







 本文介绍如何使用Python爬虫抓取豆瓣电影分类排行榜中动态加载的数据,通过分析网页请求,理解start与limit参数作用,实现对动态加载内容的完全抓取。
本文介绍如何使用Python爬虫抓取豆瓣电影分类排行榜中动态加载的数据,通过分析网页请求,理解start与limit参数作用,实现对动态加载内容的完全抓取。
在之前的爬虫豆瓣电影Top250学习中,爬取的内容都直接在网页源码中,而实际上很多数据都是在网页中实时AJAX请求,并不会显示在源代码中
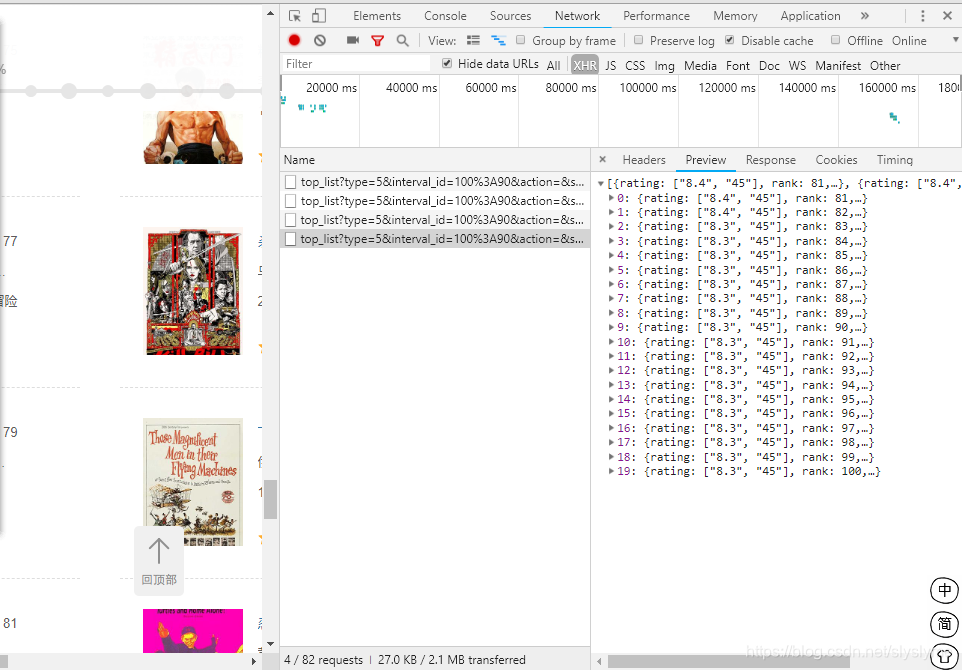
例如豆瓣电影分类排行榜 - 动作片为例,打开F12,选择Network--->XHR,当向下滑动网页时,我们可以看到新的文件出现
通过链接
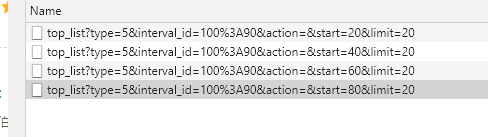
我们大体可以猜测出 start 与 limit 的含义,可以将此URL进行修改在地址栏中查看
由此:
# coding: utf-8
import urllib
import requests
post_param = {'action':'', 'start':'0', 'limit':'1'}
return_data = requests.get("https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90", data = post_param, verify = False)
print(return_data.text)

















 4300
4300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









