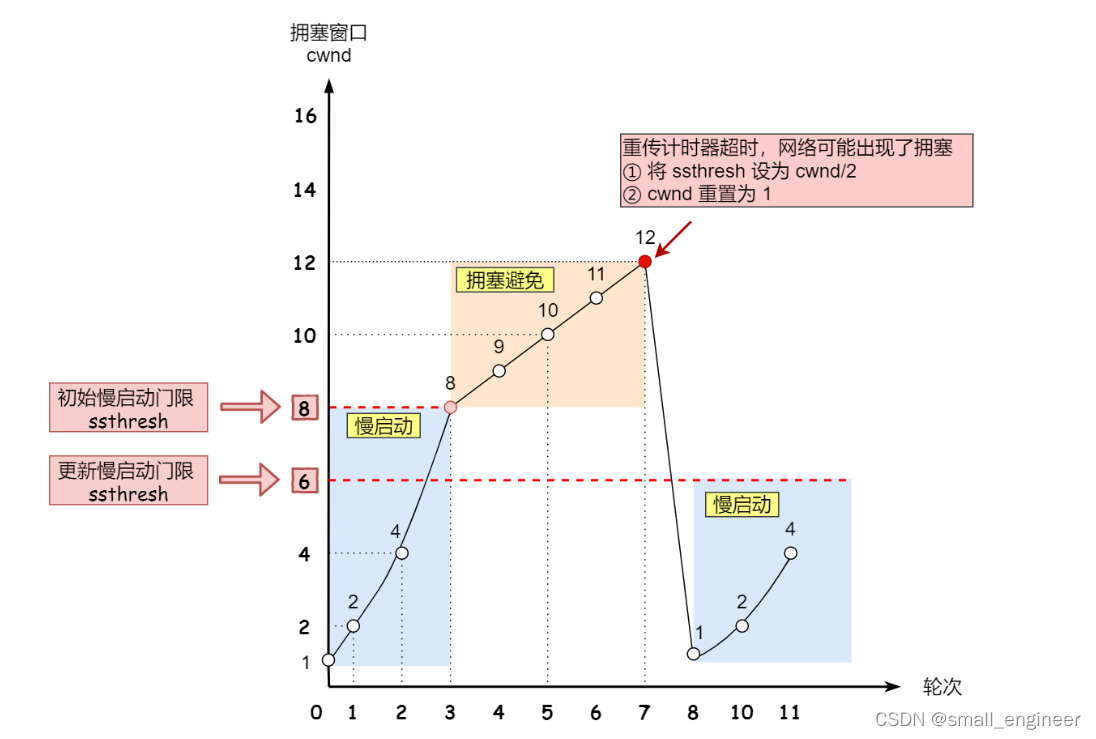
发生快速重传时,使用的拥塞发生算法(快速恢复算法)如下
当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下:
- cwnd=cwnd/2
- ssthresh=cwnd
然后,进入快速恢复算法如下:
- 拥塞窗口 cwnd = ssthresh + 3 ( 3 的意思是确认有 3 个数据包被收到了);
- 重传丢失的数据包
- 如果再收到重复的 ACK,那么 cwnd 增加 1;
- 如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;

















 1143
1143




 到【灌水乐园】发言
到【灌水乐园】发言







